前言
Go语言编译器简介 未读完
- N种语言+M种机器=N+M个任务,有几种方案
- 其它语言 ==> C ==> 各个机器
- 各个语言 ==> x86 ==> 各个机器
- 通用编译器方案
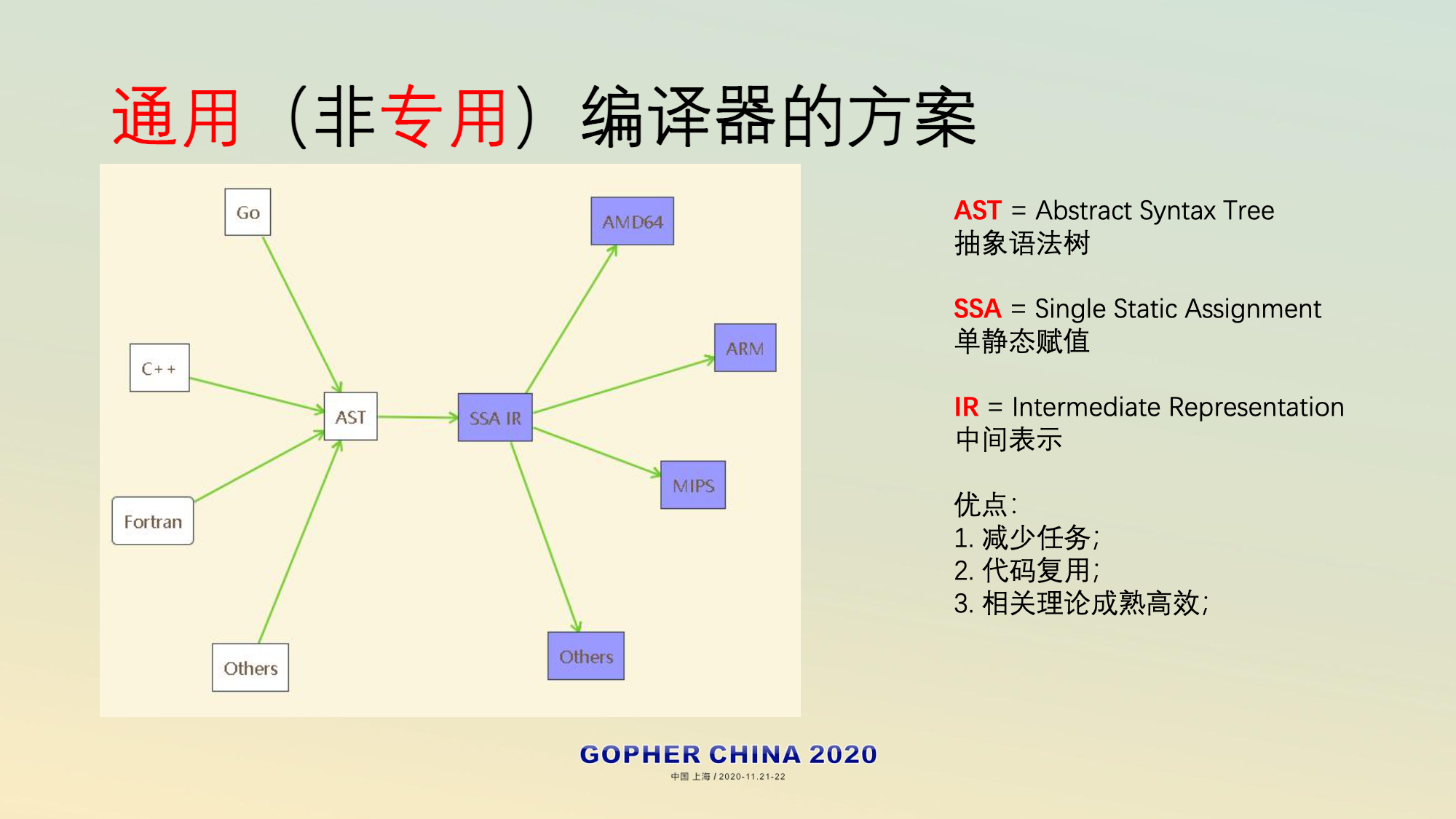
SSA-IR(Single Static Assignment)是一种介于高级语言和汇编语言的中间形态的伪语言,从高级语言角度看,它是(伪)汇编;而从真正的汇编语言角度看,它是(伪)高级语言。顾名思义,SSA(Single Static Assignment)的两大要点是:
- Static:每个变量只能赋值一次(因此应该叫常量更合适);
- Single:每个表达式只能做一个简单运算,对于复杂的表达式ab+cd要拆分成:”t0=ab; t1=cd; t2=t0+t1;”三个简单表达式;
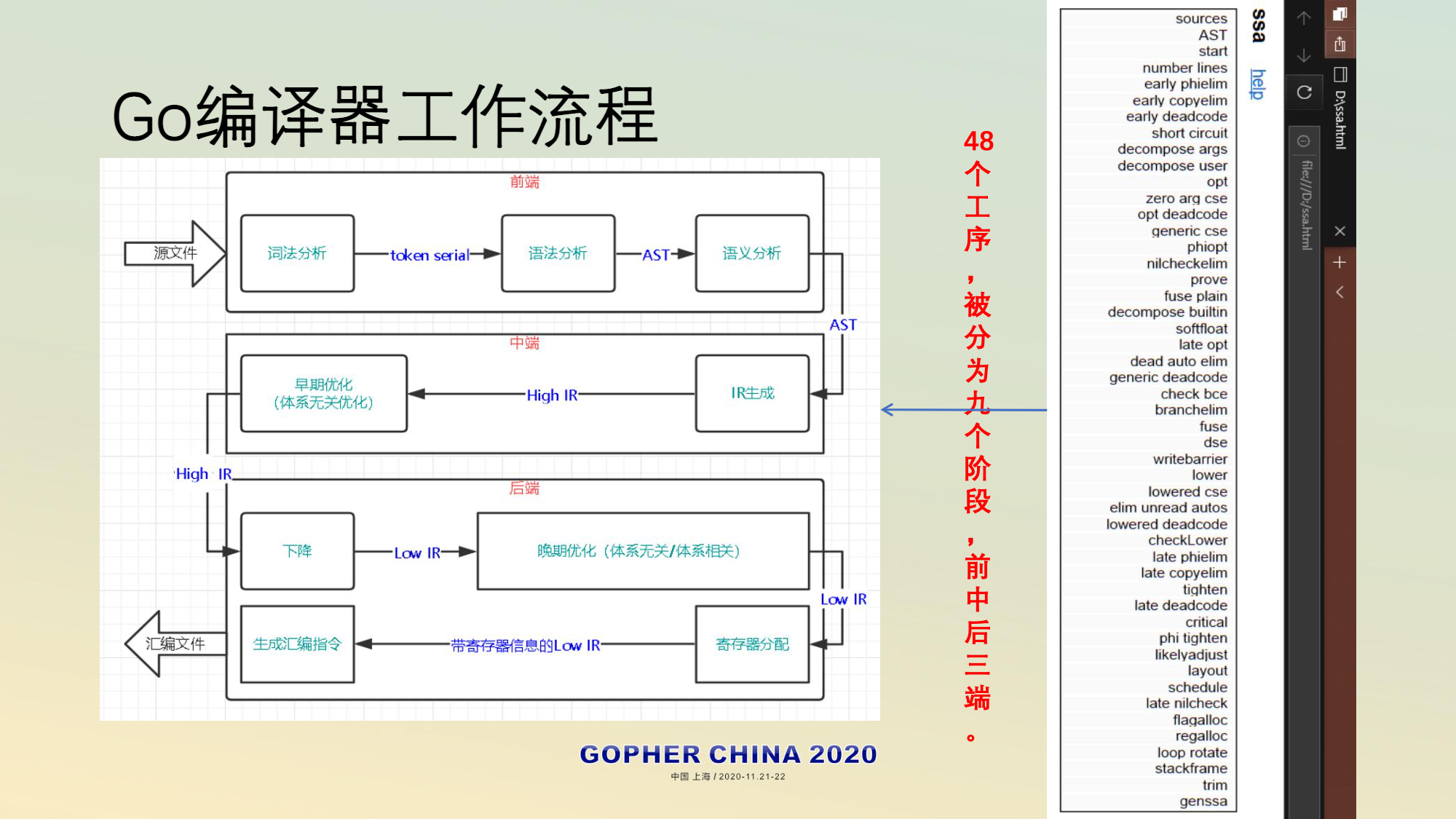
go编译器
Go 语言的编译器完全用 Go 语言本身来实现,它完全实现了从(编译)前端到后端的所有工作
一个95分位延迟要求5ms的场景,如何做性能优化Golang 的生态中相关工具我们能用到的有 pprof 和 trace。pprof 可以看 CPU、内存、协程等信息在压测流量进来时系统调用的各部分耗时情况。而 trace 可以查看 runtime 的情况,比如可以查看协程调度信息等。代码层面的优化,是 us 级别的,而针对业务对存储进行优化,可以做到 ms 级别的,所以优化越靠近应用层效果越好。对于代码层面,优化的步骤是:
- 压测工具模拟场景所需的真实流量
- pprof 等工具查看服务的 CPU、mem 耗时
- 锁定平顶山逻辑,看优化可能性:异步化,改逻辑,加 cache 等
- 局部优化完写 benchmark 工具查看优化效果
- 整体优化完回到步骤一,重新进行 压测+pprof 看效果,看 95 分位耗时能否满足要求(如果无法满足需求,那就换存储吧~。
火焰图中圈出来的大平顶山都是可以优化的地方
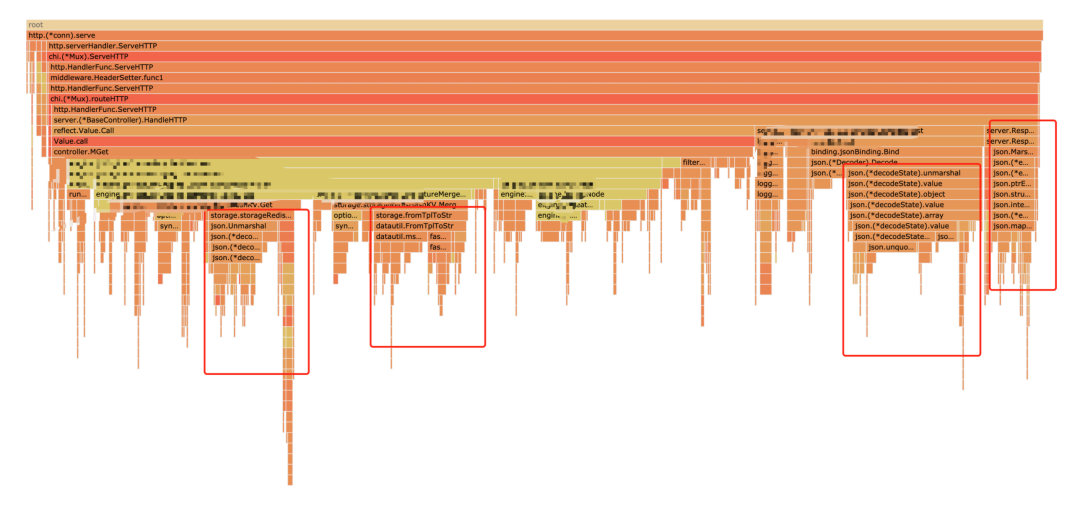
另外推荐一个不错的库,这是 Golang 布道师 Dave Cheney 搞的用来做性能调优的库,使用起来非常方便:https://github.com/pkg/profile,可以看 pprof和 trace 信息。有兴趣读者可以了解一下。
Go 程序启动引导
Go 程序启动引导Go 程序既不是从 main.main 直接启动,也不是从 runtime.main 直接启动。 相反,其实际的入口位于 runtime.rt0_amd64*。随后会转到 runtime.rt0_go 调用。在这个调用中,除了进行运行时类型检查外,还确定了两个很重要的运行时常量,即处理器核心数以及内存物理页大小。
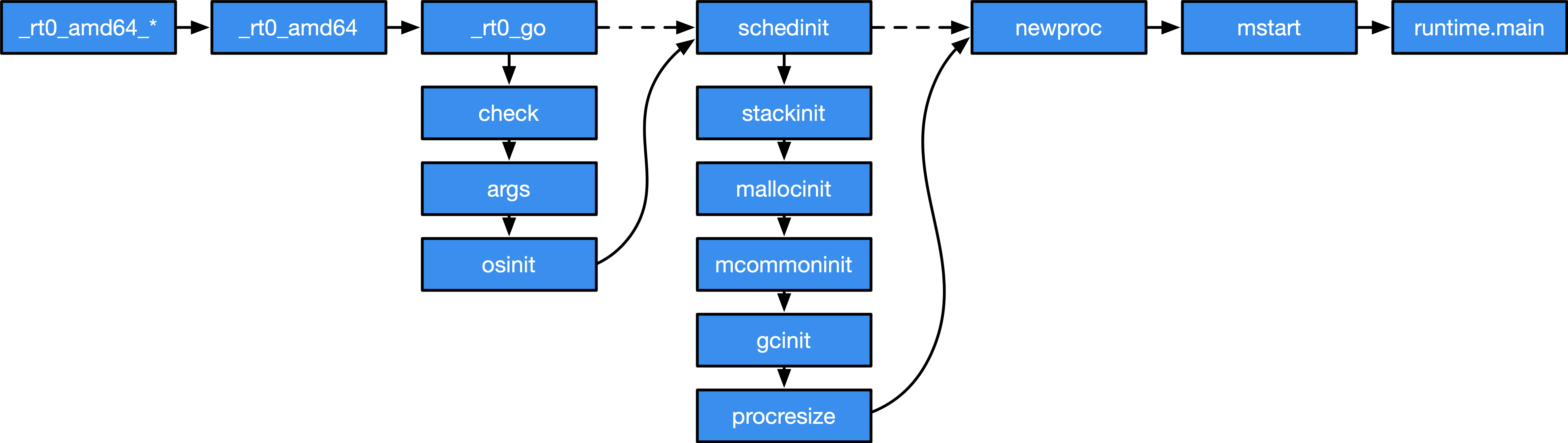
在 schedinit 这个函数的调用过程中, 还会完成整个程序运行时的初始化,包括调度器、执行栈、内存分配器、调度器、垃圾回收器等组件的初始化。 最后通过 newproc 和 mstart 调用进而开始由调度器转为执行主 goroutine。
TEXT runtime·rt0_go(SB),NOSPLIT,$0
(...)
// 调度器初始化
CALL runtime·schedinit(SB)
// 创建一个新的 goroutine 来启动程序
MOVQ $runtime·mainPC(SB), AX
PUSHQ AX
PUSHQ $0 // 参数大小
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// 启动这个 M,mstart 应该永不返回
CALL runtime·mstart(SB)
(...)
RET
主 Goroutine 的生与死主 Goroutine 运行runtime.main
// 主 Goroutine
func main() {
...
// 执行栈最大限制:1GB(64位系统)或者 250MB(32位系统)
if sys.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
...
// 启动系统后台监控(定期垃圾回收、抢占调度等等)
systemstack(func() {
newm(sysmon, nil)
})
...
// 执行 runtime.init。运行时包中有多个 init 函数,编译器会将他们链接起来。
runtime_init()
...
// 启动垃圾回收器后台操作
gcenable()
...
// 执行用户 main 包中的 init 函数,因为链接器设定运行时不知道 main 包的地址,处理为非间接调用
fn := main_init
fn()
...
// 执行用户 main 包中的 main 函数,同理
fn = main_main
fn()
...
// 退出
exit(0)
}
defer
defer 的前世今生未读完
- 在函数返回、产生恐慌或者 runtime.Goexit 时被调用。PS: 配对编程在文件、锁等场景很有必要,但全对的配对很难实现,要考虑异常等场景,在c++ 里“释放”动作经常要封装到 析构函数里
- 直觉上看, defer 应该由编译器直接将需要的函数调用插入到该调用的地方,似乎是一个编译期特性, 不应该存在运行时性能问题。但实际情况是,由于 defer 并没有与其依赖资源挂钩,也允许在条件、循环语句中出现,无法在编译期决定存在多少个 defer 调用。
defer 使用的几个注意事项
- 对于有返回值的自定义函数或方法,返回值会在 deferred 函数被调度执行的时候被自动丢弃。
- Go 语言中除了自定义函数 / 方法,还有 Go 语言内置的 / 预定义的函数。append、cap、len、make、new、imag 等内置函数都是不能直接作为 deferred 函数的,而 close、copy、delete、print、recover 等内置函数则可以直接被 defer 设置为 deferred 函数。对于那些不能直接作为 deferred 函数的内置函数,我们可以使用一个包裹它的匿名函数来间接满足要求,以 append 为例是这样的:
defer func() { _ = append(sl, 11) }() - defer 关键字后面的表达式,是在将 deferred 函数注册到 deferred 函数栈的时候进行求值的。
三种实现方案
func main() {
defer foo()
return
}
堆上分配
// 编译器伪代码
func main() {
deferproc foo() // 记录被延迟的函数调用
...
deferreturn // 取出defer记录执行被延迟的调用
return
}
一个函数中的延迟语句会被保存为一个 _defer 记录的链表,附着在一个 Goroutine 上。
// src/runtime/panic.go
type _defer struct {
siz int32 // 参数和结果的内存大小
started bool
openDefer bool
sp uintptr // 代表栈指针
pc uintptr // 代表调用方的程序计数器
fn *funcval // defer 关键字中传入的函数
_panic *_panic
link *_defer // 通过link 构成链表
}
// src/runtime/runtime2.go
type g struct {
...
_defer *_defer
...
}
栈上分配
在栈上创建 defer, 直接在函数调用帧上使用编译器来初始化 _defer 记录
func main() {
t := deferstruct(stksize) // 从编译器角度构造 _defer 结构
arg0 := s.constOffPtrSP(types.Types[TUINTPTR], Ctxt.FixedFrameSize()) // 对该记录的初始化
...
deferreturn // 取出defer记录执行被延迟的调用
return
}
开放编码式
允许进行 defer 的开放编码的主要条件:没有禁用编译器优化,即没有设置 -gcflags “-N”;存在 defer 调用;函数内 defer 的数量不超过 8 个、且返回语句与延迟语句个数的乘积不超过 15;没有与 defer 发生在循环语句中。
defer f1(a1)
if cond {
defer f2(a2)
}
...
==================>
deferBits = 0 // 初始值 00000000
deferBits |= 1 << 0 // 遇到第一个 defer,设置为 00000001
_f1 = f1
_a1 = a1
if cond {
// 如果第二个 defer 被设置,则设置为 00000011,否则依然为 00000001
deferBits |= 1 << 1
_f2 = f2
_a2 = a2
}
==================== 在退出位置,再重新根据被标记的延迟比特,反向推导哪些位置的 defer 需要被触发
exit:
// 按顺序倒序检查延迟比特。如果第二个 defer 被设置,则
// 00000011 & 00000010 == 00000010,即延迟比特不为零,应该调用 f2。
// 如果第二个 defer 没有被设置,则
// 00000001 & 00000010 == 00000000,即延迟比特为零,不应该调用 f2。
if deferBits & 1 << 1 != 0 { // 00000011 & 00000010 != 0
deferBits &^= 1<<1 // 00000001
_f2(_a2)
}
// 同理,由于 00000001 & 00000001 == 00000001,因此延迟比特不为零,应该调用 f1
if deferBits && 1 << 0 != 0 {
deferBits &^= 1<<0
_f1(_a1)
}
开放编码式 defer 并不是绝对的零成本,尽管编译器能够做到将 延迟调用直接插入返回语句之前,但出于语义的考虑,需要在栈上对参与延迟调用的参数进行一次求值; 同时出于条件语句中可能存在的 defer,还额外需要通过延迟比特来记录一个延迟语句是否在运行时 被设置。 因此,开放编码式 defer 的成本体现在非常少量的指令和位运算来配合在运行时判断 是否存在需要被延迟调用的 defer。
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
$ go run main.go
0s
// 调用 defer 关键字会立刻对函数中引用的外部参数进行拷贝,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的
func main() {
startedAt := time.Now()
defer func() { fmt.Println(time.Since(startedAt)) }()
time.Sleep(time.Second)
}
$ go run main.go
1s
panic /recover
panic 指的是 Go 程序在运行时出现的一个异常情况。如果异常出现了,但没有被捕获并恢复,Go 程序的执行就会被终止,即便出现异常的位置不在主 Goroutine 中也会这样。在 Go 中,panic 主要有两类来源,一类是来自 Go 运行时,另一类则是 Go 开发人员通过 panic 函数主动触发的。无论是哪种,一旦 panic 被触发,后续 Go 程序的执行过程都是一样的,这个过程被 Go 语言称为 panicking。
recover 是 Go 内置的专门用于恢复 panic 的函数,它必须被放在一个 defer 函数中才能生效。如果 recover 捕捉到 panic,它就会返回以 panic 的具体内容为错误上下文信息的error值。如果没有 panic 发生,那么 recover 将返回 nil。而且,如果 panic 被 recover 捕捉到,panic 引发的 panicking 过程就会停止。
Java 中对checked exception处理的本质是错误处理,虽然它的名字用了带有“异常”的字样。Go 中的 panic 呢,更接近于 Java 的RuntimeException+Error。
func main() {
defer func() {
recover() // runtime.gorecover
}()
panic(nil) // runtime.gopanic
}
数据结构
type _panic struct {
argp unsafe.Pointer // panic 期间 defer 调用参数的指针; 无法移动 - liblink 已知
arg interface{} // panic 的参数
link *_panic // link 链接到更早的 panic
recovered bool // 表明 panic 是否结束
aborted bool // 表明 panic 是否忽略
}
type g struct {
// ...
_panic *_panic // panic 链表,这是最里的一个
_defer *_defer // defer 链表,这是最里的一个;
// ...
}
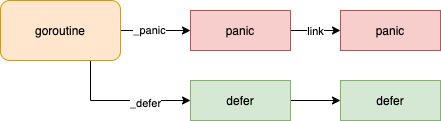
panic 的实现在一个叫做 gopanic 的函数: 创建一个panic 实例,检查有没有defer 兜着自己,有则过关执行panic后面的代码,无则gg(exit)。
// runtime/panic.go
func gopanic(e interface{}) {
// 在栈上分配一个 _panic 结构体
var p _panic
// 把当前最新的 _panic 挂到链表最前面
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
// 取出当前最近的 defer 函数;
d := gp._defer
if d == nil {
// 如果没有 defer ,那就没有 recover 的时机,只能跳到循环外,退出进程了;
break
}
// 进到这个逻辑,那说明了之前是有 panic 了,现在又有 panic 发生,这里一定处于递归之中;
if d.started {... continue}
// 标记 _defer 为 started = true (panic 递归的时候有用)
d.started = true
// 记录当前 _defer 对应的 panic
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
// 执行 defer 函数
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
// defer 执行完成,把这个 defer 从链表里摘掉;
gp._defer = d.link
// 取出 pc,sp 寄存器的值;
pc := d.pc
sp := unsafe.Pointer(d.sp)
// 如果 _panic 被设置成恢复,那么到此为止;
if p.recovered {
// 摘掉当前的 _panic
gp._panic = p.link
// 如果前面还有 panic,并且是标记了 aborted 的,那么也摘掉;
// panic 的流程到此为止,恢复到业务函数堆栈上执行代码;
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
// 注意:恢复的时候 panic 函数将从此处跳出,本 gopanic 调用结束,后面的代码永远都不会执行。
mcall(recovery)
throw("recovery failed") // mcall should not return
}
}
// 一旦走到循环外,说明 _panic 没人处理,程序即将退出;
// 打印错误信息和堆栈,并且退出进程;
preprintpanics(gp._panic)
fatalpanic(gp._panic) // should not return
*(*int)(nil) = 0 // not reached
}
首先是确定 panic 是否可恢复(一系列条件),对可恢复panic,创建一个 _panic 实例,保存在 goroutine 链表中先前的 panic 链表,接下来开始逐一调用当前 goroutine 的 defer 方法, 检查用户态代码是否需要对 panic 进行恢复,如果某个包含了 recover 的调用(即 gorecover 调用)被执行,这时 _panic 实例 p.recovered 会被标记为 true, 从而会通过 mcall 的方式来执行 recovery 函数来重新进入调度循环,如果所有的 defer 都没有指明显式的 recover,那么这时候则直接在运行时抛出 panic 信息
pprof
import (
... ...
"net/http"
_ "net/http/pprof"
... ...
)
... ...
func main() {
go func() {
http.ListenAndServe(":6060", nil)
}()
... ...
}
以空导入的方式导入 net/http/pprof 包,并在一个单独的 goroutine 中启动一个标准的 http 服务,就可以实现对 pprof 性能剖析的支持。pprof 工具可以通过 6060 端口采样到我们的 Go 程序的运行时数据。
// 192.168.10.18为服务端的主机地址
$go tool pprof -http=:9090 http://192.168.10.18:6060/debug/pprof/profile
Fetching profile over HTTP from http://192.168.10.18:6060/debug/pprof/profile
Saved profile in /Users/tonybai/pprof/pprof.server.samples.cpu.004.pb.gz
Serving web UI on http://localhost:9090
debug/pprof/profile 提供的是 CPU 的性能采样数据。CPU 类型采样数据是性能剖析中最常见的采样数据类型。一旦启用 CPU 数据采样,Go 运行时会每隔一段短暂的时间(10ms)就中断一次(由 SIGPROF 信号引发),并记录当前所有 goroutine 的函数栈信息。它能帮助我们识别出代码关键路径上出现次数最多的函数,而往往这个函数就是程序的一个瓶颈。