简介(未完成)
初识 eBPF,你应该知道的知识简单来说,eBPF 是 Linux 内核中一个非常灵活与高效的类虚拟机(virtual machine-like)组件, 能够在许多内核 hook 点安全地执行字节码(bytecode)。
在内核中运行用户指定的程序被证明是一种有用的设计,eBPF 程序是在内核中被事件触发的。在一些特定的指令被执行时,这些事件会在 hook 处被捕获。Hook 被触发就会执行 eBPF 程序,对数据进行捕获和操作。
在 eBPF 之前,内核模块是注入内核的最主要机制。由于缺乏对内核模块的安全控制,内核的基本功能很容易被一个有缺陷的内核模块破坏。而 eBPF 则借助即时编译器(JIT),在内核中运行了一个虚拟机,保证只有被验证安全的 eBPF 指令才会被内核执行。同时,因为 eBPF 指令依然运行在内核中,无需向用户态复制数据,这就大大提高了事件处理的效率。
基于 eBPF 的 Kubernetes 一站式可观测性系统eBPF 相当于在内核中构建了一个执行引擎,通过内核调用将这段程序 attach 到某个内核事件上,做到监听内核事件;有了事件我们就能进一步做协议推导,筛选出感兴趣的协议,对事件进一步处理后放到 ringbuffer 或者 eBPF 自带的数据结构 Map 中,供用户态进程读取;用户态进程读取这些数据后,进一步关联 Kubernetes 元数据后推送到存储端。这是整体处理过程。
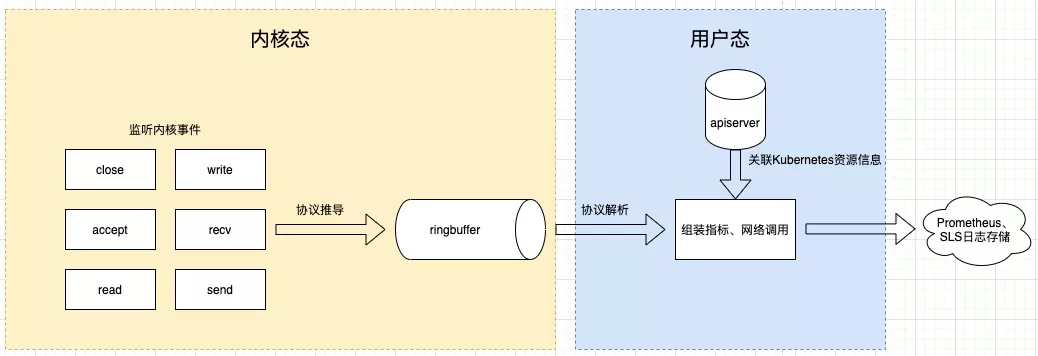
eBPF 的超能力体现在能订阅各种内核事件,如文件读写、网络流量等,运行在 Kubernetes 中的容器或者 Pod 里的一切行为都是通过内核系统调用来实现的,内核知道机器上所有进程中发生的所有事情,所以内核几乎是可观测性的最佳观测点,这也是我们为什么选择 eBPF 的原因。另一个在内核上做监测的好处是应用不需要变更,也不需要重新编译内核,做到了真正意义上的无侵入。
基于 eBPF 的 Kubernetes 问题排查全景图 MySQL 协议基于 TCP 之上的,我们的 eBPF 探针识别到 MySQL 协议后,组装、还原了 MySQL 协议内容,任何语言执行的 SQL 语句都能采集到。PS: 通过监控数据本身还原到 哪个sql 执行的慢。
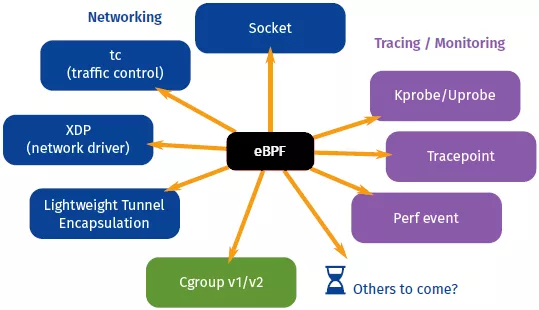
BPF 的应用最早仅限于网络包过滤这个传统的领域中,为了研究新的软件定义网络方案,将 BPF 扩展为一个通用的虚拟机,也就是 eBPF。eBPF 不仅扩展了寄存器的数量,引入了全新的 BPF 映射(map)存储,还在 4.x 内核中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制等。eBPF 的诞生是 BPF 技术的一个转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统。
demo
极客时间《ebpf核心技术实战》
eBPF 的开发和执行过程
- 使用 C 语言开发一个 eBPF 程序;
- 借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
- 通过 bpf 系统调用,把 BPF 字节码提交给内核;
- 内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
- 用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
使用c 开发一个eBPF 程序
// 在内核 eBPF 的虚拟机中执行
int hello_world(void *ctx){
// 输出一段字符串,由于 eBPF 运行在内核中,它的输出并不是通常的标准输出(stdout),而是内核调试文件 /sys/kernel/debug/tracing/trace_pipe
bpf_trace_printk("Hello, World!");
return 0;
}
使用 Python 和 BCC 库开发一个用户态程序。在运行的时候,BCC 会调用 LLVM,把 BPF 源代码编译为字节码,再加载到内核中运行。
#!/usr/bin/env python3
# 1) import bcc library
from bcc import BPF
# 2) load BPF program
# int bpf(int cmd, union bpf_attr *attr, unsigned int size);
b = BPF(src_file="hello.c")
# 3) attach kprobe, 将 BPF 程序挂载到内核探针(简称 kprobe),其中 do_sys_openat2() 是系统调用 openat() 在内核中的实现;
# attach_kprobe 内核跟踪事件,attach_uprobe用户跟踪,把加载后的程序跟具体的内核函数调用事件进行绑定,将 BPF 程序绑定到性能监控事件(perf event)。
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 4) read and print /sys/kernel/debug/tracing/trace_pipe
b.trace_print()
执行 eBPF 程序,eBPF 程序需要以 root 用户来运行
sudo python3 hello.py
以监听文件打开为例(跟踪openat 系统调用),eBPF 程序 写入数据到 eBPF map。以 bpf 开头的函数都是 eBPF 提供的辅助函数
// 包含头文件
#include <uapi/linux/openat2.h>
#include <linux/sched.h>
// 定义数据结构
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件 map
BPF_PERF_OUTPUT(events);
// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename, struct open_how *how){
struct data_t data = { };
// 获取PID和时间
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
// 获取进程名
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0){
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
// 提交性能事件 到 map
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
用户程度读取 BPF map
from bcc import BPF
# 1) load BPF program
b = BPF(src_file="trace-open.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 2) print header
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))
# 3) define the callback for perf event
start = 0
# 定义一个数据处理的回调函数,打印进程的名字、PID 以及它调用 openat 时打开的文件;
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# 4) loop with callback to print_event 定义了名为 “events” 的 Perf 事件map,而后通过一个循环调用 perf_buffer_poll 读取map的内容,并执行回调函数输出进程信息。
b["events"].open_perf_buffer(print_event)
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
工作原理
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
Linux 内核是如何实现 eBPF 程序的安全和稳定的呢?通常我们借助 LLVM 把编写的 eBPF 程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
- eBPF 程序不能随意调用内核函数,只能调用在 API 中定义的辅助函数;
- BPF 程序可以利用 BPF 映射(map)进行存储,BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态。eBPF 程序栈空间最多只有 512 字节,想要更大的存储,就必须要借助映射存储;
系统虚拟化基于 x86 或 arm64 等通用指令集,这些指令集足以完成完整计算机的所有功能。而为了确保在内核中安全地执行,eBPF 只提供了非常有限的指令集。这些指令集可用于完成一部分内核的功能,但却远不足以模拟完整的计算机。为了更高效地与内核进行交互,eBPF 指令还有意采用了 C 调用约定,其提供的辅助函数可以在 C 语言中直接调用,极大地方便了 eBPF 程序的开发。
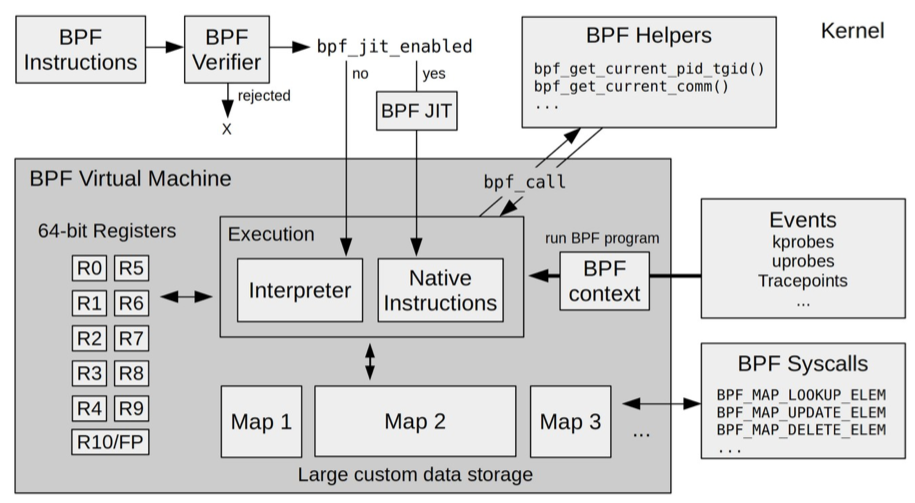
对于绑定性能监控(perf event)的内核实现原理,你也不需要详细了解,只需要知道它的具体功能,就足够我们掌握 eBPF 了。如果你对它的实现方法有兴趣的话,可以参考内核源码 perf_event_set_bpf_prog 的实现;而最终性能监控调用 BPF 程序的实现,则可以参考内核源码 kprobe_perf_func 的实现。
应用
请暂时抛弃使用 eBPF 取代服务网格和 sidecar 模式的幻想在过去,如果你想让应用程序处理网络数据包,那是不可能的。因为应用程序运行在 Linux 用户空间,它是不能直接访问主机的网络缓冲区。缓冲区是由内核管理的,受到内核保护,内核需要确保进程隔离,进程之间不能直接读取对方的网络数据包。正确的做法是,应用程序通过系统调用(syscall)来请求网络数据包信息,这本质上是内核 API 调用 —— 应用程序调用 syscall,内核检查应用程序是否有权限获得其请求的数据包;如果有,就把返回数据包。有了 eBPF 之后,应用程序不再需要 syscall,数据包不需要在内核空间和用户空间之间来回交互传递。而是我们将代码直接交给内核,让内核自己执行,这样就可以让代码全速运行,效率更高。eBPF 允许应用程序和内核以安全的方式共享内存,eBPF 允许应用程序直接向内核提交代码,目标都是通过超越系统调用的方式来实现性能提升。
因为我们直接将 eBPF 代码交给内核执行,这绕过了内核安全保护(如 syscall),内核将面临直接的安全风险。为了保护内核,所有 eBPF 程序要想运行都必须先通过一个验证器。但是要想自动验证程序是很困难的,验证器可能会过度限制程序的功能。比如 eBPF 程序不能是阻塞的,不能有无限循环,不能超过预定的大小;其复杂性也受到限制,验证器会评估所有可能的执行路径,如果 eBPF 程序不能在某些范围内完成,或者不能证明每个循环都有一个退出条件,那么验证器就不会允许该程序运行。有很多应用程序都违反了这些限制,要想将它们作为 eBPF 程序来运行的话,要么重写以满足验证器的需求,要么给内核打补丁,来绕过一些验证(这可能比较困难)。不过随着内核版本的升级,这些验证器也变得更加智能,限制也逐渐变得宽松,也有一些创造性的方法来绕过这些限制。但总的来说,eBPF 程序能做的事情非常有限。对于一些重量级事件的处理,例如处理全局范围内的 HTTP/2 流量,或者 TLS 握手协商不能在纯 eBPF 环境中完成。充其量,eBPF 可以做其中的一小部分工作,然后调用用户空间应用程序来处理对于 eBPF 来说过于复杂而无法处理的部分。基于 eBPF 的开源项目 eCapture 介绍:无需 CA 证书抓 https 网络明文通讯