简介
历史发展
一文回顾深度学习发展史上最重要经典模型以历史顺序浏览论文也是了解当前技术的来历以及为什么会发明它们。换句话说,我会尽量呈现最小集的想法,最必要的基本知识,了解现代的深度学习研究核心发展历程。
一文梳理深度学习算法演进 未读
谷歌大牛Jeff Dean单一作者撰文:深度学习研究的黄金十年人工智能硬件和软件的进步,深度学习通过组合不同的线性代数(例如矩阵乘法、向量点积以及类似操作)进行运算,但这种运算方式会受到限制,因此我们可以构建专用计算机或加速器芯片来进行处理,相比于通用 CPU,这种专业化的加速器芯片能带来新的计算效率和设计选择。
发展脉络
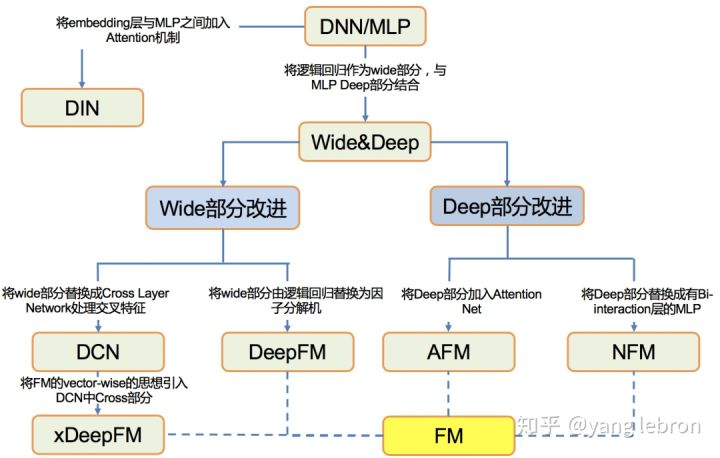
以推荐系统深度学习模型为例
- 深度学习极大地增强了推荐模型的拟合能力。理论上多层神经网络具备拟合任意函数的能力,所以我们通过增加神经网络层的方式就能解决模型欠拟合的问题了。
- 结构的灵活性:深度学习模型可以通过灵活调整自身的结构,更轻松恰当地模拟人们的思考过程和行为过程,把用户猜得更透。比如利用序列模型模拟用户兴趣的变迁、用户注意力机制等不同的用户行为过程。
关于模型改进的四个方向
- 改变神经网络的复杂程度,增加深度神经网络的层数和结构复杂。
- 改变特征交叉方式,比如说,改变用户向量和物品向量互操作方式的 NeuralCF,定义多种特征向量交叉操作的 PNN 等等。
- 把多种模型组合应用
- 让深度推荐模型和其他领域进行交叉
到底怎样的模型结构是最优的模型结构?跟你的业务特点和数据特点强相关。因此,在模型结构的选择上,没有“银弹”,没有最优,只有最合适。以DIEN为例,DIEN 的要点是模拟并表达用户兴趣进化的过程,那模型应用的前提必然是应用场景中存在着“兴趣进化”的过程。阿里巴巴的电商场景下,因为用户的购买兴趣在不同时间点有变化,所以有着明显的兴趣进化趋势。比如说,用户在购买了电脑后,就有一定概率会购买电脑周边产品,用户在购买了某些类型的服装后,就会有一定概率选择与其搭配的其他服装。这些都是兴趣进化的直观例子,也是阿里巴巴的电商场景下非常典型的情况。除此之外,我们还发现,在阿里巴巴的应用场景下,用户的兴趣进化路径能够被整个数据流近乎完整的保留。作为中国最大的电商集团,阿里巴巴各产品线组成的产品矩阵几乎能够完整地抓住用户购物过程中兴趣迁移的过程。当然,用户有可能去京东、拼多多等电商平台购物,从而打断阿里巴巴的兴趣进化过程,但从统计意义上讲,大量用户的购物链条还是可以被阿里巴巴的数据体系捕获的。
这样一来,我们就总结出了 DIEN 有效的前提是应用场景满足两个条件,一是应用场景存在“兴趣的进化”。二是用户兴趣的进化过程能够被数据完整捕获。如果二者中有一个条件不成立,DIEN 就很可能不会带来较大的收益。为什么这么说呢?还是以我自身的实践经历为例,
- 我现在工作的公司 Roku 是北美最大的视频流媒体平台,在使用的过程中,用户既可以选择我们自己的频道和内容,也可以选择观看 Netflix、YouTube,或者其他流媒体频道的内容。但是,一旦用户进入 Netflix 或者其他第三方应用,我们就无法得到应用中的具体数据了。在这样的场景下,我们仅能获取用户一部分的观看、点击数据,而且这部分的数据仅占用户全部数据的 10% 左右,用户的整个行为过程我们无法完全获取到,那么谈何构建起整个兴趣进化链条呢?
- 另外一点也很关键,通过分析我们发现,长视频用户的兴趣点相比电商而言其实是非常稳定的。电商用户可以今天买一套衣服,明天买一套化妆品,兴趣的变化过程非常快。但你很难想象长视频用户今天喜欢看科幻电影,明天就喜欢看爱情片,绝大多数用户喜好非常稳定地集中在一个或者几个兴趣点上。这也是序列模型并不能给我们公司提高效果的另一个主要原因。
模型结构不存在最优,只要你的数据、业务特点和阿里不一样,就不能假设这个模型在你的场景下具有同样的效果,所以根据自己的数据特点来改进模型才最重要。
why deep
- 深度学习就等于深度神经网络吗?深度学习是机器学习中使用深度神经网络的的子领域。所以如果我们要谈深度学习的话,是绕不开深度神经网络的。
- 神经网络需要可微的函数、需要能够计算梯度,这是最根本最重要的
- 我们知道一个机器学习模型,它的复杂度实际上和它的容量有关,而容量又跟它的学习能力有关。所以就是说学习能力和复杂度是有关的。机器学习界早就知道,如果我们能够增强一个学习模型的复杂度,那么它的学习能力能够提升。那怎么样去提高复杂度,对神经网络这样的模型来说,有两条很明显的途径。一条是我们把模型变深,一条是把它变宽。如果从提升复杂度的角度,那么变深是会更有效的。当你变宽的时候,你只不过是增加了一些计算单元,增加了函数的个数,在变深的时候不仅增加了个数,其实还增加了它的嵌入的程度。既然你们早就知道要建立更深的模型了?那为什么现在才开始做?这就涉及到另外一个问题,我们把机器学习的学习能力变强了,这其实未必是一件好事。因为机器学习一直在斗争的一个问题,就是经常会碰到过拟合(overfit)。我希望学到的是一般规律,能够用来预测未来的事情。但是有时候我可能把这个样本数据本身的一些独特特性学出来了,而不是一般规律。错误地把它当成一般规律来用的时候,会犯巨大的错误。那现在我们为什么可以用很复杂的模型?其实我们设计了许多方法来对付过拟合,比如神经网络有 dropout、early-stop 等。但有一个因素非常简单、非常有效,那就是用很大的数据。
- 为什么深度神经网络能成功?就是因为复杂度大。如果从复杂度这个角度去解释的话,我们就没法说清楚为什么扁平的(flat),或者宽的网络做不到深度神经网络的性能?实际上我们把网络变宽,虽然它的效率不是那么高,但是它同样也能起到增加复杂度的能力。但是这样的模型在应用里面怎么试,我们都发现它不如深度神经网络好。所以我们要问这么一个问题:深度神经网络里面最本质的东西到底是什么?今天我们的回答是,本质是表征学习的能力。以往我们用机器学习解决一个问题的时候,首先我们拿到一个数据,比如说这个数据对象是个图像,然后我们就用很多特征把它描述出来,比如说颜色、纹理等等。这些特征都是我们人类专家通过手工来设计的,表达出来之后我们再去进行学习。而今天我们有了深度学习之后,现在不再需要手工去设计特征了。你把数据从一端扔进去,结果从另外一端就出来了,中间所有的特征完全可以通过学习自己来解决。所以这就是我们所谓的特征学习,或者说表征学习。我们都认可这和以往的机器学习技术相比可以说是一个很大的进步,这一点非常重要。我们不再需要依赖人类专家去设计特征了。这个过程中的关键点是什么呢?是逐层计算,layer-by-layer processing。
- 当我们有很大的训练数据的时候,这就要求我们必须要有很复杂的模型。否则假设我们用一个线性模型的话,给你 2000 万样本还是 2 亿的样本,其实对它没有太大区别。它已经学不进去了。而我们有了充分的复杂度,恰恰它又给我们使用深度模型加了一分。所以正是因为这几个原因,我们才觉得这是深度模型里面最关键的事情。
- 这是我们现在的一个认识:第一,我们要有逐层的处理;第二,我们要有特征的内部变换;第三,我们要有足够的模型复杂度。这三件事情是我们认为深度神经网络为什么能够成功的比较关键的原因。或者说,这是我们给出的一个猜测。那如果满足这几个条件,我们其实马上就可以想到,那我不一定要用神经网络。凡是用过深度神经网络的人都会知道,你要花大量的精力来调它的参数,其实在图像上面调参数的经验,在语音问题上基本上不太有借鉴作用。所以当我们跨任务的时候,这些经验可能就很难共享。还有很多问题,比如说我们在用深度神经网络的时候,模型复杂度必须是事先指定的。因为我们在训练这个模型之前,我们这个神经网络是什么样就必须定了,然后我们才能用 BP 算法等等去训练它。其实这会带来很大的问题,因为我们在没有解决这个任务之前,我们怎么知道这个复杂度应该有多大呢?所以实际上大家做的通常都是设更大的复杂度。比如说 Kaggle 上面的很多竞赛有各种各样的真实问题,有买机票的,有订旅馆的,有做各种的商品推荐等等,我们就可以看到在很多任务上的胜利者并不是神经网络,它往往是像随机森林,像 xgboost 等等这样的模型。深度神经网络获胜的任务,往往就是在图像、视频、声音这几类典型任务上,都是连续的数值建模问题。而在别的凡是涉及到混合建模、离散建模、符号建模这样的任务上,其实深度神经网络的性能可能比其他模型还要差一些。这也就是我们说的「没有免费的午餐定理」,已经有数学证明,一个模型不可能在所有任务中都得到最好的表现。
- 我们从学术的观点来总结一下,今天我们谈到的深度模型基本上都是深度神经网络。如果用术语来说的话,它是多层、可参数化的、可微分的非线性模块所组成的模型,而这个模型可以用 BP 算法来训练。那么这里面有两个问题。第一,我们现实世界遇到的各种各样的问题的性质,并不是绝对都是可微的,或者用可微的模型能够做最佳建模的。第二,过去几十年里面,我们的机器学习界做了很多模型出来,这些都可以作为我们构建一个系统的基石,而中间有相当一部分模块是不可微的。
模型复杂之后的负面影响也非常多,比如训练时间加长,收敛所需数据和训练轮数增加,模型不一定稳定收敛,模型过拟合的风险增加等等。如果测试集的评估结果相比训练集出现大幅下降,比如下降幅度超过了 5%,就说明模型产生了非常严重的过拟合现象,我们就要反思一下是不是在模型设计过程中出现了一些问题,比如模型的结构对于这个问题来说过于复杂,模型的层数或者每层的神经元数量过多,或者我们要看一看是不是需要加入 Dropout,正则化项来减轻过拟合的风险。