简介
弹性背景
实现弹性训练需要面对哪些挑战和难点
- 需要一个节点/进程之间彼此发现的机制。
- 如何处理成员变更
- 如何捕获单个进程训练失败,如何在单个节点上管理所有训练进程。
- 如何与现有训练代码集成。
train_script 的守护者elastic agent
python -m torch.distributed.run train_script.py 对于每一个node 有两个角色
- run.py 负责启动 elastic agent
- elastic agent 负责启动 train_script.py, 并给train_script.py 传递必要的参数(环境变量或参数形式,由脚本的获取方式决定)。
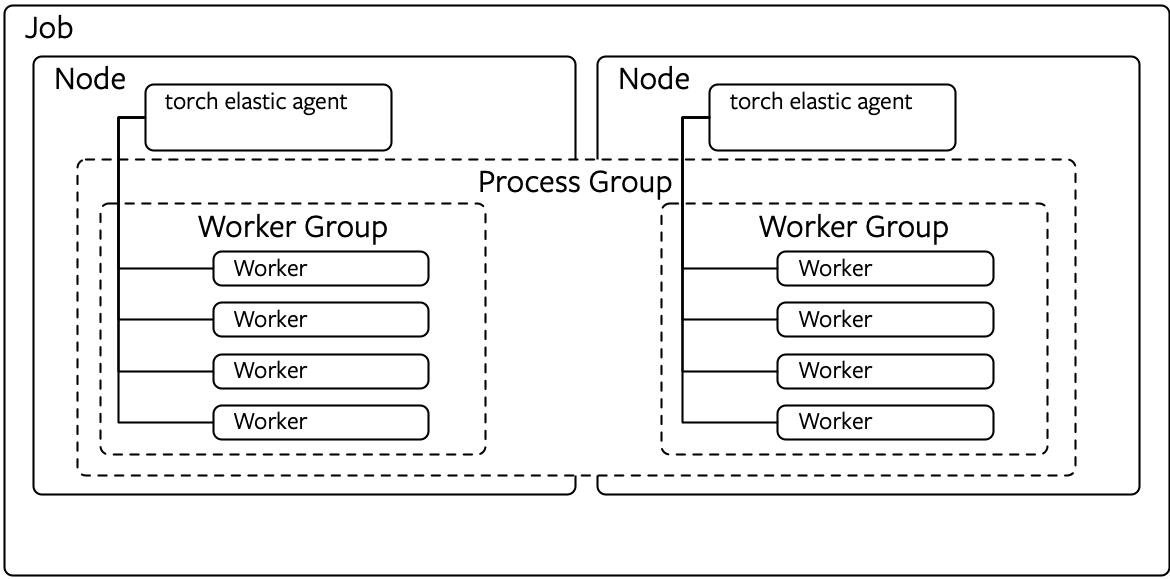
每个Node 上运行一个 Agent,Agent是一个worker manager,包含一个 rendezous,负责分布式协商,Agent 同时负责启动workers,监控 workers,捕获失效 workers,如果有故障/新加入worker,则重启 worker。Agent负责维护 WORLD_SIZE 以及 RANK 信息。用户不需要再手动提供,Agent会自动处理这些。
PyTorch 分布式之弹性训练(1) — 总体思路PyTorch Elastic Trainer (PET) 提供了一个可以用容错和弹性方式跨集群来训练模型的框架。PS: 还与Horovod 进行了对比。
- PET 使用了一个名为elastic-agent的新进程,每个节点有一个独立的elastic-agent。每个代理进程只负责管理该节点的一组本地工作进程,并与本作业其他节点上的弹性代理一起协调来确定进程组成员身份的变化。
- 成员变更的处理方式如下:
- 当一个工作进程失败时,管理它的弹性代理会杀死该节点上的所有worker,然后与其他代理建立一个集合操作(rendezvous),并使用新的集合信息来重启worker。
- 当代理以非零错误代码退出时,应该由上层调度模块(例如 Kubernetes)来重新启动代理(同理,此代理将重新启动它负责的所有worker)。
- 相同的恢复机制也适用于节点级故障。编排工具(诸如 Kubernetes )会调度作业以便job可以使用最小数目的代理副本运行,然后每个代理将依次编排用户的训练脚本。
- PET 尝试维护工作进程的数量,使它们保持在作业所需的
[min,max]范围内。一旦发生故障或成员变更,所有幸存的worker将立即被杀掉。所以用户需要手动地处理 checkpoint,定期保存你的工作进度,来保证重启后训练能够继续下去。PET不强制指定如何管理checkpoints。应用编写者可以任意使用torch.save 和 torch.load 或更高层次的框架如PyTorch Lightening 进行处理,checkpoint的频率应取决于用户job对于失败的容忍度。
rendezvous/集会机制/实现服务发现
Agent 是具体节点上的后台进程,是独立个体。需要一个机制来完成 worker 之间的相互发现,变更同步等等(WORLD_SIZE 和 RANK 这些信息其实也需要多个节点同步才能确定),这就是下面的 Rendezvous 概念。
深度学习分布式训练框架 horovod (3) — Horovodrun背后做了什么Gloo 机制工作时,需要从env 中获取到 RendezvousServer 信息以便进行 Collective communication
设计
Rendezvous 负责集群逻辑,保证节点之间对于”“有哪些节点参与训练”达成强一致共识。
- 每一个 Agent 内部包括一个 Rendezvous handler,这些 handler 总体上构成了一个 Rendezvous 集群,从而构成了一个 Agent 集群。
- Rendezvous 完成之后,会创建一个共享键值存储(shared key-value store),这个store实现了一个torch.distributed.Store API。此存储仅由已完成Rendezvous的成员共享,它旨在让Torch Distributed Elastic在初始化作业过程之中交换控制和数据信息。
- Rendezvous 负责在每个agent之上维护当前 group 所有相关信息。每个 agent 之上有一个 rendezvous,它们会互相通信,总体维护一套信息,这些信息存储在上面提到的Store 之中。
- Rendezvous 负责集群逻辑相关,比如新加入节点,移除节点,分配rank等等。
PyTorch 分布式之弹性训练(4)—Rendezvous 架构和逻辑Rendezvous会提供以下细分功能。
- Barrier, 执行会合的节点将全部阻塞到 rendezvous 完成,即至少有min个节点(针对同一作业)已加入到Barrier,这也意味着对于固定大小的节点数目,barrier是不必要的。在达到”min”数量后,rendezvous 不会立刻宣布完成,而是会等待额外的一小段时间,这用来保证rendezvous不会”过快”完成,因为如果立刻完成,就会错过那些加入时只慢了一点点的节点。当然如果在Barrier处聚集了max个节点,则rendezvous立即完成。另外,还有一个总超时时间配置 :如果在超时时间之内 min个节点一直没有达到,则会导致 rendezvous 失败,这是一个简单的故障安全(fail-safe)解决方案,用来帮助释放部分分配的作业资源,防止资源浪费。
- 排他性(Exclusivity),如果一组节点已经完成rendezvous(可能已经在训练),那么其他试图加入的”迟到”节点只会被认为是等待状态,且必须等到现有rendezvous被结束。
- 一致性(Consistency),rendezvous完成后,其所有成员将对工作成员资格以及每个人在其中的角色(role)达成共识。此角色(role)使用一个介于 0 ~ world size 之间的整型来表示,被称之为rank。请注意,rank是不稳定的,比如,同一个的节点在下一次(重新)rendezvous中可能被分配了不同的rank。
- 在 rendezvous 过程中有容错机制:
- 在开始join rendezvous 和 rendezvous 完成之间,如果有进程崩溃(或网络故障等),就会自动引发一个re-rendezvous,剩余健康节点会自动重组。
- 节点也可能在rendezvous 完成后失败(或被其他节点观察到失败),这个场景由Torch Distributed Elastic train_loop 负责,也会触发一个re-rendezvous,训练过程不会中断。
RendezvousHandler
RendezvousHandler = 类似rpc 框架中的注册中心 + 协商逻辑,必要时还要自己 启动注册中心(后面的TCPStore),层层抽象将注册中心的kv 操作 ==> state 操作(Backend) ==> 注册、发现、rank/world_size 协商。PyTorch 分布式之弹性训练(5)—Rendezvous 引擎
Rendezvous 的支撑系统
- RendezvousParameters ,构建RendezvousHandler所需参数。
- RendezvousSettings ,用来存储rendezvous的配置,可以理解为静态元信息。
- _RendezvousState 是rendezvous的状态,是动态信息,每一个 node 都会维护一个本地 state。
- _NodeDesc 是rendezvous的一个节点。
- backend, RendezvousBackend
# /pytorch/torch/distributed/elastic/rendezvous/api.py
# rdzv backend: etcd/etcd-v2/c10d/static
class RendezvousHandler(ABC):
def next_rendezvous(self,) -> Tuple[Store, rank, world_size] # 注册、发现、协商都得用它
def get_backend(self) -> str
def is_closed(self) -> bool
def set_closed(self)
def num_nodes_waiting(self) -> int
def get_run_id(self) -> str
def shutdown(self) -> bool # 监听worker 失效后关闭 本轮rendezvous
pytoch 针对 RendezvousHandler(有多种实现 DynamicRendezvousHandler/StaticTCPRendezvous等) 维护了一个 RendezvousHandlerRegistry,launch_agent ==> rdzv_handler = rdzv_registry.get_rendezvous_handler(rdzv_parameters) 首先 根据backend 确定类型,再根据 rdzv_parameters 对 rendezvous_handler 初始化。
# /pytorch/torch/distributed/elastic/rendezvous/api.py
class RendezvousHandlerRegistry:
_registry: Dict[str, RendezvousHandlerCreator]
def register(self, backend: str, creator: RendezvousHandlerCreator) -> None:
def create_handler(self, params: RendezvousParameters) -> RendezvousHandler:
rendezvous_handler_registry = RendezvousHandlerRegistry()
实际运行发现 rdzv_endpoint 中指定的port 由 python -m torch.distributed.run train_script.py 进程监听,也就是 c10dStore 运行在 elastic agent 上。PS: 代码上看 etcd 系列的会清晰一下。
这里要注意的是,elastic 内部有一套 Rendezvous,和 distributed 原有的 Rendezvous 那套不一样,别搞混了。distributed 原有的 Rendezvous 就是一套简单的 KV 存储。elastic Rendezvous 则要复杂得多。
RendezvousBackend
在 PyTorch 之中,backend 概念指的是当前进程要使用的通信后端,一般来说,支持的通信后端有 gloo,mpi,nccl 。建议用 nccl。在弹性训练这里(Backend概念不一样),Backend 其核心就是一个 Store,用来存储相关信息,通过 set_state 和 get_state 来对 store 进行读写。Rendezvous 的各种同步操作,都是由各个代理连接到这个中心化的 Store,在其上完成。
class RendezvousBackend(ABC):
@abstractmethod
def get_state(self) -> Optional[Tuple[bytes, Token]]
@abstractmethod
def set_state(self, state: bytes, token: Optional[Token] = None) -> Optional[Tuple[bytes, Token, bool]]
pytorch 默认实现了 C10dRendezvousBackend 和 EtcdRendezvousBackend。C10d 后端主要基于一个 TCPStore,通过 TCP 进行同步。TCPStore 是基于 TCP 的分布式键值存储实现(类似于 Redis)。是一个典型的 client-server 架构,服务器存储/保存数据,而存储客户端可以通过 TCP 连接到服务器存储并执行诸如set()插入键值对、get()检索键值对等操作。 所以,对于 c10d 后端来说,在其中一个代理之上会运行 TCPStore Master,其负责监听端口,提供API,Rendezvous 的各种同步操作(barrier/rank rendezvous等),都是由各个代理连接到这个中心化的 TCPStore Master,在其上完成。
我们在构建DynamicRendezvousHandler时候要指定后端(RendezvousBackend)。
store = TCPStore("localhost")
backend = C10dRendezvousBackend(store, "my_run_id") # 配置了后端
rdzv_handler = DynamicRendezvousHandler.from_backend(
run_id="my_run_id",
store=store,
backend=backend,
min_nodes=2,
max_nodes=4
)
Store
Elastic Introduction Elastic Agent 的设计:如何管理多个 worker 进程
Rendezvous 完成后,将创建一个共享键值存储(key-value store)并返回给node。此存储实现了一个torch.distributed.store API,此存储仅由已完成rendezvous的成员共享,被Torch Distributed Elastic用作交换初始化作业控制和数据平面所必需的信息。
Elastic 调用 rdzv_handler.next_rendezvous() 来处理成员关系变化,在 worker 被初始化,或者重启的时候,这一函数都会被调用。其会返回 world size,store等。会把 store 配置到 workgroup 之中,后续worker 之间就可以通过这个kvstore进行沟通。
class Store(__pybind11_builtins.pybind11_object):
def add(self, arg0, arg1)
def compare_set(self, arg0, arg1, arg2)
def delete_key(self, arg0)
def get(self, arg0)
def num_keys(self)
def set(self, arg0, arg1)
def set_timeout(self, arg0)
def wait(self, *args, **kwargs)
”注册中心“可以是c10d/etcd,使用不同的“注册中心”有不同的问题
- c10d 运行在rank0 节点, 因此使用c10d时,非rank0 节点挂掉ok,rank0 节点挂掉会导致训练任务失败
- 使用etcd时,非rank0 节点挂掉ok,rank0 节点挂掉后 其它节点会作为rank0节点,可能会有问题:有些框架喜欢在rank0 做一些特殊工作
elastic agent 源码
agent 总体逻辑如下
- 调用 _initialize_workers 来启动 worker 进程
- 调用 _rendezvous,其内部:调用 next_rendezvous 处理成员关系变化,调用 _assign_worker_ranks 为 worker 建立 ranks。
- 调用 _start_workers 启动 workers。
- 调用 _monitor_workers 监控这些进程的运行结果。 代码结构上,agent 实现了启动、停止、监控worker的逻辑,将rendezvous 逻辑抽象成/委托给 RendezvousHandler负责,agent 就是 worker 管理 与 RendezvousHandler 的协作。
elastic agent 的可扩展性非常好,在 1.9.0 版本中,一共有三个 Agent,分别是 ElasticAgent、SimpleElasticAgent 和 LocalElasticAgent。 其中 ElasticAgent 是一个 Abstract Class,SimpleElasticAgent 对其中的某些函数进行了实现(半成品),而 LocalElasticAgent 则实现了管理单机上所有 worker 进程的 elastic agent。
agent运行
python3.9/site-packages/torch/distributed/run.py ==> ` main() ==> run(args) ==> elastic_launch(config=config,entrypoint=cmd,)(cmd_args) ==> call(args)` ==> launch_agent ==> agent.run ==> SimpleElasticAgent._invoke_run
# /python3.9/site-packages/torch/distributed/launcher/api.py
class elastic_launch:
def __init__(self,config: LaunchConfig,entrypoint: Union[Callable, str, None],):
self._config = config
self._entrypoint = entrypoint
def __call__(self, *args):
return launch_agent(self._config, self._entrypoint, list(args))
def launch_agent(config: LaunchConfig,entrypoint: Union[Callable, str, None],args: List[Any],) -> Dict[int, Any]:
## 构造WorkerSpec 包括worker 启动参数等
entrypoint_name = _get_entrypoint_name(entrypoint, args)
rdzv_parameters = RendezvousParameters(
backend=config.rdzv_backend,
endpoint=config.rdzv_endpoint,
min_nodes=..,max_nodes=..,..)
rdzv_handler = rdzv_registry.get_rendezvous_handler(rdzv_parameters)
master_addr, master_port = _get_addr_and_port(rdzv_parameters)
try:
spec = WorkerSpec(
local_world_size=config.nproc_per_node,
entrypoint=entrypoint,...,
master_addr=master_addr,master_port=master_port,)
agent = LocalElasticAgent(spec=spec, start_method=config.start_method, log_dir=config.log_dir)
result = agent.run() # 启动agent
except Exception:
...
finally:
rdzv_handler.shutdown() # 以 EtcdRendezvousHandler 为例,EtcdRendezvousHandler.shutdown 会在 etcd 上记录 本次rendezvous closed。
初始化/启动worker
# python3.9/site-packages/torch/distributed/elastic/agent/server/api.py
class SimpleElasticAgent(ElasticAgent):
def run(self, role: str = DEFAULT_ROLE) -> RunResult:
try:
return self._invoke_run(role)
except SignalException as e:
...
finally:
self._shutdown()
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
spec = self._worker_group.spec
self._initialize_workers(self._worker_group) ## 启动worker
while True:
time.sleep(monitor_interval) ## 每隔 monitor_interval 查看下 worker 的状态
# 监控循环
class SimpleElasticAgent(ElasticAgent):
def _initialize_workers(self, worker_group: WorkerGroup) -> None:
role = worker_group.spec.role
log.info(f"[{role}] Rendezvous'ing worker group")
self._rendezvous(worker_group)
log.info(f"[{role}] Starting worker group")
worker_ids = self._start_workers(worker_group)
for local_rank, w_id in worker_ids.items():
worker = worker_group.workers[local_rank]
worker.id = w_id
worker_group.state = WorkerState.HEALTHY
def _rendezvous(self, worker_group: WorkerGroup) -> None:
spec = worker_group.spec
store, group_rank, group_world_size = spec.rdzv_handler.next_rendezvous()
self._store = store
workers = self._assign_worker_ranks(store, group_rank, group_world_size, spec)
worker_group.workers = workers
worker_group.store = store
worker_group.group_rank = group_rank
worker_group.group_world_size = group_world_size
if group_rank == 0:
self._set_master_addr_port(store, spec.master_addr, spec.master_port)
master_addr, master_port = self._get_master_addr_port(store)
restart_count = spec.max_restarts - self._remaining_restarts
next_rendezvous 方法会调用 rendezvous_barrier。在 rendezvous_barrier 之中,如果底层抛出各种异常,则会捕获,然后调用 init_phase 再次执行一次rendezvous,直到deadline时间到为止。
监控循环
PyTorch 分布式之弹性训练(2)—启动&单节点流程进入 while True 循环,在循环之中:通过 _monitor_workers 定期轮训用户程序运行情况 SUCCEEDED/FAILED/HEALTHY,得到客户进程运行结果,然后依据情况作出判断。
- 如果程序正常结束,则返回。
- 如果程序出错,则重试,即重启所有 workers,如果重试次数达到依然有问题,就结束所有workers。
- 如果节点成员关系有变化,比如scale up就会有新的节点在waiting,这时候就重启所有workers。
class SimpleElasticAgent(ElasticAgent):
def _invoke_run(self, role: str = DEFAULT_ROLE) -> RunResult:
# NOTE: currently only works for a single role
spec = self._worker_group.spec
role = spec.role
self._initialize_workers(self._worker_group) # 启动worker
monitor_interval = spec.monitor_interval
rdzv_handler = spec.rdzv_handler
while True:
assert self._worker_group.state != WorkerState.INIT
# 定期监控
time.sleep(monitor_interval)
# 监控客户程序运行情况
run_result = self._monitor_workers(self._worker_group)
state = run_result.state # 进程运行情况
self._worker_group.state = state
if state == WorkerState.SUCCEEDED:
# 程序正常结束
self._exit_barrier() # 有一个成功了就全部结束
return run_result
elif state in {WorkerState.UNHEALTHY, WorkerState.FAILED}:
# 程序出错
if self._remaining_restarts > 0: # 重试
self._remaining_restarts -= 1
self._restart_workers(self._worker_group) # 进行重启
else:
self._stop_workers(self._worker_group) # 重试次数达到,结束workers
self._worker_group.state = WorkerState.FAILED
self._exit_barrier()
return run_result
elif state == WorkerState.HEALTHY:
# 程序正常运行
# 节点成员关系有变化,比如scale up
# membership changes do not count as retries
num_nodes_waiting = rdzv_handler.num_nodes_waiting()
group_rank = self._worker_group.group_rank
# 如果有新的节点在waiting,就重启所有workers
if num_nodes_waiting > 0:
self._restart_workers(self._worker_group)
else:
raise Exception(f"[{role}] Worker group in {state.name} state")
def _restart_workers(self, worker_group: WorkerGroup) -> None:
"""
Restarts (stops, rendezvous, starts) all local workers in the group.
"""
role = worker_group.spec.role
log.info(f"[{role}] Stopping worker group")
self._stop_workers(worker_group)
worker_group.state = WorkerState.STOPPED
self._initialize_workers(worker_group) # 又执行了一次 _initialize_workers,重新一轮 rendezvous 。
启动worker
PyTorch 分布式之弹性训练(3)—代理_start_workers 方法会调用 start_processes 来启动 worker 进程,默认_start_method 是 “spawn”。也就是启动了多个进程,并行执行用户程序。同时这些进程的运行结果会被监控。start_processes 参数之中,entrypoint和args 是用户命令和参数,entrypoint可以是函数或者字符串。_start_workers 把 start_processes 方法启动多线程的结果保存在 _pcontext 之中,后续就用 _pcontext 来继续控制,比如结束 worker 就是直接调用 _pcontext 的 close方法。
class SimpleElasticAgent(ElasticAgent):
def _initialize_workers(self, worker_group: WorkerGroup) -> None:
role = worker_group.spec.role
self._rendezvous(worker_group) # 启动前先集会获取下数据
log.info(f"[{role}] Starting worker group")
worker_ids = self._start_workers(worker_group) # 启动worker
for local_rank, w_id in worker_ids.items():
worker = worker_group.workers[local_rank]
worker.id = w_id
worker_group.state = WorkerState.HEALTHY
LocalElasticAgent 实现了 _start_workers,关键就是为 worker 准备环境 变量和参数
# python3.9/site-packages/torch/distributed/elastic/agent/server/local_elastic_agent.py
class LocalElasticAgent(SimpleElasticAgent):
def _start_workers(self, worker_group: WorkerGroup) -> Dict[int, Any]:
spec = worker_group.spec
store = worker_group.store
master_addr, master_port = super()._get_master_addr_port(store)
restart_count = spec.max_restarts - self._remaining_restarts
args: Dict[int, Tuple] = {}
envs: Dict[int, Dict[str, str]] = {}
## 为worker 进程准备 环境变量 和启动参数
for worker in worker_group.workers:
local_rank = worker.local_rank
worker_env = {
"LOCAL_RANK": str(local_rank),"RANK": str(worker.global_rank),"GROUP_RANK": str(worker_group.group_rank),
"LOCAL_WORLD_SIZE": str(spec.local_world_size),"WORLD_SIZE": str(worker.world_size),
"MASTER_ADDR": master_addr,"MASTER_PORT": str(master_port),
...
}
envs[local_rank] = worker_env
worker_args = list(spec.args)
worker_args = macros.substitute(worker_args, str(local_rank))
args[local_rank] = tuple(worker_args)
self._pcontext = start_processes(
entrypoint=spec.entrypoint,
args=args,envs=envs,log_dir=attempt_log_dir,
start_method=self._start_method,...)
return self._pcontext.pids()
PContext 就是一个抽象类,有两个派生类:MultiprocessContext 和 SubprocessContext。前文提到,start_processes 参数之中,entrypoint和args 是用户命令和参数,entrypoint可以是函数或者字符串。如果entrypoint是函数,则使用MultiprocessContext。如果是字符串类型,使用SubprocessContext。
- LocalElasticAgent._pcontext 保存了 MultiprocessContext,MultiprocessContext._pc 保存了 ProcessContext。
- 监控时候,LocalElasticAgent._monitor_workers 调用了 MultiprocessContext.wait,MultiprocessContext 又调用了 ProcessContext.join,ProcessContext.join 具体监控进程的运行状态,这样完成了监控的整体逻辑。
- 子进程有变化或者超时之后,ProcessContext.join 返回了进程结果,MultiprocessContext.wait 把进程结果转发回去,_monitor_workers 把进程结果转换为 WorkerState.SUCCEEDED 或者 WorkerState.FAILED。
容错
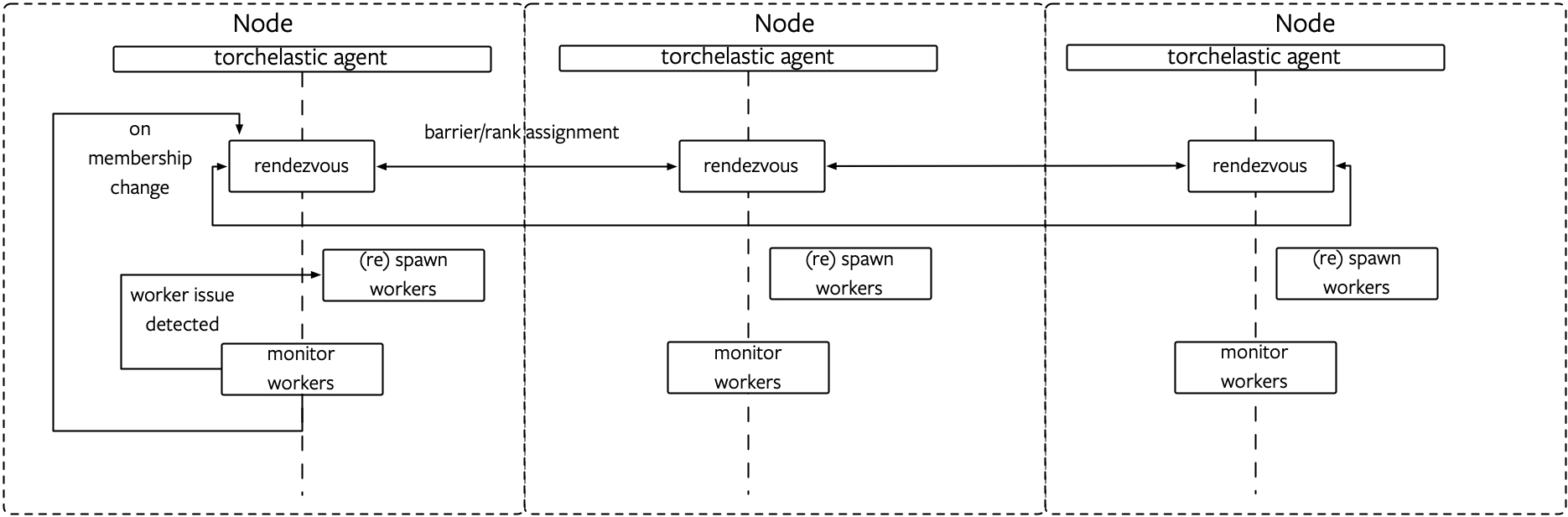
PyTorch 分布式之弹性训练(6)—监控/容错新一轮 rendezvous 会让其他 agent 也重启它们的worker。这是如何做到的?具体如下:
- Agent 0(故障Agent)通过 monitoring 发现了故障。
- Agent 0 调用 _restart_workers 重启worker。
- Agent 0 会调用 next_rendezvous 发起新一轮 rendezvous。
- Agent 0 在做任何操作之前,比如 keep alive 操作之前,会调用 sync 来从kvstore获取集群信息,这样可以保证 Agent拿到的是集群最新状态。
- Agent 0 会把自己加入到本地的 waiting_list 之中。
- Agent 0 同时会调用 mark_dirty,意思是我状态更新了,需要写入KVStore。
- Agent 0 会调用sync把自己的waiting_list 被写入 KVStore。
- Agent 1(其他正常工作的 agent)会在做任何操作之前,比如 keep alive 操作之前,会调用 sync 操作从KVStore 获取最新信息。
- Agent 1 利用这些信息来更新自己的状态,这样本地 waiting_list 就会更新。
- Agent 1 的 train loop 在每 30 秒监控之后,因为系统正常,是 Healthy 状态。
- Agent 1 所以调用 num_nodes_waiting() 看看 waiting_list 数目。
- Agent 1 会获取本地 waiting list 的数目。
- 如果 waiting list 不为空,也调用_restart_workers。
- 其最终会调用next_rendezvous。
- 启动一个新 worker。
- 调用 next_rendezvous,发起新一轮 rendezvous。
- _RendezvousJoinOp 内部运行,生成 ADD_TO_WAIT_LIST。
- executor.run 内部运行 _add_to_wait_list。
- 往 wait_list 添加一个新的 node。
- Agent 之中,定期(比如 30S)运行一次 _monitor_workers,获取worker 子进程状态。
- 如果是 HEALTHY,则调用num_nodes_waiting 获取 wait_list 个数。
- 如果 wait_list 之中等待节点数目大于 0,则:
- 调用 _restart_workers 重启进程组。
节点级容错: elastic agent 注册了 signal.signal(signal.SIGTERM, _terminate_process_handler) 之后 引起 rdzv_handler.shutdown()
与horovod 对比
其它
run.py 启动命令
python -m torch.distributed.run [args] training_script [training_script_args],包含以下参数
关于workGroup 的布局
--nnodes--nproc_per_node关于集会机制--rdzv_backend- The backend of the rendezvous (e.g.c10d). This is typically a strongly consistent key-value store.--rdzv_endpoint- The rendezvous backend endpoint; usually in form<host>:<port>.--rdzv_id- A user-defined id that uniquely identifies the worker group for a job. This id is used by each node to join as a member of a particular worker group.--rdzv_conf--standaloneStandalone 模式是分布式模式的一种特例,它主要针对单机多 Worker 的方式提供了一些便利的设置,指定Standalone后 不再需要设置一些多余的参数如 rdzv_backend 和 rdzv_endpoint 等。 User-code launch related arguments.--max_restarts--monitor_interval监听 worker 状态的间隔--start_method可选值["spawn", "fork", "forkserver"],默认值spawn-
--role以下为兼容 老版 launch.py 提供的参数 --node_rank--master_addr--master_port
如何启动 train_script
train_script 启动方式有以下几种
- 直接 python 启动 比较重要的参数是local_rank,world_size,master_host,master_port, backend
- WORLD_SIZE, 数据分几份
- RANK, 自己是第几份,自己是不是master(rank=0 是master)
- NPROC_PER_NODE,
RANK / NPROC_PER_NODE可以推算 多卡里用哪一张卡 - MASTER_ADDR:MASTER_PORT, 如何发现其它成员,组建process_group时需要
- 由 launch.py 启动,大部分参数直接 传给 train_script.py,launch根据 nnodes 和 nproc_per_node 算了一下 local_rank 和 world_size 传给train_script。
python -m torch.distributed.launch --nnodes=2 --node_rank=xx --nproc_per_node=xx --master_addr=xx --master_port=xx TRAINING_SCRIPT.py (... train script args ...)。 这个方法已经淘汰,并且在不同的时期 launch.py 的实现有变化。 - 由 run.py 启动,参数 都是给 rendezvous 用的, 由rendezvous 协商出 train_script 需要的参数,由 run.py spawn worker 进程时传给worker/传给train_script。
python -m torchelastic.distributed.run --nnodes=1:4 --nproc_per_node=xx --rdzv_id=JOB_ID --rdzv_backend=etcd --rdzv_endpoint=ETCD_HOST:ETCD_PORT TRAINING_SCRIPT.py (... train script args ...)
launch 和 run 仅仅是为启动 train_script 方便,该给 train_script 传的参数还是要传,不传参数用环境变量也行,传参或传环境变量需要的参数是一致的,可以到launch.py 或 run.py 源码下查看其启动需要哪些参数。PS:train_script 是算法写的,在train_script 内使用的库 具备分布式、弹性 能力之前,能力扩充 主要通过 加壳子的方式来解决。
python直接 启动 train_script 需要以下参数(来自run.py 代码注释)
LOCAL_RANK- The local rank.RANK- The global rank.GROUP_RANK- The rank of the worker group. A number between 0 andmax_nnodes. When running a single worker group per node, this is the rank of the node.ROLE_RANK- The rank of the worker across all the workers that have the same role. The role of the worker is specified in theWorkerSpec.LOCAL_WORLD_SIZE- The local world size (e.g. number of workers running locally); equals to--nproc_per_nodespecified ontorchrun.WORLD_SIZE- The world size (total number of workers in the job).ROLE_WORLD_SIZE- The total number of workers that was launched with the same role specified inWorkerSpec.MASTER_ADDR- The FQDN of the host that is running worker with rank 0; used to initialize the Torch Distributed backend.MASTER_PORT- The port on theMASTER_ADDRthat can be used to host the C10d TCP store.TORCHELASTIC_RESTART_COUNT- The number of worker group restarts so far.TORCHELASTIC_MAX_RESTARTS- The configured maximum number of restarts.TORCHELASTIC_RUN_ID- Equal to the rendezvousrun_id(e.g. unique job id).