简介(未完成)
- 循环神经网络,引入状态变量来存储过去的信息,并用其与当期的输入共同决定当前的输出。 多层感知机 + 隐藏状态 = 循环神经网络
- 应用到语言模型中时 ,循环神经网络根据当前词预测下一时刻词
- 通常使用困惑度来衡量语言模型的好坏
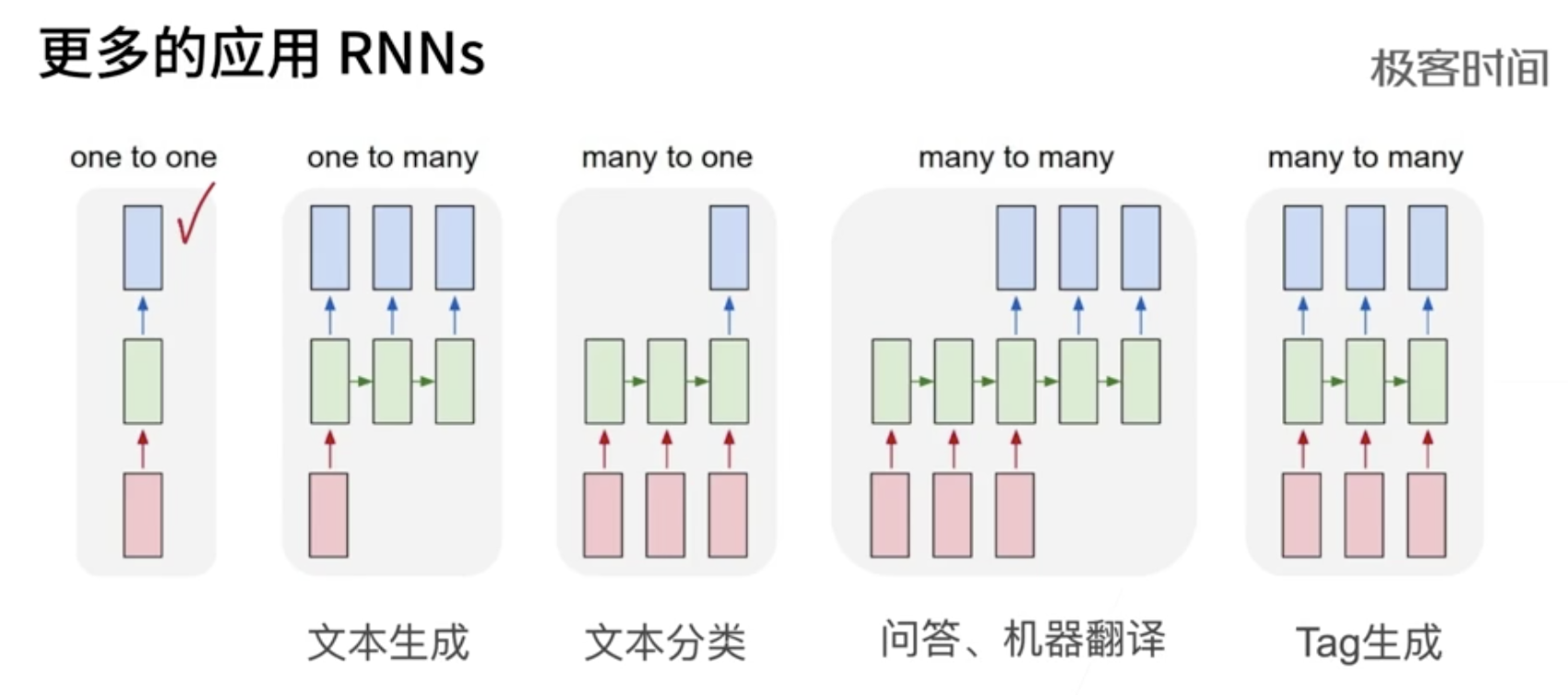
RNN 输入和输出 根据目的而不同
- 比如 根据一个字预测下一个字,输入就是一个字的特征向量(后续就是这个字的某个数字编号)
- 给一个词 标记是名词还是动词
- 语音处理。输入一个每帧的声音信号 的特征向量
为什么要发明循环神经网络
史上最详细循环神经网络讲解(RNN/LSTM/GRU)先来看一个NLP很常见的问题,命名实体识别,举个例子,现在有两句话:
- 第一句话:I like eating apple!(我喜欢吃苹果!)
- 第二句话:The Apple is a great company!(苹果真是一家很棒的公司!)
现在的任务是要给apple打Label,我们都知道第一个apple是一种水果,第二个apple是苹果公司,假设我们现在有大量的已经标记好的数据以供训练模型,当我们使用全连接的神经网络时,我们做法是把apple这个单词的特征向量输入到我们的模型中(如下图),在输出结果时,让我们的label里,正确的label概率最大,来训练模型,但我们的语料库中,有的apple的label是水果,有的label是公司,这将导致,模型在训练的过程中,预测的准确程度,取决于训练集中哪个label多一些,这样的模型对于我们来说完全没有作用。问题就出在了我们没有结合上下文去训练模型
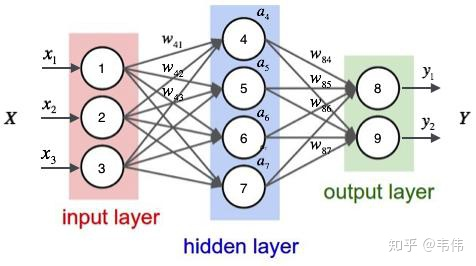
经典RNN 结构
字符集的循环神经网络 从零实现
def rnn(inputs, state, params):
# inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h) # H 是本次隐层的状态
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,) # H 随本次 output 一起返回
def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, is_random_iter, num_epochs, num_steps,
lr, clipping_theta, batch_size, pred_period,
pred_len, prefixes):
params = get_params()
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, device)
state = init_rnn_state(batch_size, num_hiddens, device)
for X, Y in data_iter:
inputs = to_onehot(X, vocab_size)
(outputs, state) = rnn(inputs, state, params) # 核心就是这句
outputs = torch.cat(outputs, dim=0)
y = torch.transpose(Y, 0, 1).contiguous().view(-1)
l = loss(outputs, y.long())
# 梯度清0
if params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
grad_clipping(params, clipping_theta, device) # 裁剪梯度
d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
l_sum += l.item() * y.shape[0]
n += y.shape[0]