简介
从kube-flow说起
KubeFlow是运行在K8S之上的一套技术栈。这套技术栈包含了很多组件,组件之间的关系比较松散,我们可以配合起来用,也可以单独用其中的一部分。比如Jupyter Notebook本身可以单机运行,但是和K8S结合之后就能组建一个分布式的Jupyter Notebook服务,供多个用户同时使用。
KubeFlow不是什么
- KubeFlow不是机器学习框架,跟TensorFlow,PyTorch,XGBoost不是一个层次的东西
- KubeFlow不负责调度,他还是要依赖K8S来调度,但是可以在KubeFlow这个层次上,使用K8S提供的机制针对机器学习来调整资源调度的策略和算法
- KubeFlow不是一个软件,他更像是一个技术栈,用户从这个技术栈中挑选符合需求的组件使用,各个组件是非常松耦合的
- KubeFlow不是机器学习算法,这个不解释了
kubeflow 也在不断发展,Kubeflow Training Operator 统一云上 AI 训练。阿里推出类似 kube-flow 的 KubeDL 加入 CNCF Sandbox,加速 AI 产业云原生化
Kubeflow 支持两种不同的 Tensorflow 框架分布式训练方法。
- Tensorflow 架构/ PS 模式,它依赖于集中式参数服务器来实现工作线程之间的协调。
- 分散式方法/mpi allreduce 模式,工作线程通过 MPI AllReduce 原语直接相互通信,不使用参数服务器。NVIDIA 的 NCCL 库已经在GPU 上有效地执行了大部分 MPI 原语,而 Uber 的Horovod 让使用 TensorFlow 执行多 GPU 和多节点训练变得轻而易举。与参数服务器相比,第二种方法可以更好地优化带宽和更好地扩展。
案例
官方文档 TensorFlow Training (TFJob)
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
generateName: tfjob
namespace: kubeflow
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
Worker:
replicas: 3
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
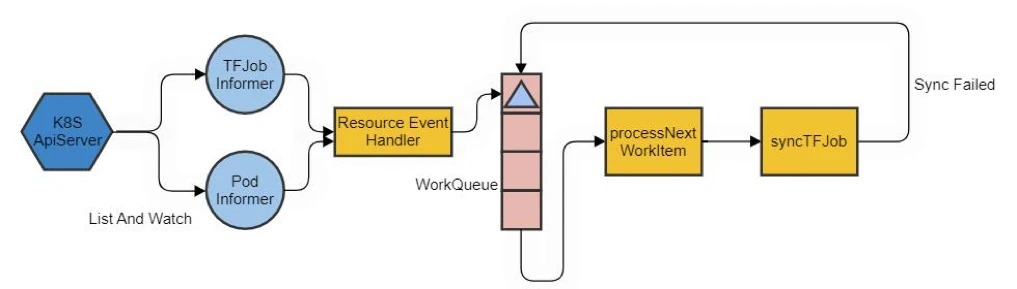
syncTFJob 是 tf-operator 管理对象的核心逻辑实现,内部对不同 ReplicaType 的 Pod 进行检查并推导出任务状态,逻辑流程图如下:
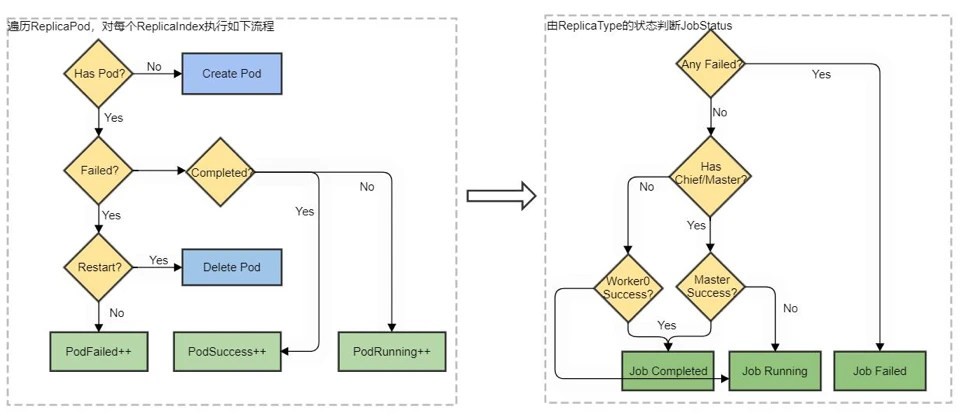
源码分析
2020.9.23 实现crd 有两派思路,tf-operator 都有体现:
- tf-operator.v1 是目前在用的版本,基于 informer 和 client 裸写的。
- training-operator.v1 是下一个大版本的设计,还不太稳定,没有发布出去。training-operator.v1 是基于 controller-runtime 写的
当然都有大量的复用部分,因此抽了一个
github.com/kubeflow/commmon。kubeflow/commmon不仅用于tf-operator 自身的迭代,也用于整合其它机器学习framework的operator。对于机器学习任务来说,一般都是运行多个进程,ps/master 进程负责协调,worker 进程负责干活儿,所有进程运行同一段代码,相互之间互相访问, 并共享一些全局信息,所以整体上各个operator(tf/pytorch/mpi 等)都是很像的。
以下分析以老版 tf-operator.v1 为主。
// pkg/controller.v1/common/job_controller.go
type JobController struct {
WorkQueue workqueue.RateLimitingInterface
}
// pkg/controller.v1/common/job.go
func (jc *JobController) ReconcileJobs(...){...}
// pkg/controller.v1/common/pod.go
// AddPod/UpdatePod/DeletePod 会作为pod event 的回调,从pod 从获取 resolveControllerRef 并将对应的tf job 加入workqueue
func (jc *JobController) AddPod(obj interface{}) {...}
func (jc *JobController) UpdatePod(old, cur interface{}) {...}
func (jc *JobController) DeletePod(obj interface{}) {...}
func (jc *JobController) ReconcilePods(...){...}
// pkg/controller.v1/common/service.go
pod/service/tfjob 的变化都会转换 jobname 加入到WorkQueue 触发reconcileTFJobs
// pkg/controller.v1/tensorflow/controller.go
func (tc *TFController) processNextWorkItem() bool {
...
// 这个Handler其实是SyncTFJob这个函数
forget, err := tc.syncHandler(key)
...
}
func (tc *TFController) syncTFJob(key string) (bool, error) {
...
// 调用reconcileTFJobs这个函数来“启动”TFJobs
reconcileTFJobsErr = tc.reconcileTFJobs(tfjob)
...
}
// pkg/controller.v1/common/job.go
func (jc *JobController) ReconcileJobs(...)error{
pods, err := jc.Controller.GetPodsForJob(job)
services, err := jc.Controller.GetServicesForJob(job)
// If the Job is succeed or failed, delete all pods and services.
// If the Job exceeds backoff limit or is past active deadline delete all pods and services, then set the status to failed
// 正常 Reconcile 逻辑
if jc.Config.EnableGangScheduling {
_, err := jc.SyncPodGroup(metaObject, pgSpec)
}
// Diff current active pods/services with replicas.
for rtype, spec := range replicas {
err := jc.Controller.ReconcilePods(metaObject, &jobStatus, pods, rtype, spec, replicas)
err = jc.Controller.ReconcileServices(metaObject, services, rtype, spec)
}
// 如果状态变更了就更新到apiserver
}
reconcilePods
Kubeflow实战系列: 利用TFJob运行分布式TensorFlow TFJob 的核心是构建ClusterSpec。
{
"cluster":{
"chief":[],
"ps":[],
"worker":[]
}
}
tf_operator的工作就是创建对应的Pod, 并且将环境变量TF_CONFIG传入到每个Pod中,TF_CONFIG包含三部分的内容,当前集群ClusterSpec, 该节点的角色类型,以及id。
// pkg/controller.v1/tensorflow/pod.go
func (tc *TFController) reconcilePods(...) {
...
// 调用createNewPod函数创建Pod
err = tc.createNewPod(tfjob, rt, strconv.Itoa(index), spec, masterRole)
...
}
func (tc *TFController) createNewPod(...) error {
...
// 生成集群的配置信息,这里最关键,看一下实现
setClusterSpec(podTemplate, tfjob, rt, index)
if tc.Config.EnableGangScheduling {... podTemplate.Spec.SchedulerName = gangSchedulerName ...}
// 使用上面的配置信息,真正启动Pod的创建
tc.PodControl.CreatePodsWithControllerRef(tfjob.Namespace, podTemplate, tfjob, controllerRef)
...
}
func setClusterSpec(podTemplateSpec *v1.PodTemplateSpec, tfjob *tfv1.TFJob, rt, index string) error {
...
// 有没有看到熟悉的字眼:这里生成了TF_CONFIG的Json串
tfConfigStr, err := genTFConfigJSONStr(tfjob, rt, index)
// 接着把TF_CONFIG作为Env环境变量,在启动时传递给容器
for i := range podTemplateSpec.Spec.Containers {
if podTemplateSpec.Spec.Containers[i].Name == tfv1.DefaultContainerName {
podTemplateSpec.Spec.Containers[i].Env = append(podTemplateSpec.Spec.Containers[i].Env, v1.EnvVar{
Name: tfConfig, // tfConfig == “TF_CONFIG”
Value: tfConfigStr,
})
break
}
}
...
}
// TF_CONFIG的生成过程,很直接
func genTFConfigJSONStr(tfjob *tfv1.TFJob, rtype, index string) (string, error) {
i, err := strconv.ParseInt(index, 0, 32)
cluster, err := genClusterSpec(tfjob)
// 组装形成TF_CONFIG
tfConfig := TFConfig{
Cluster: cluster,
Task: TaskSpec{
Type: rtype,
Index: int(i),
},
Environment: "cloud",
}
}
func genClusterSpec(tfjob *tfv1.TFJob) (ClusterSpec, error) {
...
// 这里循环生成了TF_CONFIG里面的Cluster信息。注意看注释,使用DNS配合Service,解决的还是各个节点IP不固定的问题
for i := int32(0); i < *spec.Replicas; i++ {
// As described here: https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#a-records.
// Headless service assigned a DNS A record for a name of the form "my-svc.my-namespace.svc.cluster.local".
// And the last part "svc.cluster.local" is called cluster domain
// which maybe different between kubernetes clusters.
hostName := jobcontroller.GenGeneralName(tfjob.Name, rt, fmt.Sprintf("%d", i))
svcName := hostName + "." + tfjob.Namespace + "." + "svc"
cluserDomain := os.Getenv(EnvCustomClusterDomain)
if len(cluserDomain) > 0 {
svcName += "." + cluserDomain
}
endpoint := fmt.Sprintf("%s:%d", svcName, port)
replicaNames = append(replicaNames, endpoint)
}
// rt是角色,比如worker, ps等
clusterSpec[rt] = replicaNames
...
}
reconcileServices
// pkg/controller.v1/tensorflow/service.go
func (tc *TFController) reconcileServices(...) {
...
// 循环创建多个Service
serviceSlices := tc.GetServiceSlices(services, replicas, tflogger.LoggerForReplica(tfjob, rt))
for index, serviceSlice := range serviceSlices {
if len(serviceSlice) > 1 {
...
} else if len(serviceSlice) == 0 {
tflogger.LoggerForReplica(tfjob, rt).Infof("need to create new service: %s-%d", rt, index)
// 调用createNewService创建Service
err = tc.createNewService(tfjob, rtype, strconv.Itoa(index), spec)
}
}
...
}
func (tc *TFController) createNewService(...) {
...
// 这里就直接生成了Service的配置信息。注意Selector
service := &v1.Service{
Spec: v1.ServiceSpec{
ClusterIP: "None",
Selector: labels,
Ports: []v1.ServicePort{
{
Name: tfv1.DefaultPortName,
Port: port,
},
},
},
}
// Service的名字
service.Name = jobcontroller.GenGeneralName(tfjob.Name, rt, index)
service.Labels = labels
// 调用后面的接口创建Service
err = tc.ServiceControl.CreateServicesWithControllerRef(tfjob.Namespace, service, tfjob, controllerRef)
}
Running jobs with gang-scheduling
Take tf-operator for example, enable gang-scheduling in tf-operator by setting true to --enable-gang-scheduling flag. Volcano scheduler and operator in Kubeflow achieve gang-scheduling by using PodGroup. operator will create the PodGroup of the job automatically. operator 会创建PodGroup,Volcano scheduler 会根据PodGroup 实现gang-scheduling,TFJob yaml 本身无区别。
老版tf-operator 使用kube-batch,新版使用Volcano
kubeflow/commmon
以tf-operator/pytorch-operator/mpi-operator 为例,一开始是独立发展,有对应的tfjob/pytorchjob/mpijob,但有许多共通之处
- xxjob 在runPolicy上有共通的性质 ,比如gang-schdueler 所需的 SchedulerPolicy ,都包含ReplicaSpec,需要用JobStatus 描述状态
- xxjob 在Reconcile 上有共通的逻辑,为xxjob 创建对应的pod 和service(为pod 之间互通),并根据pod 运行状态更新xxjob 状态
github.com/kubeflow/common
/pkg
/apis/common/v1
/types.go // 定义了 RunPolicy 等struct
/interface.go // 定义了 ControllerInterface
/controller.v1
/common
/job_controller.go // 定义了 JobController struct
所以kubeflow/common 定义了RunPolicy 等struct作为xxjob 的成员
type ControllerInterface interface {
// Get 方法
ControllerName() string
GetJobFromInformerCache(namespace, name string) (metav1.Object, error)
GetJobFromAPIClient(namespace, name string) (metav1.Object, error)
GetPodsForJob(job interface{}) ([]*v1.Pod, error)
GetServicesForJob(job interface{}) ([]*v1.Service, error)
// Reconcile 方法
ReconcileJobs(job interface{}, replicas map[ReplicaType]*ReplicaSpec, jobStatus JobStatus, runPolicy *RunPolicy) error
ReconcilePods(job interface{}, jobStatus *JobStatus, pods []*v1.Pod, rtype ReplicaType, spec *ReplicaSpec,
replicas map[ReplicaType]*ReplicaSpec) error
ReconcileServices(job metav1.Object, services []*v1.Service, rtype ReplicaType, spec *ReplicaSpec) error
}
type JobController struct {
Controller apiv1.ControllerInterface
...
}
// github.com/kubeflow/common/pkg/controller.v1/common/job.go
func (jc *JobController) ReconcileJobs(job interface{}, replicas map[ReplicaType]*ReplicaSpec, jobStatus JobStatus, runPolicy *RunPolicy)error{}
// github.com/kubeflow/common/pkg/controller.v1/common/job_controller.go
func (jc *JobController) SyncPodGroup(job metav1.Object, pgSpec v1beta1.PodGroupSpec) (*v1beta1.PodGroup, error) {...}
kubeflow/common 定义了 JobController,JobController.ReconcileJobs 是 Reconcile 逻辑的入口:为xxjob 创建对应的pod 和service(为pod 之间互通),并根据pod 运行状态更新xxjob 状态。这个过程中要获取 job/pod/service 的信息,要Reconcile Pods/Services。
JobController 类似模板类,需要实现核心逻辑,又要留有足够的扩展性,Get 方法自己做不了需要 嵌入 ControllerInterface 以使用Getxx 方法,ReconcilePods/Service 既要实现又 不能直接调用(否则上层业务方还扩展个啥)。
- TFJobReconciler 聚合了 JobController,这样可以使用 JobController.ReconcileJobs 触发Reconcile 逻辑(即实现 Reconcile interface)
- TFJobReconciler 又实现了ControllerInterface ,JobController 通过 ControllerInterface 实现聚合TFJobReconciler 的效果, 可以调用Get 方法获取信息,也可以调用 Reconcile 方法执行上层自定义扩展逻辑。
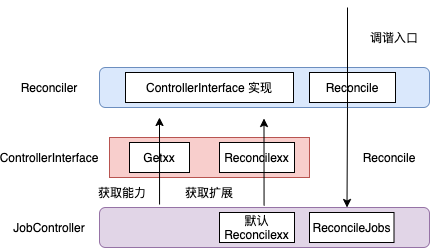
为啥 TFJobReconciler 和 JobController要相互(直接或间接)聚合呢?可以认为,如果不是想把 所有逻辑都缩在 TFJobReconciler 中,完全可以 实现一个 TFJobControllerInterface 代替TFJobReconciler 实现ControllerInterface 接口,TFJobReconciler.Reconcile ==> JobController.ReconcileJobs ==> TFJobControllerInterface.Getxx/Reconcilexx
// github.com/kubeflow/tf-operator/pkg/controller.v1/tensorflow/tfjob_controller.go
type TFJobReconciler struct {
common.JobController
client.Client
Scheme *runtime.Scheme
...
}
func (r *TFJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {}