前言
github 地址CodisLabs/codis 基于go 语言开发,是一个很好的了解go 及 分布式开发的项目。
Codis 使用文档 Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有显著区别 (不支持的命令列表), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务。
集群解决方案——Smart Client VS Proxy
Redis多实例通常有3个使用途径
- 客户端静态分片,一致性哈希;也称为Smart Client
- 通过Proxy分片,即Twemproxy;
- 官方的Redis Cluster
服务端的改造来自官方,暂时不考虑, 所以一般争论也在Smart Client 和 Proxy 之间。
需求目标
- 支持分片
- Zookeeper ==> Proxy 无状态
- 平滑扩容/缩容
- 扩容对用户透明
- 图形化监控一切
Proxy拥有更好的监控和控制,同时其后端信息亦不易暴露,易于升级;而Smart Client拥有更好的性能(因为没有中间层),及更低的延时,但是升级起来却比较麻烦。从各种大厂的方案看,都比较推崇Proxy
整体结构
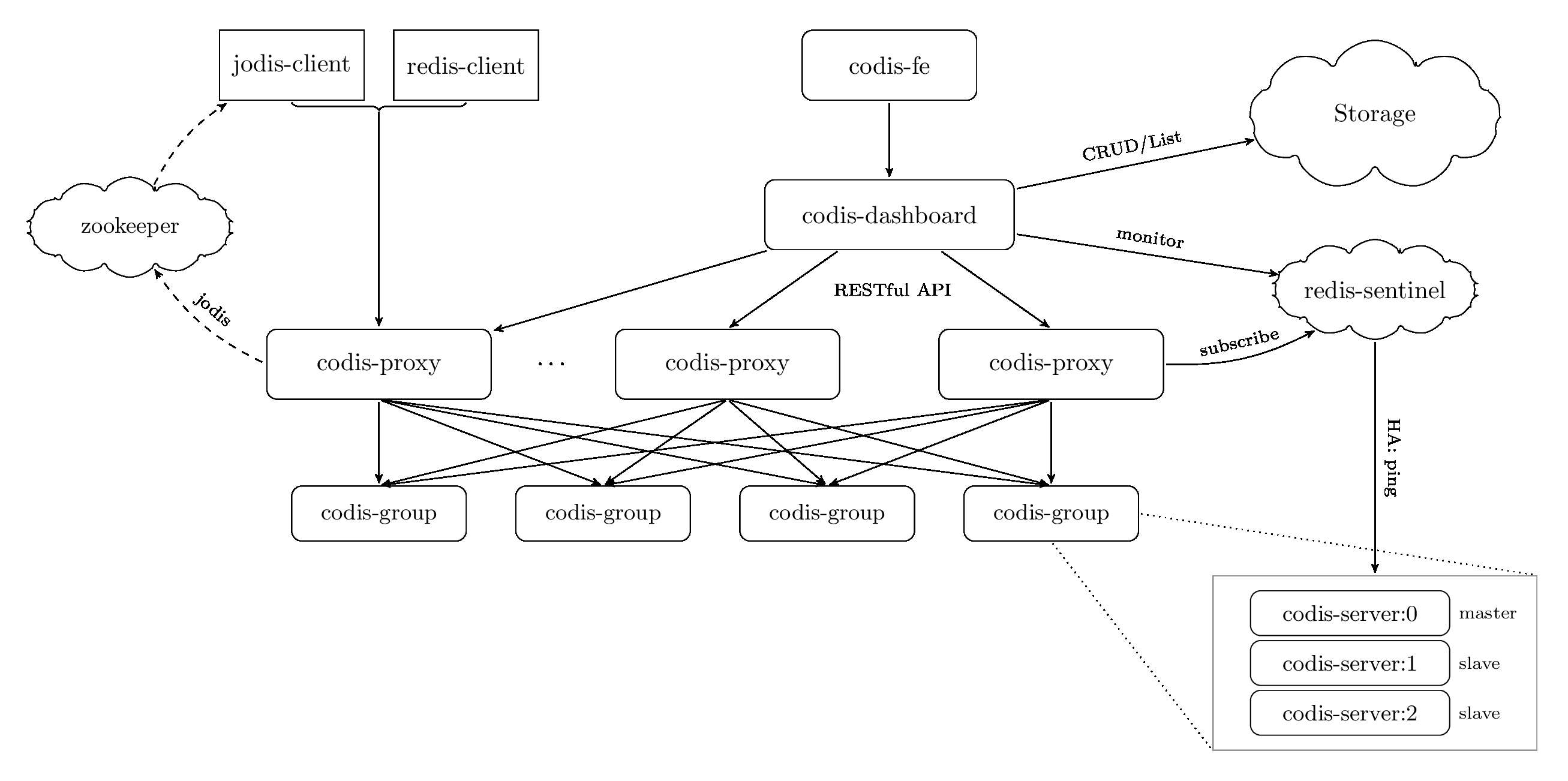
- codis-proxy 。客户端连接的Redis代理服务,本身实现了Redis协议,表现很像原生的Redis (就像 Twemproxy)。一个业务可以部署多个 codis-proxy,其本身是无状态的。
- codis-server。Codis 项目维护的一个Redis分支,加入了slot的支持和原子的数据迁移指令。
源码分析
几个好奇
- proxy 的基本逻辑就是转发,既做服务端也做客户端,在代码上如何体现?
- 如何自动做rebalance?slot hash关键逻辑是啥?
- 和zk的协作方式是啥?
主要是两个package
- cmd 命令入口,包含main.go文件,通过命令行 启动 socket server 程序等,command-line interfaces 工具用的是 docopt-go
- pkg 各个组件的源码文件。
codis-proxy 模块一共就二三十个go文件,非常适合做go 语言入门
路由规则

看一个codis-dashboard 例子
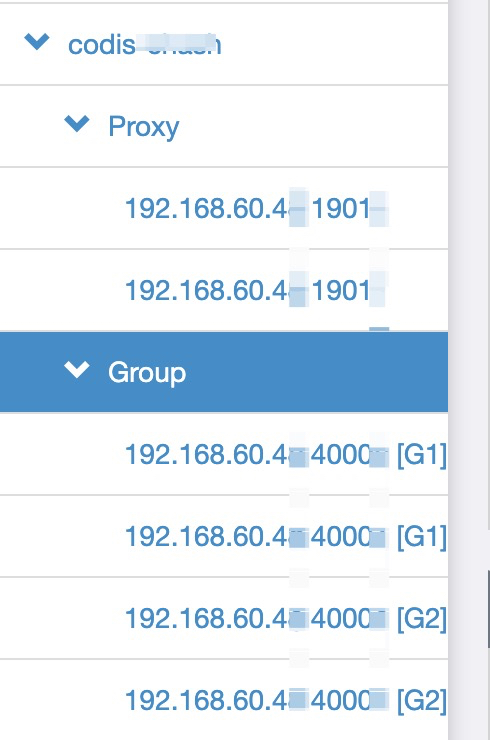
有两个Codis-Proxy,4个Redis实例,分属于两个Group(G1和G2)
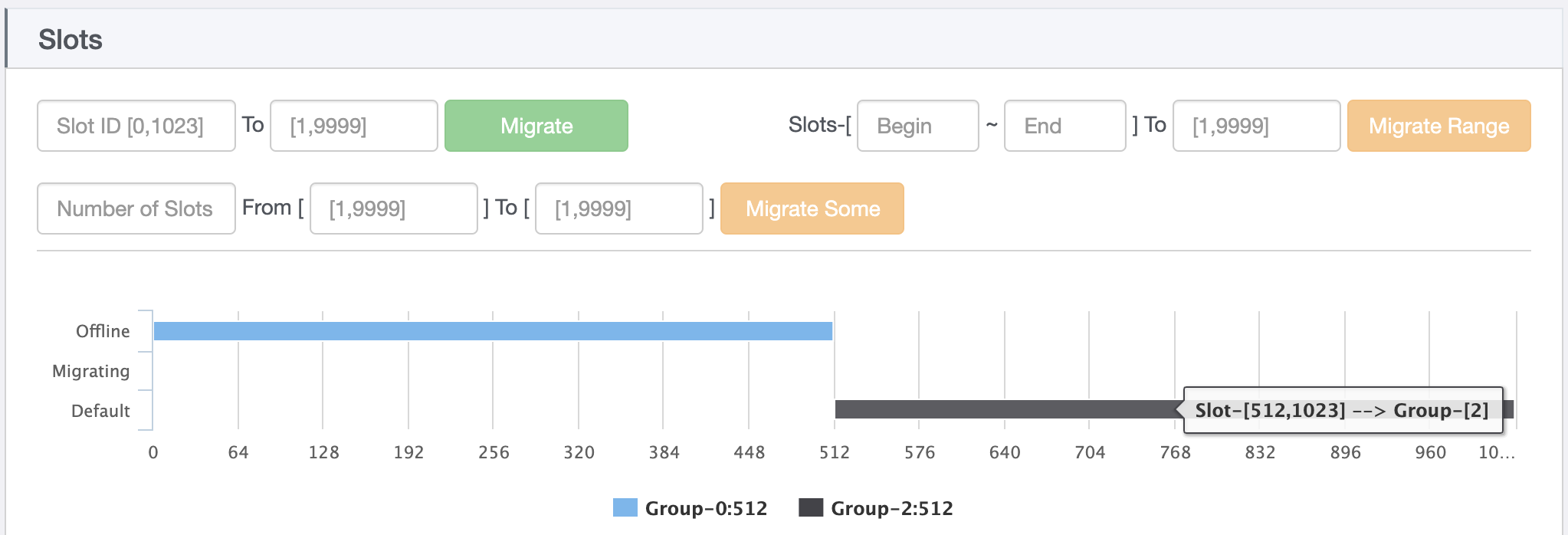
slot 一共1024个,分属于两个Group,其中第一个Group 是offline 状态
请求处理
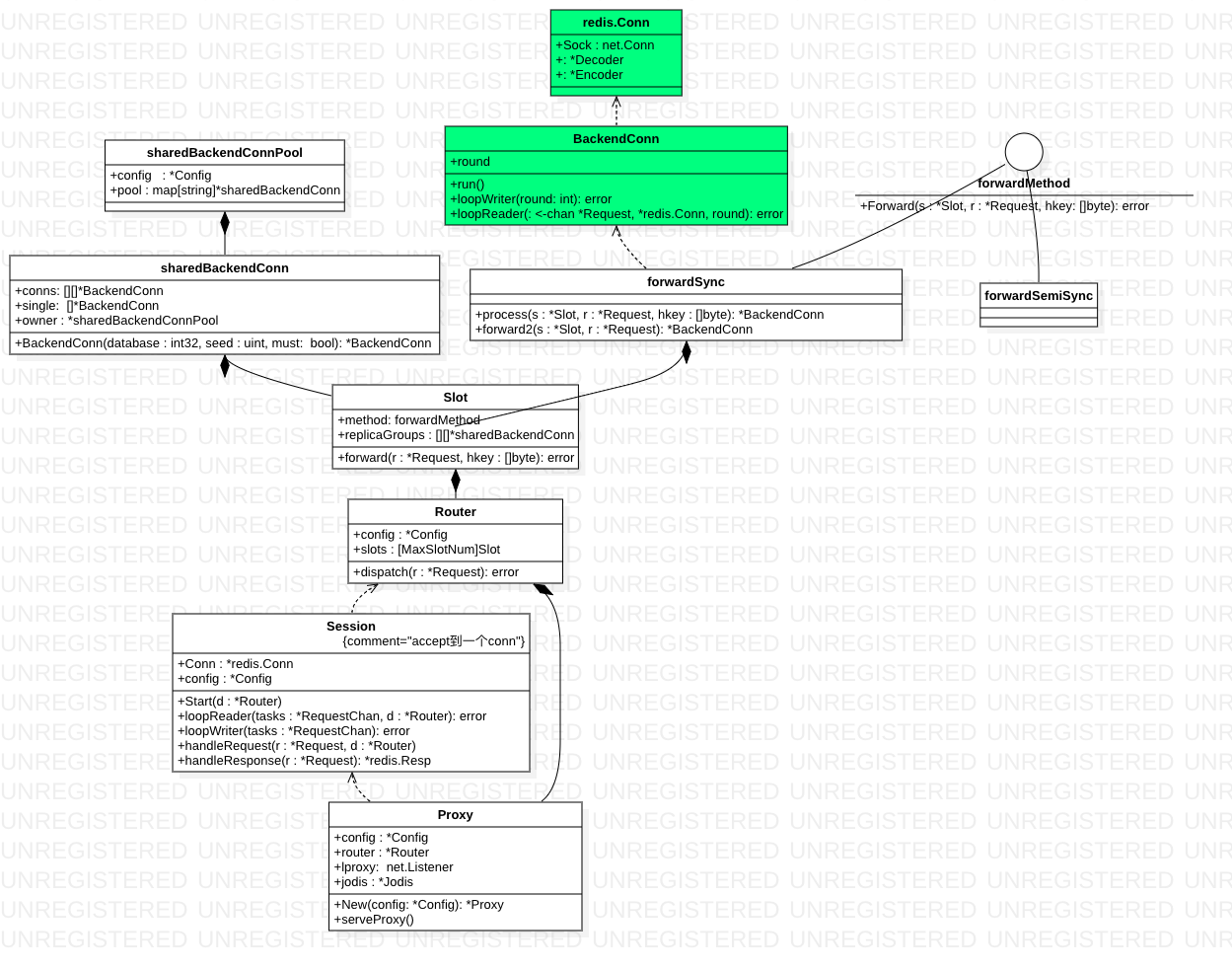
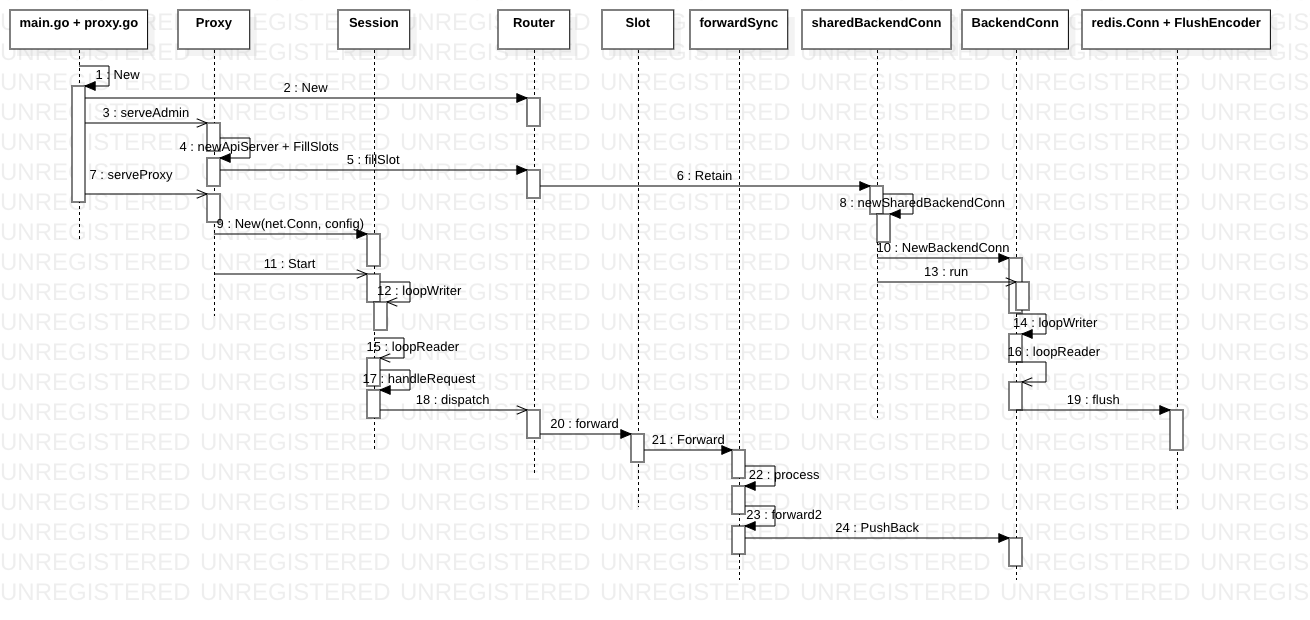
参见 Codis源码解析——proxy的启动 系列
- Proxy每接到一个redis请求,就创建一个独立的session进行处理
- codis将请求与结果关联起来的方式,就是把结果当做request的一个属性
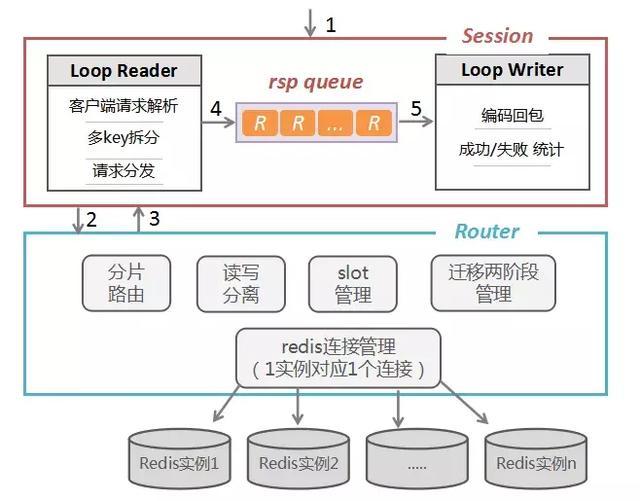
- Session核心就是创建loopReader和loopWriter。loopReader负责读取和分发请求到后端,loopWriter负责合并请求结果,然后返回给客户端。
- forwardSync将指定的slot、request、键的哈希值,经过process得到实际处理请求的BackendConn,然后把请求放入BackendConn的chan *Request中,等待处理
- backendConn负责实际对redis请求进行处理,loopWriter负责从backendConn.input中取出请求并发送,loopReader负责遍历所有请求,从redis.Conn中解码得到resp并设置为相关的请求的属性
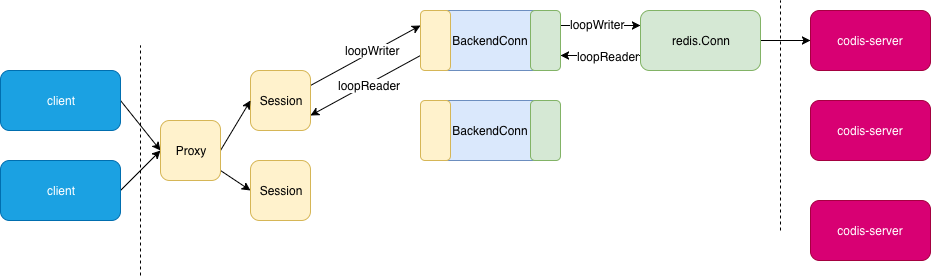
深入浅出百亿请求高可用Redis(codis)分布式集群揭秘 还是腾讯的大神画的有水平
其它
Codis作者黄东旭细说分布式Redis架构设计和踩过的那些坑们
架构师们是如此贪心,有单点就一定要变成分布式,同时还希望尽可能的透明:P。就MySQL来看,从最早的单点到主从读写分离,再到后来阿里的类似Cobar和TDDL,分布式和可扩展性是达到了,但是牺牲了事务支持,于是有了后来的OceanBase。Redis从单点到Twemproxy,再到Codis,再到Reborn。到最后的存储早已和最初的面目全非,但协议和接口永存,比如SQL和Redis Protocol。
我认为,抛开底层存储的细节,对于业务来说,KV,SQL查询(关系型数据库支持)和事务,可以说是构成业务系统的存储原语。为什么memcached/Redis+mysql的组合如此的受欢迎,正是因为这个组合,几个原语都能用上,对于业务来说,可以很方便的实现各种业务的存储需求,能轻易的写出「正确」的程序。但是,现在的问题是数据大到一定程度上时,从单机向分布式进化的过程中,最难搞定的就是事务