简介
- 简介
- 进程——为啥创建进程的 系统调用起名叫fork(分支)
- 内存管理 brk和mmap
- 一切皆文件
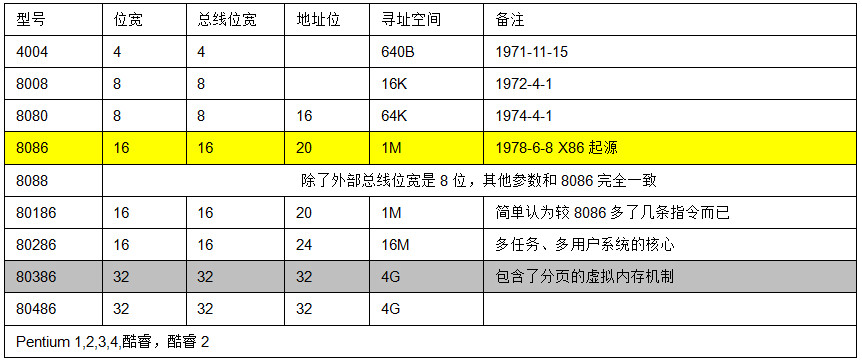
- x86 架构
- 操作系统是一个main函数
- 从glibc 到系统调用
- 输入输出
- 信号处理
- 学以致用
- debug kernel
所谓成长,就是知道自己目前在哪里,清楚将要去哪里,然后通过学习和行动到达目的地。
进程——为啥创建进程的 系统调用起名叫fork(分支)
一句看似废话的废话:进程是进程创建出来的 PS:就好像github fork 代码一样
创建进程的系统调用叫fork。这个名字很奇怪,中文叫“分支”为啥启动一个新进程叫“分支”呢?在 Linux 里,要创建一个新的进程,需要一个老的进程调用fork 来实现,其中老的进程叫作父进程(Parent Process),新的进程叫作子进程(Child Process)。当父进程调用 fork 创建进程的时候,子进程将各个子系统为父进程创建的数据结构也全部拷贝了一份,甚至连程序代码也是拷贝过来的。
对于 fork 系统调用的返回值,如果当前进程是子进程,就返回0;如果当前进程是父进程,就返回子进程的进程号。这样首先在返回值这里就有了一个区分,然后通过 if-else 语句判断,如果是父进程,还接着做原来应该做的事情;如果是子进程,需要请求另一个系统调用execve来执行另一个程序,这个时候,子进程和父进程就彻底分道扬镳了,也即产生了一个分支(fork)了。
public static void main(String[] args) throws IOException {
Process process = Runtime.getRuntime().exec("/bin/sh -c ifconfig");
//
// jvm这里隐藏了一个 父子进程 判断的过程
//
Scanner scanner = new Scanner(process.getInputStream());
while (scanner.hasNextLine()) {
System.out.println(scanner.nextLine());
}
scanner.close();
}
新进程 都是父进程fork出来的,那到底谁是第一个呢?这就是涉及到系统启动过程了。
突然想起来,linux 和 git 都是大佬Linus的 杰作。
内存管理 brk和mmap
内存空间都是”按需分配“的,但在OS层面上,都是整存整取的。对于int[] array = new int[100];
| 层次 | 表现 | array对应的感觉 |
|---|---|---|
| java 语言 | 申请一个数组,得到一个引用array | 进程标识 + 进程内 偏移地址 |
| jvm | 在堆里申请一段空间 | 进程数据段地址 + 偏移地址 |
| os | 对于一般进程,就是申请时给进程的堆一段空间。 对于jvm 就是jvm 启动时申请一段连续的空间,然后再由jvm自行管理内存分配 |
物理内存地址 |
一切皆文件
“一切皆文件”的优势,就是统一了操作的入口
x86 架构
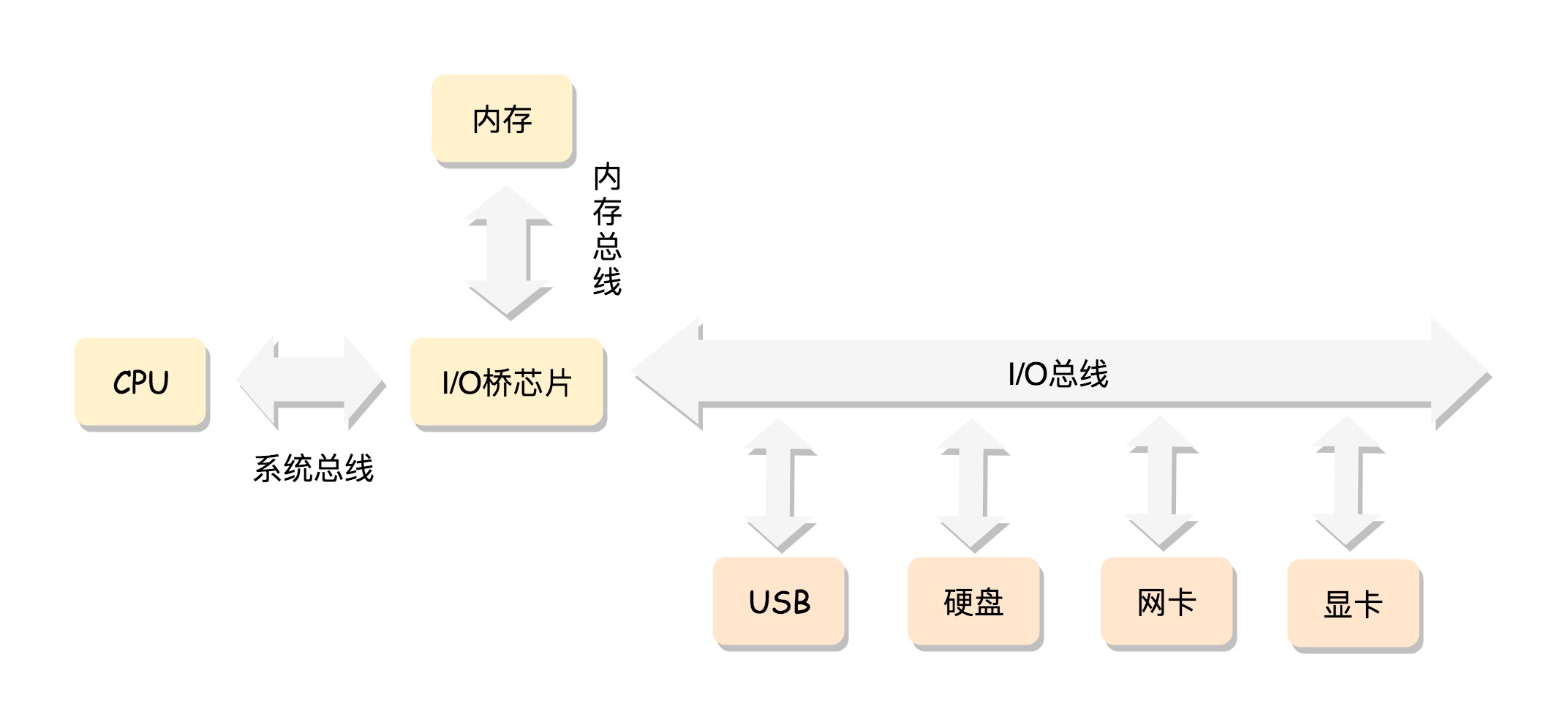
“指令格式-cpu结构-总线”的暧昧关系
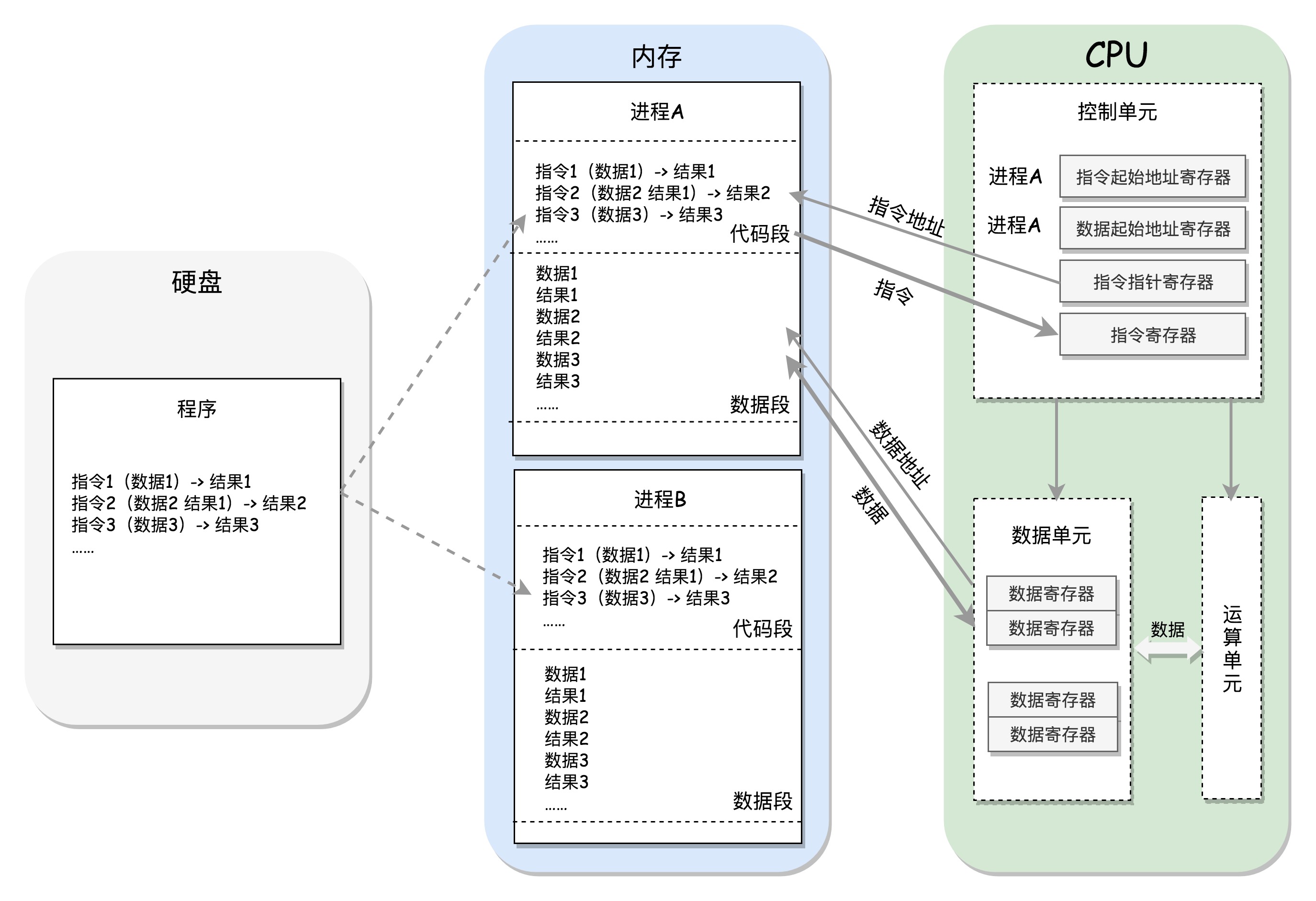
我们以一段x86汇编代码为例
mov [ebp-4], edi ; Move EDI into the local variable
add [ebp-4], esi ; Add ESI into the local variable
add eax, [ebp-4] ; Add the contents of the local variable
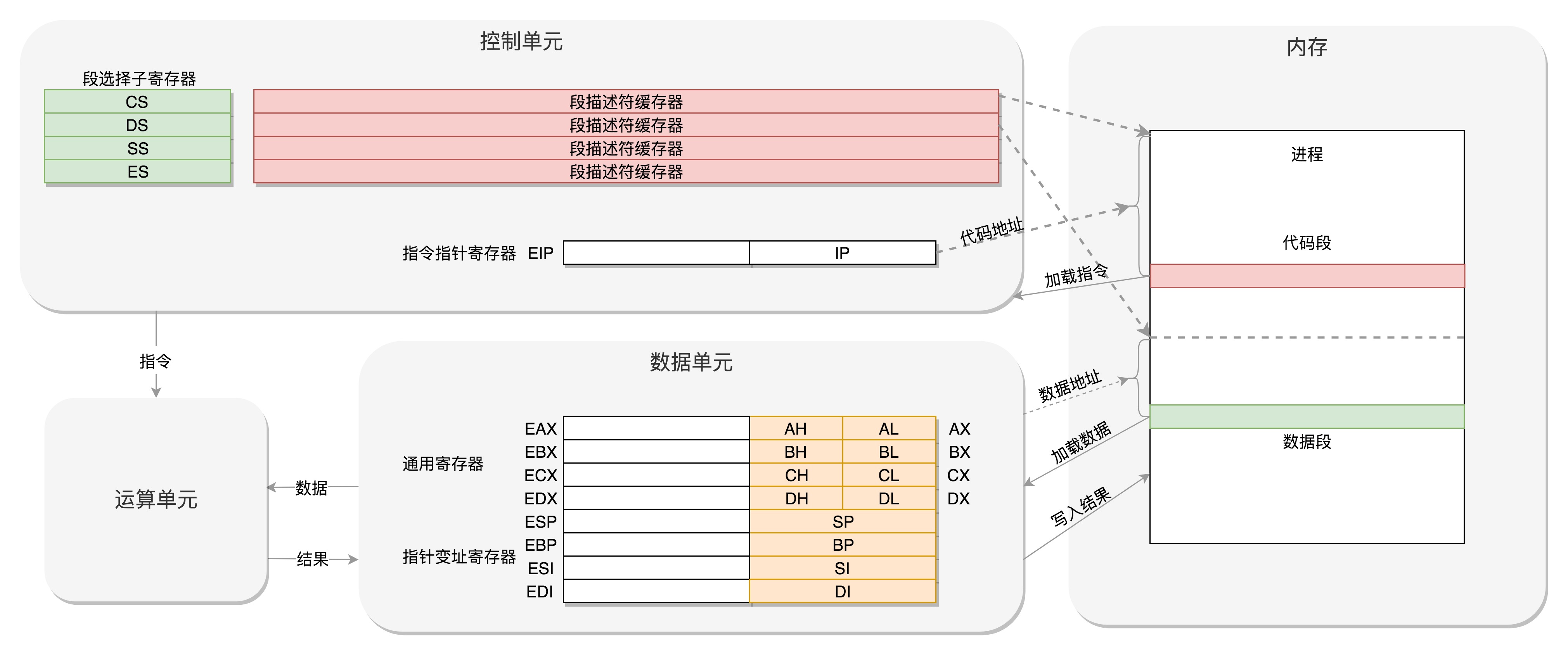
CPU 的控制单元里面,有一个指令指针寄存器,执行的是下一条指令在内存中的地址。控制单元会不停地将代码段的指令拿进来,先放入指令寄存器。当前的指令分两部分,一部分是做什么操作,例如是加法还是位移;一部分是操作哪些数据。要执行这条指令,就要把第一部分交给运算单元,第二部分交给数据单元。数据单元根据数据的地址,从数据段里读到数据寄存器里,就可以参与运算了。运算单元做完运算,产生的结果会暂存在数据单元的数据寄存器里。最终,会有指令将数据写回内存中的数据段。
CPU 里有两个寄存器,专门保存当前处理进程的代码段的起始地址,以及数据段的起始地址。这里面写的都是进程 A,那当前执行的就是进程 A 的指令,等切换成进程 B,就会执行 B的指令了,这个过程叫作进程切换(Process Switch)(注意跟线程切换做区别)
CPU 和内存来来回回传数据,靠的都是总线。其实总线上主要有两类数据,一个是地址数据,也就是我想拿内存中哪个位置的数据,这类总线叫地址总线(Address Bus);另一类是真正的数据,这类总线叫数据总线(Data Bus)。
| 程序 | 算法 | 数据结构 | |
|---|---|---|---|
| 指令 | 操作码 | 立即数/地址 | |
| cpu | 运算单元 | 数据单元 | |
| 整体结构 | cpu | 内存 | 地址总线/数据总线 |
程序是代码写的,所以一定要有”代码段“。代码的执行过程 会产生临时数据,所以要有”数据段“(数据段根据数据特点,一般分为堆和栈,此处不准确但不影响理解)。PS:这种描述方式很有感觉。进程管理信息数据结构 二进制文件分段 ==> 进程分段 ==> 指令操作码/操作数 ==> cpu运算单元/数据单元 ==> cpu代码段寄存器/数据段寄存器/堆栈段寄存器等 有一种软硬件融合的味道。
一切运算即加法,一切分支代码即jump
为什么要有保护模式?
保护模式更多是intel 兼容旧体系的历史包袱,一些新的指令体系都抛弃这一套了。
- CPU的位数是指CPU能一次同时寄存和处理二进制数码的位数,这和CPU中寄存器的位数对应,一般和数据总线的宽度一致(过宽了数据寄存器也存不下)
- 数据总线DB用于传送数据信息。数据总线是双向三态形式的总线,即他既可以把CPU的数据传送到存储器或I/O接口等其它部件,也可以将其它部件的数据传送到CPU。”地址总线AB是专门用来传送地址的,由于地址只能从CPU传向外部存储器或I/O端口,所以地址总线总是单向三态的,这与数据总线不同。
关于“实模式”和“保护模式” 实模式与保护模式解惑之(一)——二者的起源与区别
- 最开始 数据总线与地址总线宽度一致
- “段:偏移”模式。后来,8086cpu可以处理的二进制码是16位,也就是cpu能够表达的地址最大是16位的。需要一个16位内存地址到20位实际地址的转换的过程。为什么是20 不是32呢?[CPU的历史疑惑当初8086cpu为什么不直接设计成32根地址总线呢,弄成20根,用段+偏移的寻址方式不觉得尴尬吗?] (https://www.zhihu.com/question/23567412/answer/498882312) 因为当时的程序猿感觉1M内存就够大了。但”段地址“确实是个不错的副产品。
-
到这个时候,无论数据总线与地址总线宽度一致,程序员指定的地址就是物理地址,物理地址对程序员是可见的。但是,由此也带来两个问题:
- 无法支持多任务
- 程序的安全性无法得到保证(用户程序可以改写系统空间或者其他用户的程序内容)
- “段选择符:段内偏移地址”,保护模式和实模式的区别在于它是用段选择符而非段基地址,段选择符中包含特权级 信息
Java和操作系统交互细节假设我们现在还没有虚拟地址,只有物理地址,编译器在编译程序的时候,需要将高级语言转换成机器指令,那么 CPU 访问内存的时候必须指定一个地址,这个地址如果是一个绝对的物理地址,那么程序就必须放在内存中的一个固定的地方,而且这个地址需要在编译的时候就要确认,大家应该想到这样有多坑了吧, 如果我要同时运行两个 office word 程序,那么他们将操作同一块内存,那就乱套了,伟大的计算机前辈设计出,让 CPU采用段基址 + 段内偏移地址 的方式访问内存,其中段基地址在程序启动的时候确认(分段的重大意义所在,段内地址编译时确认,段基地址启动时确认),尽管这个段基地址还是绝对的物理地址,但终究可以同时运行多个程序了, CPU 采用这种方式访问内存,就需要段基址寄存器和段内偏移地址寄存器来存储地址,最终将两个地址相加送上地址总线。在保护模式下,每一个进程都有自己独立的地址空间,所以段基地址是固定的,只需要给出段内偏移地址就可以了,而这个偏移地址称为线性地址,线性地址是连续的,而内存分页将连续的线性地址和和分页后的物理地址相关联,这样逻辑上的连续线性地址可以对应不连续的物理地址(连续的物理地址很宝贵)。物理地址空间可以被多个进程共享,而这个映射关系将通过页表( page table)进行维护
操作系统是一个main函数
从加载顺序可以看到
- BIOS、Bootloader 与 os 的边界
- os 内核(是一个单独的内核镜像文件,也对应内核态) 与 os其它部分的边界(对应用户态)
内核镜像格式 与 一般可执行的文件格式(elf)也基本上是一致的。
为什么不直接加载操作系统?
Linux 启动过程:BIOS ==> MBR ==> BootLoader(grub) ==> kernel ==> systemd(centos7) ==> 系统初始化 ==> shell
| 存储 | 加载到内存 | 功能 | |
|---|---|---|---|
| BIOS(Basic Input and Output System) | ROM | ROM 直接映射到内存 | 检查硬件 简单的中断表使你可以使用鼠标和键盘 加载启动盘 |
| GRUB | 磁盘MBR | 第一个扇区直接映射到内存 ==> 加载第二阶段引导程序 ==> 加载内核镜像 | 展示内核列表 加载用户选中的linux内核文件 |
| 内核 | 文件系统某个(img)文件 | 0号进程,内核写死的 1号进程,ramdisk 的“/init”文件,会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk 上的 /init 会启动文件系统上的 init。 2号进程,内核线程,比如处理aio 的内核线程 |
|
| 用户态init进程(centos6) | 文件系统某个可执行文件 |
从上到下
- 所需内存空间越来越大;
- 对于内核代码还值得信任,启动用户代码时,就要开启保护模式了
-
地址/直接引用(BIOS地址,MBR地址) ==> (内存/磁盘)文件系统引用;中断表等符号引用
- 启动的第一个动作为什么不是字节将内核镜像copy至内存 然后执行?因为不知道内核镜像在哪?不知道用户要启动哪个?不知道用户镜像有多大(也就不知道拷贝多少)?
- 文件系统驱动太大,无法弄到内核,就先弄一个内存文件系统 ramdisk
initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img,等内核启动成功后再加载。PS:内核也玩懒加载这一套 - GNU GRUB(GRand Unified Bootloader简称“GRUB”)是一个来自GNU项目的多操作系统启动程序。GRUB是多启动规范的实现,它允许用户可以在计算机内同时拥有多个操作系统,并在计算机启动时选择希望运行的操作系统。还记得当年装的U盘启动盘么?
开机F12可以启动硬盘上的os,也可以启动U盘上的小系统
2019.5.22 最近在看教父系列,可以将bios、bootloader等接力看成是“交班接班”,一代有一代的任务和问题,一代创业,二代守成和洗白。
操作系统是一个main函数/中断处理程序的集合
操作系统是一个main函数 提出了两个问题:
- 当我们说写一个操作系统,是从main函数开始写么?
- 为什么可以单独升级内核?一个重要原因就是 内核从本质上看是一种软件,系统调用是其为上层提供的访问接口。就像docker 看着像一个整体,但docker client 与docker daemon 是分开的。系统调用作为一个接口,是一个协议和约定(比如80中断号),但不是一个代码引用。PS:一般程序 与依赖 是通过静态编译、动态链接 组合在一起的,程序对内核代码也是一种依赖,且该依赖是通过 中断号“链接”在一起。
内核的启动从入口函数 start_kernel() 开始。在 init/main.c 文件中,start_kernel 相当于内核的 main 函数。打开这个函数,你会发现,里面是各种各样初始化函数 XXXX_init。
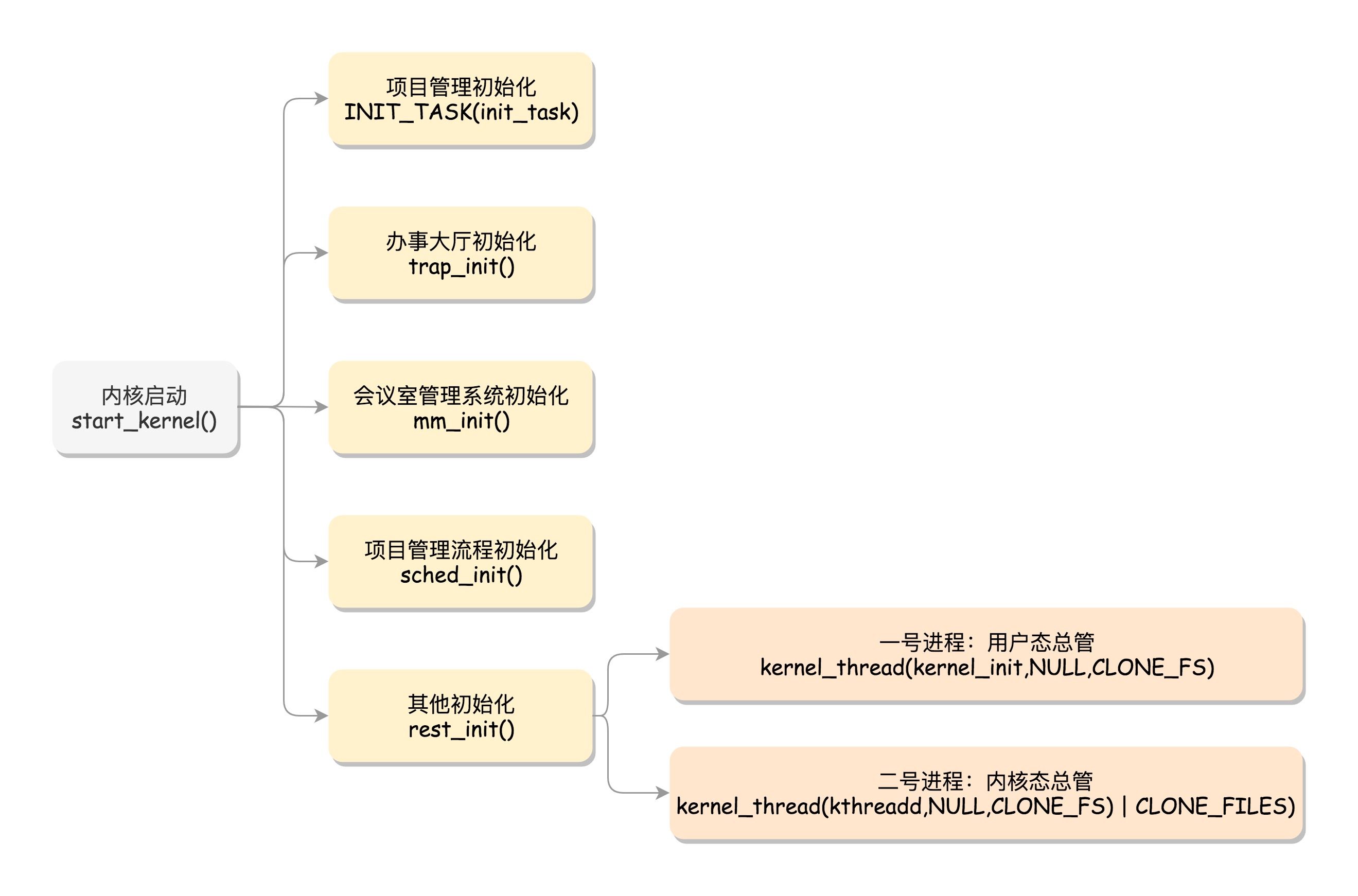
POSIX表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准。
内核就是一个由interrupt驱动的程序?
图画的不准确,待改进
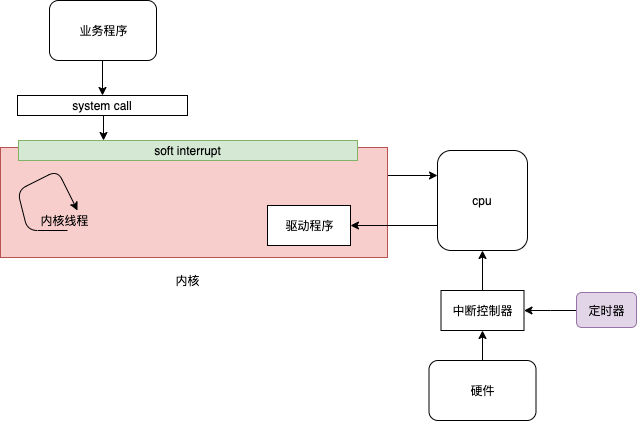
知乎高鹏的回答OS不是运行着的代码,而是一堆躺在内存里等着被调用的代码。内核就是一个由interrupt驱动的程序。这个interrupt可以是一个系统调用(x86下,很多OS的系统调用是靠software interrupt实现的),可以是一个用户程序产生的异常,也可以是一个硬件产生的事件中断。很多教材在讲os的时候,更喜欢从app的角度来看待os,于是很多时候被各种概念绑架。因为很多例如进程/线程/系统调用这样的东西都是由os在硬件上抽象出来的。站在这些概念上看os,就有点“不识庐山真面目”的感觉。所以我的意思是从硬件的角度看os,反过来理解为何os要抽象出这些概念。站在cpu的角度,理解指令是怎么在cpu上一条一条的运行的。
加电后从pc取指令执行代码是cpu硬件决定的,是刻在cpu基因上的。随着对io设备、多进程等的支持,加电后从pc 取指令执行,根据中断信号执行中断处理程序(cpu执行完一条指令就会查询下是否有中断(存疑))也是刻在cpu 基因里的。上层要做的就是 往pc寄存器、 内存、中断控制器 放好正确的数据。为了简化使用,抽象出进程等概念。
进程切换与CPU模式切换
尽管每个进程都有自己的地址空间,每个进程有用户空间和内核空间,但都必须共享CPU寄存器
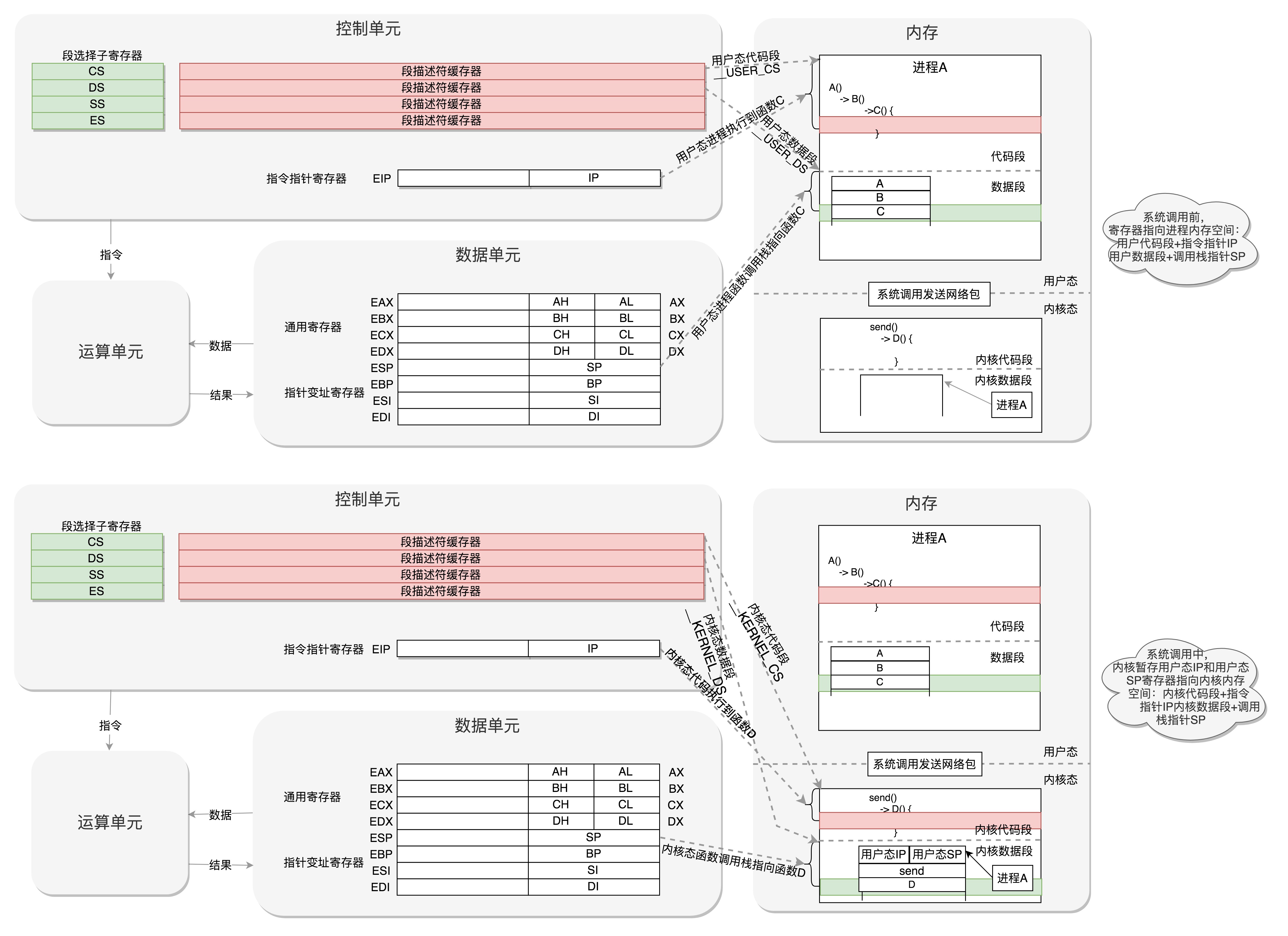
内核从本质上看是一种软件,系统调用是其为上层提供的访问接口,用户态和内核态可以看成一种微型的cs架构
| 进程切换 | 模式切换 | |
|---|---|---|
| 触发 | 时间片中断触发/进程阻塞 | 软中断触发 |
| CPU寄存器切换到 | 目标进程上下文 | 当前进程内核态上下文 |
| 系统调用执行外还回到用户态,所以内核态会暂存用户态IP和SP | ||
| 数据复制 | 无内存复制 | 例如io操作等会涉及到内存复制 |
从虚拟内存机制的视角,操作系统内核的代码和数据,不只为所有进程所共享,而且在所有进程中拥有相同的地址。这样无论哪个进程请求过来,对内核来说看起来都是一次本进程内的请求。从单个进程的视角,中断向量表的地址,以及操作系统内核的地址空间是一个契约。有了中断向量表的地址约定,用户态函数就可以发起一次系统调用(软中断)。当然你可能要问:既然操作系统内核和我同属一个地址空间,我是否可以跳过中断,直接访问调用内核函数?(PS:从指令上讲,调用系统调用是int,调用函数是call,call 只是调整了pc、栈等少数寄存器,但都没有引发调度)当然不能。这涉及虚拟内存中的内存页保护机制。内存页可以设置 “可读、可写、可执行” 三个标记位。操作系统内核虽然和用户进程同属一个地址空间,但是被设置为“不可读、不可写、不可执行”。虽然这段地址空间是有内容的,但是对于用户来说是个黑洞。
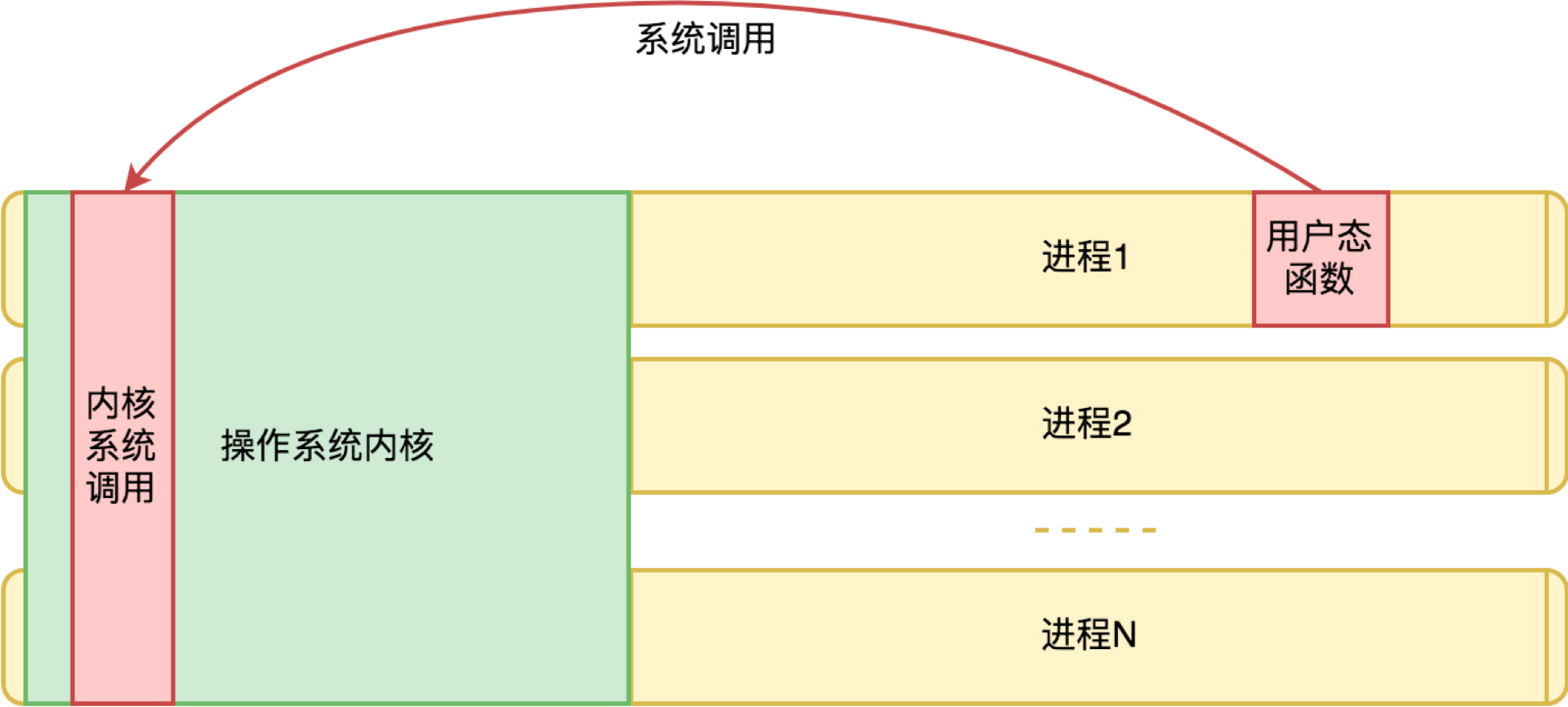
软中断是执行中断指令产生的,而硬中断是由外设引发的。硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。硬中断是可屏蔽的,软中断不可屏蔽。如果硬件需要CPU去做一些事情,那么这个硬件会使CPU中断当前正在运行的代码。而后CPU会将当前正在运行进程的当前状态放到堆栈(stack)中,以至于之后可以返回继续运行。硬中断可以停止一个正在运行的进程;可以停止正处理另一个中断的内核代码;或者可以停止空闲进程。产生软中断的进程一定是当前正在运行的进程,因此它们不会中断CPU。
从glibc 到系统调用
为什么需要系统调用?为了保证操作系统的稳定性和安全性。用户程序不可以直接访问硬件资源,如果用户程序需要访问硬件资源,必须调用操作系统提供的接口,这个调用接口的过程也就是系统调用。用户写的代码最终也会被编译为机器指令,用户代码不允许出现in/out 等访问硬件的指令,想执行这些指令只能“委托”系统人员写的内核代码。或者说,假设机器支持100条指令,开发只能使用其中六七十个,高级语言经过编译器的翻译后不会使用这些指令,但在汇编时代,用户提交的汇编代码指令是可以随便用的。
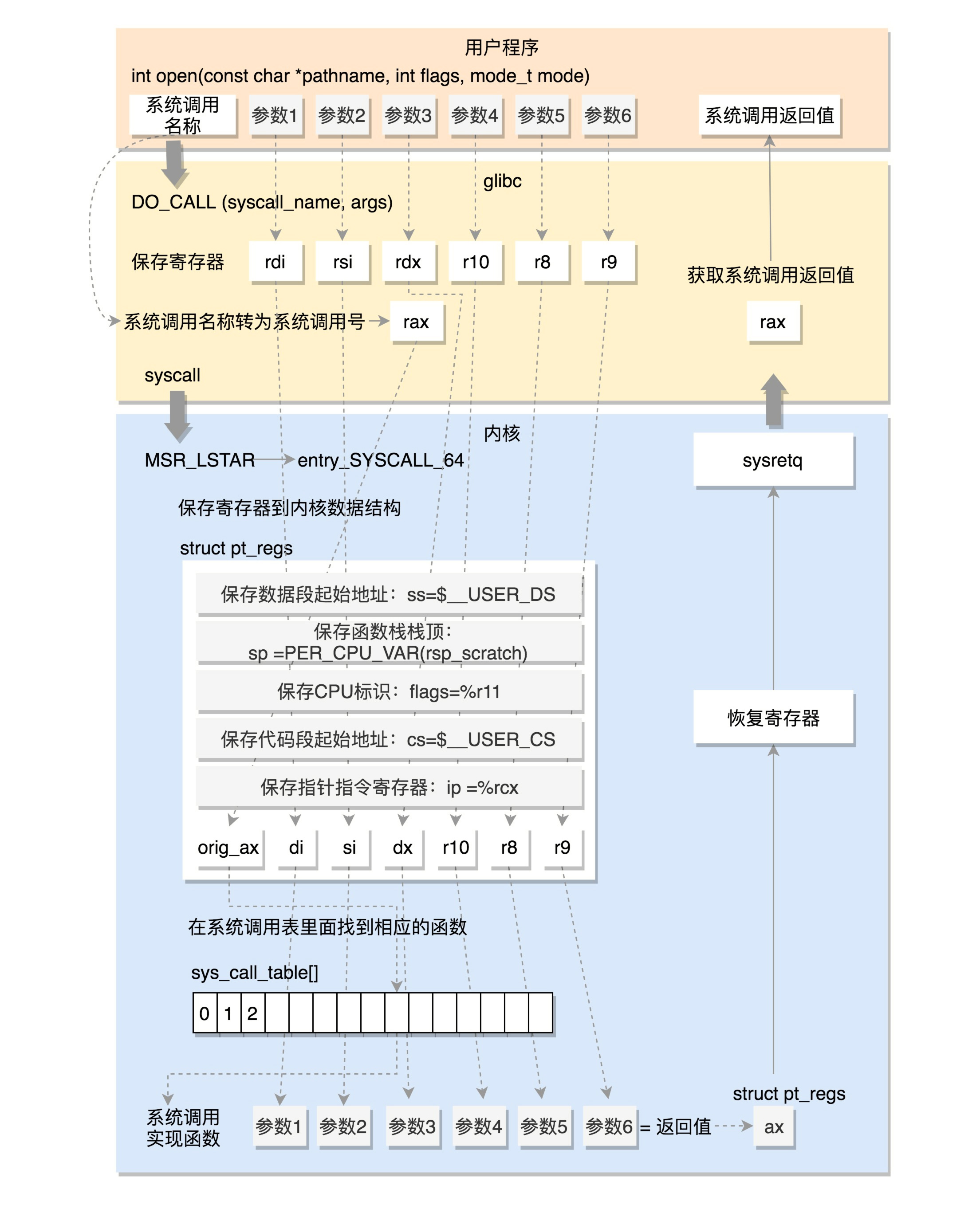
syscal和 int 指令一样,都会发生特权级切换,都可以让 CPU 跳转到特定的地址上,只不过不经过中断门,系统调用返回时要用 sysexit 指令。intel体系的系统调用限制最多六个参数,参数和返回值(rax)都通过寄存器传递。
- glibc 的 syscal.list 列出 glibc 函数对应的系统调用
- glibc 的脚本 make_syscall.sh 根据 syscal.list 生成对应的宏定义(函数映射到系统调用)
- glibc 的 syscal-template.S 使用这些宏, 定义了系统调用的调用方式(也是通过宏)
- 其中会调用 DO_CALL (也是一个宏), 32位与 64位实现不同
glibc 里面的 open 函数int open(const char *pathname, int flags, mode_t mode),在 glibc 的源代码中,有个文件 syscalls.list,里面列着所有 glibc 的函数对应的系统调用
# File name Caller Syscall name Args Strong name Weak names
open - open Ci:siv __libc_open __open open
以32位为例,函数名 ==> Syscall name ==> DO_CALL(该函数直接由汇编代码定义) ==> int $0x80
/* Linux takes system call arguments in registers:
syscall number %eax call-clobbered
arg 1 %ebx call-saved
arg 2 %ecx call-clobbered
arg 3 %edx call-clobbered
arg 4 %esi call-saved
arg 5 %edi call-saved
arg 6 %ebp call-saved
......
*/
#define DO_CALL(syscall_name, args) \
PUSHARGS_##args \
DOARGS_##args \
movl $SYS_ify (syscall_name), %eax; \
ENTER_KERNEL \
POPARGS_##args
# define ENTER_KERNEL int $0x80
函数传参到底层就是寄存器传参了。glibc 让我们完全以C语言的方式与内核交互,屏蔽了系统调用表、软中断、寄存器等硬件细节。
《操作系统实战》Cosmos 示例操作系统:int 指令提供了应用程序进入操作系统内核函数的底层机制;寄存器解决参数传递问题(个系统服务接口函数不会超过 5 个参数)最终由 C 语言中嵌入汇编代码的方式来实现。PS: 找一下一段汇编是一个c函数的感觉
//传递一个参数所用的宏
#define API_ENTRY_PARE1(intnr,rets,pval1) \
__asm__ __volatile__(\
"movq %[inr],%%rax\n\t"\//系统服务号
"movq %[prv1],%%rbx\n\t"\//第一个参数
"int $255 \n\t"\//触发中断
"movq %%rax,%[retval] \n\t"\//处理返回结果
:[retval] "=r" (rets)\
:[inr] "r" (intnr),[prv1]"r" (pval1)\
:"rax","rbx","cc","memory"\
)
//传递四个参数所用的宏
#define API_ENTRY_PARE4(intnr,rets,pval1,pval2,pval3,pval4) \
__asm__ __volatile__(\
"movq %[inr],%%rax \n\t"\//系统服务号
"movq %[prv1],%%rbx \n\t"\//第一个参数
"movq %[prv2],%%rcx \n\t"\//第二个参数
"movq %[prv3],%%rdx \n\t"\//第三个参数
"movq %[prv4],%%rsi \n\t"\//第四个参数
"int $255 \n\t"\//触发中断
"movq %%rax,%[retval] \n\t"\//处理返回结果
:[retval] "=r" (rets)\
:[inr] "r" (intnr),[prv1]"g" (pval1),\
[prv2] "g" (pval2),[prv3]"g" (pval3),\
[prv4] "g" (pval4)\
:"rax","rbx","rcx","rdx","rsi","cc","memory"\
)
//示例:时间库函数
sysstus_t api_time(buf_t ttime){
sysstus_t rets;
API_ENTRY_PARE1(INR_TIME,rets,ttime);//处理参数,执行int指令
return rets;
}
// 根据 INR_TIME 查询系统服务表 得到krlsvetabl_time 入口函数
sysstus_t krlsvetabl_time(uint_t inr, stkparame_t *stkparv){
if (inr != INR_TIME)//判断是否时间服务号{
return SYSSTUSERR;
}
//调用真正时间服务函数
return krlsve_time((time_t *)stkparv->parmv1);
}
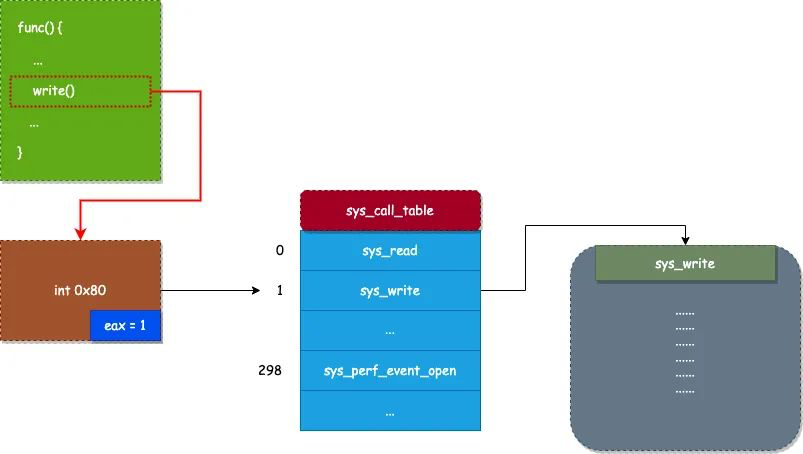
Linux拦截系统调用说白了,系统调用其实就是函数调用,只不过调用的是内核态的函数。但与普通的函数调用不同,系统调用不能使用 call 指令来调用(call不触发特权级切换,改变特定寄存器的值),而是需要使用 软中断 来调用。在 Linux 系统中,系统调用一般使用 int 0x80 指令(x86)或者 syscall 指令(x64)来调用。
- 在 Linux 内核中,使用 sys_call_table 数组来保存所有系统调用,sys_call_table 数组每一个元素代表着一个系统调用的入口
- 当应用程序需要调用一个系统调用时,首先需要将要调用的系统调用号(也就是系统调用所在 sys_call_table 数组的索引)放置到 eax 寄存器中,然后通过使用 int 0x80 指令触发调用 0x80 号软中断服务。
- 0x80 号软中断服务,会通过以下代码来调用系统调用。PS: 经了软中断一手,还是调用了call
... call *sys_call_table(,%eax,8) ...
输入输出
cpu 如何和设备打交道
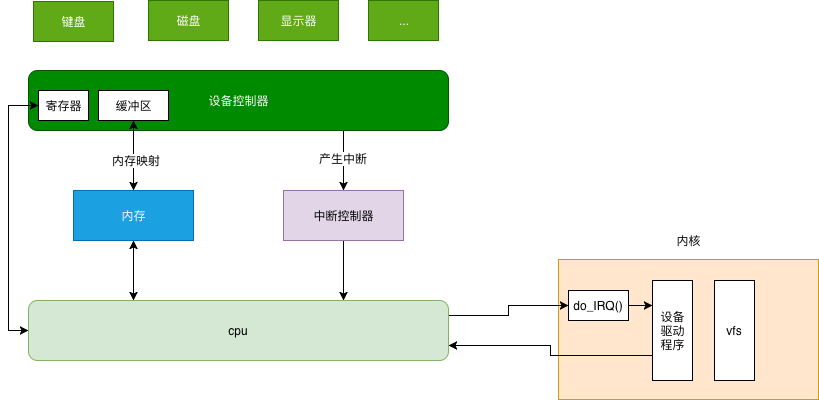
CPU 并不直接和设备打交道,它们中间有一个叫作设备控制器(Device Control Unit)的组件。控制器其实有点儿像一台小电脑。它有它的芯片,类似小 CPU,执行自己的逻辑。它也有它的寄存器。这样 CPU 就可以通过写这些寄存器,对控制器下发指令,通过读这些寄存器,查看控制器对于设备的操作状态。由于块设备传输的数据量比较大,控制器里往往会有缓冲区。CPU写入缓冲区的数据攒够一部分,才会发给设备。CPU 读取的数据,也需要在缓冲区攒够一部分,才拷贝到内存。
cpu 操作设备转换为 ==> cpu操作设备控制器的寄存器/缓冲器。CPU 如何同控制器的寄存器和数据缓冲区进行通信呢?
- 每个控制寄存器被分配一个 I/O 端口,我们可以通过特殊的汇编指令(例如 in/out 类似的指令)操作这些寄存器。
- 数据缓冲区,可内存映射 I/O,可以分配一段内存空间给它,就像读写内存一样读写数据缓冲区。
设备驱动程序
设备控制器不属于操作系统的一部分,但是设备驱动程序属于操作系统的一部分。不同的设备驱动程序,可以以同样的方式接入操作系统,而操作系统的其它部分的代码,也可以无视不同设备的区别,以同样的接口调用设备驱动程序。
一次中断的处理过程
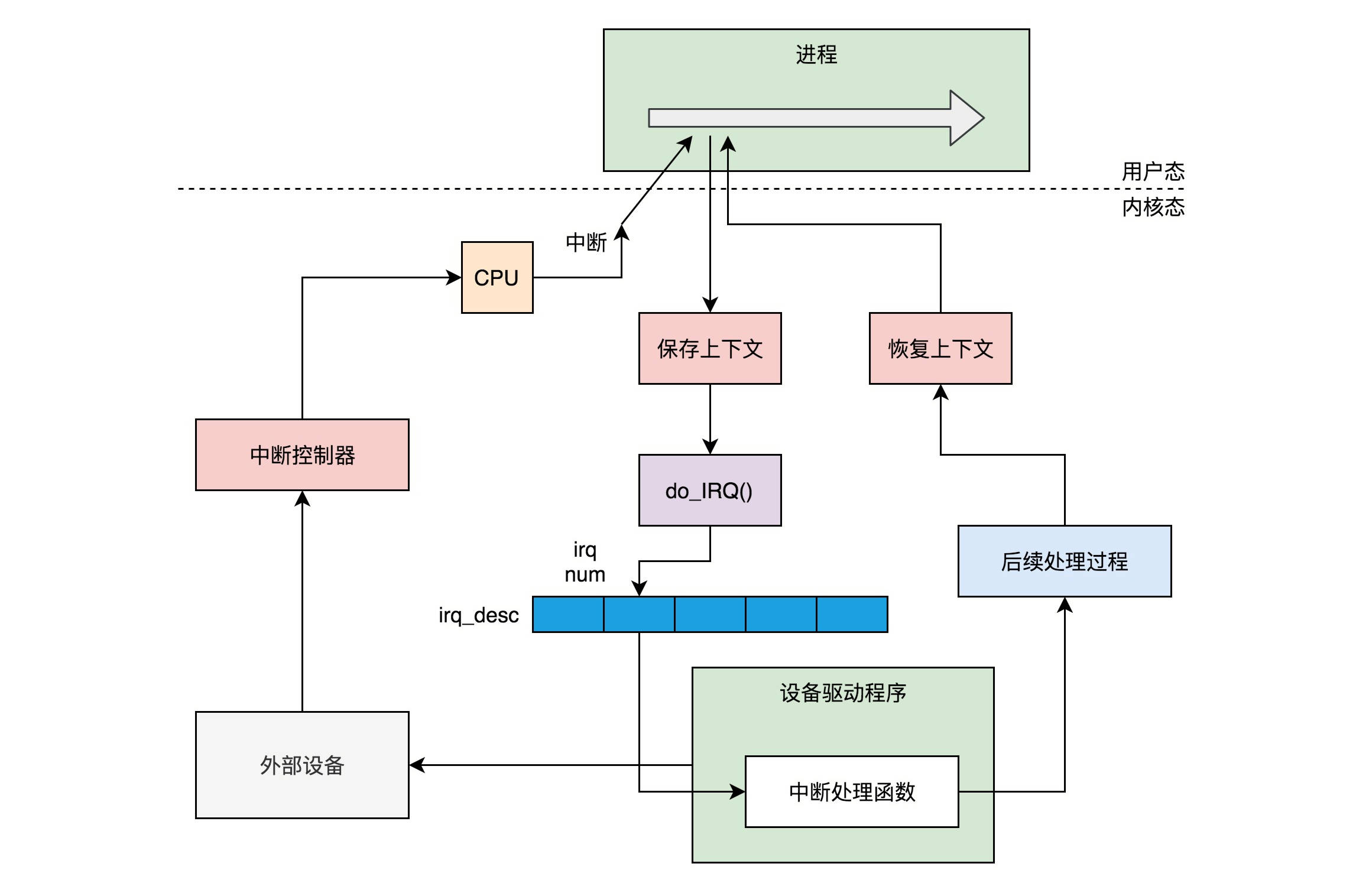
- 一个设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数。
- 中断返回的那一刻也是进程切换的时机
-
用文件系统接口屏蔽驱动程序的差异
- 所有设备都在 /dev/ 文件夹下面创建一个特殊的设备文件。这个设备特殊文件也有 inode,但是它不关联到硬盘或任何其他存储介质上的数据,而是建立了与某个设备驱动程序的连接。
-
内核驱动模块要定一个 file_operations 结构
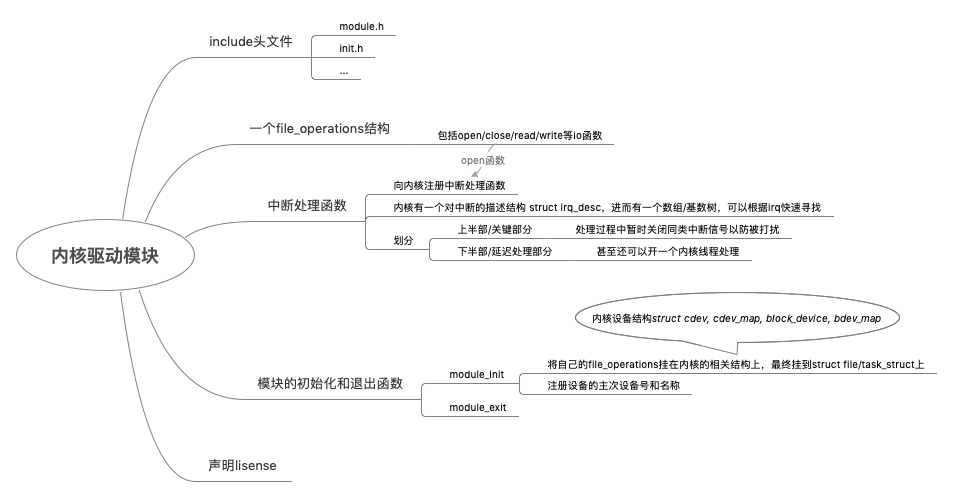
Linux 操作系统新添加了一个设备,且新的设备从来没有加载过驱动,需要安装驱动,其实就是加载一个内核模块。可以通过 insmod 安装内核模块。内核模块的后缀一般是 ko,比如insmod openvswitch.ko。一旦有了驱动,我们就可以通过命令 mknod 在 /dev 文件夹下面创建设备文件mknod filename type major minor,一旦执行了这个命令,新创建的设备文件就和上面加载过的驱动关联起来,这个时候就可以通过操作设备文件来操作驱动程序,从而操作设备。
- filename /dev 下面的设备名称
- type 就是c字符设备b块设备
- major 就是主设备号
- minor就是次设备号
硬盘设备这里有一点绕。假设一个设备文件 /dev/sdb,这个文件本身和硬盘上的文件系统没有任何关系。/dev/sdb 其实是在一个特殊的文件系统 devtmpfs 中。但是当我们将 /dev/sdb 格式化成一个文件系统 ext4 (mkfs.ext4 /dev/sdb)并将它 mount 到一个路径下面,例如在 /mnt/sdb 下面(mount -t ext4 /dev/sdb /mnt/sdb)。这个时候 /dev/sdb 还是一个设备文件在特殊文件系统 devtmpfs 中,而 /mnt/sdb 下面的文件才是在ext4 文件系统中,只不过这个设备是在 /dev/sdb 设备上的。
为什么块设备要比字符设备多此一举呢?比如将一个硬盘的块设备 mount 成为 ext4 的时候,会调用 ext4_mount->mount_bdev,mount_bdev 根据 /dev/xxx 这个名字,找到相应的设备并打开它,然后根据打开的设备文件,填充 ext4 文件系统的 super_block。/dev/sdb的inode 结构是指向设备的,/mnt/sdb 的inode 结构是指向ext4 文件系统的。
2019.12.19补充:浅谈Service Mesh体系中的Envoy一个设备驱动的两个主要职责:
- 存取设备的内存
- 处理设备产生的中断
信号处理
- 我们在终端输入某些组合键的时候,会给进程发送信号,例如,Ctrl+C 产生 SIGINT 信号,Ctrl+Z 产生SIGTSTP 信号。
- 有的时候,硬件异常也会产生信号。比如,执行了除以 0 的指令,CPU 就会产生异常,然后把 SIGFPE 信号发送给进程。再如,进程访问了非法内存,内存管理模块就会产生异常,然后把信号 SIGSEGV 发送给进程。
- 最直接的发送信号的方法就是,通过命令 kill 来发送信号了。
- 我们还可以通过 kill 或者 sigqueue 系统调用,发送信号给某个进程,也可以通过 tkill 或者 tgkill 发送信号给某个线程。
在用户程序里面,有两个函数可以调用,一个是 signal,一个是 sigaction,推荐使用 sigaction。在内核中,rt_sigaction 调用的是 do_sigaction 设置信号处理函数。在每一个进程的task_struct 里面,都有一个 sighand 指向struct sighand_struct,里面是一个数组,下标是信号,里面的内容是信号处理函数。
| 中断 | 信号 | |
|---|---|---|
| 函数执行 | 在内核态 | 在用户态 |
| 严重程度 | 影响整个系统 | 只影响一个进程 |
什么时候真正处理信号呢?就是在从系统调用或者中断返回的时候。无论是从系统调用返回还是从中断返回,都会调用 exit_to_usermode_loop,有一个参数标志位,如果设置了 _TIF_SIGPENDING,我们就调用 do_signal 进行处理
学以致用
linux 内核和文件系统的关系
- 在加载文件系统以前,linux 根据 物理地址加载磁盘上的内容,加载了文件系统之后,linux 根据文件名加载 磁盘内容。
- 内核是如何加载的?什么时候加载的? 内核是grud加载的,然后内核加载根文件系统,然后再是挂载 其它文件系统
- 磁盘上的文件系统,其实就是磁盘上的一堆文件,等被程序按 文件名 访问。包括一堆init 程序。
所以内核和文件系统是加载 和被加载的关系。一个pc 加载哪个内核可以选,一个内核加载哪个文件系统(或者是否记载)也可以选 ,便体现了这个解耦的关系。
“内核”指的是一个提供硬件抽象层、磁盘及文件系统控制、多任务等功能的系统软件。一个内核不是一套完整的操作系统。
另一个重要的关系就是 进程和文件系统的关系。内核根据程序文件运行一个进程,确切的说,是先创建一个进程,然后exec程序文件。这个进程可能用到了很多依赖(也就是其他文件),open/read/write/run 其它文件。 正因为进程 和文件系统的 关系不是那么耦合(先创建进程,再exec 程序文件),就有机会改变一个程序的“视图”,让它把xx目录当做自己的根目录。因为整个程序运行的依赖,是以一个操作系统文 件目录的形式事先准备好的。只要在xx目录里放置一个完整操作系统文件系统部分,该程序运行所需的所有依 赖就完备了。
debug kernel
就像jvm 进程和运行时remote debug 一样,内核也可以debug。