简介
使用 Elastic GPU 管理 Kubernetes GPU 资源在 GPU 场景,还是存在以下不足:
- 集群 GPU 资源缺少全局视角。没有直观方式可获取集群层面 GPU 信息,比如 Pod / 容器与 GPU 卡绑定关系、已使用 GPU 卡数等。
- 不能很好支持多 GPU 后端。各种 GPU 技术(nvidia docker、qGPU、vCUDA、gpu share、GPU 池化)均需独立部署组件,无法统一调度和管理。 腾讯云参考 PV/PVC/StorageClass 提出了ElasticGPU/ElasticGPUClaim/EGPUClass。
上报/调度/容器创建
Kubernetes GPU管理与Device Plugin机制对于云的用户来说,在 GPU 的支持上,他们最基本的诉求其实非常简单:我只要在 Pod 的 YAML 里面,声明某容器需要的 GPU 个数,那么 Kubernetes 为我创建的容器里就应该出现对应的 GPU 设备,以及它对应的驱动目录。以 NVIDIA 的 GPU 设备为例,上面的需求就意味着当用户的容器被创建之后,这个容器里必须出现如下两部分设备和目录:
- GPU 设备,比如 /dev/nvidia0;
- GPU 驱动目录,比如 /usr/local/nvidia/*。
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
在 kube-scheduler 里面,它其实并不关心nvidia.com/gpu的具体含义,只会在计算的时候,一律将调度器里保存的该类型资源的可用量,直接减去 Pod 声明的数值即可。为了能够让调度器知道这个自定义类型的资源在每台宿主机上的可用量,宿主机节点本身,就必须能够向 API Server 汇报该类型资源的可用数量。在 Kubernetes 里,各种类型的资源可用量,其实是 Node 对象 Status 字段的内容。为了能够在上述 Status 字段里添加自定义资源的数据,你就必须使用 PATCH API 来对该 Node 对象进行更新,加上你的自定义资源的数量。这个 PATCH 操作,可以简单地使用 curl 命令来发起 curl --header "Content-Type: application/json-patch+json" \--request PATCH \--data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "1"}]' \http://localhost:8001/api/v1/nodes//status
apiVersion: v1
kind: Node
...
Status:
Capacity:
cpu: 2
memory: 2049008Ki
nvidia.com/gpu: 1
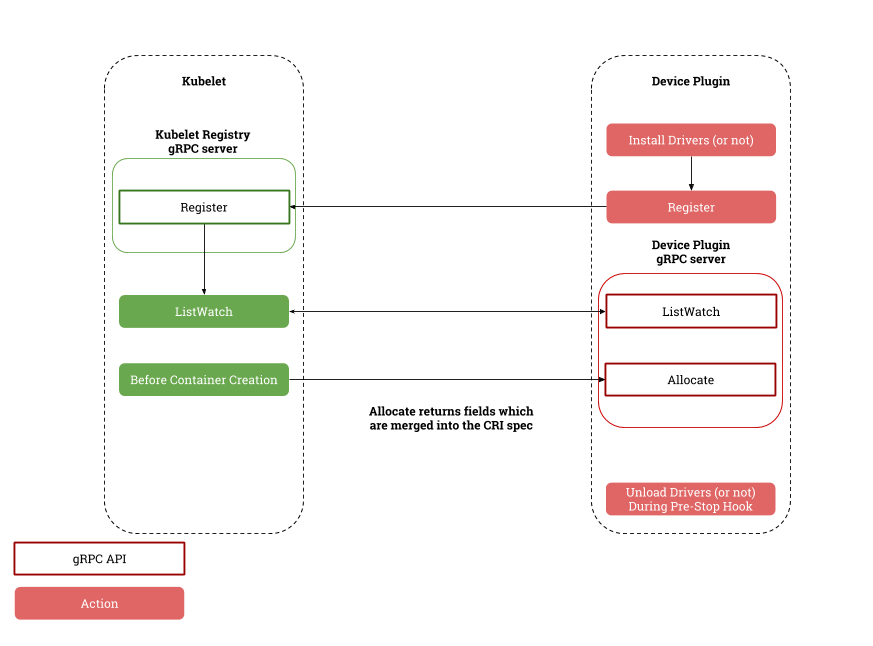
- 对于每一种硬件设备,都需要有它所对应的 Device Plugin 进行管理,这些 Device Plugin,都通过 gRPC 的方式,同 kubelet 连接起来。以 NVIDIA GPU 为例,它对应的插件叫作NVIDIA GPU device plugin。DevicePlugin 注册一个socket 文件到
/var/lib/kubelet/device-plugins/目录下,Kubelet 通过这个目录下的socket 文件向对应的 DevicePlugin 发送gRPC 请求。PS: 通过目录做服务发现。 - Device Plugin 会通过一个叫作 ListAndWatch 的 API,定期向 kubelet 汇报该 Node 上 GPU 的列表。比如,在上图的例子里,一共有三个 GPU(GPU0、GPU1 和 GPU2)。这样,kubelet 在拿到这个列表之后,就可以直接在它向 APIServer 发送的心跳里,以 Extended Resource 的方式,加上这些 GPU 的数量,比如nvidia.com/gpu=3。
- 当 kubelet 发现这个 Pod 的容器请求一个 GPU 的时候,kubelet 就会从自己持有的 GPU 列表里,为这个容器分配一个 GPU。此时,kubelet 就会向本机的 Device Plugin 发起一个 Allocate() 请求。这个请求携带的参数,正是即将分配给该容器的设备 ID 列表。
- 当 Device Plugin 收到 Allocate 请求之后,它就会根据 kubelet 传递过来的设备 ID,从 Device Plugin 里找到这些设备对应的设备路径和驱动目录。比如,在 NVIDIA Device Plugin 的实现里,它会定期访问 nvidia-docker 插件,从而获取到本机的 GPU 信息。而被分配 GPU 对应的设备路径和驱动目录信息被返回给 kubelet 之后,kubelet 就完成了为一个容器分配 GPU 的操作。接下来,kubelet 会把这些信息追加在创建该容器所对应的 CRI 请求当中。这样,当这个 CRI 请求发给 Docker 之后,Docker 为你创建出来的容器里,就会出现这个 GPU 设备,并把它所需要的驱动目录挂载进去。
service DevicePlugin {
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
}
目前 Kubernetes 本身的 Device Plugin 的设计,实际上能覆盖的场景是非常单一的,属于“可用”但是“不好用”的状态。一旦你的设备是异构的、不能简单地用“数目”去描述具体使用需求的时候,比如,“我的 Pod 想要运行在计算能力最强的那个 GPU 上”,Device Plugin 就完全不能处理了。在很多场景下,我们其实希望在调度器进行调度的时候,就可以根据整个集群里的某种硬件设备的全局分布,做出一个最佳的调度选择。
- 调度器扮演的角色,仅仅是为 Pod 寻找到可用的、支持这种硬件设备的节点
- GPU 等硬件设备的调度工作,实际上是由 kubelet 完成的。即,kubelet 会负责从它所持有的硬件设备列表中,为容器挑选一个硬件设备,然后调用 Device Plugin 的 Allocate API 来完成这个分配操作。
- 不支持多个pod共享一个gpu
上报细节
kuebctl describe node xx 查看对应节点的gpu数据
Capacity:
cpu: 48
ephemeral-storage: 2239684580Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131661580Ki
nvidia.com/gpu: 4
pods: 110
Allocatable:
cpu: 46
ephemeral-storage: 2058724596391
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 126418700Ki
nvidia.com/gpu: 4
pods: 110
nvidia gpu operator
如果在k8s 上支持gpu 设备调度,需要做
- 节点上安装 nvidia 驱动
- 节点上安装 nvidia-docekr
- 集群部署 gpu device plugin
- 部署 dcgm-exporter 监控gpu 使用 为此, nvidia 开源了 nvidia-gpu-exporter 自动化管理上述组件