前言
整体来说,本书是对源码的“照本宣科”,提炼的东西不多,试试另外一本书:《learning apache kafka》
Apache Kafka is a distributed streaming platform. What exactly does that mean? A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
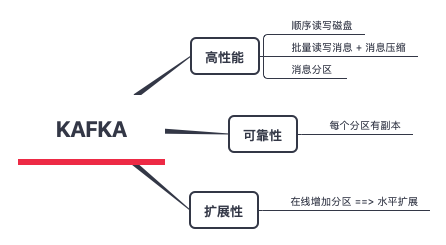
给自己提几个问题
- kafka 将消息保存在磁盘中,在其设计理念中并不惧怕磁盘操作,它以顺序方式读写磁盘。具体如何体现?
- 多面的offset。一个msg写入所有副本后才会consumer 可见(消息commit 成功)。leader / follower 拿到的最新的offset=LEO, 所有副本都拿到的offset = HW
- 一个consumer 消费partition 到哪个offset 是由consumer 自己维护的
书中源码基于0.10.0.1
宏观概念
仅从逻辑概念上看
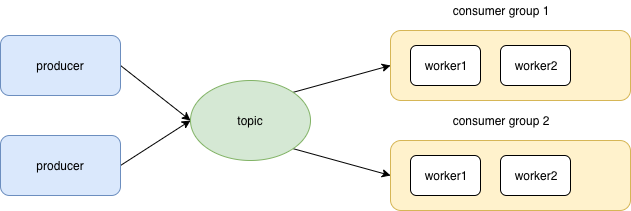
每个topic包含多个分区,每个分区包含多个副本。作为producer,一个topic消息放入哪个分区,hash一下即可。 《learning apache kafka》every partition is mapped to a logical log file that is represented as a set of segment files of equal sizes. Every partition is an ordered, immutable sequence of messages;
Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息 Partitions are nothing but separate queues in Kafka to make it more scalable. When we increase partitions or we have 1+ number of Partitions it is expected that you run multiple consumers. Ideally number of Consumer should be equal to number of Partitions. 分区相当于把“车道”拓宽了。
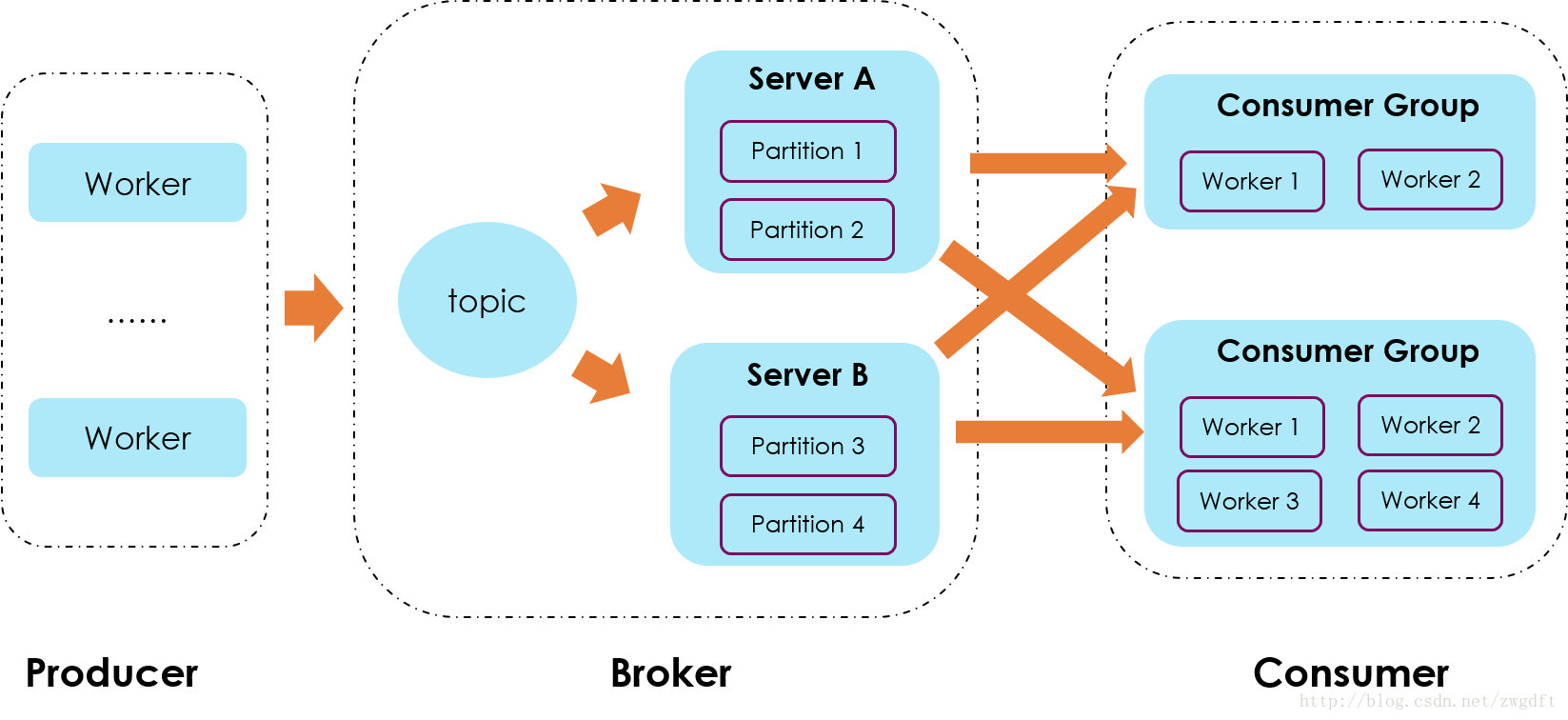
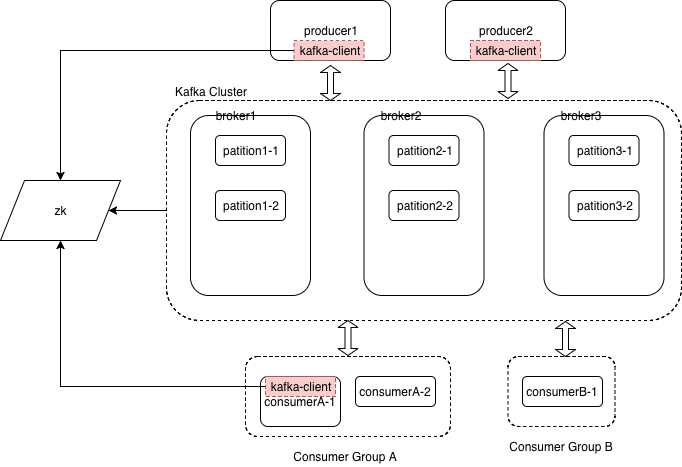
整体架构图
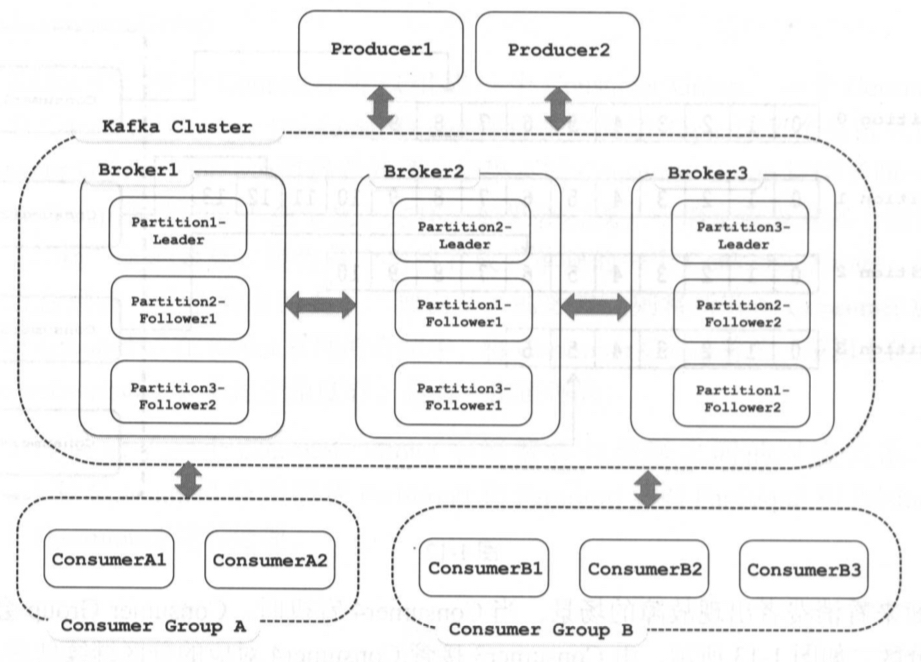
细化一下是这样的
代码使用
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.8.2</artifactId>
<version>0.8.0</version>
</dependency>
生产者
// 配置属性
Properties props = new Properties();
props.put("metadata.broker.list", "localhost:9092");
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("request.required.acks", "1");
ProducerConfig config = new ProducerConfig(props);
// 构建Producer
Producer<String, String> producer = new Producer<String, String>(config);
// 构建msg
KeyedMessage<String, String> data = new KeyedMessage<String, String>(topic, nEvents + "", msg);
// 发送msg
producer.send(data);
// 关闭
producer.close();
消费者
Kafka系列(四)Kafka消费者:从Kafka中读取数据
// 配置属性
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList("customerCountries"));
// 拉取循环
try {
while (true) { //1)
ConsumerRecords<String, String> records = consumer.poll(100); //2)
for (ConsumerRecord<String, String> record : records) //3){
log.debug("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
int updatedCount = 1;
if (custCountryMap.countainsValue(record.value())) {
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount)
JSONObject json = new JSONObject(custCountryMap);
System.out.println(json.toString(4))
}
}
} finally {
consumer.close(); //4
}
高可用机制
- 为了让 Kafka 能够高可用,我们需要对于每一个分区都有多个副本,和 GFS 一样,Kafka 的默认参数选择了 3 个副本。
- 这些副本中,有一个副本是 Leader,其余的副本是 Follower。我们的 Producer 写入数据的时候,只需要往 Leader 写入就好了。Leader 自然也就是将对应的数据,写入到本地的日志文件里。
- 然后,每一个 Follower 都会从 Leader 去拉取最新的数据,一旦 Follower 拉到数据之后,会向 Leader 发送一个 Ack 的消息。
- 我们可以设定,有多少个 Follower 成功拉取数据之后,就能认为 Producer 写入完成了。这个可以通过在发送的消息里,设定一个 acks 的字段来决定。如果 acks=0,那就是 Producer 的消息发送到 Broker 之后,不管数据是否刷新到本地硬盘,我们都认为写入已经完成了;而如果设定 acks=2,意味着除了 Leader 之外,至少还有一个 Follower 也把数据写入完成,并且返回 Leader 一个 Ack 消息之后,消息才写入完成。我们可以通过调整 acks 这个参数,来在数据的可用性和性能之间取得一个平衡。
负载均衡机制
Kafka 本身没有 Master,每一个 Kafka 的 Broker 启动的时候,就会把自己注册到 ZooKeeper 上,注册信息自然是 Broker 的主机名和端口。在 ZooKeeper 上,Kafka 还会记录,这个 Broker 里包含了哪些主题(Topic)和哪些分区(Partition)。上游的 Producer 只需要监听 Brokers 的目录,就能知道下游有哪些 Broker。那么,无论是随机发送,还是根据消息中的某些字段进行分区,上游都可以很容易地把消息发送到某一个 Broker 里。
所有的 Broker 本身也不维护任何状态,对应的状态信息也是放在 ZooKeeper 上,而下游的 Consumer 也是一样。
Kafka 的 Consumer 一样会把自己“注册”到 ZooKeeper 上。在同一个 Consumer Group 下,一个 Partition 只会被一个 Consumer 消费,这个 Partition 和 Consumer 的映射关系,也会被记录在 ZooKeeper 里。这部分信息,被称之为“所有权注册表”。而 Consumer 会不断处理 Partition 的数据,一旦某一段的数据被处理完了,对应这个 Partition 被处理到了哪个 Offset 的位置,也会被记录到 ZooKeeper 上。这样,即使我们的 Consumer 挂掉,由别的 Consumer 来接手后续的消息处理,它也可以知道从哪里做起。那么在这个机制下,一旦我们针对 Broker 或者 Consumer 进行增减,Kafka 就会做一次数据“再平衡(Rebalance)”。所谓再平衡,就是把分区重新按照 Consumer 的数量进行分配,确保下游的负载是平均的。Kafka 的算法也非常简单,就是每当有 Broker 或者 Consumer 的数量发生变化的时候,会再平均分配一次。
如果我们有 X 个分区和 Y 个 Consumer,那么 Kafka 会计算出 N=X/Y,然后把 0 到 N-1 的分区分配给第一个 Consumer,N 到 2N-1 的分配给第二个 Consumer,依此类推。而因为之前 Partition 的数据处理到了哪个 Offset 是有记录的,所以新的 Consumer 很容易就能知道从哪里开始处理消息。
Kafka 对于消息的处理也是“至少一次”的。如果消息成功处理完了,那么我们会通过更新 ZooKeeper 上记录的 Offset,来确认这一点。而如果在消息处理的过程中,Consumer 出现了任何故障,我们都需要从上一个 Offset 重新开始处理。这样,我们自然也就避免不了重复处理消息。
为什么kafka 这么快
《大数据经典论文解读》传统的消息队列,关注的是小数据量下,是否每一条消息都被业务系统处理完成了。因为这些消息队列里的消息,可能就是一笔实际的业务交易,我们需要等待 consumer 处理完成,确认结果才行。但是整个系统的吞吐量却没有多大。Kafka 的假设是,我们处理的是互联网领域的海量日志,我们对于丢失一部分日志是可以容忍的。因为几 TB 的广告浏览和点击日志少了几条,其实并不会对业务产生什么影响。但是,我们需要关注系统整体的吞吐量、可扩展性、以及错误恢复能力。kafka的整体设计
- 让所有的 Consumer 来“拉取”数据,而不是主动“推送”数据给到 Consumer。并且,Consumer 到底消费完了哪些数据,是由 Consumer 自己维护的,而不是由 Kafka 这个消息队列来进行维护。
- 采用了一个非常简单的追加文件写的方式来直接作为我们的消息队列。在 Kafka 里,每一条消息并没有通过一个唯一的 message-id,来标识或者维护。整个消息队列也没有维护什么复杂的内存里的数据结构。下游的消费者,只需要维护一个此时它处理到的日志,在这个日志文件中的偏移量(offset)就好了。
基于这两个设计思路,Kafka 做了一些简单的限制,那就是一个 consumer 总是顺序地去消费,来自一个特定分区(Partition)的消息。而一个 Partition 则是 Kafka 里面可以并行处理的最小单位,这就是说,一个 Partition 的数据,只会被一个 consumer 处理。这样一来,整个 Kafka 的系统设计也一下子变得特别简单。所有的 Producer 生成消息,和 Consumer 消费消息,都变成了简单的顺序的文件读和文件写。而我们知道,硬盘的顺序读写的性能要远高于随机读写。Kafka 是直接使用本地的文件系统承担了消息队列持久化的功能,所以 Kafka 干脆没有实现任何缓存机制,而是直接依赖了 Linux 文件系统里的页缓存(Page Cache)。Kafka 写入的数据,本质上都还是在 Page Cache。而且因为我们是进行流式数据处理,读写的数据有很强的时间局部性,Broker 刚刚写入的数据,几乎立刻会被下游的 Consumer 读取访问,所以大量的数据读写都会命中缓存。除了利用文件系统之外,Kafka 还利用了 Linux 下的 sendfile API,通过 DMA 直接将数据从文件系统传输到网络通道,所以它的网络数据传输开销也很小。
- 写入优化:利用了“磁盘” 顺序写比 内存读写还快的特性。Kafka的message是不断追加到本地磁盘文件末尾的,换句话说, kafka 基于磁盘 主要因素是因为磁盘顺序写比内存操作更快,附带因为磁盘容量更大。
- 读取优化:零拷贝。
- 文件分段。Kafka的队列topic被分为了多个区partition, 每个partition又分为了多个segment,所以一个队列中的消息实际上是保存在N多个片段文件中,通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理能力
- 批量发送
- 数据压缩
背景知识
网络通信
kafka-producer/consumer 与zk 通信的部分相对有限,主要是与kafka server交互,通信时使用自定义的协议,一个线程(kafka 服务端一个线程就不够用了)裸调java NIO 进行网络通信。
- producer 使用 NetworkClient 与kafka server 交互
- consumer 使用 ConsumerNetworkClient(聚合了NetworkClient)与kafka server 交互
-
协议对象如下图所示,
org.apache.kafka.common.protocol.ApiKeys定义了所有 Request/Response类型,FetchXX 是一个具体的例子
-
NetworkClient 发请求比较“委婉” 先send(缓存),最后poll真正开始发请求
- send,Send a new request. Note that the request is not actually transmitted on the network until one of the
poll(long)variants is invoked. At this point the request will either be transmitted successfully or will fail.Use the returned future to obtain the result of the send. - poll,Poll for any network IO.
- send,Send a new request. Note that the request is not actually transmitted on the network until one of the
传递保证语义(Delivery(guarantee) sematic)
Delivery guarantee 有以下三个级别
- At most once,可以丢,但不能重复
- At least once,不能丢,可能重复
- exactly once,只会传递一次
这三个级别不是一个配置保证的,而是producer 与consumer 配合实现的。比如想实现“exactly once”,可以为每个消息标识唯一id,producer 可能重复发送,而consumer 忽略已经消费过的消息即可。
《learning apache kafka》
- producers and consumers work on the traditional push-and-pull model, where producers push the message to a Kafka broker and consumers pull the message from the broker.
- Log compaction,相同key的value 只会保留最新的
- Message compression in Kafka, For the cases where network bandwidth is a bottleneck, Kafka provides a message group compression feature for efficient message delivery.
- replication modes。Asynchronous replication: as soon as a lead replica writes the message to its local log, it sends the acknowledgement to the message client and does not wait for acknowledgements from follower replicas。Synchronous replication 则反之