简介
http://fishcried.com/ 有一个linux 网络的基础知识系列,要研读下
tcpdump
## 监听某个网卡的数据包
tcpdump -i eth0
## 监听某个端口的数据包,默认是第一个网卡
tcpdump port 1024
## 监控本机 eth0 网卡与目标主机的往来数据包
tcpdump -i eth0 -nn 'host 目标主机ip'
Wireshark 还可以用来读取 tcpdump 保存的 pcap 文件。你可以使用 tcpdump 命令行在没有 GUI 界面的远程机器上抓包然后在 Wireshark 中分析数据包。
通过分析数据包收到和发出的时间差,可以分析数据包在网卡之间的耗时。
ip命令
我们知道经典的OSI七层网络模型,学要致用,要将其掺入到对linux网络命令的理解中。
我们知道网卡有mac地址和ip地址,分别用在链路层和网络层。打个比方,MAC地址像是我们的身份证,到哪都是那个样子;IP像是居住证,换了地方信息就要变了。政府机构同时给公民发身份证和居住证以便管理动态的社会,网络管理机构则通过给所有的上网设备同时分配MAC和IP达到这个目的。(mac地址是和位置无关的,所以是不可路由的)(这个比方来自知乎)是不是有点动静结合的意思。
一开始mac地址都是烧在网卡中的,后来则是可以动态设置(虚拟的网卡mac地址就更可以改变了)。网卡的ip地址和mac地址可变也没什么关系,因为交换机和路由器可以学习所连接网络pc的ip、mac和swtich/router的port的对应关系。网卡可以设置为混杂模式,这样一个网卡可以接受所有收到的数据包(即便数据包的目的ip地址不是该网卡的ip地址)。
iproute2是一个套件,包含的是一套命令,类似于docker,所有的docker操作命令以docker开头,就可以完成关于docker的所有操作。具体的子操作,则类似于”docker network xx”。
既然网络是分层的,那么理论上讲不同的ip命令负责不同层的事情。比如ip link (Data Link layer,所以叫ip link)负责第二层,ip address负责第三层。所以,当你想设置mtu时(肯定是第二层的事),你得找ip link。
较高版本的linux内核支持namespace,因此ip命令还可以设置某个namespace的网卡(实际上,我们通常在root namespace执行ip命令,root namespace可以“看见”所有的子namespace)。
通过man ip我们可以看到
ip link add link DEVICE [ name ] NAME
[ txqueuelen PACKETS ]
[ address LLADDR ] [ broadcast LLADDR ]
[ mtu MTU ]
type TYPE [ ARGS ]
TYPE := [ vlan | veth | vcan | dummy | ifb | macvlan | can | bridge]
这说明,ip命令不仅可以添加网卡,还可以添加网桥等网络设备。
iptables
从零认识 iptablesiptables 并不是也不依赖于守护进程,它只是利用Linux内核提供的功能。iptables 所能做的不仅仅是对包的过滤(Filter Table),还支持对包进行网络地址转换(NAT Table)以及修改包的字段(Mangle Table)。
netfilter
深入理解 Kubernetes 网络模型 - 自己实现 kube-proxy 的功能Netfilter 是 Linux Kernel 的一种 hook 机制,围绕网络层(IP 协议)的周围埋下了五个钩子(Hooks),每当有数据包流到网络层,经过这些钩子时,就会自动触发由内核模块注册在这里的回调函数,程序代码就能够通过回调来干预 Linux 的网络通信。 5 个hook分别是 pre-routing、input、forword、output、post-routing。处理数据包的能力主要包括修改、跟踪、打标签、过滤等。一些要点:
- 主机上的所有数据包都将通过 netfilter 框架
- 在 netfilter 框架中有5个钩子点: PRE_ROUTING, INPUT, FORWARD, OUTPUT, POST_ROUTING
- 命令行工具 iptables 可用于动态地将规则插入到钩子点中
- 可以通过组合各种 iptables 规则来操作数据包(接受/重定向/删除/修改,等等)
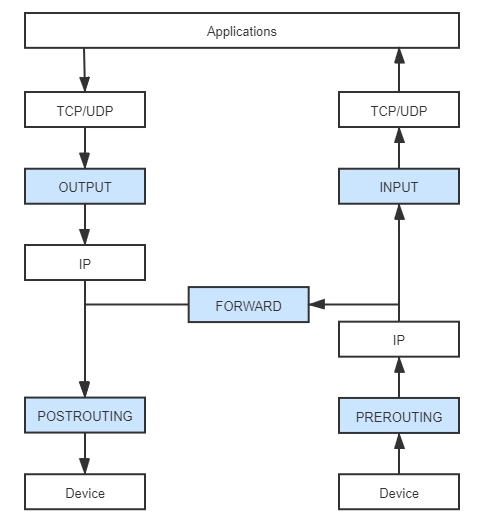
两次路由选择
- 刚刚进入网络层的数据包通过PRE_ROUTING关卡时,要进行一次路由选择
- 当目标地址为本机地址时,数据进入INPUT,
- 非本地的目标地址进入FORWARD(需要本机内核支持IP_FORWARD)
- 由本地用户空间应用进程产生的数据包,通过一次路由选择由哪个接口送往网络中
Netfilter 允许在同一个钩子处注册多个回调函数,所以数据包在向钩子注册回调函数时,必须提供明确的优先级,以便触发时能按照优先级从高到低进行激活。而因为回调函数会有很多个,看起来就像是挂在同一个钩子上的一串链条,所以钩子触发的回调函数集合,就被称为“回调链”(Chained Callbacks)。Netfilter 的钩子回调虽然很强大,但毕竟要通过程序编码才够能使用,并不适合系统管理员用来日常运维。于是把用户常用的管理意图总结成具体的行为,预先准备好,然后就会在满足条件的时候自动激活行为。
- DROP:直接将数据包丢弃。
- REJECT:给客户端返回 Connection Refused 或 Destination Unreachable 报文。
- QUEUE:将数据包放入用户空间的队列,供用户空间的程序处理。
- RETURN:跳出当前链,该链里后续的规则不再执行。
- ACCEPT:同意数据包通过,继续执行后续的规则。
- JUMP:跳转到其他用户自定义的链继续执行。
- REDIRECT:在本机做端口映射。
- MASQUERADE:地址伪装,自动用修改源或目标的 IP 地址来做
- NATLOG:在 /var/log/messages 文件中记录日志信息。
这些行为本来能够被挂载到 Netfilter 钩子的回调链上,但 iptables 又进行了一层额外抽象,它不是把行为与链直接挂钩,而是会根据这些底层操作的目的,先总结为更高层次的规则。举个例子,假设你挂载规则的目的是为了实现网络地址转换(NAT),那就应该对符合某种特征的流量(比如来源于某个网段、从某张网卡发送出去)、在某个钩子上(比如做 SNAT 通常在 POSTROUTING,做 DNAT 通常在 PREROUTING)进行 MASQUERADE 行为,这样具有相同目的的规则,就应该放到一起才便于管理,所以也就形成了“规则表”的概念。
- 链,分别对应上面提到的五个关卡,PRE_ROUTING,INPUT,FORWARD,OUTPUT,POST_ROUTING,这五个关卡分别由netfilter的五个钩子函数来触发。为什么叫做“链”呢?这个关卡上的“规则”不止一条,很多条规则会按照顺序逐条匹配,将在此关卡的所有规则组织称“链”就很适合,
- 表,每一条“链”上的一串规则里面有些功能是相似的,比如,A类规则都是对IP或者端口进行过滤,B类规则都是修改报文,我们考虑能否将这些功能相似的规则放到一起,这样管理iptables规则会更方便。iptables把具有相同功能的规则集合叫做“表”,并且定一个四种表:filter;nat;mangle;raw
因为数据包经过一个关卡的时候,会将“链”中所有的“规则”都按照顺序逐条匹配,这时候就涉及一个优先级的问题:raw→mangle→nat→filter→security,也就是前面我列举出的顺序。这里你要注意,在 iptables 中新增规则时,需要按照规则的意图指定要存入到哪张表中,如果没有指定,就默认会存入 filter 表。此外,每张表能够使用到的链也有所不同。
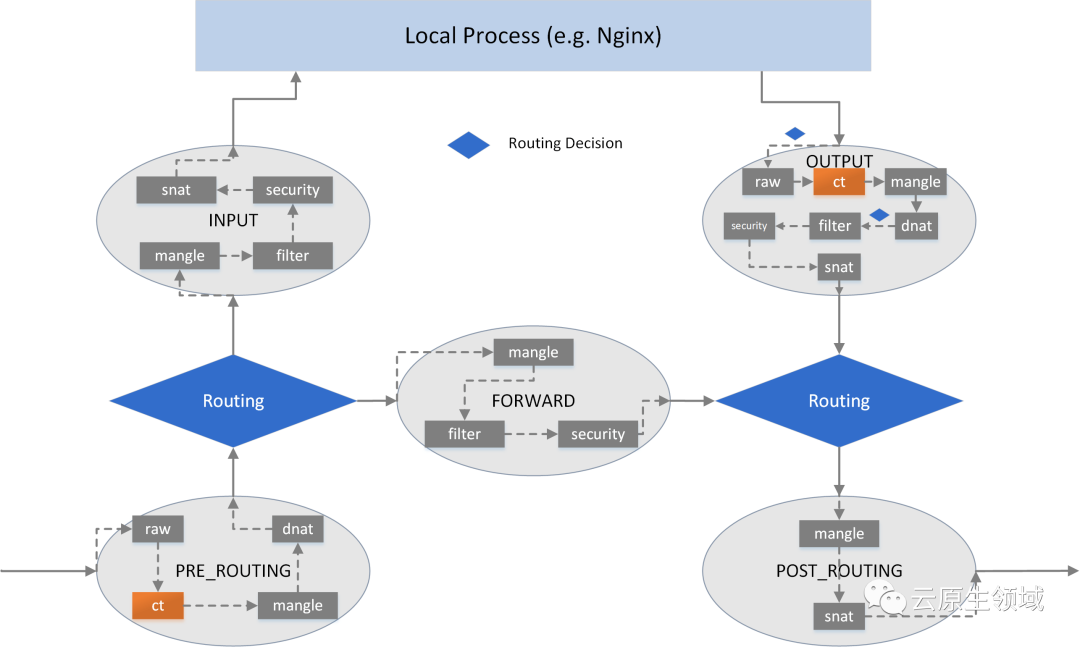
预置的五条链是直接源自于 Netfilter 的钩子,它们与规则表的对应关系是固定的,用户不能增加自定义的表,或者修改已有表与链的关系,但可以增加自定义的链。新增的自定义链与 Netfilter 的钩子没有天然的对应关系,换句话说就是不会被自动触发,只有显式地使用 JUMP 行为,从默认的五条链中跳转过去,才能被执行。
凭啥过滤
iptables规则由两部分组成,报文的匹配条件和匹配到之后的处理动作。
- 匹配条件:根据协议报文特征指定匹配条件,基本匹配条件和扩展匹配条件
- 处理动作:内建处理机制由iptables自身提供的一些处理动作
自定义的链不能直接使用,只能被某个默认的链当作Action去调用。也就是说自定义链为规则的一个处理动作的集合。
《网络是怎样连接的》:网络包的头部包含了用于控制通信操作的控制信息,经常用于设置包过滤规则的字段
| 头部类型 | 规则判断条件 | 含义 |
|---|---|---|
| MAC头部 | 发送方MAC地址 | 路由器在对包进行转发时会改写 MAC 地址,将转发目 标路由器的 MAC 地址设为接收方 MAC 地址,将自己 的 MAC 地址设为发送方 MAC 地址。通过发送方 MAC 地址,可以知道上一个转发路由器的 MAC 地址 |
| IP头部 | 发送方 IP 地址 | 发送该包的原始设备的 IP 地址。如果要以发送设备来 设置规则,需要使用这个字段 |
| 接收方 IP 地址 | 包的目的地 IP 地址,如果要以包的目的地来设置规则, 需要使用这个字段 | |
| 协议号 | TCP/IP 协议为每个协议分配了一个编号,如果要以协 议类型来设置规则,需要使用这个编号。主要的协议号 包括 IP∶0;ICMP∶1;TCP∶6;UDP∶17;OSPF∶89 | |
| TCP 头部或 UDP 头部 | 发送方端口号 | 发送该包的程序对应的端口号。服务器程序对应的端口 号是固定的,因此根据服务器返回的包的端口号可以分 辨是哪个程序发送的。不过,客户端程序的端口号大多 是随机分配的,难以判断其来源,因此很少使用客户端 发送的包的端口号来设置过滤规则 |
| 接收方端口号 | 包的目的地程序对应的端口号。和发送方端口号一样, 一般使用服务器的端口号来设置规则,很少使用客户端 的端口号 | |
| TCP 控制位 | TCP 协议的控制信息,主要用来控制连接操作 ACK 表示接收数据序号字段有效,一般用于通知发 送方数据已经正确接收 PSH 表示发送方应用程序希望不等待发送缓冲区填 充完毕,立即发送这个包 RST 强制断开连接,用于异常中断 SYN 开始通信时连接操作中发送的第一个包中, SYN 为 1,ACK 为 0。如果能够过滤这样的包, 则后面的操作都无法继续,可以屏蔽整个访问 FIN 表示断开连接 |
|
| 分片 | 通过 IP 协议的分片功能拆分后的包,从第二个分片开 始会设置该字段 | |
| ICMP 消息 (非头部)的内容 | ICMP 消息类型 |
示例如下
| 接收方IP地址 | 接收方端口号 | 发送方IP地址 | 发送方端口号 | TCP控制位 | 允许/阻止 |
|---|---|---|---|---|---|
| 192.0.2.0/24 | 80 | - | - | - | 允许 |
| - | - | 192.0.2.0/24 | 80 | SYN=1 ACK=0 |
阻止 |
| - | - | 192.0.2.0/24 | 80 | - | 允许 |
| - | - | - | - | - | 阻止 |
设置iptables规则时需要考量的要点:
- 根据要实现哪种功能,判断添加在那张“表”上
- 根据报文流经的路径,判断添加在那个“链”上
- 到本主机某进程的报文:PreRouting -> Input -> Process -> Output -> PostRouting
- 由本主机转发的报文:PreRouting -> Forward -> PostRouting
源码上的体现
// 从tcp层向ip层发送数据包
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb){
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
skb->protocol = htons(ETH_P_IP);
// 可以看到第一个hook点NF_INET_LOCAL_OUT
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
// 从ip层向link层发送数据包
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb){
struct net_device *dev = skb_dst(skb)->dev;
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
// 可以看到第一个hook点NF_INET_POST_ROUTING
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
// 从link到ip层的接收逻辑
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){
const struct iphdr *iph;
struct net *net;
u32 len;
......
net = dev_net(dev);
......
iph = ip_hdr(skb);
len = ntohs(iph->tot_len);
skb->transport_header = skb->network_header + iph->ihl*4;
......
// 可以看到第一个hook点是NF_INET_PRE_ROUTING
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
......
}
操作
iptbales -L -vn --line-number
iptables -D INPUT 7
iptables -D FORWARD 4
这样按序号删规则很方便
- iptables 是 按rules 来办事的,这些规则分别指定了源地址、目的地址、传输协议等,并按数据包与规则是否匹配采取accept、reject、drop等action
- rule 通常不只一个,所以多个rule 组成一个链,链分为自定义链和默认链
-
根据链生效位置、以及host是否开始ip_forward的不同
- 到本机某进程的报文 prerouting–> input
- 开启转发功能时,由本机转发的报文 prerouting –> forward ==> postrouting
- 由本机的某进程发出报文 output –> postrouting
- 自定义链允许我们以自定义名称组织相关的规则,要被默认链引用,才可以生效
Chain INPUT (policy ACCEPT) target prot opt source destination cali-INPUT all -- anywhere anywhere /* cali:Cz_u1IQiXIMmKD4c */ Chain cali-INPUT (1 references) target prot opt source destination ACCEPT all -- anywhere anywhere /* cali:i7okJZpS8VxaJB3n */ mark match 0x1000000/0x1000000 DROP ipencap-- anywhere anywhere /* cali:p8Wwvr6qydjU36AQ */ /* Drop IPIP packets from non-Calico hosts */ ! match-set cali4-all-hosts src
brctl
写的挺好,都不忍心翻译
Software defined networking (SDN) is the current wave sweeping the networking industry. And one of the key enablers of SDN is virtual networking. While SDN and virtual networking are in vogue these days, the support for virtual networking is not a recent development. And Linux bridge has been the pioneer in this regard.(简述SDN、virtual networking、Linux Bridge之间的关系)
Virtual networking requires the presence of a virtual switch inside a server/hypervisor. Even though it is called a bridge, the Linux bridge is really a virtual switch and used with KVM/QEMU hypervisor. Linux Bridge is a kernel module, first introduced in 2.2 kernel (circa 2000). And it is administered using brctl command on Linux.
以下来自man btctl
The command brctl addbr <name> creates a new instance of the ethernet bridge. The network interface corresponding to the bridge will be called “name”.
The command brctl delbr <name> deletes the instance “name” of the ethernet bridge. The network interface corresponding to the bridge must be down before it can be deleted!
Each bridge has a number of ports attached to it. Network traffic coming in on any of these ports will be forwarded to the other ports transparently, so that the bridge is invisible to the rest of the network.
The command brctl addif <brname> <ifname> will make the interface “ifname” a port of the bridge “brname”. This means that all frames received on “ifname” will be processed as if destined for the bridge.
总的来说,就是使用brctl
- 可以查看所有的linux bridge,增加和删除linux bridge
- 针对一个linux bridge,可以将一个interface挂到bridge或移除,可以查看“挂到”上面的所有interface
- 每建一个网桥,都会建一个跟网桥同名的interface,并挂在网桥上面。
引用
http://fishcried.com/2016-02-09/openvswitch-ops-guide/