简介
tus
服务端tusd
代码上
go中一个http server的标准写法
http.Handle("/foo", fooHandler)
http.HandleFunc("/bar", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %q", html.EscapeString(r.URL.Path))
})
log.Fatal(http.ListenAndServe(":8080", nil))
tusd 将 path / 绑定大一个自定义Handler中,该Handler使用 PatternServeMux 而不是 http package默认的DefaultServeMux 来处理 请求path与方法映射。
所以在 UnroutedHandler 中定义了服务端的主要逻辑:
- PostFile,用于声明创建一个文件,服务端返回文件id
- HeadFile,查询文件断点
- PatchFile,write chunk
- GetFile,下载文件
- DelFile,放弃上传文件,并通知服务端释放资源
UnroutedHandler 除了完成事件通知,异常处理外,将输入参数转换为StoreComposer/DataSource 的参数与返回值,核心工作交给StoreComposer完成。StoreComposer是一个开放接口,represents a composable data store. It consists of the core data store and optional extensions.
type StoreComposer struct {
Core DataStore
UsesTerminater bool
Terminater TerminaterDataStore
UsesFinisher bool
Finisher FinisherDataStore
UsesLocker bool
Locker LockerDataStore
UsesGetReader bool
GetReader GetReaderDataStore
UsesConcater bool
Concater ConcaterDataStore
}
type DataStore interface {
NewUpload(info FileInfo) (id string, err error)
WriteChunk(id string, offset int64, src io.Reader) (int64, error)
GetInfo(id string) (FileInfo, error)
}
type FileInfo struct {
ID string
Size int64
Offset int64
MetaData MetaData
IsPartial bool
IsFinal bool
PartialUploads []string
}
以FileStore为例,每次写入一个chunk,都是新建一个文件(假设文件名为id),同时对应id.info 文件,info文件内容为FileInfo 对象序列化之后的值。分片的归并,就是对所有分片文件进行合并。
感觉服务端代码完成度不是很高
- 采取文件分片,然后合并,文件片过小时,意味着大量的io
- 暂时还未发现水平扩展能力
客户端
tus android端依赖java端,由此可见,各平台逻辑比较一致。
主要包括以下几个类
- TusClient,根据TusUpload创建TusUploader,初始化URL connection以及提前获取文件offset等操作。
- TusUpload,封装一个文件
-
TusUploader,关键就在于其构造方法
TusUploader uploader = client.resumeOrCreateUpload(upload);TusUploader(TusClient client, URL uploadURL, TusInputStream input, long offset),调用uploadChunk,从offset开始, 将一个分片的数据,利用uploadURL发送出去。至此,核心上传流程为:while(uploader.uploadChunk() > -1) {} uploader.finish(); - TusExecutor,TusExecutor is a wrapper class which you can build around your uploading mechanism and any exception thrown by it will be caught and may result in a retry. TusExecutor的核心逻辑是包裹 可以观察到整个上传过程是TusUploader和TusExecutor 协作进行的。
小结
tus的基本理念:
- 在tus中,File是第一个操作对象,所谓分片的归并,只是contact File而已。contact file时,每个文件对应分片上传的分片。
- tus每一个文件/分块支持断点续传,断点信息存储在服务端。值得一提的是,如果你本来就想contact File,每个file的成功与失败还是要自己保证的,tus无法告诉你整个contact file的断点。
可以学到的东西:
- metric 性能检测
- 事件机制
- build around your uploading mechanism
七牛
- 上传空间管理
- 文件上传
API概览定义一个基本的协议api,http形式,然后是各个平台(android,ios,java sdk)的客户端代码封装,各平台客户端代码开源。
七牛云用户端
- 注册个人账号,进行实名认证
- “资源主页” ==> “对象存储” ==> 立即添加
- 设置存储空间
- 创建分区(bucket),类似于文件夹的概念
java客户端
整体上传流程
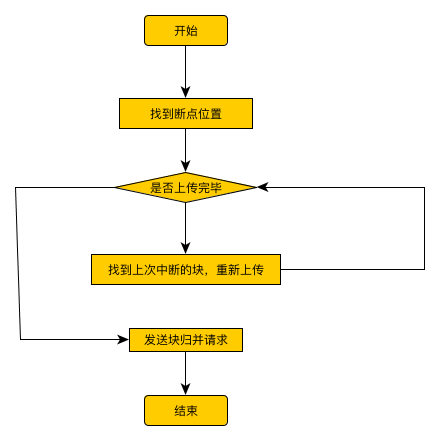
分块上传流程
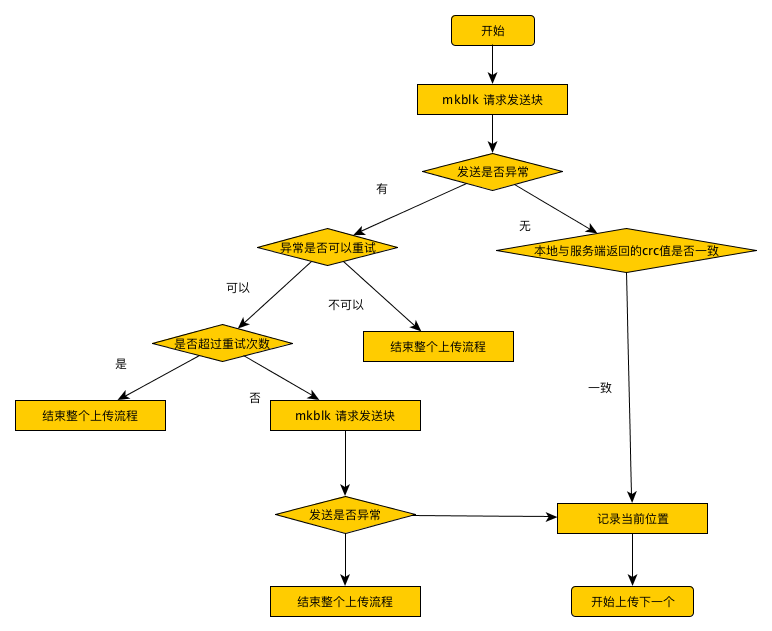
类图
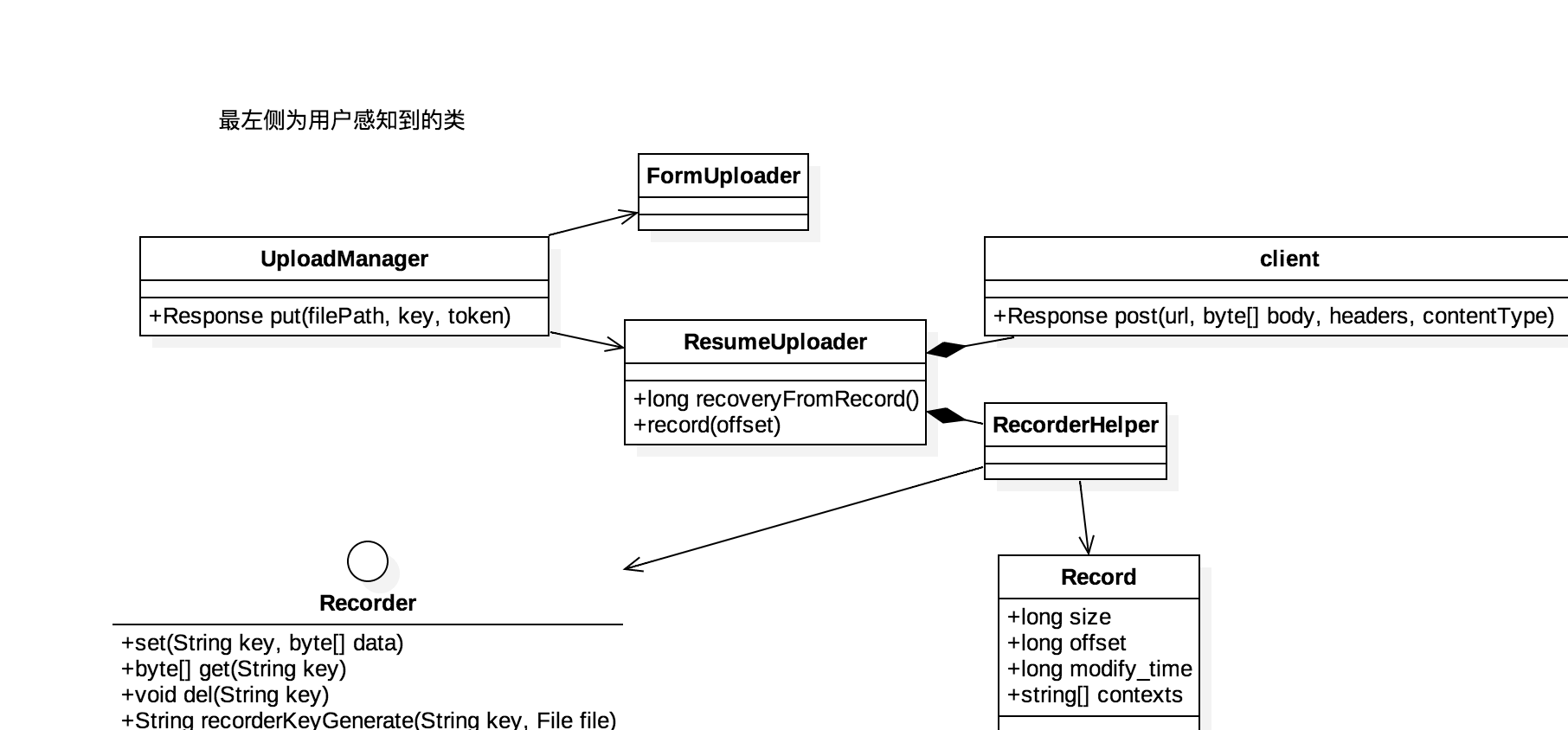
一个XXUploader对象负责一个文件的上传,它会存储中间状态信息,处理重试逻辑。
-
整体
- 如果文件大小小于4m(也是分块的大小)使用form 上传(FormUploader),大于4m采用断点续传(ResumeUploader)
- 有一个最大重试次数,定义了整个文件重传的次数。对于一个特定文件块,只重传一次,重试失败立即结束。
- 发送块失败一次,则更换上传host
- 断点
-
断点位置记录在客户端,存储方式根据Recorder实现而定,一般为FileRecorder
-
本地有一个目录,专门存储进度文件。文件名:
文件名.文件地址,文件内容:Record (进度类)gson 序列化后的字符串的字节数组。
-
-
上传块
- 上传块时只需指定block size和 token(由注册账号后得到的accessKey、secretKey以及创建的bucket拼接而成)。返回该块的唯一标识符ctx和crc32,用户后续工作。创建块
- crc校验在客户端做
-
创建文件
- 分块直接上传(对应mkblk请求),分块创建完毕后,发送创建文件请求(对应mkfile请求),内容是分块归并信息。
android 客户端
上传流程(此处未包含异常处理)
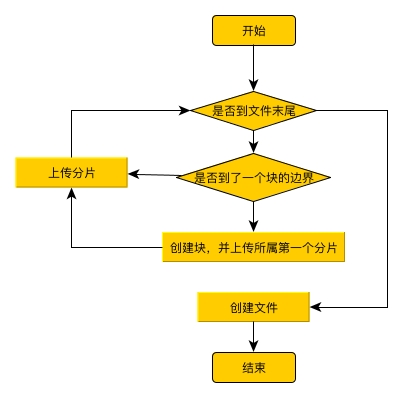
- 文件分块(块大小4m),块又分片,块大小不变。分片大小由用户传入,可根据网络情况,每个文件都不同。
- 通过递归实现类似循环的效果
- 采用okHttp的异步上传,Uploader状态更改写在回调中,因此会有并发上传的效果
七牛协议小结
- 因为带有用户token,可以直接上传分片,然后返回分片标识。无需先向服务端申请分片标识,然后发送分片数据。
- 分片上传过程中,可以随意切换上传host,只要带的是同一个token就行,这意味着七牛云有能力进行跨主机的分片合并
- 七牛基本上没有自定义的http header,也没有使用特别的http方法类型
- 表单上传、分片上传、流式上传同时支持,根据入参及文件大小做出选择
- 上传之前,Zone对象负责判断临近区域的host
- 通过文件、块和片三个粒度,兼顾了pc与mobile端的实际情况,提供了较为统一的接口
其它材料
- 分片的一个好处,如果网络状态较差,可以自动停止上传,提示用户在网络状态稍好时,继续上传。
- 小文件场景下,建议分片大小为2M
- 如果文件小于10M,md5可以在1s内完成,那么通过md5判断文件是否上传过,从而实现秒传。并且对于部分格式的文件,对部分信息计算md5即可判断文件的唯一性。
izhangzhihao/FileUpload.Java mvc 分片上传服务端实现,实现太简单了。
对象存储
存储系统与其它系统的边界:基本确定是在做一个对象存储系统,提供上传能力,返回文件地址。至于说具体业务线要对上传业务做何种处理, 业务client 在拿到文件地址后,可另外请求业务系统处理。
虚拟座谈会:有关分布式存储的三个基本问题对象存储、文件存储与块存储之间的关系
- 首先对象存储和文件存储的区别是不大的,存储的都是一样的东西,只是抛弃了统一的命名空间和目录树的结构
- 独立的互联网存储服务一般都是做对象存储的,因为块存储是给计算机用的,对象存储是给浏览器等HTTP客户端用的。
- 可用性是存储系统的基本性能,提高可用性的办法是多副本,多副本就会带来一致性问题。不仅数据库会有一致性问题,存储系统、文件系统、磁盘都会有一致性问题,比如磁盘的raid,只是不太为大家所常见。
如今市面上几种最流行的开源对象存储解决方案:
- Ceph
- Minio
- OpenStack Swift
- fastdfs
如果后端存储采用fastdfs的话,我的工作就是为fastdfs实现一个android和ios 客户端。
小结
通过对两个协议的分析汇总,可以得到以下共同点
- 使用http、使用分片
- 客户端先传分片数据,并确保所有分片在重试次数范围内全部上传成功。再发送文件请求,携带归并文件数据
不同点:
| 七牛 | tus | |
|---|---|---|
| 断点 | 客户端负责断点存储 | 服务端负责断点存储 |
| crc校验 | 有 | 没有 |
| 并发 | android客户端可以并发执行 | 不支持 |
| 重试 | 失败后直接重试 | 失败后分别按300ms,500ms,1s,2s重试 |
| 默认分片大小 | 4M | 2M |
| 各平台客户端一致性 | 不一致 | 一致 |
其它问题:
- 水平扩展。使用sticky session(配置nginx),或将服务器选择加入到协议中。
- 服务器文件合并,直接合并,或许可以用下pika(pika装在本机)