简介
采集方式
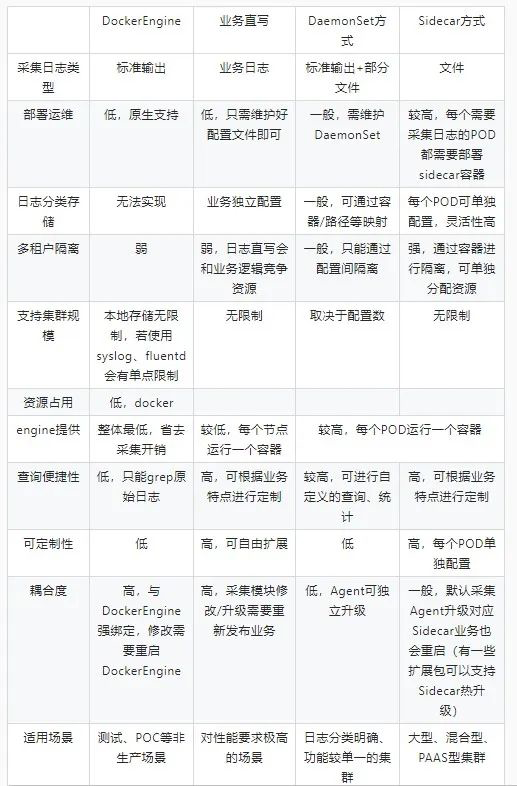
SideCar 模式 VS Node 模式
- sidecar 模式,每个 Pod 中都附带一个 logging 容器来进行本 Pod 内部容器的日志采集,一般采用共享卷的方式
- 在集群规模比较大的情况下,或者说单个节点上容器特别多的情况下,很明显的一个问题就是占用的资源比较多
- 对日志存储后端占用过多的连接数。
- node 模式,在每个 Node 节点上仅需布署一个 logging 容器来进行本 Node 所有容器的日志采集。最明显的优势就是占用资源比较少,同样在集群规模比较大的情况下表现出的优势越明显。但对于这种模式来说我们就需要一个更加智能的日志采集工具来配合
采集组件
- fluentd,CNCF社区
- filebeat,来自Elastic
- flume
- 阿里千万实例可观测采集器-iLogtail正式开源
Stdout VS 文件
容器提供标准输出和文件两种方式,
- 在容器中,标准输出将日志直接输出到 stdout 或 stderr,实际的业务场景中建议大家尽可能使用文件的方式
- Stdout 性能问题,从应用输出 stdout 到服务端,中间会经过好几个流程(例如普遍使用的 JSON LogDriver):应用 stdout -> DockerEngine -> LogDriver -> 序列化成 JSON -> 保存到文件 -> Agent 采集文件 -> 解析 JSON -> 上传服务端。整个流程相比文件的额外开销要多很多,在压测时,每秒 10 万行日志输出就会额外占用 DockerEngine 1 个 CPU 核;
- Stdout 不支持分类,即所有的输出都混在一个流中,无法像文件一样分类输出,通常一个应用中有 AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog 等,而这些日志的格式、用途不一,如果混在同一个流中将很难采集和分析;
- Stdout 只支持容器的主程序输出,如果是 daemon/fork 方式运行的程序将无法使用 stdout;
- 文件的 Dump 方式支持各种策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对更加灵活。
- 日志打印到文件的方式和虚拟机/物理机基本类似,只是日志可以使用不同的存储方式,例如默认存储、EmptyDir、HostVolume、NFS 等。
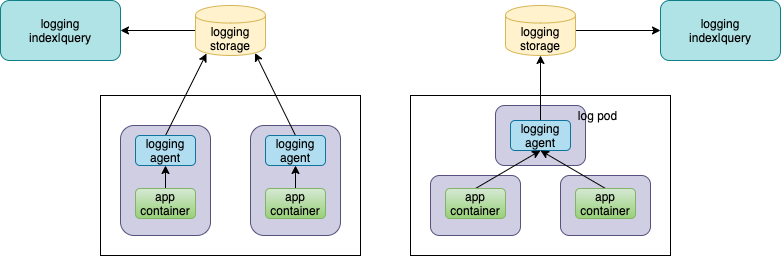
「Allen 谈 Docker 系列」之 docker logs 实现剖析对于应用的标准输出(stdout)日志,Docker Daemon 在运行这个容器时就会创建一个协程(goroutine),负责标准输出日志。由于此 goroutine 绑定了整个容器内所有进程的标准输出文件描述符,因此容器内应用的所有标准输出日志,都会被 goroutine 接收。goroutine 接收到容器的标准输出内容时,立即将这部分内容,写入与此容器—对应的日志文件中,日志文件位于/var/lib/docker/containers/<container_id>,文件名为
Docker 则通过 docker logs 命令向用户提供日志接口。docker logs 实现原理的本质均基于与容器一一对应的 <container-id>-json.log,kubectl logs类似
腾讯云容器服务日志采集最佳实践 从公有云或私有云来说,不应对实现加以限制,采集什么(stdout/容器文件/host文件);文件吐到哪里;如何解析日志格式;日志过滤/时间戳自定义;日志查询等 等都可以支持可配。
采集什么
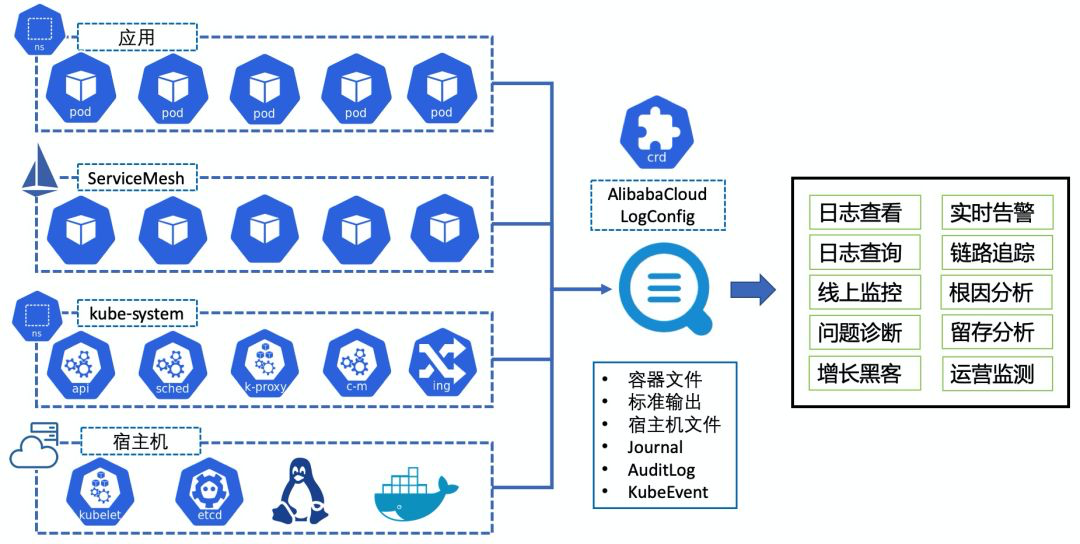
- 容器文件,比如容器运行了Tomcat,则Tomcat 的启动日志也在采集范围之内
- 容器 Stdout
- 宿主机文件
- Journal
- Event
- 支持多种采集部署方式,包括 DaemonSet、Sidecar、DockerEngine LogDriver 等;
- 支持对日志数据进行富化,包括附加 Namespace、Pod、Container、Image、Node 等信息;
- 稳定、高可靠,基于阿里自研的 Logtail 采集 Agent 实现,目前全网已有几百万的部署实例;
- 基于 CRD 进行扩展,可使用 Kubernetes 部署发布的方式来部署日志采集规则,与 CICD 完美集成。
log-pilot
启动
容器(以DaemonSet方式运行)启动时,执行entrypoint /pilot/entrypoint entrypoint 是一个可执行脚本,根据ENV_PILOT_TYPE 判断使用哪个采集插件,以filebeat为例,并执行启动命令/pilot/pilot -template /pilot/filebeat.tpl -base /host -log-level debug
容器内的一些关键文件
/pilot
/entrypoint
/pilot
/filebeat.tpl
/usr/bin/filebeat
/etc/filebeat
/filebeat.yml
/prospectors.d // 容器的配置文件
/modules.d // 各种存储后端的配置文件
- log-pilot 比较喜欢用环境变量,比如采集插件/组件 使用fluentd 还是filebeat 都是由环境变量指定
PILOT_TYPE=filebeat后来镜像专门区分开registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat和registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-fluentd - fluentd/filebeat 就像nginx 一样,根据配置文件运行,本身不具备动态发现容器日志文件的能力,log-pilot 对其封装了下(exec.Command 启动
/usr/bin/filebeat -c /etc/filebeat/filebeat.yml)。就像istio pilot-agent 对envoy 所做的那样。 - log-pilot 监听docker 拿到container 数据(比如container的label),如果container 是新的, 并为container 生成一个filebeat yml 文件,reload filebeat(filebeat 本身会动态 发现
/prospectors.d下的配置文件,reload fluentd则需要向 fluentd 进程发送syscall.SIGHUP 信号 ),filebeat 便可以搜集容器日志发往后端存储了。
源码分析
log-pilot 源码目录
log-pilot
pilot
pilot.go
piloter.go
filebeat_piloter.go
fluentd_piloter.go
main.go

pilot 和 piloter 有着明确的分工
- pilot 负责解析解析、监听容器事件、根据piloter 对应的tpl 文件创建 容器实例对应的yml 文件,start/reload piloter
- piloter 相对简单一些,就是根据 配置文件采集 log发往存储后端
启动过程
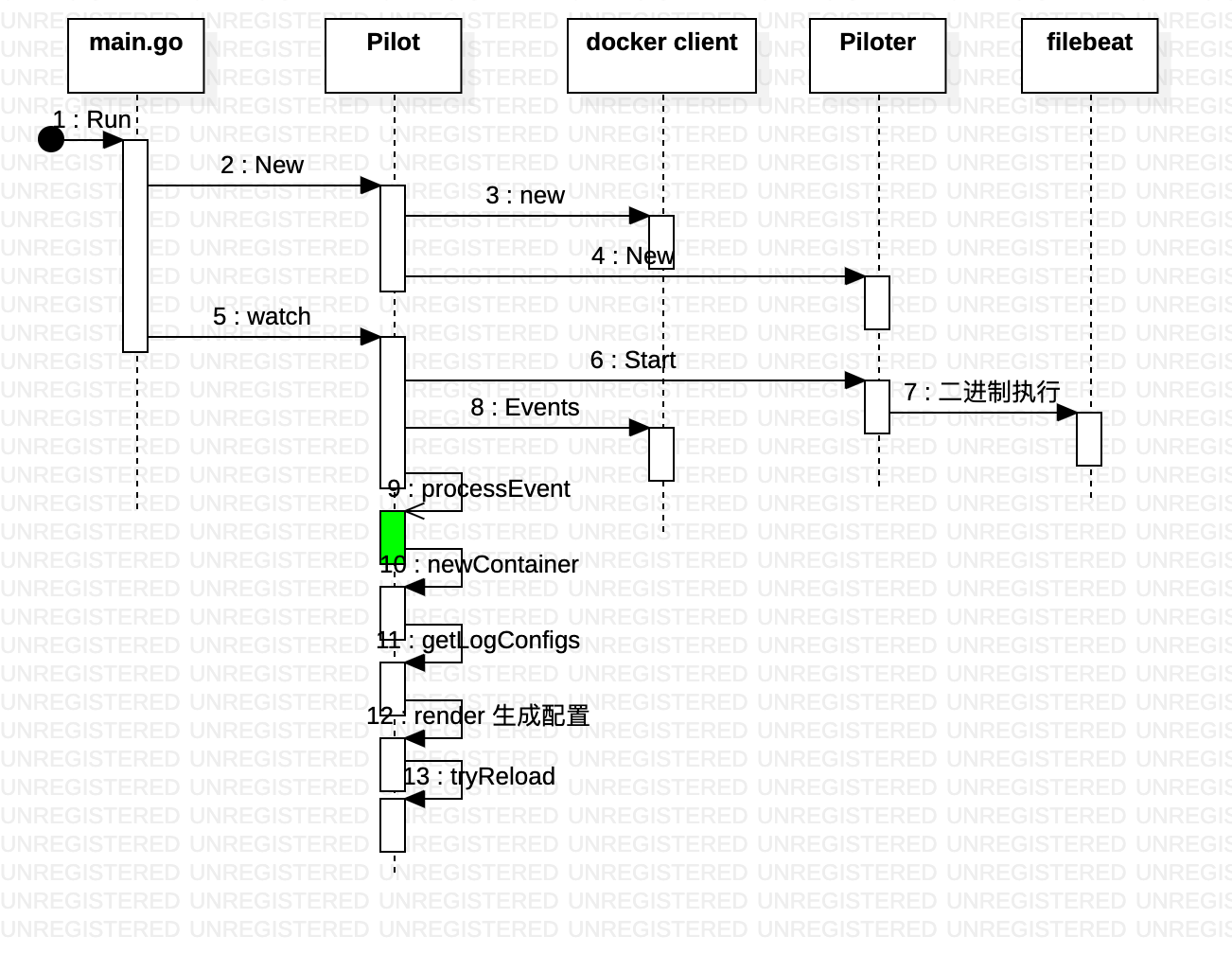
通过docker client 监听event 数据
func (p *Pilot) watch() error {
err := p.piloter.Start()
...
msgs, errs := p.client.Events(ctx, options)
go func() {
log.Info("begin to watch event")
for {
select {
case msg := <-msgs:
if err := p.processEvent(msg); err != nil {
log.Errorf("fail to process event: %v, %v", msg, err)
}
case err := <-errs:
...
}
}
}()
err := p.processAllContainers()
...
<-p.stopChan
}
为每一个容器生成filebeat yml文件
Log-Pilot 支持声明式日志配置,可以依据容器的 Label 或者 ENV 来动态地生成日志采集配置文件,或者说采集哪些容器的哪些日志。采集带有 PILOT_LOG_PREFIX.logs.$name=$path 容器标签(注意不是pod 标签) 或PILOT_LOG_PREFIX_logs_$name=$path 容器env 的容器。
name 和 path的含义
- name:我们自定义的一个字符串,它在不同的场景下指代不同的含义。当我们将日志采集到 ElasticSearch 的时候, name 表示的是 Index;当我们将日志采集到 Kafka 的时候, name 表示的是 Topic;当我们将日志采集到阿里云日志服务的时候,name 表示的是 LogstoreName。
- path:它本身支持两种,
- 一种是约定关键字 stdout,表示的是采集容器的标准输出日志,比如我们要采集 tomcat 容器日志,那么我们通过配置标签
log.catalina=stdout来采集 tomcat 标准输出日志 - 第二种是容器内部的具体文件日志路径,可以支持通配符的方式。通过配置标签
log.access=/usr/local/tomcat/logs/*.log来采集 tomcat 容器内部文件日志。
- 一种是约定关键字 stdout,表示的是采集容器的标准输出日志,比如我们要采集 tomcat 容器日志,那么我们通过配置标签
filebeat.tpl 内容
- type: log
enabled: true
paths:
- /
scan_frequency: 10s
fields_under_root: true
docker-json: true
json.keys_under_root: true
fields:
:
:
tail_files: false
close_inactive: 2h
close_eof: false
close_removed: true
clean_removed: true
close_renamed: false
Pilot.processEvent ==> Pilot.newContainer ==> Pilot.render ==> WriteFile
某个容器对应的 filebeat yml 文件示例
- type: log
enabled: true
paths:
- /host/var/lib/docker/containers/068eef0de2acd07f4b4d20d3e51e173ee02e5c3d9c1e403857f23e45d432cab0/068eef0de2acd07f4b4d20d3e51e173ee02e5c3d9c1e403857f23e45d432cab0-json.log*
scan_frequency: 10s
fields_under_root: true
docker-json: true
fields:
app_name: $APP_NAME
index: stdout
topic: stdout
docker_container: k8s_$APP_NAME_$POD_NAME_default_3f53634c-7f34-4148-821b-83b0f4b4d154_0
k8s_container_name: $APP_NAME
k8s_node_name: 192.168.60.96
k8s_pod: $POD_NAME
k8s_pod_namespace: default
tail_files: false
close_inactive: 2h
close_eof: false
close_removed: true
clean_removed: true
close_renamed: false
- type: log
enabled: true
paths:
- /host/var/lib/kubelet/pods/3f53634c-7f34-4148-821b-83b0f4b4d154/volumes/kubernetes.io~empty-dir/tomcat-logs/catalina.*.log
scan_frequency: 10s
fields_under_root: true
fields:
app_name: $APP_NAME
index: tomcat
topic: tomcat
docker_container: k8s_$APP_NAME_$POD_NAME_default_3f53634c-7f34-4148-821b-83b0f4b4d154_0
k8s_container_name: $APP_NAME
k8s_node_name: 192.168.60.96
k8s_pod: $POD_NAME
k8s_pod_namespace: default
tail_files: false
close_inactive: 2h
close_eof: false
close_removed: true
clean_removed: true
close_renamed: false
本地日志清理
从物理机角度,有一个方案是执行docker system df -v 可以列出每个容器占用的 磁盘空间,当期大小超过一定阈值时,可以根据container id 将其删除。
CONTAINER ID IMAGE COMMAND LOCAL VOLUMES SIZE CREATED ago STATUS NAMES
2ba3bb81f4a6 harbor.test.ximalaya.com/test/wws-library-web:20190305-190207 "/sbin/my_init" 0 3.76MB 40 minutes ago ago Up 40 minutes mesos-8f4307c7-6a44-467e-9a94-56e09182013d
98e129663d1c harbor.test.ximalaya.com/test/anchor-sell-web:20190305-182739 "/sbin/my_init" 0 2.47MB About an hour ago ago Up About an hour mesos-60309b8a-27bd-4744-99f9-685f68dca71a
cd38d9c7fb71 test/docker-count-service-album-test:6 "/usr/local/tomcat/b…" 0 49.2MB 2 hours ago ago Up 2 hours mesos-33f4264e-77fc-4a4f-84c7-aae78519c0ad
使用定时任务每天执行docker system prune -af