前言
| 不同层面的并行化支持 | 表现 |
|---|---|
| 硬件并行化 | 多核心、多cpu |
| 操作系统并行化 | 并行抽象(进程、线程)以及交互手段的提供 |
| 编程语言并行化 | java启动一个线程要extends thread,而go只需一个go func(){} |
并发编程思想来自多任务操作系统,随后,人们逐渐将并发编程思想凝练成理论,同时开发出了一套关于它的描述方法。之后,人们把这套理论融入到编程语言当中。
并发程序内部有多个串行程序,串行程序之间有交互的需求,交互方式有同步和异步;不同的方式有各自的交互手段(整体分为共享内存和通讯两个交互类型);交互目的分为:互斥访问共享资源、协调进度。
交互目的中,比较重要的是对共享资源的访问。这个共享资源,对进程是文件等,对线程是共享内存等。共享就容易发生干扰,一切问题的起点是:OS为了支持并发执行,会中断进程==> 中断前要保存现场,中断后要恢复现场。这个现场小了说是寄存器数据,大了说,就是进程关联的所有资源的状态(比如进程打开的fd) ==> 要确保进程“休息”期间,别的进程不能“动它的奶酪”,否则,现场就被破坏了。==> 解决办法有以下几个:
- 访问共享资源的操作不能被中断(原子操作);
- 可中断,但资源互斥访问(临界区);
- 资源本身就是不变的(比如常量)
临界区为什么不都弄成原子操作呢?因为一个操作执行起来没办法中断,也意味着很大的风险。所以,内核只提供针对二进制位和整数的原子操作。
交互类型中,通信比共享内存要简单。因为,把数据放在共享内存区供多个线程访问,这种方式的基本思想非常简单,却使并发访问控制变得复杂,要做好各种约束和限制,才能使看似简单的方法得以正确实施。比如,当线程离开临界区时,不仅要放弃对临界区的锁定(设置互斥量),还要通知其它等待进入该临界区的线程(操作条件变量)。同步工具的引入(互斥量和条件变量等)增加了业务无关代码,其本身的正确使用也有一定的学习曲线。而通讯就简单了,收到消息就往下走,收不到就等待,自得其乐,不用管其它人。
针对并发粒度的不同,我们把上述概念梳理一下:
| 并发粒度 | 交互手段 | 同步/异步 | 交互类型 |
|---|---|---|---|
| 进程 | 管道、信号、socket | 同步异步都有 | 只支持通信 |
| 线程 | 共享内存 | 1. 互斥量+条件变量 支持同步;2. 程序层面通过模拟signal弄出的futrue模式支持异步 | 只支持共享内存,高层抽象支持通信,比如java的blockingQueue |
| goroutine | channel | 1. channel支持同步;2. 程序层面提供异步 | 只支持通信,高层抽象支持共享内存,比如go的sync包 |
PS,routine is a set sequence of steps, part of larger computer program.
理念变化
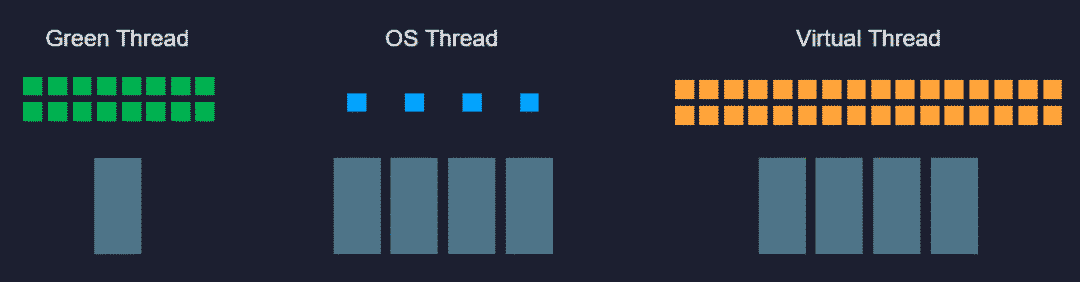
云原生时代,Java危矣?Java语言抽象出来隐藏了各种操作系统线程差异性的统一线程接口,这曾经是它区别于其他编程语言(C/C++表示有被冒犯到)的一大优势,不过,统一的线程模型不见得永远都是正确的。 Java目前主流的线程模型是直接映射到操作系统内核上的1:1模型,这对于计算密集型任务这很合适,既不用自己去做调度,也利于一条线程跑满整个处理器核心。但对于I/O密集型任务,譬如访问磁盘、访问数据库占主要时间的任务,这种模型就显得成本高昂,主要在于内存消耗和上下文切换上:64位Linux上HotSpot的线程栈容量默认是1MB,线程的内核元数据(Kernel Metadata)还要额外消耗2-16KB内存,所以单个虚拟机的最大线程数量一般只会设置到200至400条,当程序员把数以百万计的请求往线程池里面灌时,系统即便能处理得过来,其中的切换损耗也相当可观。
并发之痛 Thread,Goroutine,Actor中的几个基本要点:
-
那我们从最开始梳理下程序的抽象。开始我们的程序是面向过程的,数据结构+func。后来有了面向对象,对象组合了数结构和func,我们想用模拟现实世界的方式,抽象出对象,有状态和行为。但无论是面向过程的func还是面向对象的func,本质上都是代码块的组织单元,本身并没有包含代码块的并发策略的定义。于是为了解决并发的需求,引入了Thread(线程)的概念。PS: 这一点go 使用关键字比使用专门类库要好一些。
-
We believe that writing correct concurrent, fault-tolerant and scalable applications is too hard. Most of the time it’s because we are using the wrong tools and the wrong level of abstraction. —— Akka。,有论文认为当前的大多数并发程序没出问题只是并发度不够,如果CPU核数继续增加,程序运行的时间更长,很难保证不出问题
-
最让人头痛的还是下面这个问题:系统里到底需要多少线程?从外部系统来观察,或者以经验的方式进行计算,都是非常困难的。于是结论是:让”线程”会说话,吃饱了自己说,自管理是最佳方案。
-
能干活的代码片段就放在线程里,如果干不了活(需要等待,被阻塞等),就摘下来。我自己的感觉就是:按需(代码被阻塞)调度,有别于cpu的按时间片调度。
- 异步回调方案 典型如NodeJS,遇到阻塞的情况,比如网络调用,则注册一个回调方法(其实还包括了一些上下文数据对象)给IO调度器(linux下是libev,调度器在另外的线程里),当前线程就被释放了,去干别的事情了。等数据准备好,调度器会将结果传递给回调方法然后执行,执行其实不在原来发起请求的线程里了,但对用户来说无感知。
- GreenThread/Coroutine/Fiber方案 这种方案其实和上面的方案本质上区别不大,关键在于回调上下文的保存以及执行机制。为了解决回调方法带来的难题,这种方案的思路是写代码的时候还是按顺序写,但遇到IO等阻塞调用时,将当前的代码片段暂停,保存上下文,让出当前线程。等IO事件回来,然后再找个线程让当前代码片段恢复上下文继续执行,写代码的时候感觉好像是同步的,仿佛在同一个线程完成的,但实际上系统可能切换了线程,但对程序无感。
基调:性能最高 ==> 线程数=CPU核心数
线程数过多很容易导致 CPU 频繁的在这些线程之间切换,虽然 CPU 看起来已经在满负荷运行了,但 CPU 并没有把所有的时间都用在执行我们的业务逻辑上,其中一部分 CPU 时间浪费在线程上下文切换上了。怎么来优化这种情况呢?要想让 CPU 高效地执行业务逻辑,最佳方式就是我们开头提到的流水线,用和 CPU 核数相同的线程数,通过源源不断地供给请求,让 CPU 一直不停地执行业务逻辑。所以优化的关键点是,减少线程的数量,把线程数量控制在和 CPU 核数相同的数量级这样一个范围。要减少线程数量,有这样两个问题需要解决。
- 如何用少量的线程来处理大量并发请求呢?我们可以用一个请求队列,和一组数量(等于CPU核数)固定的执行线程,来解决这个问题。这样基本上能达到,让每个 CPU 的核心相对固定到一个线程上,不停地执行业务逻辑这样一个效果。
- 执行线程在需要调用外部服务的时候,如何避免线程等待外部服务,同时还要保证及时处理返回的响应呢?我们希望的情况是,执行线程需要调用外部服务的时候,把请求发送出去之后,不要去等待响应,而是去继续处理下一个请求。等外部请求的响应回来之后,能有一个通知,来触发执行线程再执行后续的业务逻辑,直到给客户端返回响应。其实就是我们通常所说的异步 IO 模型,Linux 内核从 2.6 开始才加入了 AIO 的支持,到目前为止 AIO 还没有被广泛的使用。使用更广泛的是 IO 多路复用模型(IO Multiplexing)
可以看到,异步模型并不会让程序的业务逻辑执行得更快,但是它可以非常有效地避免线程等待,大幅减少 CPU 在线程上下文切换上浪费的时间。