前言
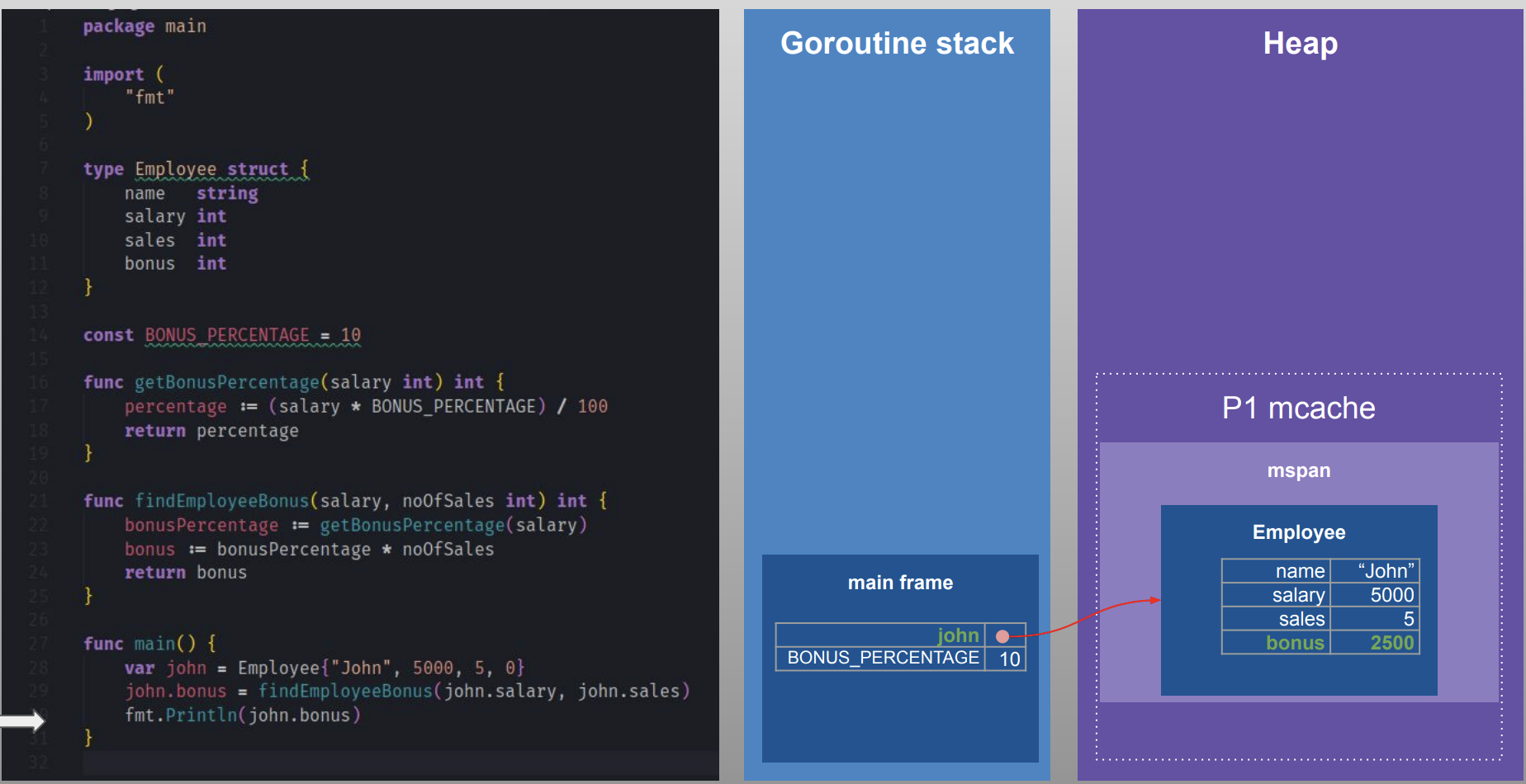
有关go内存是在堆上分配的,还是在栈上分配的,这个是在编译过程中,通过逃逸分析来确定的,其主体思想是(实际更复杂):假设有变量v,及指向v的指针p,如果p的生命周期大于v的生命周期,则v的内存要在堆上分配。我们可以使用 go build -gcflags="-m" 来观察逃逸分析的结果
package main
func main() {
var m = make([]int, 10240)
println(m[0])
}
$ go build -gcflags="-m" xx.go
xx.go: can inline main
xx.go: make([]int, 10240) escapes to heap
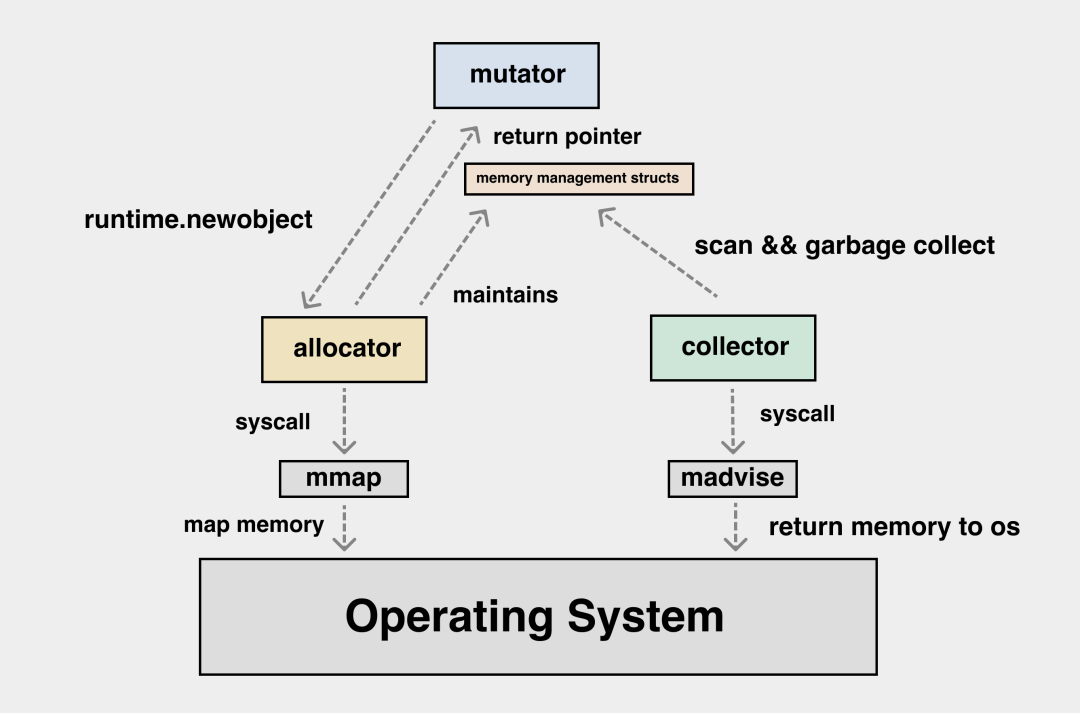
若对象被分配在栈上,它的管理成本就比较低,我们通过挪动栈顶寄存器就可以实现对象的分配和释放。若对象被分配在堆上,我们就要经历层层的内存申请过程。但这些流程对用户都是透明的。一切抽象皆有成本,这个成本要么花在编译期,要么花在运行期。mutator需要在堆上申请内存时,会由编译器帮程序员自动调用 runtime.newobject,这时 allocator 会使用 mmap 这个系统调用从操作系统中申请内存,若 allocator 发现之前申请的内存还有富余,会从本地预先分配的数据结构中划分出一块内存,并把它以指针的形式返回给应用。在内存分配的过程中,allocator 要负责维护内存管理对应的数据结构。而 collector 要扫描的就是 allocator 管理的这些数据结构,应用不再使用的部分便应该被回收,通过 madvise 这个系统调用返还给操作系统。
传统意义上的栈被 Go 的运行时霸占,不开放给用户态代码;而传统意义上的堆内存,又被 Go 运行时划分为了两个部分, 一个是 Go 运行时自身所需的堆内存,即堆外内存;另一部分则用于 Go 用户态代码所使用的堆内存,也叫做 Go 堆。 Go 堆负责了用户态对象的存放以及 goroutine 的执行栈。
mutator 申请内存是以应用视角来看问题。比如说,我需要的是某一个 struct 和某一个 slice 对应的内存,这与从操作系统中获取内存的接口之间还有一个鸿沟。这就需要由 allocator 进行映射与转换,将以“块”来看待的内存与以“对象”来看待的内存进行映射。
整体设计
图解 Go GCmutator 申请内存是以应用视角来看问题,我需要的是某一个 struct,某一个 slice 对应的内存,这与从操作系统中获取内存的接口(比如mmap)之间还有一个鸿沟。需要由 allocator 进行映射与转换,将以“块”来看待的内存与以“对象”来看待的内存进行映射。在现代 CPU 上,我们还要考虑内存分配本身的效率问题,应用执行期间小对象会不断地生成与销毁,如果每一次对象的分配与释放都需要与操作系统交互,那么成本是很高的。这需要在应用层设计好内存分配的多级缓存,尽量减少小对象高频创建与销毁时的锁竞争,这个问题在传统的 C/C++ 语言中已经有了解法,那就是 tcmalloc
内存分配算法 TCMalloc
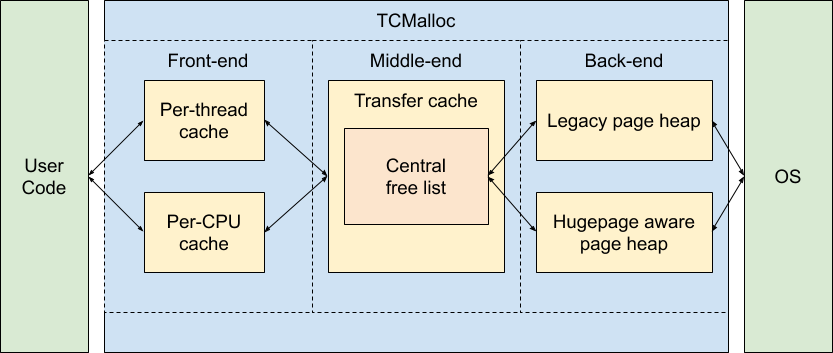
在 TCMalloc(Thread Cache Memory alloc) 18张图解密新时代内存分配器TCMalloc
五个基本概念
- Page,操作系统是按Page管理内存的,1Page为8KB
- Span 和 SpanList,一个Span是由N个Page构成,构成这个Span的N个Page在内存空间上必须是连续的,持有相同数量Page的Span构成一个双向链表SpanList
- Object,一个Span会被按照某个大小拆分为N个Objects,同时这N个Objects构成一个FreeList
TCMalloc三层逻辑架构
-
ThreadCache:线程缓存。 每一个线程都可以获得一个用于无锁分配小对象的缓存,这样可以让并行程序分配小对象(<=32KB)非常高效。ThreadCache对象里维护了一个属性list_类型是个数组,数组元素的类型是FreeList/ObjectList(Object构成),同时FreeList里的元素还具有以下特性:
- 索引值为1对应的ObjectList,该ObjectList的Object大小为8 Bytes;
- 索引值为2对应的ObjectList,该ObjectList的Object大小为16 Bytes;
- 以此类推,free_索引值为MaxNumber对应的ObjectList,该ObjectList的Object大小为MaxNumber Bytes;
- MaxNumber的值由kNumClasses决定
- CentralFreeList/CentralObjectList(TransferCacheManager):中央缓存,从中央缓存CentralObjectList获取缓存需要加锁。TransferCacheManager 有一个属性 freelist_ 是个数组,元素的类型是 CentralObjectList,CentralObjectList是一个数据结构,设定了有几个统一规格的span(构成SpanList),一个span 被拆成 objects_per_span_ 个 size_class_ 大小的 object
- PageHeap:堆内存,主要负责管理不同规格的Span,pageHeap对象里维护了一个属性free_类型是个数组,粗略看数组元素的类型是SpanList。同时free_这个数据的元素具有以下特性:
- 索引值为1对应的SpanList,该SpanList的Span都持有1Pages;
- 索引值为2对应的SpanList,该SpanList的Span都持有2Pages;
- 以此类推,free_索引值为MaxNumber对应的SpanList,该SpanList的Span都持有MaxNumber Pages;
- MaxNumber的值由kMaxPages决定
据我分析,基本思想:
- 整存零取,因为page 大小是定死的,一个object 很大跨page 了怎么办?所以不能直接基于page 管理object,于是提出了span的概念,span 的page 必须连续,也就是span 是一整块内存,基于span 零取object
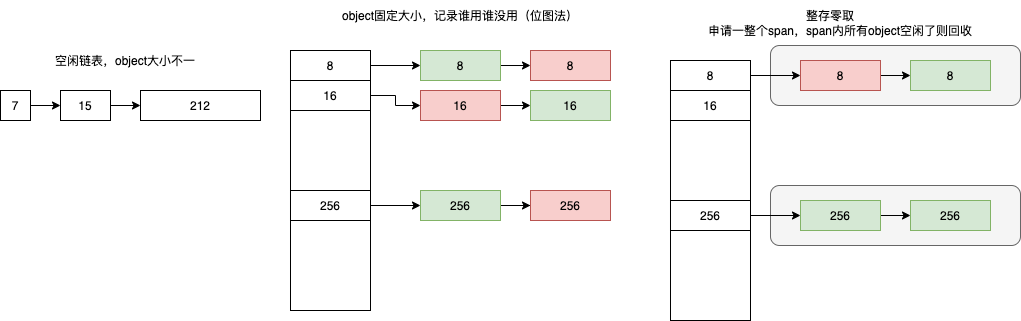
- 一个span 内的object 大小是固定的
- 所谓申请内存,是申请 size 大小的内存,参数是size。 ThreadCache 和 TransferCacheManager 维护了 特定几个大小的 object,要做的事情就是个根据size 尽快找到 对应的空闲object,如果没有,向os 申请内存。
多级分配
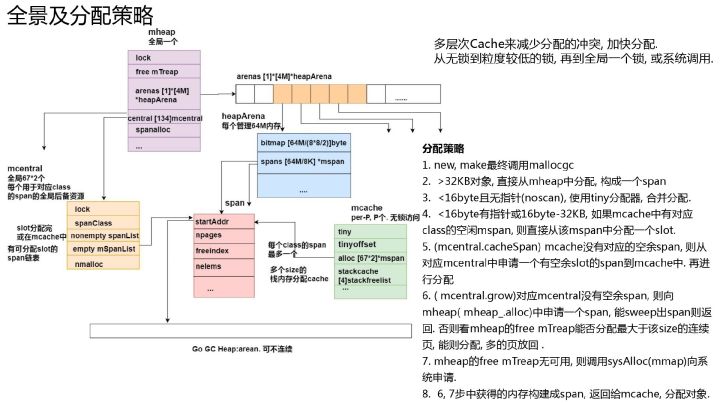
Go 的内存分配器基于 Thread-Cache Malloc (tcmalloc) ,tcmalloc 为每个线程实现了一个本地缓存, 区分了小对象(小于 32kb)和大对象分配两种分配类型,其管理的内存单元称为 span。但与 tcmalloc 存在一定差异。 这个差异来源于 Go 语言被设计为没有显式的内存分配与释放, 完全依靠编译器与运行时的配合来自动处理,因此也就造就了内存分配器、垃圾回收器两大组件。统一管理内存会提前分配或一次性释放一大块内存, 进而减少与操作系统沟通造成的开销,进而提高程序的运行性能。 支持内存管理另一个优势就是能够更好的支持垃圾回收。
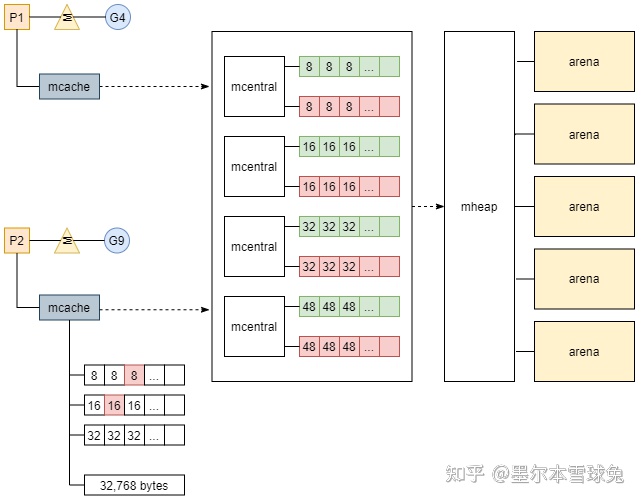
我们可以将内存分配的路径与 CPU 的多级缓存作类比,这里 mcache 内部的 tiny 可以类比为 L1 cache,而 alloc 数组中的元素可以类比为 L2 cache,全局的 mheap.mcentral 结构为 L3 cache,mheap.arenas 是 L4,L4 是以页为单位将内存向下派发的,由 pageAlloc 来管理 arena 中的空闲内存。如果 L4 也没法满足我们的内存分配需求,那我们就需要向操作系统去要内存了。
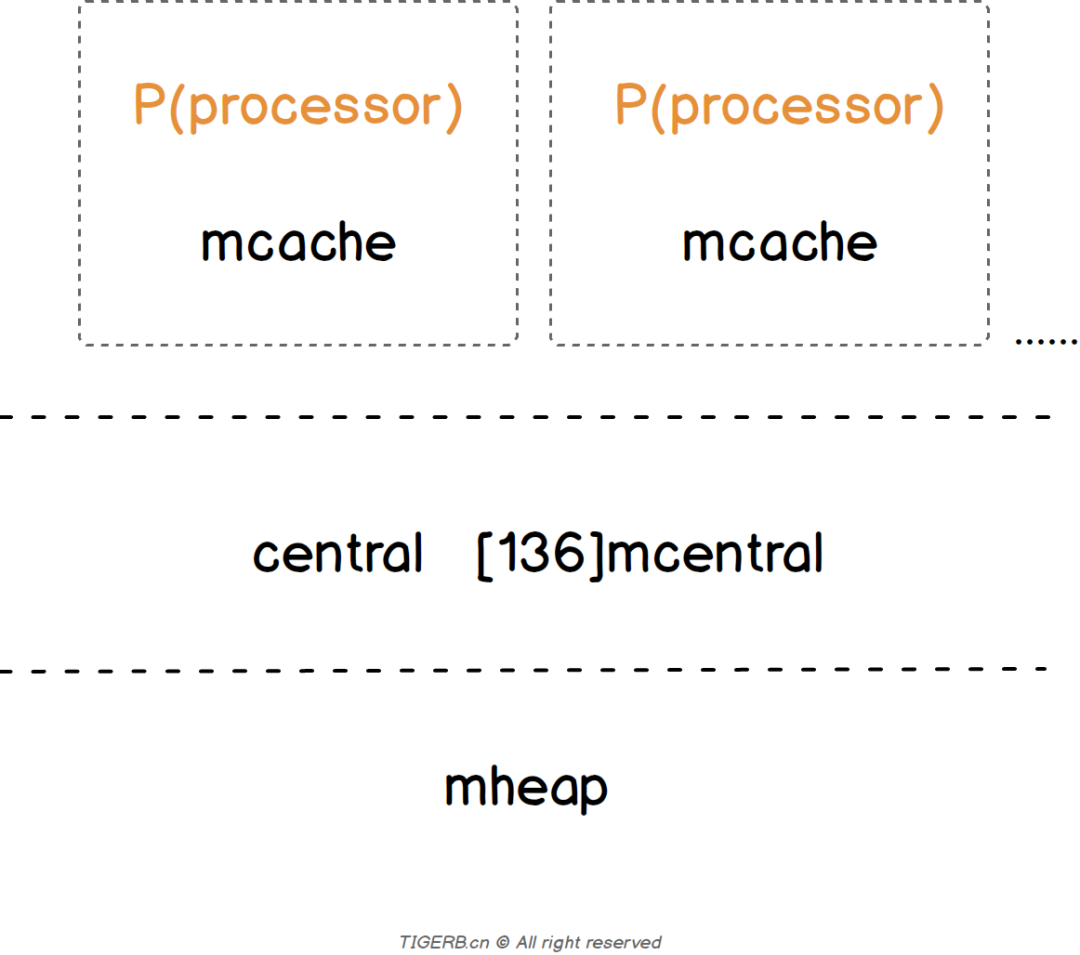
在 Go 语言中,根据对象中是否有指针以及对象的大小,将内存分配过程分为三类:
- tiny :size < 16 bytes && has no pointer(noscan);
-
small :has pointer(scan) (size >= 16 bytes && size <= 32 KB); - large :size > 32 KB。
| L1 | mcache.tiny | tiny 从此开始 |
| L2 | mcache.alloc[] | small 从此开始 |
| L3 | mcache.central | 全局的 |
| L4 | mcache.arenas | large 直接从此开始,以页为单位将内存向下派发的,由 pageAlloc 来管理 arena 中的空闲内存。 |
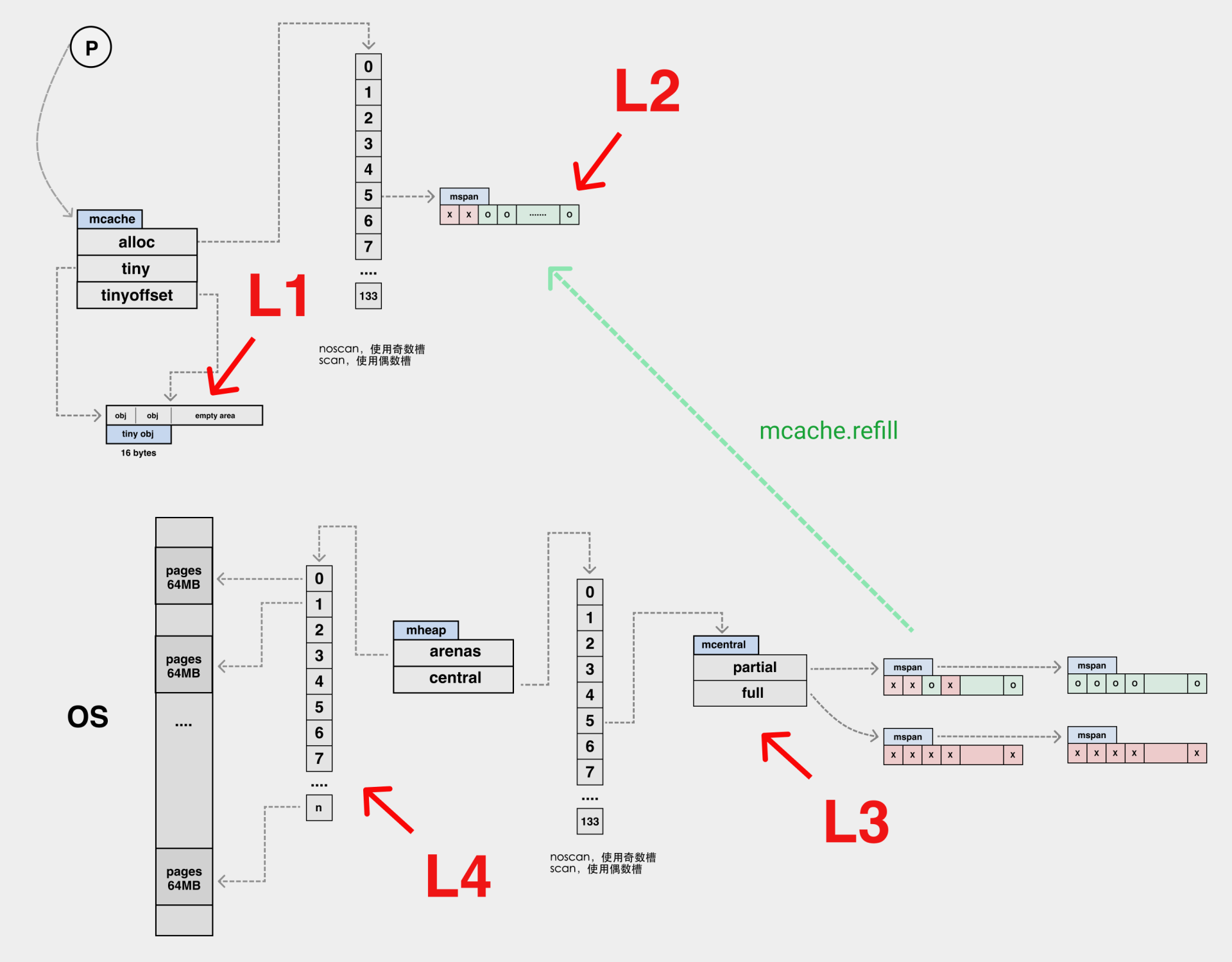
arenas 是 Go 向操作系统申请内存时的最小单位,每个 arena 为 64MB 大小,在内存中可以部分连续,但整体是个稀疏结构。单个 arena 会被切分成以 8KB 为单位的 page,一个或多个 page 可以组成一个 mspan,每个 mspan 可以按照 sizeclass 再划分成多个 element。同样大小的 mspan 又分为 scan 和 noscan 两种,分别对应内部有指针的 object 和内部没有指针的 object。
多级分配——另一种表述
分配的顺序从右向左,代价也就越来越大。 tiny和small 对象优先从白色区域 per-P 的 mcache 分配 span,这个过程不需要加锁(白色); 若失败则会从 mheap 持有的 mcentral 加锁获得新的 span,这个过程需要加锁,但只是局部(灰色); 若仍失败则会从右侧的 free 或 scav 进行分配,这个过程需要对整个 heap 进行加锁,代价最大(黑色)。
页管理
操作系统是按page管理内存的,同样Go语言也是也是按page管理内存的,1page为8KB,保证了和操作系统一致。page由 page allocator 管理,pageAlloc在 Go 语言中迭代了多个版本,从简单的 freelist 结构,到 treap 结构,再到现在最新版本的 radix 结构,它的查找时间复杂度也从 O(N) -> O(log(n)) -> O(1)。 内存按块管理,空闲块一般由空闲链表来管理:维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表。因为分配内存时需要遍历链表,所以它的时间复杂度就是 O(n),为了提高效率,将内存分割成多个链表,每个链表中的内存块大小相同(不同链表不同),申请内存时先找到满足条件的链表,再从链表中选择合适的内存块,减少了需要遍历的内存块数量。
数据结构
Go 的内存分配器主要包含以下几个核心组件:
- heapArena: 保留整个虚拟地址空间
- mheap:分配的堆,在页大小为 8KB 的粒度上进行管理
- mspan:是 mheap 上管理的一连串的页
- mcentral:收集了给定大小等级的所有 span
- mcache:为 per-P 的缓存。
Go 语言的内存分配器包含内存管理单元runtime.mspan、线程缓存runtime.mcache、中心缓存runtime.mcentral和页堆runtime.mheap几个重要组件
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
spanclass spanClass // size class and noscan (uint8)
...
allocBits *gcBits // 从 mspan 里分配 element ,就是将 mspan 对应 allocBits 中的对应 bit 位置一
gcmarkBits *gcBits // 实现 span 的颜色标记
}
9张图轻松吃透Go内存管理单元Go是按页page8KB为最小单位分配内存的吗?当然不是,如果这样的话会导致内存使用率不高。Go内存管理单元mspan通常由N个且连续的page组成,会把mspan再拆解为更小粒度的单位object。object和object之间构成一个链表(FreeList),object的具体大小由sizeclass决定,mspan结构体上维护一个sizeclass的字段(实际叫spanclass)。PS:mspan通常由N个且连续的page组成,所以可以视为一段连续内存,内部又按统一大小的object 分配,所以可以认为:mspan是 npages 整存,object 零取。
mspan 关键字段
- next、prev、list, mspan之间可以构成链表
- startAddr,mspan内存的开始位置,N个连续page内存的开始位置
- npages,mspan由几page组成
- freeindex,空闲object链表的开始位置
- nelems,一共有多少个object
- spanclass,决定object的大小、以及当前mspan是否需要垃圾回收扫描
- allocBits,从 mspan 里分配 element 时,我们只要将 mspan 中对应该 element 位置的 bit 位置一就可以了,其实就是将 mspan 对应 allocBits 中的对应 bit 位置一。
type mcache struct {
// Tiny allocator
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr
}
Golang为每个线程分配了span的缓存,即mcache,避免多线程申请内存时不断的加锁。当 mcache 没有可用空间时,从 mcentral 的 mspans 列表获取一个新的所需大小规格的 mspan。
type mcentral struct {
lock mutex // 互斥锁
spanclass spanClass // span class ID
nonempty mSpanList // non-empty 指还有空闲块的span列表
empty mSpanList // 指没有空闲块的span列表
nmalloc uint64 // 已累计分配的对象个数
}
从mcentral数据结构可见,每个mcentral对象只管理特定的class规格的span,事实上每种class都会对应一个mcentral。
Go 使用 mheap 对象管理堆,只有一个全局变量(mheap 也是go gc 工作的地方)。持有虚拟地址空间。mheap 存储了 mcentral 的数组。这个数组包含了各个的 span 规格的 mcentral。由于我们有各个规格的 span 的 mcentral,当一个 mcache 从 mcentral 申请 mspan 时,只需要在独立的 mcentral 级别中使用锁,其它任何 mcache 在同一时间申请不同大小规格的 mspan 互不影响。
当 mcentral 列表为空时,mcentral 从 mheap 获取一系列页用于需要的大小规格的 span。
type mheap struct {
lock mutex
spans []*mspan
bitmap uintptr //指向bitmap首地址,bitmap是从高地址向低地址增长的
arena_start uintptr //指示arena区首地址
arena_used uintptr //指示arena区已使用地址位置
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
源码分析
type p struct {
id int32
mcache *mcache
pcache pageCache
...
}
go 内存分配器细节补充
// go:noinline
func smallAllocation() *smallStruct {
return &smallStruct{}
}
// &smallStruct{} 对应汇编代码
LEAQ type."".smallStruct(SB), AX
MOVQ AX, (SP)
PCDATA $1, $0
CALL runtime.newobject(SB)
堆上所有的对象都会通过调用 runtime.newobject 函数分配内存,runtime.newobject 就是内存分配的核心入口,该函数会调用 runtime.mallocgc 分配指定大小的内存空间。
// src/runtime/malloc.go
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
mp := acquirem()
var c *mcache
if mp.p != 0 {
c = mp.p.ptr().mcache // 获取当前的 G所属的P
} else {
c = mcache0
}
var span *mspan
if size <= maxSmallSize {
if noscan && size < maxTinySize { // Tiny allocator.
...
span = c.alloc[tinySpanClass]
v := nextFreeFast(span)
x = unsafe.Pointer(v)
...
}else{
...
span = c.alloc[spc]
v := nextFreeFast(span)
x = unsafe.Pointer(v)
...
}
}else{
...
span = largeAlloc(size, needzero, noscan)
x = unsafe.Pointer(span.base())
...
}
}
内存模型/happen-before
Go 开发要了解的 1 个内存模型细节The Go memory model specifies the conditions under which reads of a variable in one goroutine can be guaranteed to observe values produced by writes to the same variable in a different goroutine. Go 内存模型规定了:“在一个 goroutine 中读取一个变量时,可以保证观察到不同 goroutine 中对同一变量的写入所产生的值” 的条件。PS: 也是约定了一些规则,与java类似