简介
背景材料
整体流程

该图是两个角色,并不准确,还未准确理解mydocker,mydocker runCommand进程,mydocker initCommand进程,以及用户自定义command的作用关系。但大体可以分为 mydocker 一方,容器一方。
据猜测应该是,mydocker runCommand 进程 启动 了 initCommand 进程(相当于 mydocker run 内部执行了 mydocker init),同时为两者沟通建立管道,并为其配置cgroup。
initComand 启动后挂载文件系统,从管道中读取用户输入的command,用户输入的command 顶替掉 initCommand
从图中可以看到,能在父进程的干的,就在父进程干了(不准确的说,runCommand 是“父进程”的父进程,父进程是initCommand的父进程)。比如提前预备好子进程的root目录,子进程只是change root 一下。比如配置父进程的namespace 和 cgroup,因为子进程会自动继承。 父进程 还负责 在子进程 退出时 进行子进程相关资源的清理工作。 go语言中
{
cmd:=NewProcess(xx) // 创建进程对象
if err:= cmd.Start();err != nil { // 启动子进程
log.Error(err)
}
... // 这里cmd.Process.pid 拿到子进程的pid 能干很多事,比如设置cgroup
cmd.Wait() // 该函数阻塞知道子进程退出,比如子进程命令敲入exit
... // 这里可以做一些 清理工作
}
镜像的来龙去脉
- 虚拟机启动时,是完全的全新启动内核,挂载rootfs及特定发行版对应的文件系统(比如ubuntu的ext4);
- 容器启动时,只是运行了一个进程
- mount namespace/changeroot 使得进程将某个目录作为其根目录
- UFS 使得多个容器可以共用镜像文件但不改变其内容,也不会相互影响
镜像是一个压缩后的文件夹
- 通过namespace,可以让容器工作在一个隔离的环境中。但用户输入的command 比如
/bin/sh仍然是宿主机上的可执行文件。(注意,此时只是新的mnt namespace,还没有change root) - 下载busybox 镜像,将其解压至目录
/root/busybox,会看到内容为bin dev etc home lib mnt opt proc bin sbin tmp ...changeroot
2019.3.13 补充:Mount Namespace 修改的,是容器进程对文件系统“挂载点”的认知。但是,这也就意味着,只有在“挂载”这个操作发生之后,进程的视图才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
- 启动带有namespace 隔离的进程,并将
/root/busybox作为其根目录。那么该进程运行的 可执行文件 便来自/root/busybox这片小天地了。 - 将
/root/busybox作为进程根目录之后,mount -t proc proc /procmount -t tmpfs dev /dev,proc 和 dev 都是临时数据,busybox 提供不了(或无需提供)。此时,跟一个容器就很像了:进程隔离,资源限制,所有的数据文件被限制在/root/busybox下。学名叫:一个有镜像的环境。此时,可以用centos 的内核跑出ubuntu的感觉。
联合挂载——不想让进程直接操作镜像文件
- 但是,
/root/busybox中的数据 都是busybox 镜像文件的内容,进程的运行会更改这些镜像文件。所以,aufs 终于可以登场了。学名叫:容器和镜像隔离。 -
镜像文件夹
/root/busybox,别名readOnlyLayer. 另创建一个/root/writeLayer作为writeLayer. 通过mount -t aufs -o dirs=/root/busybox:/root/writeLayer none /root/mnt挂到/root/mnt并将其作为 进程的根目录。 进程退出时,卸载/root/mnt,删除/root/writeLayer,/root/busybox独善其身。所谓的layer 就是一个个文件夹,不管是提供操作系统文件还是单纯提供一个挂载点,在root namespace 看是平级关系,在容器 namespace 看是有层次关系。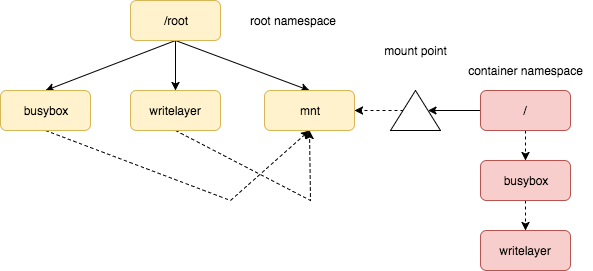
- 容器退出后,删除
/root/writeLayer,写入的数据全丢了,通常也不是我们想要的。因此在上述挂载完/root/mnt,执行mount -t aufs -o dirs=/root/hostVolume /root/mnt/containerVolume将主机的/root/hostVolume目录挂载到 主机的/root/mnt/containerVolume上,也就是容器的/containerVolume上。 - 所谓镜像打包,就是将 进程的 根目录
/root/mnt打包成tar文件。因为子进程挂载的 /proc,/dev 父进程也看不到,它们是内存数据,再加上打包时,通常已经退出了容器进程,所以不用担心 打包无效数据进去。
上述 过程 阐述了二层模式的镜像分层存储的原理, 虽然不是docker的最终形态,但非常直观的将 namespace、cgroup、aufs 等技术与docker 关联在了一起。
mount namespace 虽然很重要,但隔离本身并不能让容器工作,解压镜像、挂载/proc、专门的读写层、挂载volume 这系列技术的组合运用才是 关键。
几个问题
为什么tty 和 d 不能共存?
使用tty后,mydocker没有退出,其实是卡在哪里,等待子进程退出。但因为你将mydocker 的 stdin和stdout 也赋给了 子进程,你shell 输入的 stdin 数据会被 容器/子进程的/bin/sh 接收,子进程的输出stdout也 会展示到 当前的shell 上。你shell 敲入 exit,则子进程退出, 父进程 cmd.Wait()返回,代码执行完毕也退出了。
d 表示 mydocker/父进程退出时,子进程仍然可以运行。此时,父进程代码中,只能
{
...
if tty{
cmd.Wait()
}
}
即 父子进程 支持detach 之后,父进程 启动 子进程后会立即退出,自然也就不存在 通过 父进程的stdin 给 子进程 传命令的 可能了。
当我在说“进入容器“时,我在说什么?
- 你拿到了容器进程 关联的stdin,并且容器进程 能够处理stdin(比如各种bash),则你可以和容器 进程交互。
- 你新创建一个进程,并且它的namespace 与 容器中的进程一样。就像
docker exec -it containerName bash,本质就是为bash 进程赋予了containerName 一样的namesapce
从这个角度看, 容器中的进程有两类
- 容器启动进程及其 衍生的进程
- 人为设定的进程, 类似于容器 环境的 attacker
为什么通过子进程 实现command 的执行?
docker 中这样做有两个场景:
- docker run
- docker exec
类似docker ps 本质就是到特定 位置读取文件数据,而command 可以看简单,也可以很复杂(比如tomcat等),此时就需要单独的进程来执行。更重要的是,docker run 要为command 创建独立的环境, docker exec要为 command 赋予 特定的环境。当你使用 docker exec <existing-container><command> 在现有容器中执行命令时,实际上是在运行(即 create 然后 start)一个全新的容器,该容器恰好重用了目标容器的所有命名空间
停止容器的本质是什么?
以daemon 方式启动容器后,docker 在创建 容器进程后 就退出了,容器进程 此时和 linux pid=1 进程为父子关系。docker stop 进程与 容器进程 没啥关系。docker stop 的工作 就是找到 容器进程的 pid,向其发送 sigterm(你自己 kill -TERM pid也可以), 并更改容器状态文件。
容器网络
linux 实际是通过 网络设备 去操作和使用网卡的,系统装了一个网卡之后会为其 生成一个网络设备实例, 比如eth0(注意,这是一个”网络设备“,不是网卡)。而随着网络虚拟化技术的发展,Linux 支持创建出虚拟化的设备, 可以通过虚拟化设备的组合实现多种多样的功能和网络拓扑。
eth0 在linux中 就是一个 struct device , 每一个struct device 都有一个irq(中断号)。网络数据到达,触发中断,执行网卡驱动程序,根据中断号找到 struct device,从下到上执行 网络协议栈 流程,参见Linux网络源代码学习
此处有几个基本抽象
- 网络
type Network struct{ Name string // 网络名 IpRange *net.IPNet // 地址段 Driver string // 网络驱动名 } - 网络端点
type Endpoint struct{ ID string, Device netlink.Veth IPAddress net.IP MacAddress net.HardwareAddr PortMapping []string Network *Network } - 网络驱动
type NetworkDriver interface{ Name() string Create(subnet string,name string)(*Network,error) Delete(network Network) error Connect(network *Network,endpoint * Endpoint) error Disconnect(network *Network,endpoint * Endpoint) error } - ipam
type IPAM struct{ ... } func (ipam *IPAM)Allocate(subnet *net.IPNet)(ip net.IP,err error) func (ipam *IPAm)Release(subnet *net.IPNet,ipaddr *net.IP) error从中可以看到
- 网络信息的dump,就是将 Network json化并写入文件中
-
对于bride network driver
- 网络的创建 就是调用IPAM 获取网关地址,创建一个网桥(包括创建和配置网桥,设置iptables 规则)
- 网络的删除 就是删除 网桥
-
Connect 操作的步骤
- 创建veth
- 挂载一端到Bridge上
- 将另一端移动到netns 中
- 设置另一端的ip 地址
- 设置netns中的路由
- 设置端口映射
- 网络的生命周期 和 容器是不同的,网络也是mydocker 数据(也可以叫资源)管理的一部分。所以此处 网络的抽象很了不起,Create和Delete 用于管理网路的生命周期(还有
mydocker network ls),Connect和Disconnect 用于 和容器生命周期的交互。
mydocker 与 docker 区别
- mydocker commond 都是直接执行 代码,而docket command 实际是 docker client 发送命令到 dockerd或后来的 containerd
小结
我们常说,docker的核心技术是namespace、cgroup、aufs。具体的说,光namespace,没有其他“微操”,比如veth pair 也是很尴尬的。《自己动手写docker》 提供了一个很有意思的线:
- 光有namespace,进程什么样
- namespace + cgroup + base image files + change root 是啥效果
- 加上aufs 呢
- 数据持久化呢
- 后台运行呢
- 排查调错呢
我们有机会看到:从无到有,每扩充一个特性,“容器”是个什么样子。
其它
Docker:一场令人追悔莫及的豪赌 要点如下:
-
将所有依赖关系、一切必要配置乃至全部必要的资源都塞进同一个二进制文件,从而简化整体系统资源机制。 如果具备这种能力,docker 便不是必要的。
- 静态链接库方式。一些语言,比如go,可以将依赖一起打包,生成一个毫无依赖的二进制文件。
- macos 则从 更广泛的意义上实现了 该效果
- Docker 的重点 不在于 提供可移植性、安全性以及资源管理与编排能力,而是 标准化。docker 做的事情以前各种运维工程师也在做,只是在A公司的经验无法复制到B公司上。
- 在我看来,Docker有朝一日将被定性为一个巨大的错误。其中最强有力的论据在于,即使最终成为标准、始终最终发展成熟,Docker也只是为科技行业目前遭遇的种种难题贴上一张“创可贴”
- Kubernetes is a complex system. It does a lot and brings new abstractions. Those abstractions aren’t always justified for all problems. I’m sure that there are plenty of people using Kubernetes that could get by with something simpler.
- That being said, I think that, as engineers, we tend to discount the complexity we build ourselves vs. complexity we need to learn. 个人也觉得 k8s 管的太宽了,实现基本功能,外围的我们自己做,也比学它的弄法要好。
- 文章的后半部分基本都是吐槽,没啥实质的内容。