简介
Demystifying memory management in modern programming languages是一个系列,建议细读。
整体描述
内存管理设计精要虽然多数系统都会将内存管理拆分成多个复杂的模块并引入一些中间层提供缓存和转换的功能,但是内存管理系统实际上都可以简化成两个模块,即内存分配器(Allocator)、垃圾收集器(Collector)。在研究内存管理时都会引入第三个模块 — 用户程序(Mutator/App)
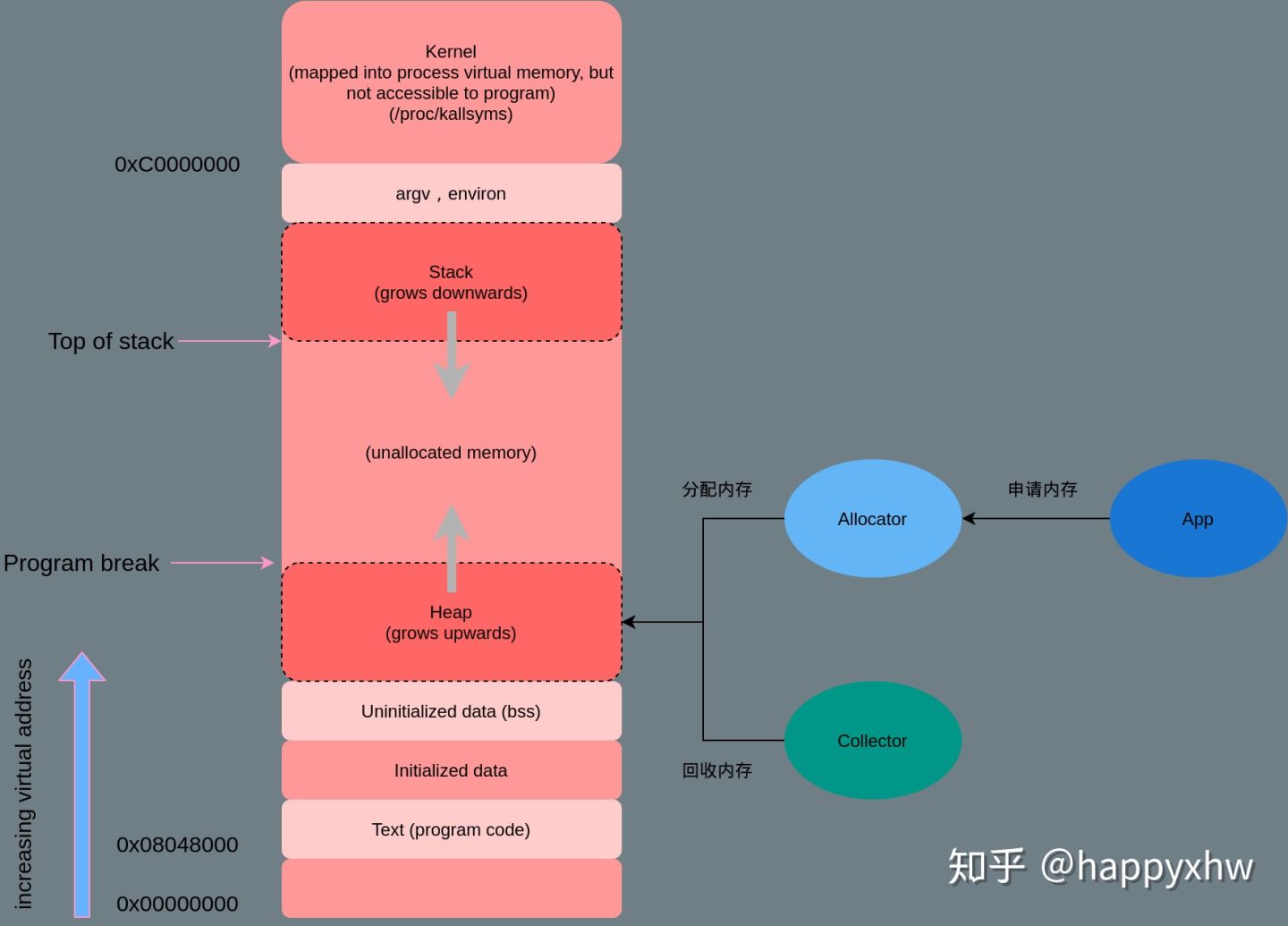
一个优秀的通用内存分配器应具有以下特性:
- 额外的空间损耗尽量少
- 分配速度尽可能快
- 尽量避免内存碎片
- 缓存本地化友好。每个线程有自己的栈,每个线程有自己的堆缓存(减少对全局堆内存管理结构的争用)
- 通用性,兼容性,可移植性,易调试
我们可以将内存管理简单地分成手动管理和自动管理两种方式,手动管理内存一般是指由工程师在需要时通过 malloc 等函数手动申请内存并在不需要时调用 free 等函数释放内存;自动管理内存由编程语言的内存管理系统自动管理,在编程语言的编译期或者运行时中引入,最常见的自动内存管理机制就是垃圾回收,一些编程语言也会使用自动引用计数辅助内存的管理,自动内存管理会带来额外开销并影响语言的运行时性能。
内存管理可以分为三个层次,自底向上分别是:
- 操作系统内核的内存管理
- glibc层使用系统调用维护的内存管理算法。glibc/ptmalloc2,google/tcmalloc,facebook/jemalloc。C 库内存池工作时,会预分配比你申请的字节数更大的空间作为内存池。比如说,当主进程下申请 1 字节的内存时,Ptmalloc2 会预分配 132K 字节的内存(Ptmalloc2 中叫 Main Arena),应用代码再申请内存时,会从这已经申请到的 132KB 中继续分配。当我们释放这 1 字节时,Ptmalloc2 也不会把内存归还给操作系统。
- 应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如netty的arena
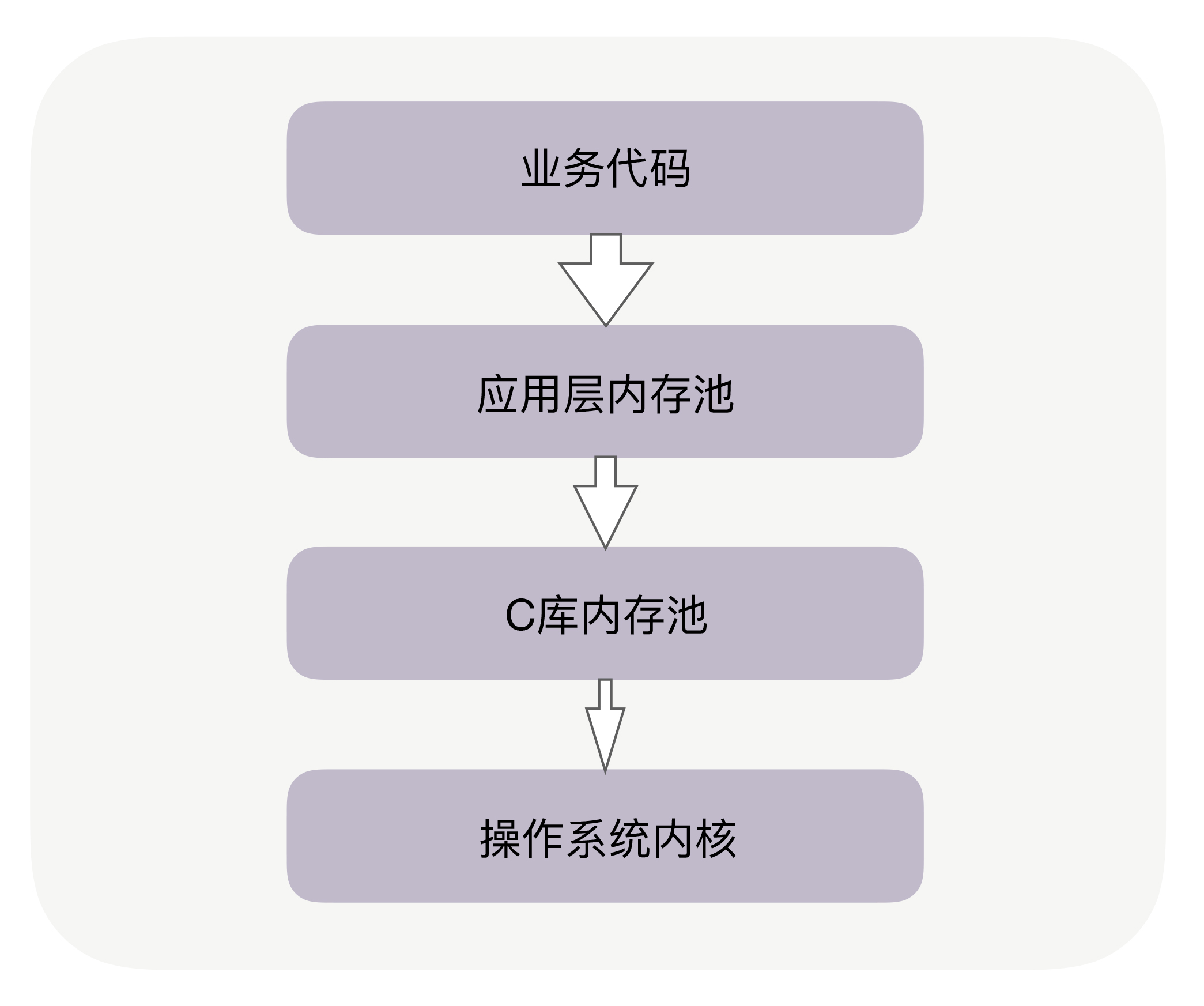
进程/线程与内存:Linux 下的 JVM 编译时默认使用了 Ptmalloc2 内存池,64 位的 Linux 为每个线程的栈分配了 8MB 的内存,还(为每个线程?)预分配了 64MB 的内存作为堆内存池。在多数情况下,这些预分配出来的内存池,可以提升后续内存分配的性能。但也导致创建很多线程时会占用大量内存。
栈空间由编译器 + os管理。如果堆上有足够的空间的满足我们代码的内存申请,内存分配器可以完成内存申请无需内核参与,否则将通过操作系统调用(brk)进行扩展堆,通常是申请一大块内存。(对于 malloc 大默认指的是大于 MMAP_THRESHOLD 个字节 - 128KB)。但是,内存分配器除了更新 brk address 还有其他职责。其中主要的一项就是如何减少 内部(internal)和外部(external)碎片和如何快速分配当前块。我们该如何减少内存碎片化呢 ?答案取决是使用哪种内存分配算法,也就是使用哪个底层库。
操作系统
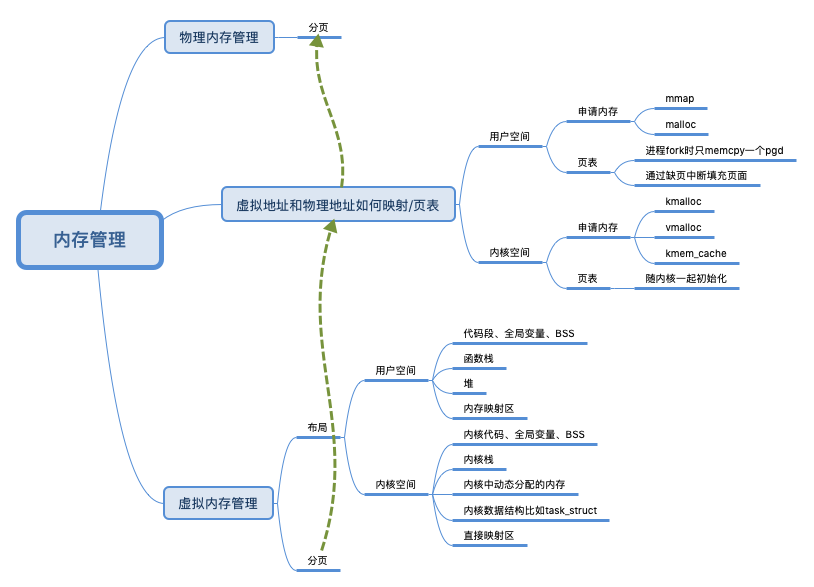
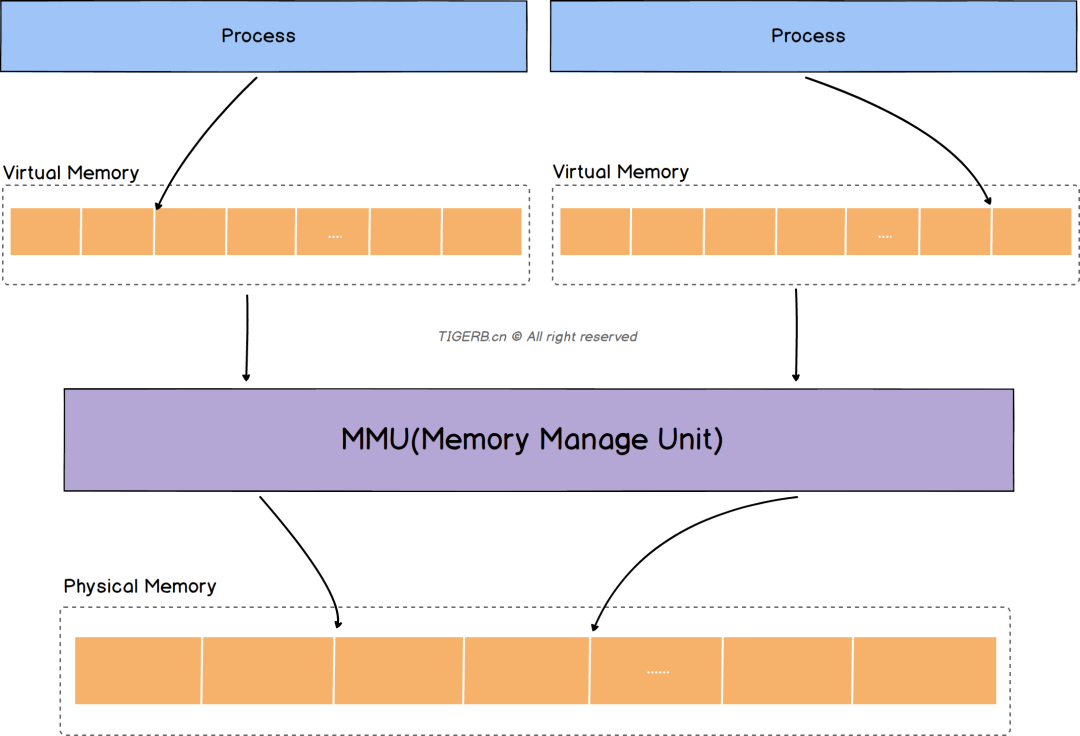
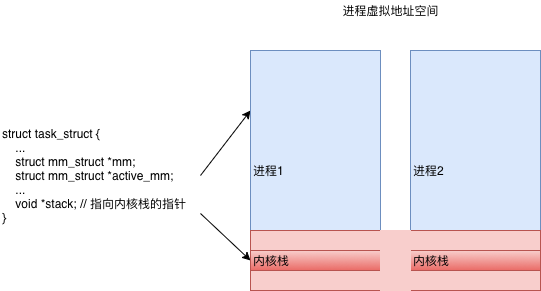
语言/运行时
进程在推进运行的过程中会调用一些数据,可能中间会产生一些数据保留在堆栈段,栈空间 一般在编译时确定(在编译器和操作系统的配合下,栈里的内存可以实现自动管理), 堆空间 运行时动态管理。对于堆具体的说,由runtime 在启动时 向操作 系统申请 一大块内存,然后根据 自定义策略进行分配与回收(手动、自动,分代不分代等),必要时向操作系统申请内存扩容。
从堆还是栈上分配内存?
如果你使用的是静态类型语言,那么,不使用 new 关键字分配的对象大都是在栈中的,通过 new 或者 malloc 关键字分配的对象则是在堆中的。对于动态类型语言,无论是否使用 new 关键字,内存都是从堆中分配的。
为什么从栈中分配内存会更快?由于每个线程都有独立的栈,所以分配内存时不需要加锁保护,而且栈上对象的size在编译阶段就已经写入可执行文件了,执行效率更高!性能至上的 Golang 语言就是按照这个逻辑设计的,即使你用 new 关键字分配了堆内存,但编译器如果认为在栈中分配不影响功能语义时,会自动改为在栈中分配。
当然,在栈中分配内存也有缺点,它有功能上的限制。
- 栈内存生命周期有限,它会随着函数调用结束后自动释放,在堆中分配的内存,并不随着分配时所在函数调用的结束而释放,它的生命周期足够使用。
- 栈的容量有限,如 CentOS 7 中是 8MB 字节,如果你申请的内存超过限制会造成栈溢出错误(比如,递归函数调用很容易造成这种问题),而堆则没有容量限制。
jvm
JVM1——jvm小结极客时间《深入拆解Java虚拟机》垃圾回收的三种方式(免费的其实是最贵的)
- 清除sweep,将死亡对象占据的内存标记为空闲。
- 压缩,将存活的对象聚在一起
- 复制,将内存两等分, 说白了是一个以空间换时间的思路。
go runtime
Visualizing memory management in Golang 有动图建议细读
中间件
netty arena
代码上的体现 以netty arena 为例 netty内存管理
kafka BufferPool
《Apache Kafka源码分析》——Producer与Consumer
redis
内存分配
内存的分配和使用其是一个增加系统中熵的过程,内存分配器只包含线性内存分配器(Sequential Allocator)和空闲链表内存分配器(Free-list Allocator)两种,其它内存分配器其实都是上述两种不同分配器的变种。
- 线性内存分配器。“用到哪了标识到哪”,维护一个指向内存特定位置的指针,当用户程序申请内存时,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置。已分配的内存无法直接回收,需要与拷贝方式的垃圾回收算法配合使用,比如标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等,所以 C 和 C++ 等需要直接对外暴露指针的语言就无法使用该策略。PS:所以就是为什么java 不支持指针。
- 空闲链表内存分配器。维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表。因为分配内存时需要遍历链表,所以它的时间复杂度就是 O(n),为了提高效率,将内存分割成多个链表,每个链表中的内存块大小相同(不同链表不同),申请内存时先找到满足条件的链表,再从链表中选择合适的内存块,减少了需要遍历的内存块数量。
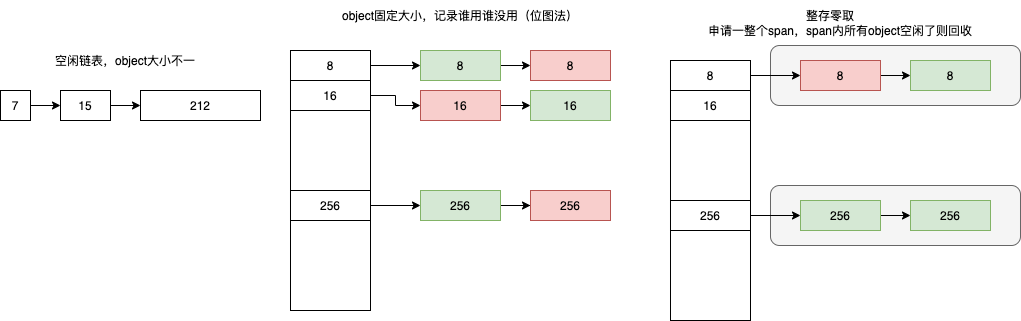
内存回收/gc
int * func(void) {
int num = 1234;
/* ... */
return #
}
在各种流传甚广的 C 语言葵花宝典里,一般都有这么一条神秘的规则,不能返回局部变量。当函数返回后,函数的栈帧(stack frame)就会被销毁,引用了被销毁位置的内存,轻则数据错乱,重则 segmentation fault。依赖人去处理复杂的对象内存管理的问题是不科学、不合理的。C 和 C++ 程序员已经被折磨了数十年,我们不应该再重蹈覆辙了,于是,后来的很多编程语言就用上垃圾回收(GC)机制。
对象头是实现自动内存管理的关键元信息,内存分配器和垃圾收集器都会访问对象头以获取相关的信息。不同的自动内存管理机制会在对象头中存储不同的信息,使用垃圾回收的编程语言会存储标记位 MarkBit/MarkWord,例如:Java 和 Go 语言;使用自动引用计数的会在对象头中存储引用计数 RefCount,例如:Objective-C。编程语言会选择将对象头与对象存储在一起,不过因为对象头的存储可能影响数据访问的局部性,所以有些编程语言可能会单独开辟一片内存空间来存储对象头并通过内存地址建立两者之间的隐式联系。
V8 增量 GC 之三色标记垃圾回收顾名思义,主要是两点:垃圾、回收。
- 什么是垃圾?如何找到垃圾?何时找垃圾?
- 垃圾已经没用的内存区域
- 找垃圾: STW vs 增量。找垃圾就是一种图的遍历,从 Root 出发,对所有能访问的节点进行标记,访问不到的就是垃圾。
- 什么是回收?怎么回收?何时回收?
- 怎么回收? Sweep 和 Compact。串行回收(单gc线程)、并行回收(多gc线程)、并发回收
- 回收的时机也都是找完了就操作
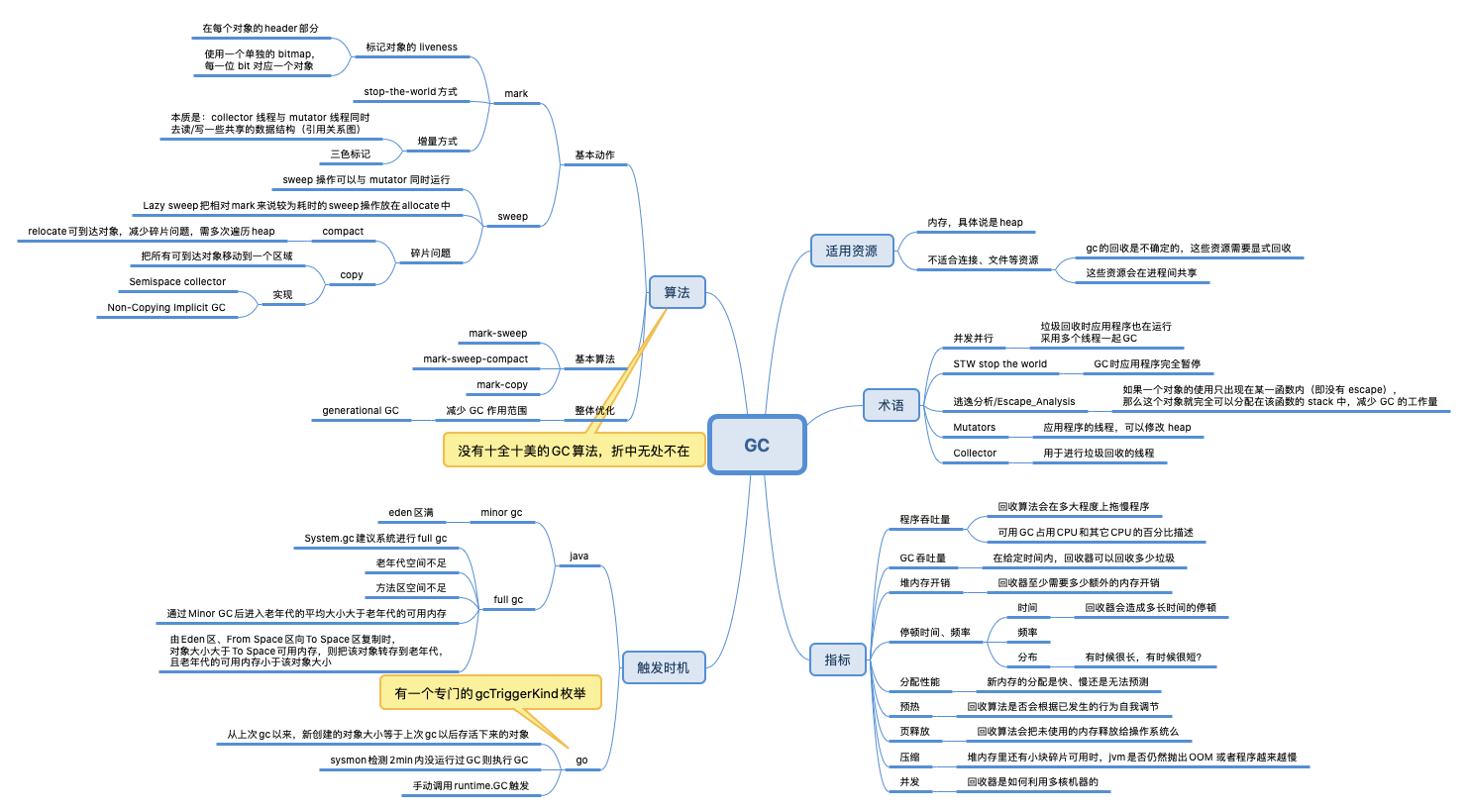
gc 策略
- 基于引用计数的垃圾收集器是直接垃圾收集器,当我们改变对象之间的引用关系时会修改对象之间的引用计数,每个对象的引用计数都记录了当前有多少个对象指向了该对象,当对象的引用计数归零时,当前对象就会被自动释放。基于引用计数的垃圾收集是在用户程序运行期间实时发生的,所以在理论上也就不存在 STW 或者明显地垃圾回收暂停。缺点是递归的对象回收(一个对象引用计数归0 ==> 回收 ==> 其引用的对象都归0并回收)和循环引用。引用计数垃圾收集器是一种非移动(Non-moving)的垃圾回收策略,它在回收内存的过程中不会移动已有的对象,很多编程语言都会对工程师直接暴露内存的指针,所以 C、C++ 以及 Objective-C 等编程语言其实都可以使用引用计数来解决内存管理的问题。
- 标记清除。分代算法中一般用于老年代
- 一般需要在对象头中加入表示对象存活的标记位(Mark Bit),也可以 使用位图(Bitmap)标记
- 一般会使用基于空闲链表的分配器,因为对象在不被使用时会被就地回收,所以长时间运行的程序会出现很多内存碎片
- 标记压缩。会把活跃的对象重新整理,从头开始排列,减少内存碎片。一种 moving 收集器,如果编程语言支持使用指针访问对象,那么我们就无法使用该算法。
- 标记复制
高级策略
- 分代垃圾收集。也是一种 moving 收集器
- 基于弱分代假设(Weak Generational Hypothesis)上 —— 大多数的对象会在生成后马上变成垃圾
- 常见的分代垃圾回收会将堆分成青年代(Young、Eden)和老年代(Old、Tenured)。为了处理分代垃圾回收的跨代引用,我们需要解决两个问题,分别是如何识别堆中的跨代引用以及如何存储识别的跨代引用,在通常情况下我们会使用写屏障(Write Barrier)识别跨代引用并使用卡表(Card Table)存储相关的数据。
- 卡表与位图比较相似,它也由一系列的比特位组成,其中每一个比特位都对应着老年区中的一块内存,如果该内存中的对象存在指向青年代对象的指针,那么这块内存在卡表中就会被标记,当触发 Minor GC 循环时,除了从根对象遍历青年代堆之外,我们还会从卡表标记区域内的全部老年代对象开始遍历青年代。
- 增量并发收集器。今天的计算机往往都是多核的处理器,有条件在用户程序执行时并发标记和清除垃圾
- 需要使用屏障技术保证垃圾收集的正确性;与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别
- 增量式的垃圾收集需要与三色标记法一起使用,为了保证垃圾收集的正确性,我们需要在垃圾收集开始前打开写屏障,这样用户程序对内存的修改都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。
- 用户程序可能在标记执行的过程中修改对象的指针(改变引用关系),所以三色标记清除算法本身是不可以并发或者增量执行的,它仍然需要 STW。想要并发或者增量地标记对象还是需要使用屏障技术。
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前的多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证代码对内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作。垃圾收集中的屏障技术更像是一个钩子方法,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,根据操作类型的不同,我们可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。写屏障是当对象之间的指针发生改变时调用的代码片段。PS:内存屏障保障指令有序执行 ==> 编译器针对类似*slot = ptr代码A 插入内存屏障及代码片段B ==> 可以保证代码片段B 在A 之前执行。
最基本的 mark-and-sweep 算法伪代码
mutator 通过 new 函数来申请内存
new():
ref = allocate()
if ref == null
collect()
ref = allocate()
if ref == null
error "Out of memory"
return ref
collect 分为mark 和 sweep 两个基本步骤
atomic collect(): // 这里 atomic 表明 gc 是原子性的,mutator 需要暂停
markFromRoots()
sweep(heapStart, heapEnd)
从roots 对象开始mark
markFromRoots():
initialize(worklist)
for each reference in Roots // Roots 表示所有根对象,比如全局对象,stack 中的对象
if ref != null && !isMarked(reference)
setMarked(reference)
add(worklist, reference)
mark() // mark 也可以放在循环外面
initialize():
// 对于单线程的collector 来说,可以用队列实现 worklist
worklist = emptyQueue()
//如果 worklist 是队列,那么 mark 采用的是 BFS(广度优先搜索)方式来遍历引用树
mark():
while !isEmpty(worklist):
ref = remove(worklist) // 从 worklist 中取出第一个元素
for each field in Pointers(ref) // Pointers(obj) 返回一个object的所有属性,可能是数据,对象,指向其他对象的指针
child = *field
if child != null && !isMarked(child)
setMarked(child)
add(worklist, child)
sweep逻辑
sweep(start, end):
scan = start
while scan < end
if isMarked(scan)
unsetMarked(scan)
else
free(scan)
scan = nextObject(scan)