简介
《深入浅出Pytorch》理论上,根据万能近似定理(Universal Approximation Theorem)3,对于多层感知机来说,只要参数和隐含层的数量足够,就能够拟合任意的连续函数。此时,多层感知机是模型,模型固定了,就得调整参数 来使模型能够尽量拟合真实世界,调参问题 ==> 求损失函数最小值/梯度下降 ==> 复杂函数对参数微分 ==> 自动微分 ==> 正向传播+反向传播。
学习路径上,先通过单层神经网络(线性回归、softmax回归)理解基本原理,再通过两层感知机理解正向传播和反向传播,增加层数可以增强表现能力,增加特殊的层来应对特定领域的问题。
典型的监督学习由3部分组成:模型、损失函数和优化算法。在数据中发现潜在的模式就是人们常说的模型。有的模型可以通过解析式精确定义,如线性回归、逻辑回归、高斯混合模型等;有的模型则不能,如多层感知机、深度神经网络等。模型训练的过程将模型、损失函数和优化算法 三个部分联系起来,模型f(x)可以千变万化,但本质都是输入数据为x,输出推理值为y的数学函数。损失函数的作用是定量描述推理值y与真实值y_ 的不一致程度,即求得损失值loss。利用损失值和模型的拓扑结构,可以计算出模型参数的梯度,优化算法以一种高效而合理的方式将梯度值更新到对应的模型参数,完成模型的进一步迭代训练。
线性回归
很多人工智能问题可以理解为分类问题,比如判断一个邮件是否为垃圾邮件,根据身高体重预测一个人的性别,当我们将目标特征数值化之后,可以将目标映射为n维度空间上的一个点
从几何意义上来说,分类问题就是 在n维空间上将 一系列点 划分成 不同的集合,以二分为例
- 对于二维空间,分类器就是一条线,直线or 曲线
- 对于三维空间,分类器就是一个面,平面or 曲面
- 对于高维空间,xx
我们要做的就是根据一系列样本点,找到这条“分界线/面”。线性回归假设特征和结果满足线性关系,线性关系的表达能力非常强大,通过对所有特征的线性变换加一次非线性变换,我们可以划一条“近似的分界线/面”,虽然并不完全准确,但大部分时候已堪大用。就像数学中的泰特展开式一样,不管多么复杂的函数,泰勒公式可以用这些导数值做系数构建一个多项式来近似函数在这一点的邻域中的值。而不同的函数曲线其实就是这些基础函数的组合,理所当然也可以用多项式去趋近。
正向传播计算loss
给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。假设有训练样本(x, y),数据有两个特征x1,x2,模型为h,参数为θ,$\theta=(w1,w2,b)$,估计函数$h(x)=g(θ^T x)=g(w_1x_1+w_2x_2+b)$。即对x1,x2 施加一次线性变换 + 非线性变换,($θ^T$表示θ的转置)。因为x1,x2 都是已知的,所以h(θ) 是一个关于θ的函数
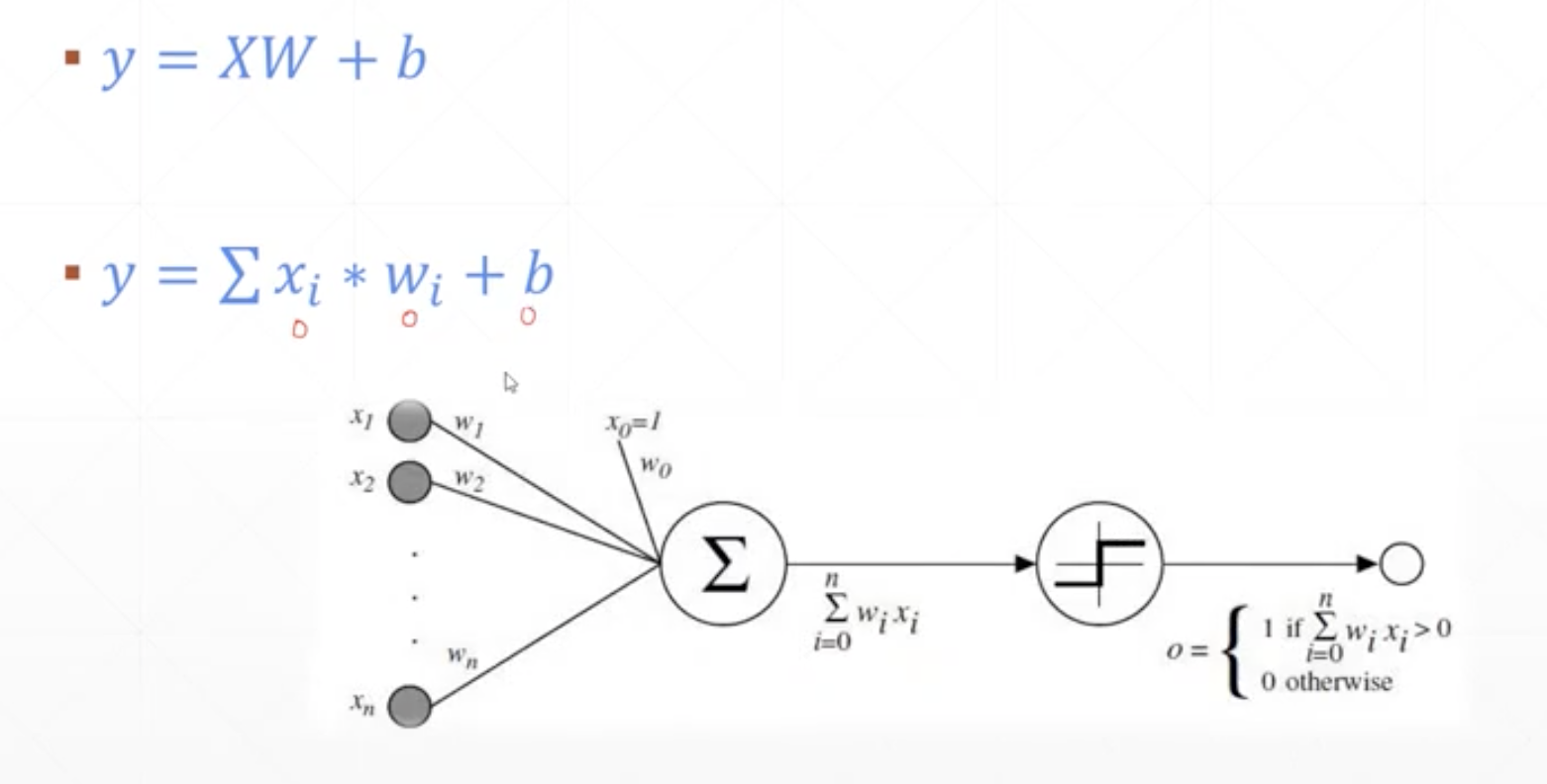
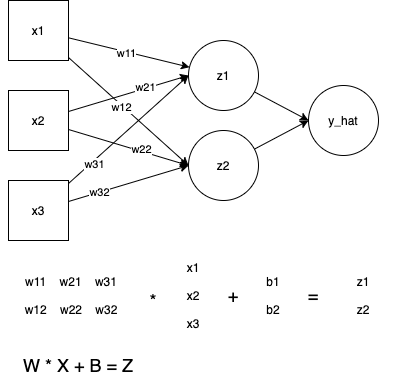
两层神经网络的表示(不同文章的表示用语略微有差异),Z = WX + B Z 可以看做是X经过 线性变换W后的表示。
反向传播计算gradient
反向传播的思路:
-
概况来讲,任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ),如果有多个样本,则可以将所有代价函数的取值求均值,记做J(θ)。因此很容易就可以得出以下关于代价函数的性质:
- 对于每种算法来说,代价函数不是唯一的;
- 代价函数是参数θ的函数;
- 总的代价函数J(θ)可以用来评价模型的好坏,代价函数越小说明模型和参数越符合训练样本(x, y);
- J(θ)是一个标量;
- 当我们确定了模型h,后面做的所有事情就是训练模型的参数θ。那么什么时候模型的训练才能结束呢?这时候也涉及到代价函数,由于代价函数是用来衡量模型好坏的,我们的目标当然是得到最好的模型(也就是最符合训练样本(x, y)的模型)。因此训练参数的过程就是不断改变θ,从而得到更小的J(θ)的过程。理想情况下,当我们取到代价函数J的最小值时,就得到了最优的参数θ.例如,J(θ) = 0,表示我们的模型完美的拟合了观察的数据,没有任何误差。
- 代价函数衡量的是模型预测值h(θ) 与标准答案y之间的差异,所以总的代价函数J是h(θ)和y的函数,即J=f(h(θ), y)。又因为y都是训练样本中给定的,h(θ)由θ决定,所以,最终还是模型参数θ的改变导致了J的改变。
- 在优化参数θ的过程中,最常用的方法是梯度下降,这里的梯度就是代价函数J(θ)对
θ1, θ2, ..., θn的偏导数。由于需要求偏导,我们可以得到另一个关于代价函数的性质:选择代价函数时,最好挑选对参数θ可微的函数(全微分存在,偏导数一定存在)
如何让计算机 求复杂函数的(偏)导数

用pytorch 代码来观察反向传播
y1 = x * w1 + b1
y2 = y1 * w2 + b2
dy2_dy1 = autograd.grad(y2,[y1],retain_graph=True)[0]
dy1_dw1 = autograd.grad(y1,[w1],retain_graph=True)[0]
dy2_dw1 = autograd.grad(y2,[w1],retain_graph=True)[0]
dy2_dw1 可以用公式 推导直接算出来, 也可以 根据 $\frac{dy2}{dw1} = \frac{dy2}{dy1} * \frac{dy1}{dw1}$ 先计算 $\frac{dy2}{dy1}$ ,再使用 $\frac{dy2}{dy1} * \frac{dy1}{dw1}$ 计算 $\frac{dy2}{dw1}$。$\frac{dy2}{dw1}$ 偏导数的计算 先用到了 $\frac{dy2}{dy1}$,此为“反向”。y1 将 y2 对自己的梯度/导数 $\frac{dy2}{dy1}$ 和自己 对w1 梯度 $\frac{dy1}{dw1}$ 传给 w1,w1 将这两者 相乘 即可得到 y2(output) 对自己的梯度, 传播的是 output 对 y1 中间值的 偏导数,此为“反向传播”。PS: 对应到 《用python实现深度学习框架》,从计算图中作为结果的节点开始,依次从后向前,每个节点都将结果 对自己的雅克比矩阵 和 自己对父节点的雅克比矩阵 传给父节点,根据链式法则,父节点将这二者想乘就得到 结果对自己的雅克比矩阵。
[矩阵求导]神经网络反向传播梯度计算数学原理关于反射传播的数学原理,可能就不是那么好理解了,因为这里面需要用到矩阵的高级算法,一般的理工科数学的《线性代数》甚至《高等代数》里面都没有提到相关的内容,对于矩阵的微分是一个“三不管”的地带,但是这个内容又是深度学习神经网络中用得最多的数学原理,所以基本上已经超过了大多数高校学生的知识范围了。在这个时候,就要祭出张贤达的《矩阵分析》了。像数学工具这种内容,建议大家还是去看书,因为书作为几十年的经典教材,其推导过程,内容的完整性,认证的严密性都是经得起推敲的。网络文章只能帮大家启蒙一下,学几个术语,但是具体想深入了解细节,建议还是看书。
优化算法:梯度下降法 ==> 求使得J极小的(w1,w2,b)
优化算法通常采用迭代方式实现:首先设定一个初始的可行解,然后基于特定函数反复重新计算可行解,直到找到一个最优解或达到预设的收敛条件。不同的优化算法采用的迭代策略各有不同:
- 使用目标函数的一阶导数,如梯度下降法。
新解 = 老解 + 学习率 * 梯度 - 使用目标函数的二阶导数,如牛顿法
- 使用前几轮迭代的信息,如Adam。PS: 所以优化器不同,耗费的显存也很不一样
典型的机器学习和深度学习问题通常都需要转化为最优化问题进行求解,模型就是通过不断地减小损失函数值的方式来进行学习的。
给定绝对值足够小的数$\xi$,根据泰勒展开式 $f(x+\xi)\approx f(x)+\xi f’(x)$,f’(x) 是f 在x 处的梯度,一维函数的梯度是一个标量,也称导数。
| 找一个 $\eta > 0$,使得 $ | \eta f’(x) | $ 足够小,那么可以 用 $-\eta f’(x)$ 替换$\xi$ 代入 $f(x+\xi)\approx f(x)+\xi f’(x)$,得到 |
如果导数 f’(x) !=0 , 那么$\eta f’(x)^2 > 0$,所以 \(f(x-\eta f'(x)) < f(x)\)
意味着如果 用$x-\eta f’(x)$ 来迭代 $x$,函数 f(x) 的值会降低。在多元微积分中 也有类似 的证明。这就是梯度下降法可以降低目标函数值的原因。
函数所有偏导数构成的向量就叫做梯度,某个点的 梯度的方向是方向导数中取到最大值的方向,某个点梯度的值(向量的模)是方向导数的最大值(函数在当前点增长的速率)。举例来说,对于3变量函数 $f=x^2+3xy+y^2+z^3$ ,它的梯度可以这样求得 \(\frac{d_f}{d_x}=2x+3y\) \(\frac{d_f}{d_y}=3x+2y\) \(\frac{d_f}{d_z}=3z^2\)
于是,函数f的梯度可表示为 由3个偏导数组成的向量:$grad(f)=(2x+3y,3x+2y,3z^2)$,针对某个特定点,如点A(1, 2, 3),带入对应的值即可得到该点的梯度(8,7,27),朝着向量点(8,7,27)方向进发,函数f的值增长得最快。
对于机器学习来说
- 首先对(w1,w2,b)赋值,这个值可以是随机的,也可以让(w1,w2,b)是一个全零的向量
- 改变(w1,w2,b)的值,使得J(w1,w2,b)按梯度下降的方向进行减少,梯度方向由J(w1,w2,b)对(w1,w2,b)的偏导数确定。PS:求梯度 就是求损失值对每个参数的偏导数。
- $w1=w1+\sigma d_{w1}$ 依次得到 w1,w2,b 的新值,$\sigma$为学习率。 在代码上经常表示为 $w1=w1+\sigma * grad(w1)$
细节问题
正向传播为什么需要非线性激活函数

如果要用线性激活函数,或者没有激活函数,那么无论你的神经网络有多少层,神经网络只是把输入线性组合再输出,两个线性函数组合本身就是线性函数,所以不如直接去掉所有隐藏层。唯一可以用线性激活函数的通常就是输出层
常见激活函数: sigmoid,tanh,ReLU,softMax 机器学习中常用激活函数对比与总结
sigmoid的作用是把输入信号从(-∞,+∞)的定义域映射到(0,1)的值域,且有处处可导的优良数学形式,方便之后的梯度下降学习过程,所以它成为了经常使用的激活函数。
损失函数如何确定
损失函数可以把模型拟合程度量化成一个函数值,损失函数值越小,说明 实际输出 和预期输出 的差值就越小,也就表明构建的模型精确度就越高。损失函数里一般有两种参数:权重和偏置。所谓”学习”,就是不断调整权重和偏置,从而找到神经元之间最合适的权重和偏置,让损失函数的值达到最小。
损失函数是h(θ)和y的函数,本质是关于$\theta$的函数,分为
-
log对数损失函数,PS:概率意义上,假设样本符合伯努利分布
\[L(Y,P(Y|X))=-logP(Y|X)\] -
平方损失函数 ,PS:概率意义上,假设误差符合高斯分布
\[L(Y,h_\theta(X))=(Y-h\_\theta(x))^2\] \[MSE(\theta)=MSE(X,h_\theta)=\frac{1}{m}\sum\_{i=1}^m(\theta^T.x^i-y^i)^2\] - 指数损失函数
- Hinge损失函数
- 0-1损失函数
-
绝对值损失函数
\[L(Y,h_\theta(X))=|Y-h\_\theta(x)|\]
https://zhuanlan.zhihu.com/p/46928319
对线性回归,logistic回归和一般回归的认识 深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点
从自动微分法来理解线性回归
英文论文Automatic Differentiation in Machine Learning: a Survey
《深入理解神经网络》用训练样本做输入向量,逐层计算直到计算出神经网络的输出,此过程称为前向传播。用网络输出和训练标签计算损失值。在训练样本和标签给定的情况下, 损失值可以视作<W,b> 的函数。用梯度下降法来更新<W,b> 以降低损失值,这就是神经网络的训练。 梯度下降法需要计算损失值 对 <W,b> 梯度,也就是损失值对 <W,b> 梯度,也就是损失值对 的偏导数。
最优解(极大值/极小值)在 导数为0 的地方,对于y=f(x),手动可以求解 f'(x)=0 的解(解析解,得到的是 解的表达式而非具体的数值),大部分深度学习模型并没有解析解(比如导数永远大于0)。计算机不擅长求微分方程,所以只能通过插值等方法进行海量尝试,把函数的极值点求出来。 已知 $x_i$,计算dy/dx,进而得到 $x_{i+1}$,使得$f’(x_{i+1})$ 更接近0。结论:求最优解必须 先求微分。
一文读懂自动微分( AutoDiff)原理假设我们定义了 $f(x,y)=x^2y+y+2$
,需要计算它的偏微分 df/dx 和 df/dy 来进行梯度下降,微分求解大致可以分为4种方式:
- 手动求解法(Manual Differentiation),直接算出来 $\frac{df}{dx}=2xy$,用代码实现这个公式。然而大部分深度学习模型不好算公式。 PS: 一些课程 用实际的公式计算单层/两层 感知机 W的梯度
-
数值微分法(Numerical Differentiation),直接对原函数代入数值近似求解。直接 $\lim_{x \to x_0}\frac{h(x)-h(x_0)}{x-x_0}$。
- 符号微分法(Symbolic Differentiation),代替第一种手动求解法的过程,强调直接对代数进行求解,最后才代入问题数值;
- 自动微分法(Automatic Differentiation)
自动微分法是一种介于符号微分和数值微分的方法,自动微分基于一个事实,即每一个计算机程序,不论它有多么复杂,都是在执行加减乘除这一系列基本算数运算,以及指数、对数、三角函数这类初等函数运算。于是自动微分先将符号微分法应用于最基本的算子(不直接算完),比如常数,幂函数,指数函数,对数函数,三角函数等,然后代入数值,保留中间结果,最后再通过链式求导法则应用于整个函数。因此它应用相当灵活,可以做到完全向用户隐藏微分求解过程,由于它只对基本函数或常数运用符号微分法则,所以它可以灵活结合编程语言的循环结构,条件结构等,使用自动微分和不使用自动微分对代码总体改动非常小,并且由于它的计算实际是一种图计算,可以对其做很多优化,这也是为什么该方法在现代深度学习系统中得以广泛应用。
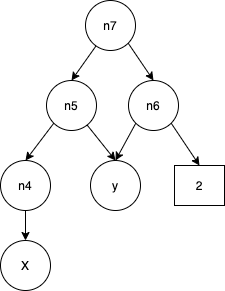
要计算 dy/dx 也就是 dn7/dx,可以先计算 dn7/dn5,即 dn7/dx=dn7/dn5 * dn5/dx,这么链式推导下去。
如果你在Tensorflow 中加入一个新类型的操作,你希望它和自动微分兼容,你需要提供一个函数来建一个计算它的偏导数(相对于它的输入)的图。例如你实现了一个函数来计算输入的平方,$f(x)=x^2$,你需要提供一个偏导数函数 $f’(x)=2x$。
个人理解,对于y=f(x), f'(x) 要么是个常量,要么也是x 的函数。也就是dn7/dn5 不是常量 就是关于n5 的函数,在自上到下 求导(反向传播)用到 dn7/dn5之前,得先自下而上(正向传播)求出来n5 再说。所以正向 + 负向传播加起来 是为了求微分,反向传播依赖正向传播,下一次迭代正向传播依赖本次反向传播。在机器学习框架里,每个node 会包含一个grad 属性,记录了当前的node微分函数或值。
深度学习利器之自动微分(1) 自动微分是一种数值计算方式,计算复杂函数(多层复合函数)在某一点处对某个的导数。又是一种计算机程序,是深度学习框架的标配,是反向传播算法的泛化。文中对比了各种微分算法,解释了梯度以及雅克比矩阵等,值得一读。 深度学习利器之自动微分(2) 讲了自动微分的前向模式与反向模式。
引申:可微分编程是一个比较新的概念,是反向传播和weight-tying的延伸。用户仅指定了函数的结构以及其调用顺序,函数程序实际上被编译成类似于反向传播所需的计算图。图的各个组成部分也必须是可微的,可微分编程把实现/部署的细节留给优化器——语言会使用反向传播根据整个程序的目标自动学习细节,基于梯度进行优化,就像优化深度学习中的权重一样。
早期 Pytorch≈Numpy+AutoGrad,pytorch 封装了torch.autograd包,torch.autograd is PyTorch’s automatic differentiation engine that powers neural network training. 封装了前向后向传播逻辑(实现自动微分)
道理我都懂,但是神经网络反向传播时的梯度到底怎么求? 大牛推荐
逻辑回归
逻辑回归是线性回归的一种特例,激活函数使用 Sigmoid,损失函数使用 log对数损失函数
正向传播过程
\(f(x)=\theta^Tx=w_1x_1+w_2x_2+b\) \(g(z)=\frac{1}{1+e^{-z}}\)
细节问题
激活函数为什么使用Sigmoid
- 它的输入范围是正负无穷,而值刚好为(0,1),正好满足概率分布为(0,1)的要求。我们用概率去描述分类器,自然比单纯的某个阈值要方便很多
- 它是一个单调上升的函数,具有良好的连续性,不存在不连续点
损失函数为什么使用对数损失函数
$h_\theta(x)$与y 只有0和1两个取值
对数损失函数的直接意义
logistic回归详解(二):损失函数(cost function)详解
\[cost(h_\theta(x),y)= \begin{cases} -logh_\theta(x) & \text{if y=1} \\ -log(1-h_\theta(x)) & \text{if y=0} \end{cases}\]当y=1时
- 如果此时$h_θ(x)=1$,$logh_θ(x)=0$,则单对这个样本而言的cost=0,表示这个样本的预测完全准确。
- 如果此时预测的概率$h_θ(x)=0$,$logh_θ(x)=-\infty$,$-logh_θ(x)=\infty$,相当于对cost加一个很大的惩罚项。
当y=0 时类似,所以,取对数在直觉意义上可以将01二值与 正负无穷映射起来
汇总一下就是
| $h_\theta(x)$ | y | cost |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | $\infty$ |
| 1 | 0 | $\infty$ |
| 1 | 1 | 0 |
将以上两个表达式合并为一个,则单个样本的损失函数可以描述为:
\[cost(h_\theta(x),y)= -y\_ilogh\_\theta(x)- (1-y\_i)log(1-h\_\theta(x))\]因为$h_\theta(x)$与y 只有0和1两个取值,该函数与上述表格 或分段表达式等价
全体样本的损失函数可以表示为:
\[cost(h_\theta(x),y)= \sum\_{i=1}^m -y\_ilogh\_\theta(x)- (1-y\_i)log(1-h\_\theta(x))\]对数损失函数的概率意义
对于逻辑回归模型,假定的概率分布是伯努利分布(p未知)
\[P(X=n)= \begin{cases} 1-p & \text{n=0} \\ p & \text{n=1} \end{cases}\]概率公式可以表示为( x只能为0或者1)
\[f(x)=p^x(1-p)^{1-x}\]假设我们做了N次实验,得到的结果集合为 data={x1,x2,x3},对应的最大似然估计函数可以写成
要使上面的式子最大,等价于使加上ln底的式子值最大,我们加上ln的底就可以将连乘转换为加和的形式
\[lnP(data|p)= \sum\_{i=1}^Nx\_ilnp+(1-x\_i)(1-p)\]对数损失函数与上面的极大似然估计的对数似然函数本质上是等价的,xi 对应样本实际值yi,p即 $h_\theta(x)$,所以逻辑回归直接采用对数损失函数来求参数,实际上与采用极大似然估计来求参数是一致的
几何意义和概率意义殊途同归(当然,不是所有的损失函数都可以这么理解)
参数和超参数
parameters: $W^{[1]},b^{[1]},W^{[2]},b^{[2]},…$
超参数hyperparameters: 每一个参数都能够控制w 和 b
- learning rate
- 梯度下降算法循环的数量
- 隐层数
- 每个隐层的单元数
- 激活函数
深度学习的应用领域,很多时候是一个凭经验的过程,选取一个超参数的值,试验,然后再调整。
吴恩达:我通常会从逻辑回归开始,再试试一到两个隐层,把隐藏数量当做参数、超参数一样调试,这样去找比较合适的深度。
为什么批量是一个超参数
训练的目的是 得到一个 <W,b> 使损失函数值最小,损失函数是所有样本数据 损失值的和,是一个关于<W,b> 的函数。理论上来讲,要减小优化的损失是在整个训练集上的损失,所以每次更新参数时应该用训练集上的所有样本来计算梯度。但是实际中,如果训练集太大,每次更新参数时都用所有样本来计算梯度,训练将非常慢,耗费的计算资源也很大。在进行ResNet152对120G的ImageNet数据进行训练时,在使用Batch Size=128,Input Image Size=512x512的前提下,训练过程占用了16G的内存,在GPU一般具有16G内存的情况下,没办法把模型放在一个一块AI芯片上。想进一步加大每次执行数据的Batch size,模型训练的内存占用也会随之增长,最后高于AI芯片的内存容量。
所以用训练集的一个子集上计算的梯度来近似替代整个训练集上计算的梯度。这个子集的大小即为batch size,相应地称这样的优化算法为batch梯度下降。batch size可以为训练集大小,可以更小,甚至也可以为1,即每次用一个样本来计算梯度更新参数。batch size越小收敛相对越快,但是收敛过程相对不稳定,在极值附近振荡也比较厉害。
尤其是batch-size,在GPU处理单元已经充分利用的情况下:
- 增大batch size能增大速度,但是很有限(主要是并行计算的优化)
- 增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。
- 增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch_size 变成全部样本数目)。
梯度震荡:理论和实践证明,随机数据产生的小batch梯度方向,一定程度上可以模拟整个数据的梯度下降方向。但是在实际情况下,小batch梯度并不足够代替整个数据集的梯度方向,每次小batch在BP算法求解出来的梯度方向,与整体数据集并不完全一致。这样就会导致优化迭代(训练)过程不断震荡。
小结
首先你要知道 机器学习的两个基本过程
- 正向传播,线性 + 非线性函数(激活函数) 得到一个估计值
- 反向传播,定义损失函数,通过(链式)求导 更新权重
关键问题
- 激活函数的选择
- 损失函数的选择
- 对损失函数及$\theta$链式求偏导数,涉及到矩阵的导数,根据偏导 + 学习率 调整$\theta$
- 向量化上述过程
- 使用python 中线程的 矩阵/向量计算的库 将上述过程代码化, 涉及到numpy的学习