前言
Linux虚拟网络技术学习在Linux虚拟化技术中,网络层面,通常重要的三个技术分别是Network Namespace、veth pair、以及网桥或虚拟交换机技术。
- 对于每个 Network Namespace 来说,它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。ip命令提供了
ip netns exec子命令可以在对应的 Network Namespace 中执行命令。PS: 也就是ip netns exec操作网卡、路由表、ARP表、iptables 等。也可以打开一个shell ,后面所有的命令都在这个Network Namespace中执行,好处是不用每次执行命令时都要带上ip netns exec ,缺点是我们无法清楚知道自己当前所在的shell,容易混淆。 - 默认情况下,network namespace 是不能和主机网络,或者其他 network namespace 通信的。可以使用 Linux 提供的veth pair来完成通信,veth pair你可以理解为使用网线连接好的两个接口,把两个端口放到两个namespace中,那么这两个namespace就能打通。
- 虽然veth pair可以实现两个 Network Namespace 之间的通信,但 veth pair 有一个明显的缺陷,就是只能实现两个网络接口之间的通信。如果多个network namespace需要进行通信,则需要借助bridge。
将vlan 理解为网络协议的多路复用,vxlan 理解为mesh,网络路由、交换设备理解为支持某种协议的进程,feel 会很不一样。
虚拟设备
Linux 虚拟网络设备之 tun/tapLinux内核中有一个网络设备管理层,处于网络设备驱动和协议栈之间,负责衔接它们之间的数据交互。驱动不需要了解协议栈的细节,协议栈也不需要了解设备驱动的细节。对于一个网络设备来说,就像一个管道(pipe)一样,有两端,从其中任意一端收到的数据将从另一端发送出去。对于Linux内核网络设备管理模块来说,虚拟设备和物理设备没有区别,都是网络设备,都能配置IP,从网络设备来的数据,都会转发给协议栈,协议栈过来的数据,也会交由网络设备发送出去,至于是怎么发送出去的,发到哪里去,那是设备驱动的事情,跟Linux内核就没关系了,所以说虚拟网络设备的一端也是协议栈,而另一端是什么取决于虚拟网络设备的驱动实现。
常见 PCIe 设备中,最适合 虚拟化 的就是网卡了: 一或多对 TX/RX queue + 一或多个中断,结合上一个 Routing ID,就可以抽象为一个 VF。而且它是近乎无状态的。
tun/tap
tun 和 tap 是一组通用的虚拟驱动程序包,是两个相对独立的虚拟网络设备,其中 tap 模拟了以太网设备,操作二层数据包(以太帧),tun 则是模拟了网络层设备,操作三层数据包(IP 报文)。它和物理设备eth0的差别,它们的一端虽然都连着协议栈,但另一端不一样,eth0的另一端是物理网络,这个物理网络可能就是一个交换机,而tun0的另一端是一个用户层的程序。使用 tun/tap 设备的目的,其实是为了把来自协议栈的数据包,先交给某个打开了/dev/net/tun字符设备的用户进程处理后,再把数据包重新发回到链路中。如此一来,只要协议栈中的数据包能被用户态程序截获并加工处理,程序员就有足够的舞台空间去玩出各种花样,比如数据压缩、流量加密、透明代理等功能,都能够在此基础上实现。PS:有点类似于FUSE 用户态实现文件系统
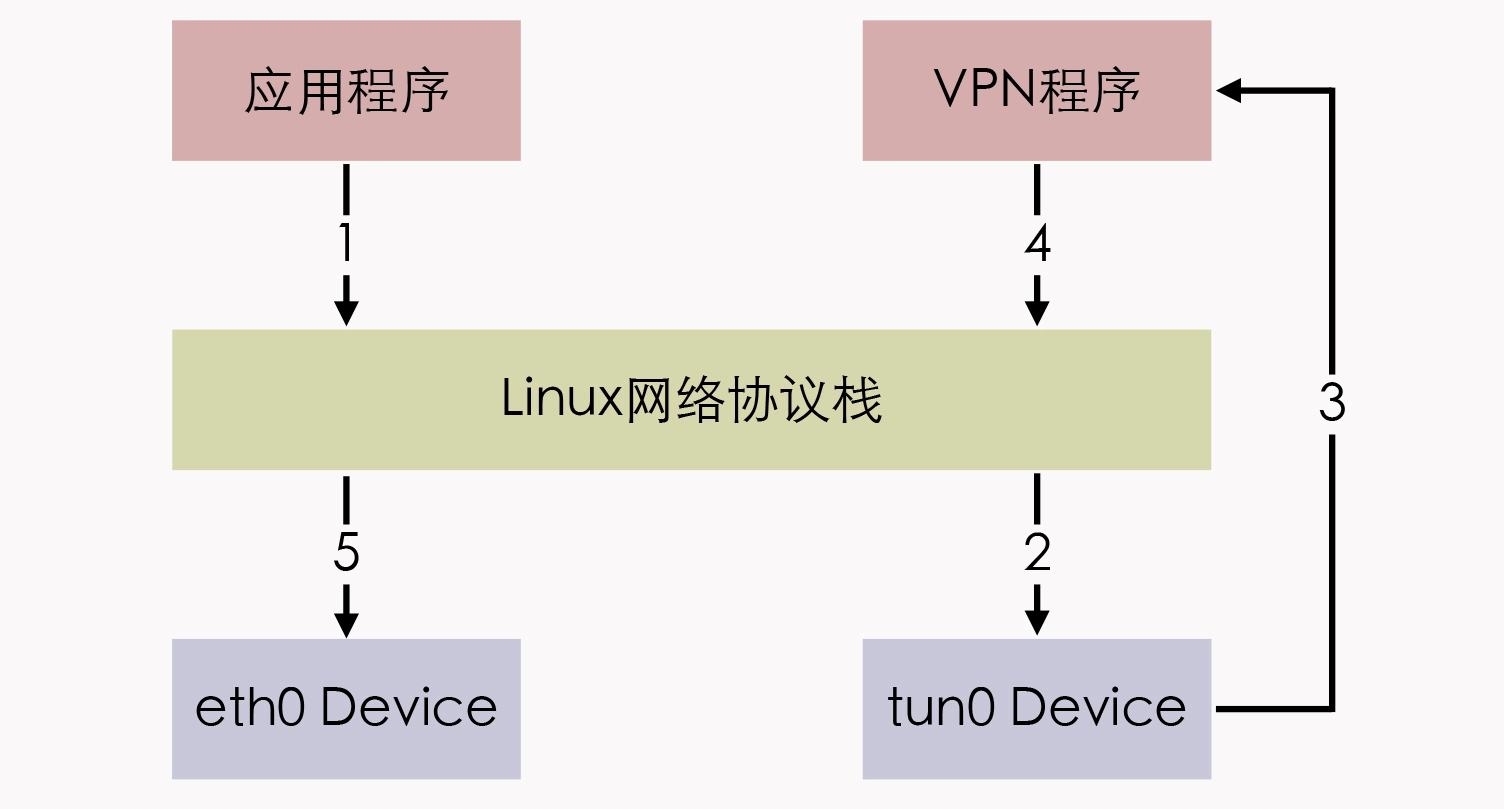
以最典型的 VPN 应用程序为例,应用程序通过 tun 设备对外发送数据包后,tun 设备如果发现另一端的字符设备已经被 VPN 程序打开(这就是一端连接着网络协议栈,另一端连接着用户态程序),就会把数据包通过字符设备发送给 VPN 程序,VPN 收到数据包,会修改后再重新封装成新报文,比如数据包原本是发送给 A 地址的,VPN 把整个包进行加密,然后作为报文体,封装到另一个发送给 B 地址的新数据包当中。
不过,使用 tun/tap 设备来传输数据需要经过两次协议栈,所以会不可避免地产生一定的性能损耗,因而如果条件允许,容器对容器的直接通信并不会把 tun/tap 作为首选方案,而是一般基于 veth 来实现的。但 tun/tap 并没有像 veth 那样,有要求设备成对出现、数据要原样传输的限制,数据包到了用户态程序后,我们就有完全掌控的权力,要进行哪些修改、要发送到什么地方,都可以通过编写代码去实现,所以 tun/tap 方案比起 veth 方案有更广泛的适用范围。
veth
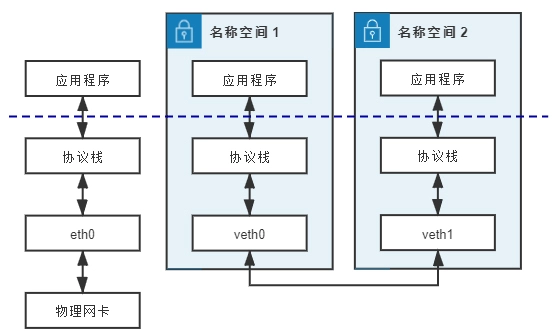
veth和其它的网络设备都一样,一端连接的是内核协议栈。eth0的另一端是物理网络,veth设备是成对出现的,veth另一端两个设备彼此相连,一个设备收到协议栈的数据发送请求后,会将数据发送到另一个设备上去。Linux 开始支持网络名空间隔离的同时,也提供了veth,让两个隔离的网络名称空间之间可以互相通信。
手把手带你搞定4大容器网络问题如果我们不能与一个专用的网络堆栈通信,那么它就没那么有用了。veth 设备是虚拟以太网设备。它们可以作为网络命名空间之间的隧道(也可以作为独立的网络设备使用)。虚拟以太网设备总是成对出现:sudo ip link add veth0 type veth peer name ceth0。创建后,veth0和ceth0都驻留在主机的网络堆栈(也称为根网络命名空间)上。为了连接根命名空间和netns0命名空间,我们需要将一个设备保留在根命名空间中,并将另一个设备移到netns0中:sudo ip link set ceth0 netns netns0。一旦我们打开设备并分配了正确的 IP 地址,任何出现在其中一台设备上的数据包都会立即出现在连接两个命名空间的对端设备上。
veth 发送数据的函数是 veth_xmit(),它里面的主要操作就是找到 veth peer 设备,然后触发 peer 设备去接收数据包。
static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev){
...
/* 拿到veth peer设备的net_device */
rcv = rcu_dereference(priv->peer);
...
/* 将数据送到veth peer设备 */
if (likely(veth_forward_skb(rcv, skb, rq, rcv_xdp) == NET_RX_SUCCESS)) {
...
}
static int veth_forward_skb(struct net_device *dev, struct sk_buff *skb,
struct veth_rq *rq, bool xdp){
/* 这里最后调用了 netif_rx(), 是一个网络设备驱动里面标准的接收数据包的函数,netif_rx() 里面会为这个数据包 raise 一个 softirq。*/
return __dev_forward_skb(dev, skb) ?: xdp ?
veth_xdp_rx(rq, skb) :
netif_rx(skb);
}
容器网络延时要比宿主机上的高吗?veth 发送数据的函数是 veth_xmit(),它里面的主要操作就是找到 veth peer 设备,然后触发 peer 设备去接收数据包。虽然 veth 是一个虚拟的网络接口,但是在接收数据包的操作上,除了没有硬件中断的处理,虚拟接口和真实的网路接口并没有太大的区别,特别是软中断(softirq)的处理部分和真实的网络接口是一样的。即使 softirq 的执行速度很快,还是会带来额外的开销。如果要减小容器网络延时,可以给容器配置 ipvlan/macvlan 的网络接口来替代 veth 网络接口。Ipvlan/macvlan 直接在物理网络接口上虚拟出接口,在发送对外数据包的时候可以直接通过物理接口完成,可以非常接近物理网络接口的延时。不过,由于 ipvlan/macvlan 网络接口直接挂载在物理网络接口上,对于需要使用 iptables 规则的容器,比如 Kubernetes 里使用 service 的容器,就不能工作了。
网桥
如果对网络不太熟悉,对于网桥的概念是很困惑的,下面试着简单解释一下。
-
如果两台计算机想要互联?这种方式就是一根网线,有两个头。一头插在一台电脑的网卡上,另一头插在 另一台电脑的网卡上。但是在当时,普通的网线这样是通不了的,所以水晶头要做交叉线,用的就是所 谓的1-3、2-6 交叉接法。水晶头的第 1、2 和第 3、6 脚,它们分别起着收、发信号的作用。将一端的 1 号和 3 号线、2 号和 6 号线互换一下位置,就能够在物理层实现一端发送的信号,另一端能收到。
-
三台计算机互联的方法
- 两两连接,那得需要多少网线,每个电脑得两个“插槽”,线路也比较乱。
- 使用集线器。使用集线器连接局域网中的pc时,一个重要缺点是:任何一个pc发数据,其它pc都会收到,无用不说,还导致物理介质争用。
- 使用交换机,使用交换机替换集线器后,会学习mac地址与端口(串口)的映射,pc1发给pc2的数据只有pc2才会接收到。
虽然 veth 以模拟网卡直连的方式,很好地解决了两个容器之间的通信问题,然而对多个容器间通信,如果仍然单纯只用 veth pair 的话,事情就会变得非常麻烦,毕竟,让每个容器都为与它通信的其他容器建立一对专用的 veth pair,根本就不实际,真正做起来成本会很高。因此这时,就迫切需要有一台虚拟化的交换机,来解决多容器之间的通信问题了。
Linux Bridge 是在 Linux Kernel 2.2 版本开始提供的二层转发工具,由brctl命令创建和管理。Linux Bridge 创建以后,就能够接入任何位于二层的网络设备,无论是真实的物理设备(比如 eth0),还是虚拟的设备(比如 veth 或者 tap),都能与 Linux Bridge 配合工作。当有二层数据包(以太帧)从网卡进入 Linux Bridge,它就会根据数据包的类型和目标 MAC 地址,按照如下规则转发处理:
- 如果数据包是广播帧,转发给所有接入网桥的设备。
- 如果数据包是单播帧,且 MAC 地址在地址转发表中不存在(网桥与交换机类似,会学习mac地址与端口(串口)的映射),则洪泛(Flooding)给所有接入网桥的设备,并把响应设备的接口与 MAC 地址学习(MAC Learning)到自己的 MAC 地址转发表中。
- 如果数据包是单播帧,且 MAC 地址在地址转发表中已存在,则直接转发到地址表中指定的设备。
- 如果数据包是此前转发过的,又重新发回到此 Bridge,说明冗余链路产生了环路。由于以太帧不像 IP 报文那样有 TTL 来约束,所以一旦出现环路,如果没有额外措施来处理的话,就会永不停歇地转发下去。那么对于这种数据包,就需要交换机实现生成树协议(Spanning Tree Protocol,STP)来交换拓扑信息,生成唯一拓扑链路以切断环路。
Linux Bridge 不仅用起来像交换机,实现起来也像交换机。对于通过brctl命令显式接入网桥的设备,Linux Bridge 与物理交换机的转发行为是完全一致的,它也不允许给接入的设备设置 IP 地址,因为网桥是根据 MAC 地址做二层转发的,就算设置了三层的 IP 地址也没有意义。不过,它与普通的物理交换机也还是有一点差别的,普通交换机只会单纯地做二层转发,Linux Bridge 却还支持把发给它自身的数据包,接入到主机的三层协议栈中。除了显式接入的设备外,它自己也无可分割地连接着一台有着完整网络协议栈的 Linux 主机,因为 Linux Bridge 本身肯定是在某台 Linux 主机上创建的,我们可以看作是 Linux Bridge 有一个与自己名字相同的隐藏端口,隐式地连接了创建它的那台 Linux 主机。因此,Linux Bridge 允许给自己设置 IP 地址,这样就比普通交换机多出了一种特殊的转发情况:如果数据包的目的 MAC 地址为网桥本身,并且网桥设置了 IP 地址的话,那该数据包就会被认为是收到发往创建网桥那台主机的数据包,这个数据包将不会转发到任何设备,而是直接交给上层(三层)协议栈去处理。这时,网桥就取代了物理网卡 eth0 设备来对接协议栈,进行三层协议的处理。
Switching was just a fancy name for bridging, and that was a 1980s technology – or so the thinking went.A bridge can be a physical device or implemented entirely in software. Linux kernel is able to perform bridging since 1999. Switches have meanwhile became specialized physical devices and software bridging had almost lost its place. However, with the advent of virtualization, virtual machines running on physical hosts required Layer 2 connection to the physical network and other VMs. Linux bridging provided a well proven technology and entered it’s Renaissance(文艺复兴). 最开始bridge是一个硬件, 也叫swtich,后来软件也可以实现bridge了,swtich就专门称呼硬件交换机了,再后来虚拟化时代到来,bridge 迎来了第二春。
Linux 虚拟网络设备之 bridgebridge 常用场景
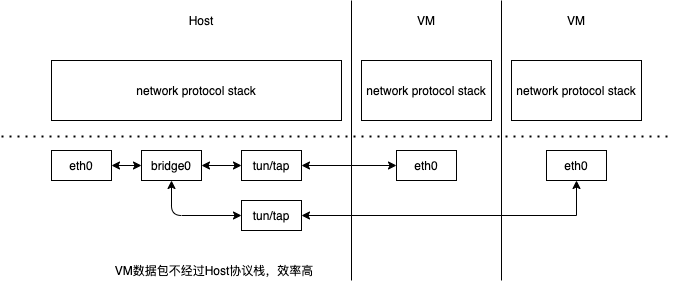
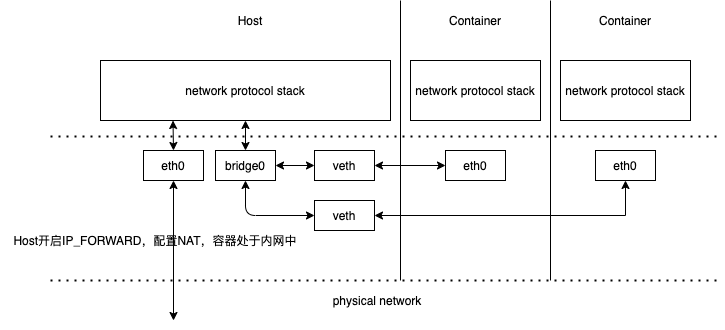
Macvlan and IPvlan basicsIn linux bridge implementation, VMs or Containers will connect to bridge and bridge will connect to outside world. For external connectivity, we would need to use NAT. container 光靠 bridge 无法直接访问外网。
A bridge transparently relays traffic between multiple network interfaces. In plain English this means that a bridge connects two or more physical Ethernets together to form one bigger (logical) Ethernet
| network layer | iptables rules | ||
| func | netif_receive_skb/dev_queue_xmit | netif_receive_skb/dev_queue_xmit | |
| data link layer | eth0 | br0 | |
| eth1 | eth2 | ||
| func | rx_handler/hard_start_xmit | rx_handler/hard_start_xmit | rx_handler/hard_start_xmit |
| phsical layer | device driver | device driver | device driver |
通俗的说,网桥屏蔽了eth1和eth2的存在。正常情况下,每一个linux 网卡都有一个device or net_device struct.这个struct有一个rx_handler。
eth0驱动程序收到数据后,会执行rx_handler。rx_handler会把数据包一包,交给network layer。从源码实现就是,接入网桥的eth1,在其绑定br0时,其rx_handler会换成br0的rx_handler。等于是eth1网卡的驱动程序拿到数据后,直接执行br0的rx_handler往下走了。所以,eth1本身的ip和mac,network layer已经不知道了,只知道br0。
br0的rx_handler会决定将收到的报文转发、丢弃或提交到协议栈上层。如果是转发,br0的报文转发在数据链路层,但也会执行一些本来属于network layer的钩子函数。也有一种说法是,网桥处于forwarding状态时,报文必须经过layer3转发。这些细节的确定要通过学习源码来达到,此处先不纠结。
读了上文,应该能明白以下几点。
- 为什么要给网桥配置ip,或者说创建br0 bridge的同时,还会创建一个br0 iface。
- 为什么eth0和eth1在l2,连上br0后,eth1和eth0的连通还要受到iptables rule的控制。
- 网桥首先是为了屏蔽eth0和eth1的,其次是才是连通了eth0和eth1。
2018.12.3 补充:一旦一张虚拟网卡被“插”在网桥上,它就会变成该网桥的“从设备”。从设备会被“剥夺”调用网络协议栈处理数据包的资格,从而“降级”成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包的“生杀大权”(比如转发或者丢弃),全部交给对应的网桥。
vlan
VLAN是二层技术还是三层技术-车小胖的回答知乎先用生活里的例子来比喻一下什么是VLAN,以及VLAN解决哪些问题。在魔都中心城区,经常有一些大房子被用来群租,有时大客厅也会放几张床用于出租,睡在客厅里的人肯定不爽的,因为有打呼噜的、有磨牙的、有梦游的、有说梦话的,一地鸡毛。为了克服以上的互相干扰,房东将客厅改造成若干个小房间,小房间还有门锁,这样每个房间就有了自己的私密空间,又可以有一定的安全性,至少贵重的物品可以放在房间里不怕别人拿错了。
隔断间形象的解释了划分vlan的理由,VLAN 的首要职责就是划分广播域,一个vlan一个广播域,把连接在同一个物理网络上的设备区分开来。我们将大广播域所对应的网段10.1.0.0/16分割成255个,那它们所对应的网段为10.1.1.0/24、10.1.2.0/24、10.1.3.0/24…10.1.255.0/24,它们对应的VLAN ID为1、2、3…255,这样每个广播域理论可以容纳255个终端,广播冲突的影响指数下降。
划分的具体方法是在以太帧的报文头中加入 VLAN Tag,让所有广播只针对具有相同 VLAN Tag 的设备生效。

对于支持 VLAN 的交换机,当这个交换机把二层的头取下来的时候,就能够识别这个 VLAN ID。这样只有相同 VLAN 的包,才会互相转发,不同 VLAN 的包,是看不到的。有一种口叫作 Trunk 口,它可以转发属于任何 VLAN 的口。交换机之间可以通过这种口相互连接。PS:说白了就是 在网络层支持了 “多路复用”,类似于http2 的StreamId,rpc 框架中的requestId
vlan 划分
- 常用的 VLAN 划分方式是通过端口进行划分,虽然这种划分 VLAN 的方式设置比较很简单, 但仅适用于终端设备物理位置比较固定的组网环境。随着移动办公的普及,终端设备可能不 再通过固定端口接入交换机,这就会增加网络管理的工作量。比如,一个用户可能本次接入 交换机的端口 1,而下一次接入交换机的端口 2,由于端口 1 和端口 2 属于不同的 VLAN,若 用户想要接入原来的 VLAN 中,网管就必须重新对交换机进行配置。显然,这种划分方式不 适合那些需要频繁改变拓扑结构的网络。
- 而 MAC VLAN 则可以有效解决这个问题,它根据 终端设备的 MAC 地址来划分 VLAN。这样,即使用户改变了接入端口,也仍然处在原 VLAN 中。注意,这种称为mac based vlan,跟macvlan还不是一个意思
在交换机上配置了IMP(ip-mac-port映射)功能以后,交换机会检查每个数据包的源IP地址和MAC,对于没有在交换机内记录的IP和MAC地址的计算机所发出的数据包都会被交换机所阻止。ip-mac-port映射静态设置比较麻烦,可以开启交换机上面的DHCP SNOOPING功能, DHCP Snooping可以自动的学习IP和MAC以及端口的配对,并将学习到的对应关系保存到交换机的本地数据库中。
默认情况下,交换机上每个端口只允许绑定一个IP-MAC条目,所以在使用docker macvlan时要打开这样的限制。
为何要一个VLAN一个网段?
先来看看若是同一个网段会有什么问题?
计算机发送数据包的基本过程:
- 如果要访问的目标IP跟自己是一个网段的(根据CIDR就可以判断出目标端IP和自己是否在一个网段内了),就不用经过网关了,先通过ARP协议获取目标端的MAC地址,源IP直接发送数据给目标端IP即可。
- 如果访问的不是跟自己一个网段的,就会先发给网关,然后再由网关发送出去,网关就是路由器的一个网口,网关一般跟自己是在一个网段内的,通过ARP获得网关的mac地址,就可以发送出去了
从中可以看到,两个vlan 若是同一个网段,数据包会不经网关 直接发往目的ip,也就是第一种方式,会先通过ARP广播获取目的ip的MAC地址,而arp 广播只会在源ip本身的vlan 中广播(vlan限定了广播域),因此永远也无法拿到目的ip的mac地址。
若是一个vlan 一个网段,按照上述基本过程
- 数据包会先发往网关(你必须为pc配置一个网关)
- 网关进行数据转发
这里要注意:
- vlan是实现在二层交换机上的,二层交换机没有网段的概念,只有路由器/三层交换机才有网段的概念。
- vlan网段的配置是配置在路由器的子接口上,每个子接口(Sub-Interface)采用802.1Q VLAN ID封装,这样就把网段和对应的VLAN联系了起来,子接口通常作为此网段的缺省网关。如果采用三层交换机来替代路由器,则使用 Interface VLAN ID 来将VLAN与网段联系起来,和使用路由器类似。
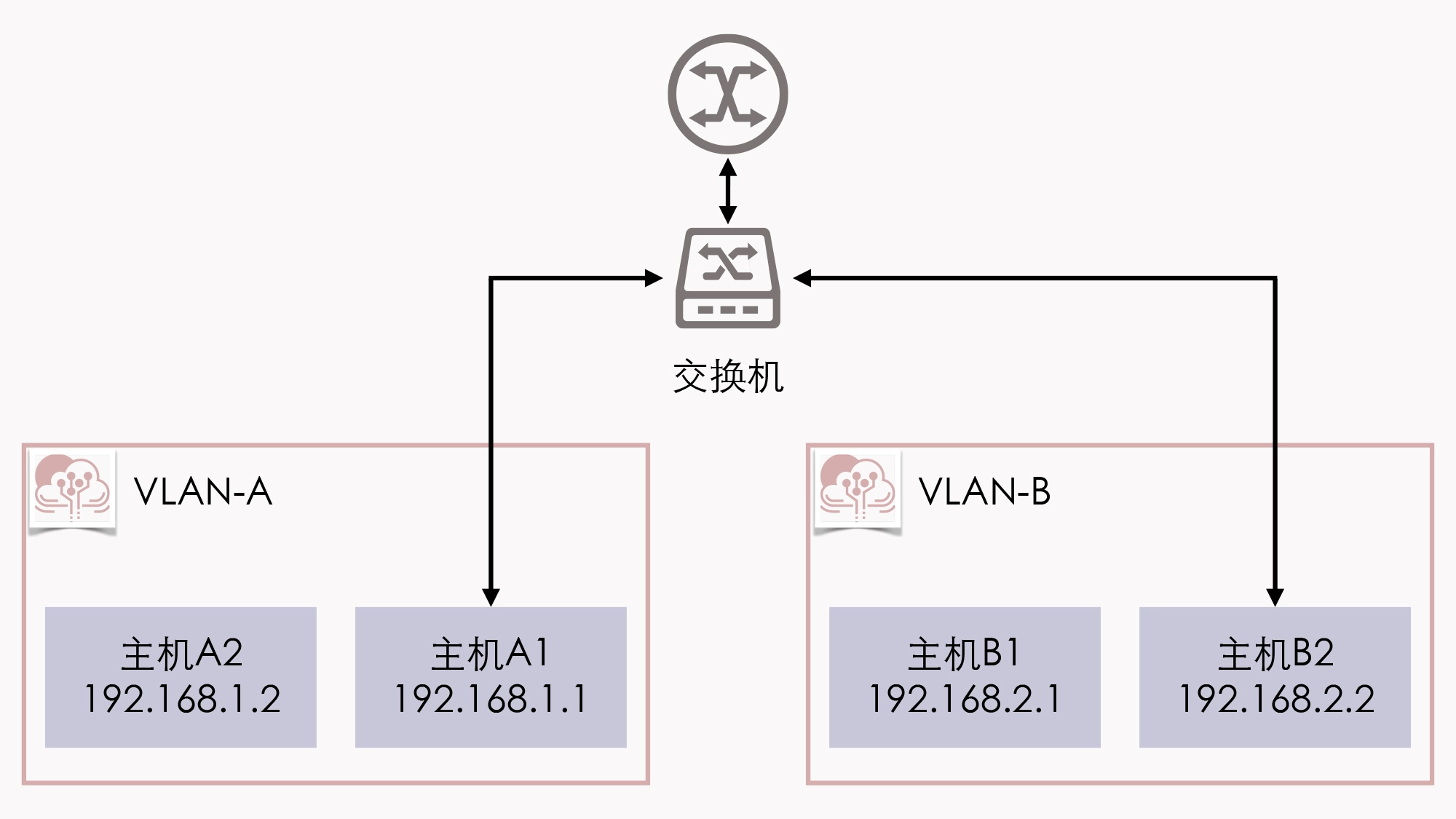
为啥vlan 要有个sub interface?
两个 VLAN 之间位于独立的广播域,是完全二层隔离的,要通信就只能通过三层设备。假设位于 VLAN-A 中的主机 A1,希望把数据包发送给 VLAN-B 中的主机 B2,由于 A、B 两个 VLAN 之间二层链路不通,因此引入了单臂路由。单臂路由不属于任何 VLAN,它与交换机之间的链路允许任何 VLAN ID 的数据包通过,这种接口被称为 TRUNK。这样,A1 要和 B2 通信,A1 就把数据包先发送给路由(只需把路由设置为网关即可做到),然后路由根据数据包上的 IP 地址得知 B2 的位置,去掉 VLAN-A 的 VLAN Tag,改用 VLAN-B 的 VLAN Tag 重新封装数据包后,发回给交换机,交换机收到后就可以顺利转发给 B2 了。由于 A1、B2 各自处于独立的网段上,它们又各自要把同一个路由作为网关使用,这就要求路由器必须同时具备 192.168.1.0/24 和 192.168.2.0/24 的 IP 地址。当然,如果真的就只有 VLAN-A、VLAN-B 两个 VLAN,那把路由器上的两个接口分别设置不同的 IP 地址,然后用两条网线分别连接到交换机上,也勉强算是一个解决办法。但要知道,VLAN 最多可以支持 4096 个 VLAN,那如果要接四千多条网线就太离谱了。因此为了解决这个问题,802.1Q 规范中专门定义了子接口(Sub-Interface)的概念,它的作用是允许在同一张物理网卡上,针对不同的 VLAN 绑定不同的 IP 地址。
vxlan
VLAN 有两个明显的缺陷
- 第一个缺陷在于 VLAN Tag 的设计。,VLAN 只有 12 位,共 4096 个。
- 第二个缺陷:跨数据中心传递。VLAN 本身是为二层网络所设计的,但是在两个独立数据中心之间,信息只能跨三层传递。而由于云计算的灵活性,大型分布式系统完全有跨数据中心运作的可能性,所以此时如何让 VLAN Tag 在两个数据中心间传递
- vlan 和vxlan 都是 virtual lan(局域网),但vlan 是隔离出来的,借助了交换机的支持(或者说推出太久了,以至于交换机普遍支持),vxlan 是虚拟出来的,交换机无感知。
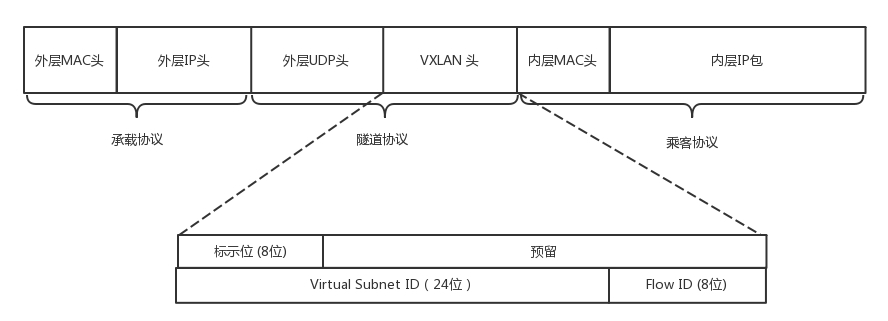
- VXLAN 对网络基础设施的要求很低,不需要专门的硬件提供特别支持,只要三层可达的网络就能部署 VXLAN。VLAN修改了原始的Ethernet Header,而VXLAN是将原始的Ethernet Frame隐藏在UDP数据里面。VXLAN 网络的每个边缘入口上,布置有一个 VTEP(VXLAN Tunnel Endpoints)设备,它既可以是物理设备,也可以是虚拟化设备,主要负责 VXLAN 协议报文的封包和解包。经过VTEP封装之后,在网络线路上看起来只有VTEP之间的UDP数据传递,原始的网络数据包被掩盖了。
使用报文解耦二三层

不过,VXLAN也带来了额外的复杂度和性能开销,具体表现为以下两点:
- 传输效率的下降,经过 VXLAN 封装后的报文,新增加的报文头部分就整整占了 50 Bytes(VXLAN 报文头占 8 Bytes,UDP 报文头占 8 Bytes,IP 报文头占 20 Bytes,以太帧的 MAC 头占 14 Bytes),而原本只需要 14 Bytes 而已,而且现在这 14 Bytes 的消耗也还在,只是被封到了最里面的以太帧中。以太网的MTU是 1500 Bytes,如果是传输大量数据,额外损耗 50 Bytes 并不算很高的成本,但如果传输的数据本来就只有几个 Bytes 的话,那传输消耗在报文头上的成本就很高昂了。
- 传输性能的下降,每个 VXLAN 报文的封包和解包操作都属于额外的处理过程,尤其是用软件来实现的 VTEP,要知道额外的运算资源消耗,有时候会成为不可忽略的性能影响因素。
macvlan
MACVLAN 借用了 VLAN 子接口的思路,并且在这个基础上更进一步,不仅允许对同一个网卡设置多个 IP 地址,还允许对同一张网卡上设置多个 MAC 地址,这也是 MACVLAN 名字的由来。原本 MAC 地址是网卡接口的“身份证”,应该是严格的一对一关系,而 MACVLAN 打破了这层关系。方法就是在物理设备之上、网络栈之下生成多个虚拟的 Device,每个 Device 都有一个 MAC 地址,新增 Device 的操作本质上相当于在系统内核中,注册了一个收发特定数据包的回调函数,每个回调函数都能对一个 MAC 地址的数据包进行响应,当物理设备收到数据包时,会先根据 MAC 地址进行一次判断,确定交给哪个 Device 来处理,如下图所示。
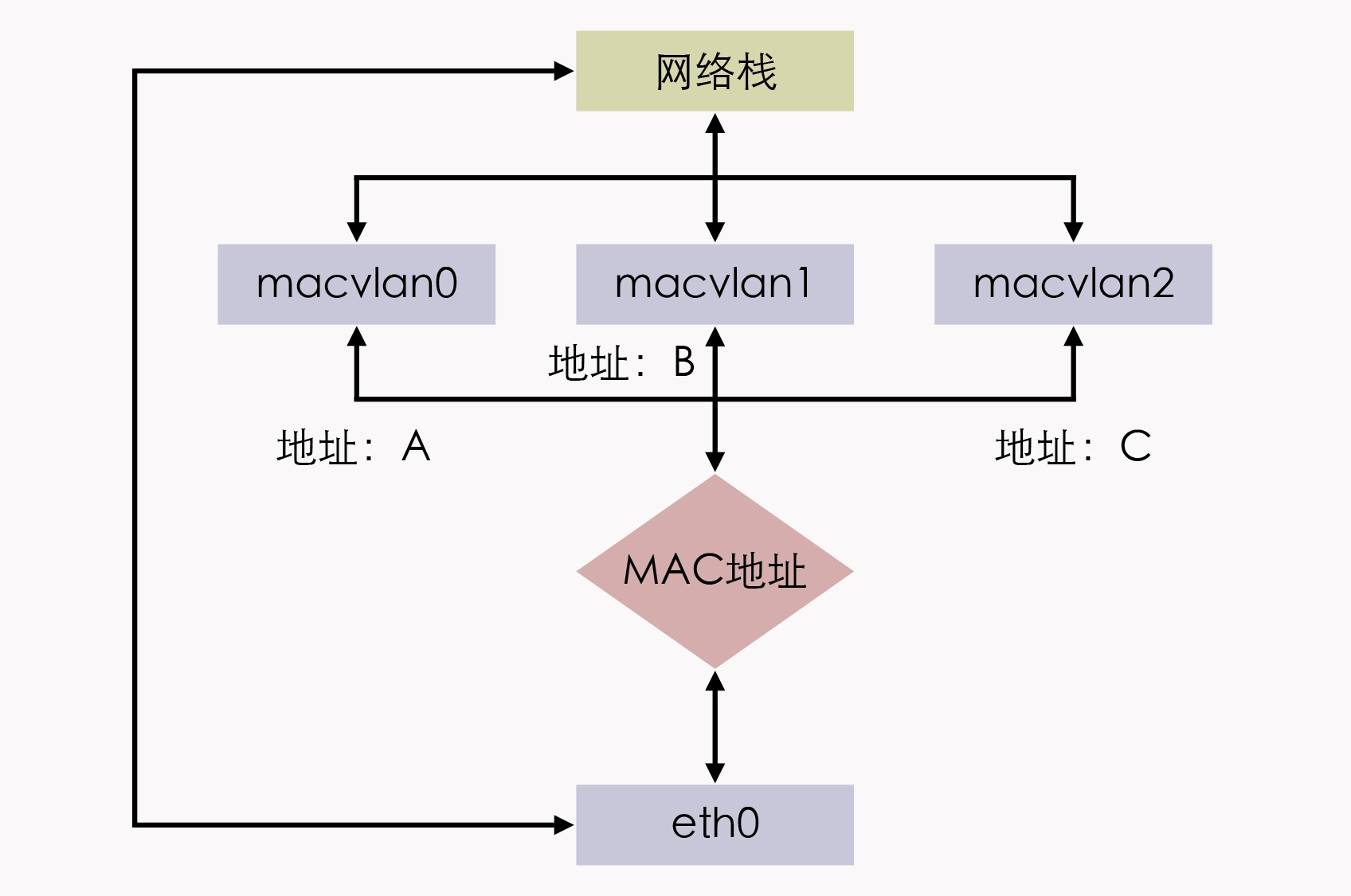
用 MACVLAN 技术虚拟出来的副本网卡,在功能上和真实的网卡是完全对等的,此时真正的物理网卡实际上也确实承担着类似交换机的职责。在收到数据包后,物理网卡会根据目标 MAC 地址,判断这个包应该转发给哪块副本网卡处理,由同一块物理网卡虚拟出来的副本网卡,天然处于同一个 VLAN 之中,因此可以直接二层通信,不需要将流量转发到外部网络。而除了模拟交换机的 Bridge 模式外,MACVLAN 还支持虚拟以太网端口聚合模式(Virtual Ethernet Port Aggregator,VEPA)、Private 模式、Passthru 模式、Source 模式等另外几种工作模式。
Macvlan and IPvlan basicsMacvlan and ipvlan are Linux network drivers that exposes underlay or host interfaces directly to VMs or Containers running in the host.
Kubernetes在信也科技的落地实战Macvlan是一种直连网络,数据包通过宿主机网卡传输到硬件链路上,通过交换机路由器等设备最终到达目的地。Macvlan网络是Linux内核原生支持,不需要部署额外的组件。本身包含VLAN特性,一台宿主机上面可以虚拟出多块VLAN网卡,支持多个C类地址的IP分配。此时宿主机和交换机的链路必须是trunk模式,同一链路根据不同报文内的vlanID如(10、20、30)组成逻辑信道,互不干扰。
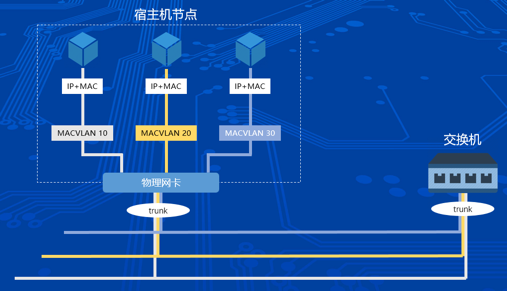
采用Macvlan网络模式之后,容器里面的网络协议栈和宿主机是完全独立。这就导致容器不能使用宿主机的iptables规则从而容器里面无法通过ClusterIP去访问Service。
与 mac based vlan 区别
要跟mac based vlan 有所区分,参见虚拟网络。
Macvlan, MACVLAN or MAC-VLAN allows you to configure multiple Layer 2 (i.e. Ethernet MAC) addresses on a single physical interface. Macvlan allows you to configure sub-interfaces (also termed slave devices) of a parent, physical Ethernet interface (also termed upper device), each with its own unique (randomly generated) MAC address, and consequently its own IP address. Applications, VMs and containers can then bind to a specific sub-interface to connect directly to the physical network, using their own MAC and IP address. 基于物理机网卡 physical interface 创建多个 sub-interface,拥有自己的MAC and IP ,直接接入physical network。
sub-interface
Macvlan and IPvlan basics 讲清了macvlan sub-interface 和 vlan-sub-interface 的异同
| 物理网卡 | vlan sub-interface | macvlan sub-interface | |
|---|---|---|---|
| mac/ip | all sub-interfaces have same mac address(ip 手动/自动配) | each sub-interface will get unique mac and ip address | |
| each sub-interface belongs to a different L2 domain using vlan(发的包自带vlan id,是数据帧的一部分) | exposed directly in underlay network | ||
| 配置文件 | 独立的网络接口配置文件 | 保存在临时文件/proc/net/vlan/config,重启会丢失 |
独立的网络接口配置文件 |
| 一般格式 | eth0 | eth0.1 | eth0:1 |
vlan sub-interface他们没有自己的配置文件,他们只是通过将物理网加入不同的VLAN而生成的VLAN虚拟网卡。如果将一个物理网卡添加到多个VLAN当中去的话,就会有多个VLAN虚拟网卡出现。vlan sub-interface 的mac 地址都一样
macvlan 本身跟vlan 没啥关系,如果不考虑虚拟化的概念,甚至可以理解为一个物理机插了多个网卡。但在容器里面通常跟vlan 结合使用(因为一个宿主机的上百个容器可能属于不同的vlan)。 Following picture shows an example where macvlan sub-interface works together with vlan sub-interface. Containers c1, c2 are connected to underlay interface ethx.1 and Containers c3, c4 are connected to underlay interface ethx.2.
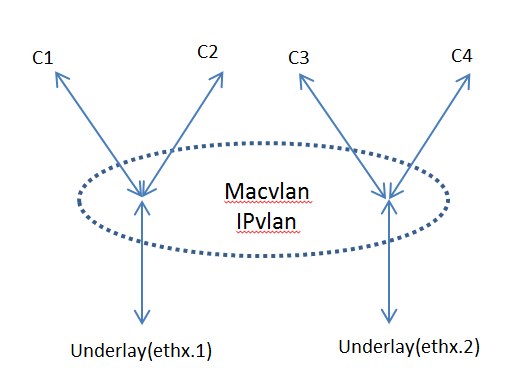
Docker Networking: macvlans with VLANs
One macvlan, one Layer 2 domain and one subnet per physical interface, however, is a rather serious limitation in a modern virtualization solution. 这个说的是物理机时代,一个host 两个网卡,每个网卡属于不同的vlan(属于同一个vlan的话还整两个网卡干啥),而两个vlan 不可以是同一个网段。
a Docker host sub-interface can serve as a parent interface for the macvlan network. This aligns perfectly with the Linux implementation of VLANs, where each VLAN on a 802.1Q trunk connection is terminated on a sub-interface of the physical interface. You can map each Docker host interface to a macvlan network, thus extending the Layer 2 domain from the VLAN into the macvlan network.
Docker macvlan driver automagically creates host sub interfaces when you create a new macvlan network with sub interface as a parent。vlan sub interface 创建完毕后,以其为parent 创建macvlan sub interface 由 macvlan driver 自动完成。
ipvlan
ipvlan 的虚拟网络接口是和物理网络接口共享同一个 mac 地址。
为容器手动配置上 ipvlan 的网络接口
docker run --init --name lat-test-1 --network none -d registry/latency-test:v1 sleep 36000
pid1=$(docker inspect lat-test-1 | grep -i Pid | head -n 1 | awk '{print $2}' | awk -F "," '{print $1}')
echo $pid1
ln -s /proc/$pid1/ns/net /var/run/netns/$pid1
ip link add link eth0 ipvt1 type ipvlan mode l2
ip link set dev ipvt1 netns $pid1
ip netns exec $pid1 ip link set ipvt1 name eth0
ip netns exec $pid1 ip addr add 172.17.3.2/16 dev eth0
ip netns exec $pid1 ip link set eth0 up
容器的虚拟网络接口,直接连接在了宿主机的物理网络接口上了,直接形成了一个网络二层的连接。如果从容器里向宿主机外发送数据,通过的接口要比 veth 少了,没有内部额外的 softirq 处理开销。。
static int ipvlan_xmit_mode_l2(struct sk_buff *skb, struct net_device *dev){
…
/* 拿到ipvlan对应的物理网路接口设备, 然后直接从这个设备发送数据。*/
skb->dev = ipvlan->phy_dev;
return dev_queue_xmit(skb);
}
其它
什么是network driver?
A network device driver is a device driver that enables a network device to communicate between the computer and operating system as well as with other network computers and network devices.
Device driverIn computing, a device driver is a computer program that operates or controls a particular type of device that is attached to a computer. A driver provides a software interface to hardware devices, enabling operating systems and other computer programs to access hardware functions without needing to know precise details about the hardware being used. 驱动就是对硬件提供软件接口,屏蔽硬件细节。
A driver communicates with the device through the computer bus or communications subsystem to which the hardware connects. When a calling program invokes a routine in the driver, the driver issues commands to the device. Once the device sends data back to the driver, the driver may invoke routines in the original calling program. Drivers are hardware dependent and operating-system-specific. They usually provide the interrupt handling required for any necessary asynchronous time-dependent hardware interface.
网卡 ==> computer bus ==> network driver ==> Subroutine/子程序 ==> calling program。也就是network driver 在网卡 与操作系统之间,从这个角度看,跟磁盘驱动、鼠标驱动类似了。