简介
一开始是kube-batch,后来volcano 逐渐接替了 kube-batch
Volcano 在 Kubernetes 中运行高性能作业实践
必要性
kube-batch在AI计算平台的应用k8s原生的调度器,会将需要启动的容器,放到一个优先队列(Priority Queue)里面,每次从队列里面取出一个容器,将其调度到一个节点上。 分布式训练需要所有worker都启动后,训练才能够开始进行。使用原生调度器,可能会出现以下问题:
- 一个任务包含了10个worker, 但是集群的资源只满足9个worker。原生调度器会将任务的9个worker调度并启动,而最后一个worker一直无法启动。这样训练一直无法开始,9个已经启动的worker的资源被浪费了。
- 两个任务,各包含10个worker, 集群的资源只能启动10个worker。两个任务分别有5个worker被启动了,但两个任务都无法开始训练。10个worker的资源被浪费了。
- 因为运行一个胖业务,饿死大批小业务
示例文件
kube-batch 案例
apiVersion: batch/v1
kind: Job
metadata:
name: qj-1
spec:
backoffLimit: 6
completions: 6
parallelism: 6
template:
metadata:
annotations:
scheduling.k8s.io/group-name: qj-1
spec:
containers:
- image: busybox
imagePullPolicy: IfNotPresent
name: busybox
resources:
requests:
cpu: "1"
restartPolicy: Never
## 使用 kube-batch调度器
schedulerName: kube-batch
---
apiVersion: scheduling.incubator.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: qj-1
spec:
minMember: 6
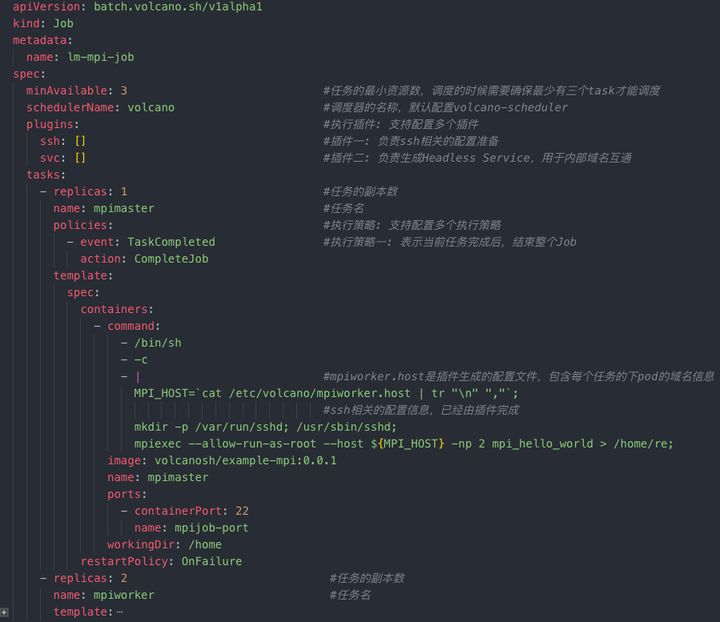
整体设计
volcano 支持自定义的crd jobs.batch.volcano.sh.Job(因此有附属的Controller等)作为workload,也支持第三方workload 直接使用podgroup/queue 等crd 来进行批量调度。
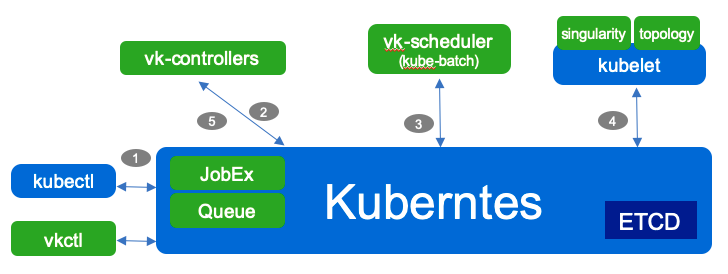
Volcano Controller 依据JobSpec创建依赖的Pod, Service, ConfigMap等资源,执行配置的插件,并负责Job后续的生命周期管理(状态监控,事件响应,资源清理等)。之后,Volcano Scheduler监听Pod资源的创建,依据策略,完成Pod资源的调度和绑定。
整体流程
- 接口:创建xxjob
- Controller
- volcano Controller resync vcjob,创建pg 。pg 非pending后,创建pod。
- 一些operator 创建pg + pod。
- Controller 会根据pg 所属的pod 为pg 计算minResources
- webhook: 如果pg pending,则拦截create pod。 保证pod 在pg 非pending后被创建
- scheduler
- enqueue: 判断pg 能不能enqueue,能则 pg pending ==> enqueue
- allocate: pod 创建得到task,根据task 判断queue 有没有资源,有则分配
- backfill: 如果pod 没有标明 request resource,且集群有富余资源,就运行一下这类pod。
基本概念
kube-batch 本身是一个是scheduler,从apiserver 获取pod信息,如果pod 的 schedulerName 不是kube-batch 就会ignore。
接口层:queue/podgroup
- queue是容纳一组podgroup的队列,也是该组podgroup获取集群资源的划分依据。queue 是资源管理的基本单位(weight是软约束,capacity 是硬约束,reclaimable 是超出软约束占据资源后是不是可以吐出来),podGroup 是调度的基本单位
- 当创建vcjob(Volcano Job的简称)时,若没有指定该vcjob所属的podgroup,默认会为该vcjob创建同名的podgroup。
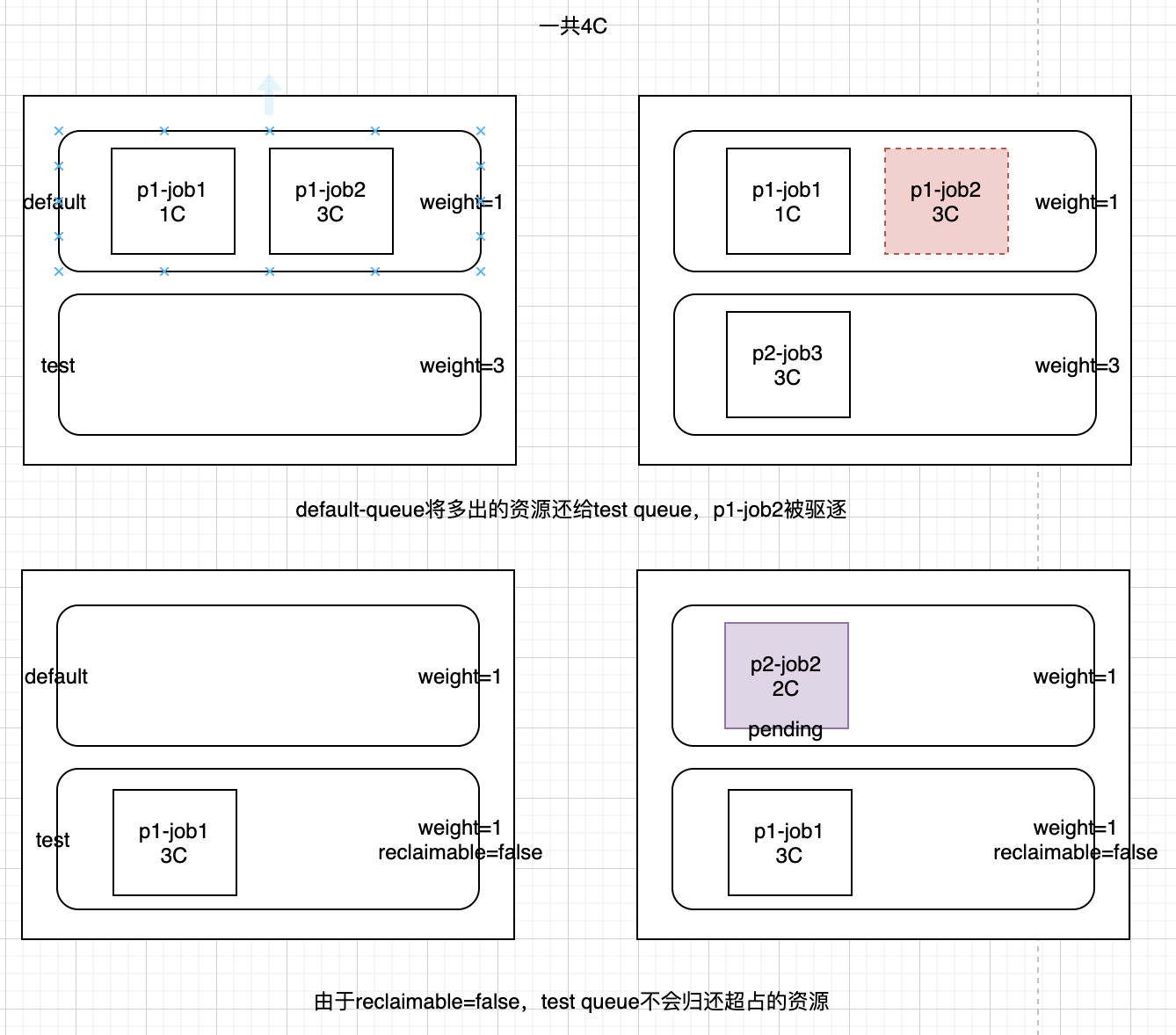
能够将一个训练任务的多个worker当做一个整体进行调度,只有当任务所有worker的资源都满足,才会将容器在节点上启动;kube-batch还提供了Queue的机制(其实就是多租户),不同队列之间可以设置优先级,优先级高的队列中的任务会优先得到调度。队列还可以设置权重,权重高的队列分配到的资源会更多。PS: 换个表述,将调度单元从 Pod 修改为 PodGroup,以组的形式进行调度。
实现层:action 和plugin
虽然我们使用kube-batch主要是为了gang-scheduler,kube-batch 作为一个调度器,基本的“为pod 选择一个最合适的node/node间pod 数量尽可能均衡/抢占” 这些特性还是要支持的。因此在设计上,即便不需要 像default scheduler 那么灵活,至少在代码层面要方便扩展,方便塞入个性化的调度需求。扩展性具体体现为 Action + Plugin。
Action 实现了调度机制(mechanism),Plugin 实现了调度的不同策略(policy)。举个例子,在 Allocate 中,每次会从优先队列中找到一个容器进行调度,这是机制,是由 Action 决定的。而在优先队列中容器排序的策略,是调用了 session 的 TaskOrderFn 方法,这个方法会调用 Plugin 注册的方法,因此策略是由 Plugin 实现。这种机制和策略分离的软件设计,带来了很好的扩展性和灵活性。总体来讲,带有动作属性的功能,一般需要引入 action 插件;带有选择 (包括排序) 属性的功能,一般使用 plugin 插件。
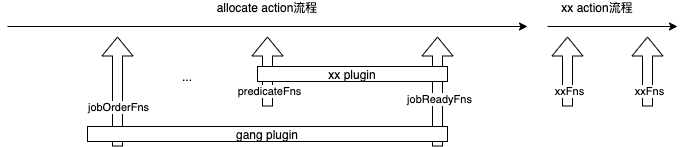
action负责管理核心逻辑和流程,xxFns 是流程里暴露出来的hook,一个plugin(扩展需求)通过一个或多个Fns 组合来实现,这就很像default-scheduler 中的 Scheduling Framework 了。Volcano火山:容器与批量计算的碰撞action 和plugin 的关系
- action是第一级插件,定义了调度周期内需要的各个动作;默认提供 enqueue、allocate、 preempt和backfill四个action。比如allocate 为pod 分配node ,preempt 实现抢占。
- plugin是第二级插件,定义了action需要的各个算法;比如如何为job排序,为node排序,优先抢占谁。
调度流程
Volcano Scheduler是负责Pod调度的组件,它由一系列action和plugin组成。action定义了调度各环节中需要执行的动作;plugin根据不同场景提供了action 中算法的具体实现细节。
每次调用 Scheduler.runOnce 的过程如下面调度流程图所示:
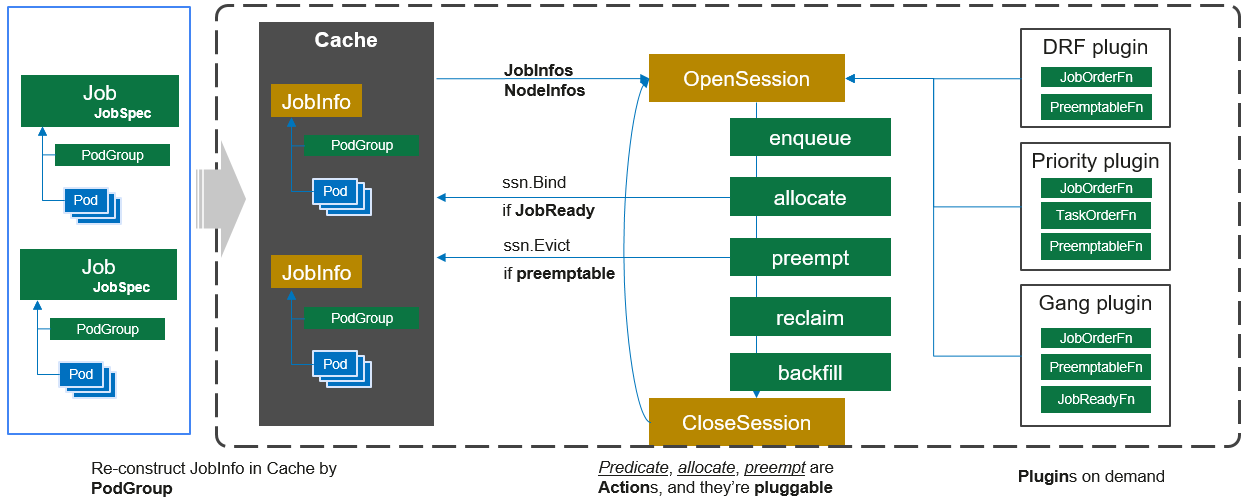
- 客户端提交的Job被scheduler观察到并缓存起来。
- 周期性的开启会话,一个调度周期开始。主要是对 cache 的信息(JobInfos,NodeInfos)做一次 snapshot,然后注册不同 actions 的 plugins。
- 遍历所有的待调度Job,按照定义的次序依次执行enqueue、allocate、preempt、reclaim、backfill等动作,为每个Job找到一个最合适的节点。将该Job 绑定到这个节点。action中执行的具体算法逻辑取决于注册的plugin中各函数的实现。
- 关闭本次会话。 触发plugin 清理中间数据;session snapshot 数据清空;部分状态更新到cache: 比如
cache.UpdateJobStatus根据job running task数量与 minMember 对比更新 job(也就是pg)的状态。
各个action 的主要逻辑
- Enqueue action 将
session.Jobs中符合条件的job 状态从pending 改为非pending(allocate 不处理pending状态的job,以免太多的pending task 进入处理逻辑,影响调度性能) 。比如 一个job 申请的资源超过 所在queue 的capacity 则这个job 便在这个环节被过滤掉。PS: 按组调度的落地点 - Allocate action负责通过一系列的预选和优选算法筛选出最适合的节点。
- Preempt action 为谁抢占? JobStarving 的job,主要是不够minAvailable 的job。谁来牺牲?preemptableFns, 用于同一个Queue中job之间的抢占。PS: 对应job 及task 的优先级字段,优先级也用于处理时的排队
- Reclaim action 为谁抢占?queue 配额还够但是 存在pending的task。谁来牺牲?reclaimableFns, 会尝试抢占其它Queue 已经running 的task。PS:对应queue.reclaimalble 配置。
- backfill action 负责将处于pending状态的Task(注意不是job)尽可能的调度下去以保证节点资源的最大化利用。当前只有一个case:为没有指明资源申请量的Pod 调度(这类pod allocate action 不处理)。
以allocate为例,它定义了调度中资源分配过程:根据 plugin 的 JobOrderFn 对作业进行排序,根据NodeOrderFn对节点进行排序,检测节点上的资源是否满足,满足作业的分配要求(JobReady)后提交分配决定。
// allocate 逻辑
// the allocation for pod may have many stages
// 1. pick a namespace named N (using ssn.NamespaceOrderFn)
// 2. pick a queue named Q from N (using ssn.QueueOrderFn)
// 3. pick a job named J from Q (using ssn.JobOrderFn)
// 4. pick a task T from J (using ssn.TaskOrderFn)
// 5. use predicateFn to filter out node that T can not be allocated on.
// 6. use ssn.NodeOrderFn to judge the best node and assign it to T
其它
调度策略
| 思路 | 优点 | 算法 | |
|---|---|---|---|
| Gang | 满足了调度过程中的“All or nothing”的调度需求 | 避免Pod的任意调度导致集群资源的浪费 | 观察Job下的Pod已调度数量是否满足了最小运行数量,当Job的最小运行数量得到满足时,为Job下的所有Pod执行调度动作,否则,不执行 |
| Binpack | binpack调度算法的目标是尽量把已有的节点填满(尽量不往空白节点分配) | 尽可能填满节点的小作业有利,在空闲的机器上为申请了更大资源请求的Pod预留足够的资源空间 | Binpack算法以插件的形式,注入到volcano-scheduler调度过程中,将会应用在Pod优选节点的阶段(这个表述对理解action和plugin的关系) |
| Priority | 让用户自定义job、task优先级 | ||
| DRF | 具有较低share值的Job将具有更高的调度优先级 | 优先考虑集群中业务的吞吐量,适用单次AI训练、单次大数据计算以及查询等批处理小业务场景 | |
| Proportion | 不同团队使用不同的Queue | ||
| Task-topology | 根据Job内task之间亲和性和反亲和性配置计算task优先级和Node优先级的算法 | node affinity/Anti-affinity,以TensorFlow计算为例,“ps”与“ps”之间的反亲和性 | |
| SLA | 用户可以在自己的集群定制SLA相关参数,例如最长等待时间(JobWaitingTime) | ||
| Tdm | 在特定的时间将任务调度到标记的节点上,其它时间则不调度 | 提高了volcano在调度过程中节点资源的分时复用能力 | |
| Numa-aware | 许多工作负载对cpu资源迁移并不敏感。然而,有一些cpu的缓存亲和度以及调度延迟显著影响性能的工作负载 |
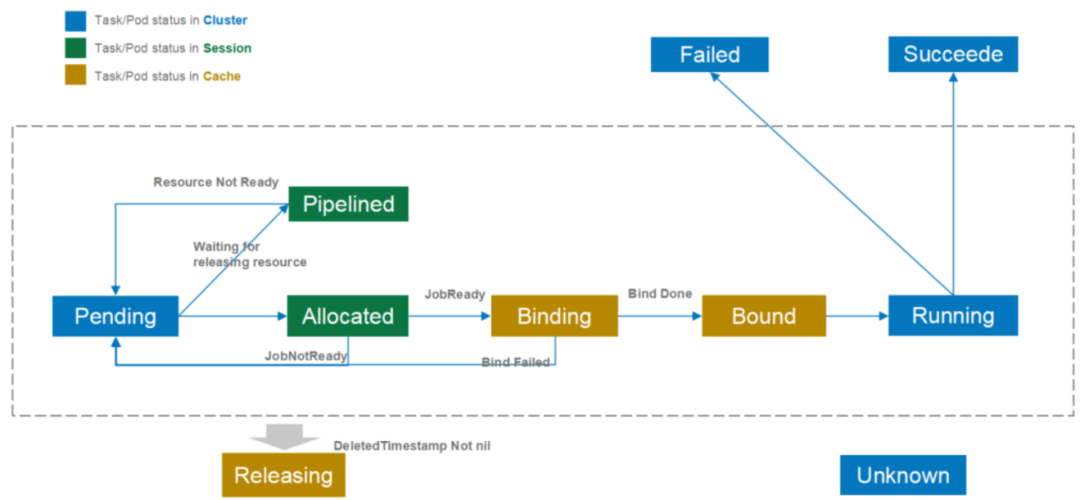
pod 状态变化
pod 在k8s cluster、scheduler session(一个调度周期)、scheduler cache中的状态,目前Volcano调度器仅使用了状态的部分功能
- Pending: 当Pod被创建后就处于Pending状态,等待调度器对其进行调度;调度的主要目的也是为这些Pending的Pod寻找最优的资源
- Allocated: 当Pod被分配空闲资源,但是还没有向kube-apiserver发送调度决策时,Pod处于Allocated状态。 Allocated状态仅存在于调度周期内部,用于记录Pod和资源分配情况。当作业满足启动条件时 (e.g. 满足minMember),会向kube-apiserver提交调度决策。如果本轮调度周期内无法提交调度决策,由状态会回滚为Pending状态。
- Pipelined: 该状态与Allocated状态相似,区别在于处于该状态的Pod分配到的资源为正在被释放的资源 (Releasing)。该状态主要用于等待被抢占的资源释放。该状态是调度周期中的状态,不会更新到kube-apiserver以减少通信,节省kube-apiserver的qps。
- Binding: 当作业满足启动条件时,调度器会向kube-apiserver提交调度决策,在kube-apiserver返回最终状态之前,Pod一直处于Binding状态。该状态也保存在调度器的Cache之中,因此跨调度周期有效。
- Bound: 当作业的调度决策在kube-apiserver确认后,该Pod即为Bound状态。
- Releasing: Pod等待被删除时即为Releasing状态。
- Running, Failed, Succeeded, Unknown: 与Pod的现有含义一致。
监控
Volcano 监控设计解读 主要是延迟分布(有没有延迟,延迟多久),以及因为什么原因延迟。
Coscheduling
对于同一集群资源,调度器需要中心化。但如果同时存在两个调度器的话,有可能会出现决策冲突,例如分别将同一块资源分配给两个不同的Pod,导致某个Pod调度到节点后因为资源不足,导致无法创建的问题。解决的方式只能是通过标签的形式将节点强行的划分开来,或者部署多个集群。这种方式通过同一个Kubernetes集群来同时运行在线服务和离线作业,势必会导致整体集群资源的浪费以及运维成本的增加。再者,Volcano运行需要启动定制的MutatingAdmissionWebhook和ValidatingAdmissionWebhook。这些Webhooks本身存在单点风险,一旦出现故障,将影响集群内所有pod的创建。另外,多运行一套调度器,本身也会带来维护上的复杂性,以及与上游Kube-scheduler接口兼容上的不确定性。
进击的 Kubernetes 调度系统(一):Kubernetes scheduling framework 进击的Kubernetes调度系统(二):支持批任务的Coscheduling/Gang scheduling 进击的Kubernetes调度系统(三):支持批任务的Binpack Scheduling Kubernetes默认开启的资源调度策略是LeastRequestedPriority,消耗的资源最少的节点会优先被调度,使得整体集群的资源使用在所有节点之间分配地相对均匀。但是这种调度策略往往也会在单个节点上产生较多资源碎片。假设两个节点各剩余1GPU的资源,这时有申请2GPU的新作业,提交到调度器,则因为无法提供足够的资源,导致调度失败。每个节点都有1个GPU卡空闲,可是又无法被利用,导致资源GPU这种昂贵的资源被浪费。如果使用的资源调度策略是Binpack,优先将节点资源填满之后,再调度下一个节点,则资源碎片问题可以得到解决。