简介
CPU 和 GPU - 异构计算的演进与发展世界上大多数事物的发展规律是相似的,在最开始往往都会出现相对通用的方案解决绝大多数的问题,随后会出现为某一场景专门设计的解决方案,这些解决方案不能解决通用的问题,但是在某些具体的领域会有极其出色的表现。
GPU
各种游戏里面的人物的脸,并不是那个相机或者摄像头拍出来的,而是通过多边形建模(Polygon Modeling)创建出来的。而实际这些人物在画面里面的移动、动作,乃至根据光线发生的变化,都是通过计算机根据图形学的各种计算,实时渲染出来的。
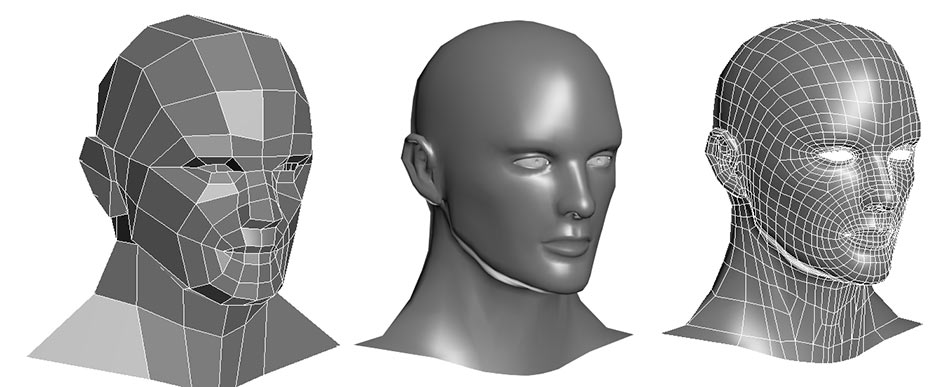
图像进行实时渲染的过程,可以被分解成下面这样 5 个步骤:
- 顶点处理(Vertex Processing)。构成多边形建模的每一个多边形呢,都有多个顶点(Vertex)。这些顶点都有一个在三维空间里的坐标。但是我们的屏幕是二维的,所以在确定当前视角的时候,我们需要把这些顶点在三维空间里面的位置,转化到屏幕这个二维空间里面。这个转换的操作,就被叫作顶点处理。这样的转化都是通过线性代数的计算来进行的。可以想见,我们的建模越精细,需要转换的顶点数量就越多,计算量就越大。而且,这里面每一个顶点位置的转换,互相之间没有依赖,是可以并行独立计算的。
- 图元处理。把顶点处理完成之后的各个顶点连起来,变成多边形。其实转化后的顶点,仍然是在一个三维空间里,只是第三维的 Z 轴,是正对屏幕的“深度”。所以我们针对这些多边形,需要做一个操作,叫剔除和裁剪(Cull and Clip),也就是把不在屏幕里面,或者一部分不在屏幕里面的内容给去掉,减少接下来流程的工作量。
- 栅格化。我们的屏幕分辨率是有限的。它一般是通过一个个“像素(Pixel)”来显示出内容的。对于做完图元处理的多边形,把它们转换成屏幕里面的一个个像素点。每一个图元都可以并行独立地栅格化。
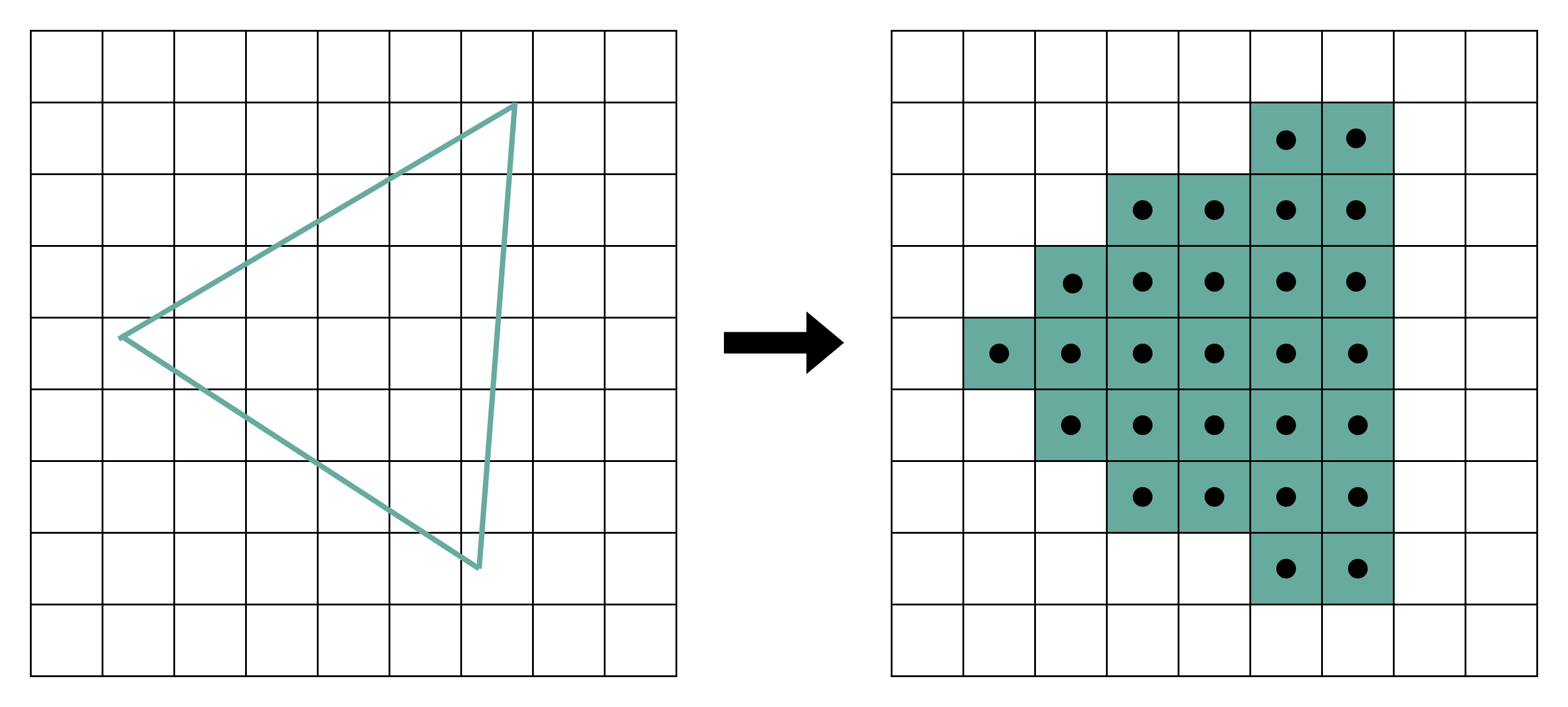
- 片段处理。在栅格化变成了像素点之后,我们的图还是“黑白”的。我们还需要计算每一个像素的颜色、透明度等信息,给像素点上色。
- 像素操作。把不同的多边形的像素点“混合(Blending)”到一起。可能前面的多边形可能是半透明的,那么前后的颜色就要混合在一起变成一个新的颜色;或者前面的多边形遮挡住了后面的多边形,那么我们只要显示前面多边形的颜色就好了。最终,输出到显示设备。
经过这完整的 5 个步骤之后,完成了从三维空间里的数据的渲染,变成屏幕上你可以看到的 3D 动画了。称之为图形流水线(Graphic Pipeline)。

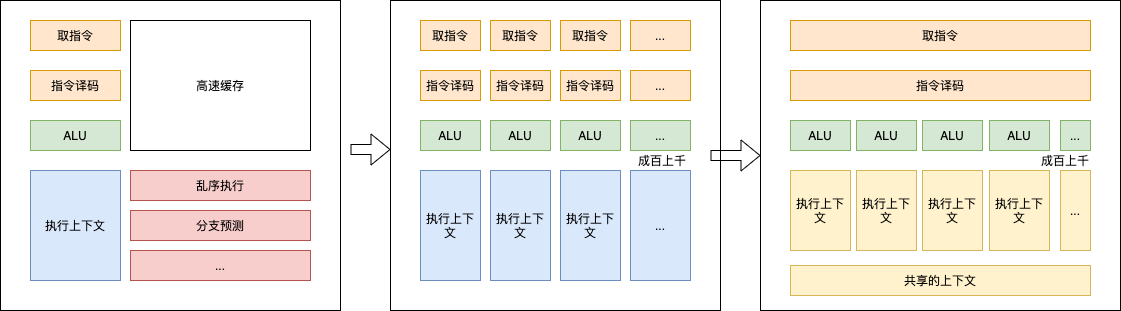
现代 CPU 里的晶体管变得越来越多,越来越复杂,其实已经不是用来实现“计算”这个核心功能,而是拿来实现处理乱序执行、进行分支预测,以及高速缓存部分。而在 GPU 里,这些电路就显得有点多余了,GPU 的整个处理过程是一个流式处理(Stream Processing)的过程。因为没有那么多分支条件,或者复杂的依赖关系,我们可以把 GPU 里这些对应的电路都可以去掉,做一次小小的瘦身,只留下取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存就好了。
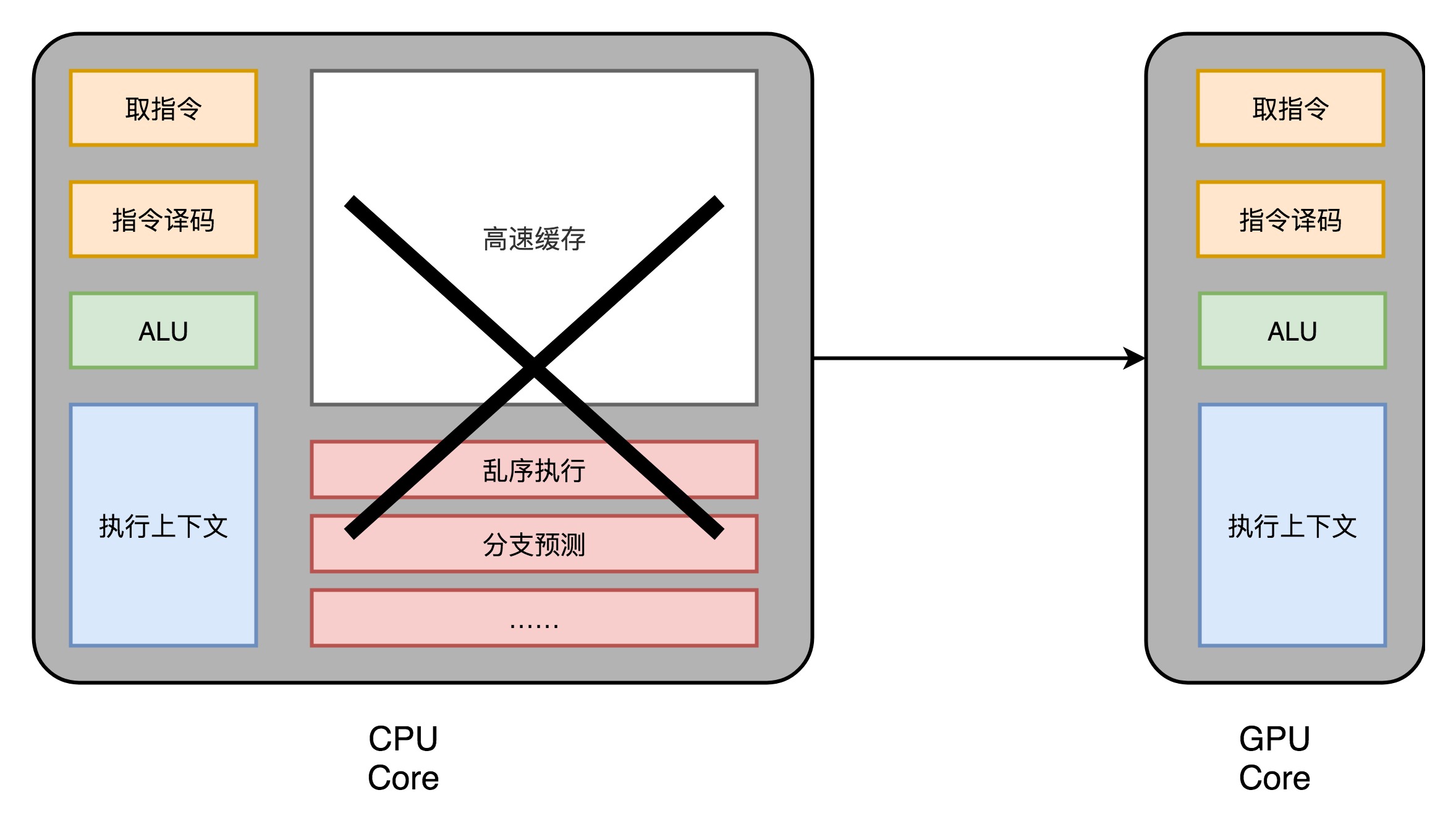
于是,我们就可以在一个 GPU 里面,塞很多个这样并行的 GPU 电路来实现计算,就好像 CPU 里面的多核 CPU 一样。和 CPU 不同的是,我们不需要单独去实现什么多线程的计算。因为 GPU 的运算是天然并行的。无论是对多边形里的顶点进行处理,还是屏幕里面的每一个像素进行处理,每个点的计算都是独立的。
一方面,GPU 是一个可以进行“通用计算”的框架,我们可以通过编程,在 GPU 上实现不同的算法。另一方面,现在的深度学习计算,都是超大的向量和矩阵,海量的训练样本的计算。整个计算过程中,没有复杂的逻辑和分支,非常适合 GPU 这样并行、计算能力强的架构。
为什么深度学习需要使用GPU
为什么深度学习需要使用GPU?相比cpu,gpu
- gpu核心很多,上千个。
- gpu内存带宽更高,速度快就贵,所以显存容量一般不大。因为 CPU 首先得取得数据, 才能进行运算, 所以很多时候,限制我们程序运行速度的并非是 CPU 核的处理速度, 而是数据访问的速度。
- 控制流,cpu 控制流很强,alu 只占cpu的一小部分。gpu 则要少用控制语句。现代 CPU 里的晶体管变得越来越多,越来越复杂,其实已经不是用来实现“计算”这个核心功能,而是拿来实现处理乱序执行、进行分支预测,以及高速缓存。GPU 只有 取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存
- 编程,cpu 是各种编程语言,编译器成熟。
CPU / GPU原理与 CUDAGPU 一开始是没有“可编程”能力的,程序员们只能够通过配置来设计需要用到的图形渲染效果(图形加速卡)。在游戏领域, 3D 人物的建模都是用一个个小三角形拼接上的, 而不是以像素的形式, 对多个小三角形的操作, 能使人物做出多种多样的动作, 而 GPU 在此处就是用来计算三角形平移, 旋转之后的位置。为了提高游戏的分辨率, 程序会将每个小三角形细分为更小的三角形,每个小三角形包含两个属性, 它的位置和它的纹理。在游戏领域应用的 GPU 与科学计算领域的 GPU 使用的不同是, 当通过 CUDA 调用 GPU 来进行科学计算的时候, 计算结果需要返回给 CPU, 但是如果用 GPU 用作玩游戏的话, GPU 的计算结果直接输出到显示器上, 也就不需要再返回到 CPU。
深度学习的模型训练,指的是利用数据通过计算梯度下降的方式迭代地去优化神经网络的参数,最终输出网络模型的过程。在这个过程中,通常在迭代计算的环节,会借助 GPU 进行计算的加速。
GPU 架构
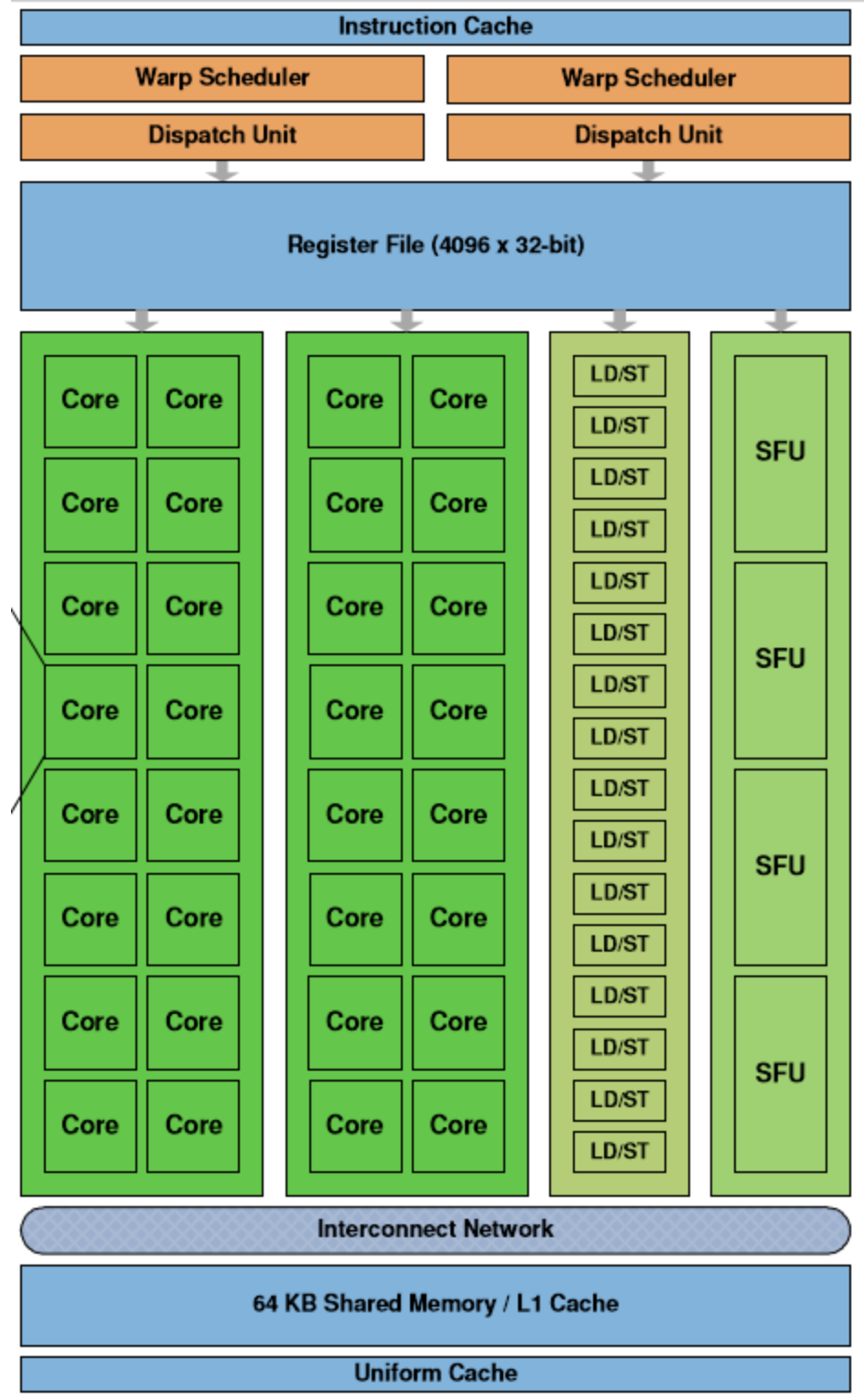
流式多处理器(Streaming Multiprocessor、SM)是 GPU 的基本单元,每个 GPU 都由一组 SM 构成,SM 中最重要的结构就是计算核心 Core
- 线程调度器(Warp Scheduler):线程束(Warp)是最基本的单元,每个线程束中包含 32 个并行的线程,它们使用不同的数据执行相同的命令,调度器会负责这些线程的调度;
- 访问存储单元(Load/Store Queues):在核心和内存之间快速传输数据;
- 核心(Core):GPU 最基本的处理单元,也被称作流处理器(Streaming Processor),每个核心都可以负责整数和单精度浮点数的计算;
- 特殊函数的计算单元(Special Functions Unit、SPU)
- 存储和缓存数据的寄存器文件(Register File)
- 共享内存(Shared Memory)
与个人电脑上的 GPU 不同,数据中心中的 GPU 往往都会用来执行高性能计算和 AI 模型的训练任务。正是因为社区有了类似的需求,Nvidia 才会在 GPU 中加入张量(标量是0阶张量,向量是一阶张量, 矩阵是二阶张量)核心(Tensor Core)18专门处理相关的任务。张量核心与普通的 CUDA 核心其实有很大的区别,CUDA 核心在每个时钟周期都可以准确的执行一次整数或者浮点数的运算,时钟的速度和核心的数量都会影响整体性能。张量核心通过牺牲一定的精度可以在每个时钟计算执行一次 4 x 4 的矩阵运算。PS:就像ALU 只需要加法器就行了(乘法指令转换为多个加法指令),但为了提高性能,直接做了一个乘法器和加法器并存。
CPU 与GPU 协作
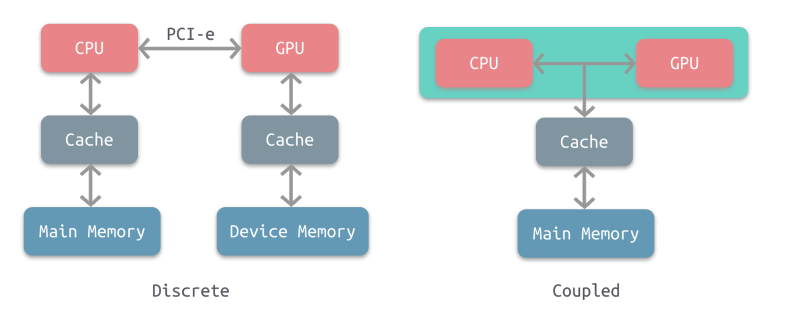
大多数采用的还是分离式结构,AMD 的 APU 采用耦合式结构,目前主要使用在游戏主机中,如 PS4。
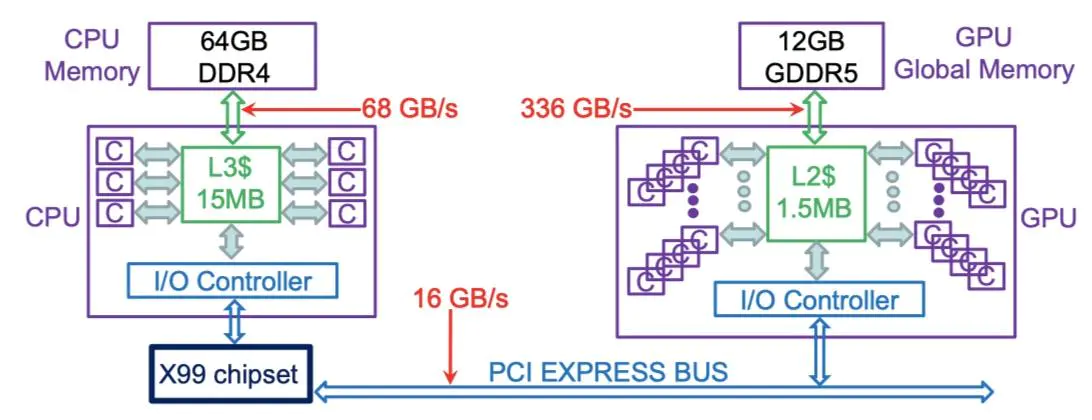
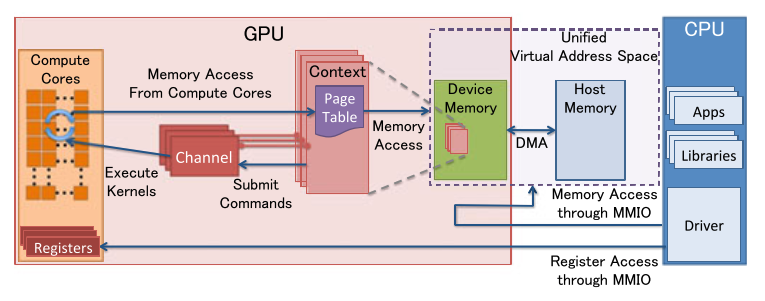
- 锁页:GPU 可以直接访问 CPU的内存。出于某些显而易见的原因,cpu 和gpu 最擅长访问自己的内存,但gpu 可以通过DMA 来访问cpu 中的锁页内存。锁页是操作系统常用的操作,可以使硬件外设直接访问内存,从而避免过多的复制操作。”被锁定“的页面被os标记为不可被os 换出的,所以设备驱动程序在给这些外设编程时,可以使用页面的物理地址直接访问内存。PS:部分内存的使用权暂时移交给设备。
- 命令缓冲区:CPU 通过 CUDA 驱动写入指令,GPU 从缓冲区 读取命令并控制其执行,
- CPU 与GPU 同步:cpu 如何跟踪GPU 的进度
对于一般的外设来说,驱动程序提供几个api接口,约定好输入和输出的内存地址,向输入地址写数据,调接口,等中断,从输出地址拿数据。输出数据地址 command_operation(输入数据地址)。gpu 是可以编程的,变成了输出数据地址 command_operation(指令序列,输入数据地址)
系统的三个要素: CPU,内存,设备。CPU 虚拟化由 VT-x/SVM 解决,内存虚拟化由 EPT/NPT 解决,设备虚拟化呢?它的情况要复杂的多,不管是 VirtIO,还是 VT-d,都不能彻底解决设备虚拟化的问题。除了这种完整的系统虚拟化,还有一种也往往被称作「虚拟化」的方式: 从 OS 级别,把一系列的 library 和 process 捆绑在一个环境中,但所有的环境共享同一个 OS Kernel。
不考虑嵌入式平台的话,那么,GPU 首先是一个 PCIe 设备。GPU 的虚拟化,还是要首先从 PCIe 设备虚拟化角度来考虑。一个 PCIe 设备,有什么资源?有什么能力?
- 2 种资源: 配置空间;MMIO(Memory-Mapped I/O)
- 2 种能力: 中断能力;DMA 能力

一个典型的 GPU 设备的工作流程是:
- 应用层调用 GPU 支持的某个 API,如 OpenGL 或 CUDA
- OpenGL 或 CUDA 库,通过 UMD (User Mode Driver),提交 workload 到 KMD (Kernel Mode Driver)
- Kernel Mode Driver 写 CSR MMIO,把它提交给 GPU 硬件
- GPU 硬件开始工作… 完成后,DMA 到内存,发出中断给 CPU
- CPU 找到中断处理程序 —— Kernel Mode Driver 此前向 OS Kernel 注册过的 —— 调用它
- 中断处理程序找到是哪个 workload 被执行完毕了,…最终驱动唤醒相关的应用
本质上GPU 还是一个外设,有驱动程序(分为用户态和内核态)和API,用户程序 ==> API ==> CPU ==> 驱动程序 ==> GPU ==> 中断 ==> CPU.
warp(gpu的一个单位)是典型的单指令多线程(SIMT,SIMD单指令多数据的升级)的实现,也就是32个线程同时执行的指令是一模一样的,只是线程数据不一样,这样的好处就是一个warp只需要一个套逻辑对指令进行解码和执行就可以了,芯片可以做的更小更快,只所以可以这么做是由于GPU需要处理的任务是天然并行的。
GPU 编程
CUDA编程入门极简教程2006年,NVIDIA公司发布了CUDA,CUDA是建立在NVIDIA的CPUs上的一个通用并行计算平台和编程模型。CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。在CUDA中,host和device是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。
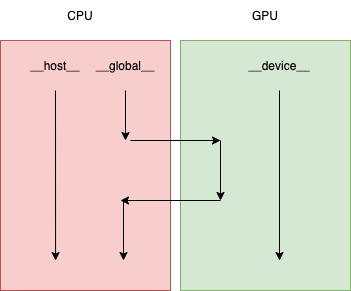
device 函数和global函数因为需要在GPU上运行,因此不能调用常见的一些 C/C++ 函数(因为这些函数没有对应的 GPU 实现)。
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
| global | 设备端执行 | 可以从主机调用也可以从某些特定设备调用 | 异步操作,host 将并行计算任务发射到GPU的任务调用单之后,不会等待kernel执行完就执行下一步 |
| device | 设备端执行 | 设备端调用 | |
| host | 主机端执行 | 主机调用 |
典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
矩阵加法示例
// __global__ 表示在device上执行,从host中调用
// 两个向量加法kernel,grid和block均为一维
__global__ void add(float* x, float * y, float* z, int n){
// 获取全局索引
int index = threadIdx.x + blockIdx.x * blockDim.x;
// 步长
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride){
z[i] = x[i] + y[i];
}
}
int main(){
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请host内存
float *x, *y, *z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nBytes);
z = (float*)malloc(nBytes);
// 初始化数据
for (int i = 0; i < N; ++i){
x[i] = 10.0;
y[i] = 20.0;
}
// 申请device内存
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
// 将host数据拷贝到device
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(d_x, d_y, d_z, N);
// 将device得到的结果拷贝到host
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;
// 释放device内存
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
// 释放host内存
free(x);
free(y);
free(z);
return 0;
}
如何在 CPU 之上调用 GPU 操作?可以通过调用 global 方法来在GPU之上执行并行操作。我的第一份CUDA代码 - xcyuyuyu的文章 - 知乎