前言
许式伟:存储系统需要花费绝大部分精力在各种异常情况的处理上,甚至你应该认为,这些庞杂的、多样的错误分支处理,才是存储系统的 “正常业务逻辑”。
- 单机时代的文件系统,机器断电、程序故障、系统重启等常规的异常,文件系统必须可以正确地应对,甚至对于磁盘扇区损坏,文件系统也需要考虑尽量将损失降到最低。
- 到了互联网时代,有了 C/S 或 B/S 结构,存储系统又有了新指标:可用性。
- 什么样的数据会有最大的存储规模?非结构化数据。这类数据的组织形式通常以用户体验友好为目标,而不是机器友好为目标。所以数据本身也自然不是以机器易于理解的结构化形式来组织。图片、音视频、Office 文档等多媒体文件,就是比较典型的非结构化数据。
- 非结构化数据的存储方式,最理想的绝对不是分布式文件系统。文件系统只是桌面操作系统为了方便用户手工管理数据而设计的产物。服务端操作系统发展的初期,人们简单沿用了桌面操作系统的整套体系框架。非结构化数据最佳的存储方式,还是键值存储(KV Storage)。用于存储非结构化数据的键值存储,有一个特殊的名字,叫对象存储(Object Storage)。对象存储的出现,是服务端体系架构和桌面操作系统分道扬镳的开始。
-
既然对象存储是一个键值存储,就意味着我们可以通过对 Key 做 Hash,或者对 Key 按 Key Range 做分区,都能够让请求快速定位到特定某一台存储机器上,从而转化为单机问题。这也是为什么在数据库之后,会冒出来那么多 NoSQL 数据库。NoSQL 数据库的名字其实并不恰当,它们更多的不是去 SQL,而是去关系(我们知道数据库更完整的称呼是关系型数据库)。有关系意味着有多个索引,也就是有多个 Key,而这对数据库转为分布式存储系统来说非常不利。
// 对象存储 AWS S3 访问接口 func PutObject(bucket, key string, object io.Reader) (err error) func GetObject(bucket, key string) (object io.ReadCloser, err error)
当我一开始学习mysql 的实现,我跟着mysql 脉络去学习一个db 如何实现,学习tidb 时也是。然后再回头看, 发现两者很多问题是类似的,知识在这个时候开始分层了。再去看mysql 的博客,你会发现内容是混杂的,一方面是 实现一个db的通用思想、机制, 一方面是msyql的实现细节。当学习了多个数据库实现之后,通用思想、机制提炼出来, mysql/tidb 专属细节整理一下,上帝的归上帝、凯撒的归凯撒。
对象存储
对象存储:常见的操作都是通过PUT实现上传和GET 实现下载等;它的表现形式,你可以认为后端存储空间无限大,你只需要使用PUT、GET方式实现上传下载即可,无需关心后端存储 ;可扩展性强,使用简单,但上传的文件,无法在对象存储中对其进行修改编辑,如果有需要,下载到本地,然后再上传,无法为服务器提供块级别的存储;产品举例,百度网盘,HDFS、FastDFS、swift、公有云的:ASW S3,腾讯云的COS,阿里云的OSS等;
关于一致性
存储大势的发展:ACID’s Consistency vs. CAP’s Consistency
一开始数据库都是单机的,实现ACID 的特性相对简单,然后数据量开始变大,在分布式场景下可用性盖过了一致性(所谓的CAP,大部分最终选择了牺牲了部分一致性),此时一致性由上游根据业务需要来取舍。 但是ACID 的需求只是被转移却从未消失过,Avoiding lost updates, dirty reads, stale reads and enforcing app-specific integrity constraints are critical concerns for app developers,Solving these concerns directly at the database layer using the consistency provided by ACID transactions is a much simpler approach.
A Primer on ACID Transactions: The Basics Every Cloud App Developer Must Know
Consistency in CAP is a more fundamental concept — it refers to the guarantee that all members of a distributed system have a shared understanding of the value of a single data element from a read standpoint.
On the other hand, ACID’s consistency refers to data integrity guarantees that ensure the transition of the entire database from one valid state to another. Such a transition involves strict enforcement of integrity constraints such as data type adherence, null checks, relationships and more. Given that a single ACID transaction can touch multiple data elements where as CAP’s consistency refers to a single data element, ACID transactions are a stronger guarantee than CAP’s consistency.
What’s Needed For Implementing ACID?
- Provisional Updates (Atomicity). Transactions involve multiple operations across multiple rows. needs a mechanism to track the start, progress and end of every transaction along with the ability to make provisional updates across multiple nodes in some temporary space. Conflict detection, rollbacks, commits and space cleanups are also needed. Using Two-phase commit (2PC) protocol or one of its variations is the most common way to achieve atomicity. Achieving Atomicity
- Strongly Consistent Core (Consistency) 单机时不成问题,分布式场景下,因为副本问题,The transaction manager will rely on the correctness of a single operation on a single row to enforce the broader ACID-level consistency of multiple operations over multiple rows. Achieving Consistency
- Transaction Ordering (Isolation), For a database to support the strictest serializable isolation level, a mechanism such as globally ordered timestamps is needed to sequentially arrange all the transactions. 必须为事务界定一个顺序 Achieving Isolation
- Persistent Storage (Durability) Achieving Durability
上述的各种机制 在mysql、postgresql、tidb 中都有体现,实现一个机制有多种策略,有些策略只能单机用,有些策略可以推广到分布式上。分布式可以有coordinator ,也可以消灭coordinator, 通过不断地 探察本质,逐步逼近实现一个分布式ACID 的原子能力是什么?
列式存储
当一行数据有 100 个字段,而我们的分析程序只需要其中 5 个字段的时候,就很尴尬了。因为如果我们顺序解析读取数据,我们就要白白多读 20 倍的数据。那么,能不能跳着只读我们需要的字段呢?当然也是不行的,因为对于硬盘来说,顺序读远远要优于随机读。
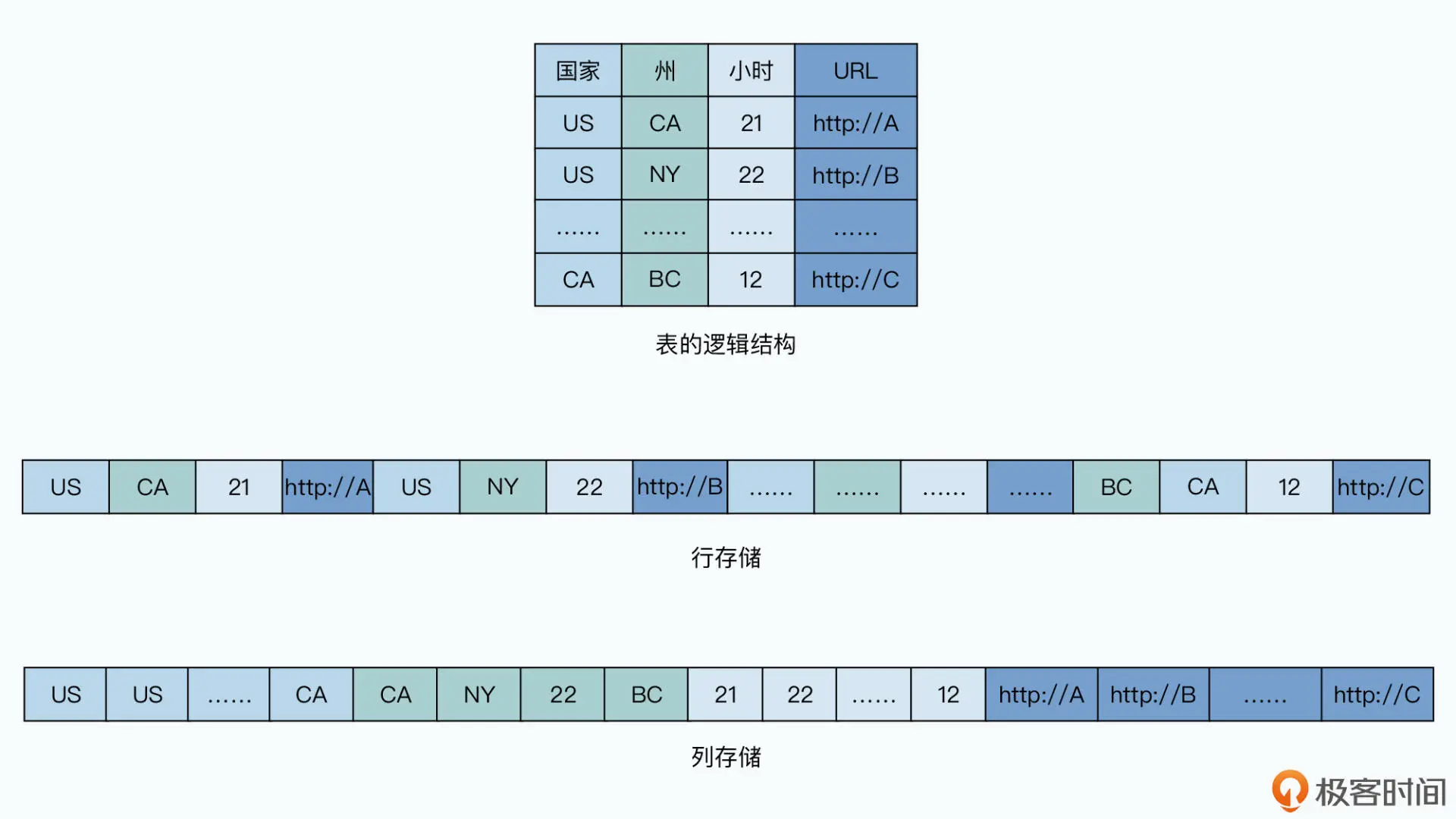
不过,这样存储之后,数据写入就变得有些麻烦了。原先我们只需要顺序追加写入数据,而现在我们需要向很多个文件去追加写入数据,那有没有什么好办法呢?对于追加写入的数据,我们可以先写 WAL 日志,然后再把数据更新到内存中,接着再从内存里面,定期导出按列存储的文件到硬盘上。事实上,在一个分布式的环境里,我们的数据其实并不能称之为 100% 的列存储。因为我们在分析数据的时候,可能需要多个列的组合筛选条件。所以,更合理的解决方案是行列混合存储。在单个服务器上,数据是列存储的,但是在全局,数据又根据行进行分区,分配到了不同的服务器节点上。