简介
整体结构
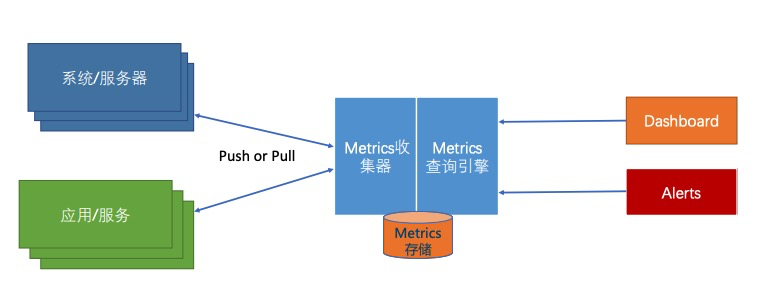
Prometheus is an open-source systems monitoring and alerting toolkit. 数据采集、简单计算、存储、展示、报警都支持,部分能力可以使用其他组件替代,比如存储,Prometheus本来支持存储在磁盘,也可以通过adapter将数据存在influxdb,进而就可以复用influxdb的一系列能力。
Prometheus is a monitoring platform that collects metrics from monitored targets by scraping metrics HTTP endpoints on these targets. prometheus 通过被抓取对象 暴露出的http 端口抓取metrics,可以看作是一个按配置拉取特定url的“爬虫”
Prometheus官网Prometheus官方文档Prometheus 是由SoundCloud 开发的开源监控报警系统和时序数据库(TSDB),由Golang编写。
由于数据采集可能会有丢失,所以 Prometheus 不适用于对采集数据要 100% 准确的情形,例如实时监控
配置文件
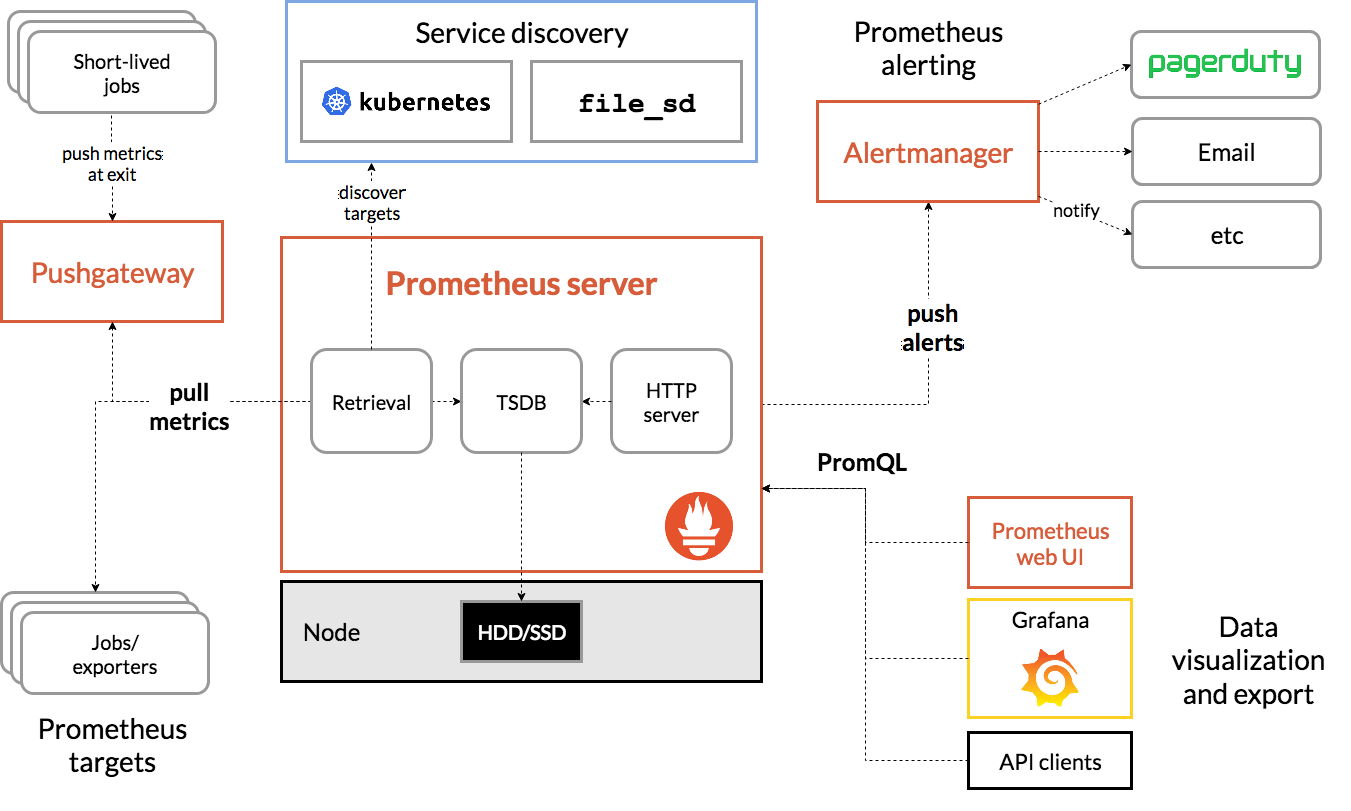
Prometheus is configured via command-line flags and a configuration file. While the command-line flags configure immutable system parameters (such as storage locations, amount of data to keep on disk and in memory, etc.), the configuration file defines everything related to scraping jobs and their instances, as well as which rule files to load.
从配置文件来看 prometheus
$ cat /usr/local/prometheus/prometheus.yml
# 全局配置
global:
scrape_interval: 15s # 默认抓取间隔, 15秒向目标抓取一次数据。
evaluation_interval: 15s # 执行rules的频率
alerting:
alertmanagers: ## 配置alertmanager的地址
rule_files:
# - "first.rules"
# - "second.rules"
# controls what resources Prometheus monitors.
scrape_configs:
# 这里是抓取promethues自身的配置
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
# 重写了全局抓取间隔时间,由15秒重写成5秒。
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'mysql'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9104','localhost:9105']
relabel_configs vs metric_relabel_configsrelabel_config 作用于scrape 之前,metric_relabel_configs 作用域scrape 之后保存之前。
- relabel_configs, Prometheus needs to know what to scrape, and that’s where service discovery and relabel_configs come in. Relabel configs allow you to select which targets you want scraped, and what the target labels will be. So if you want to say scrape this type of machine but not that one, use relabel_configs.
- metric_relabel_configs, metric_relabel_configs by contrast are applied after the scrape has happened, but before the data is ingested by the storage system. So if there are some expensive metrics you want to drop, or labels coming from the scrape itself (e.g. from the /metrics page) that you want to manipulate that’s where metric_relabel_configs applies.
启动prometheus prometheus --config.file=prometheus.yml
Reloading Prometheus’ Configuration类似于nginx 运行时reload 配置文件一样nignx -c nginx.conf -s reload, prometheus 也支持运行时reload
- 给Prometheus 进程发送SIGHUP信号
kill -HUP $Prometheus_Pid - 在Prometheus 启动时携带command line flag
--web.enable-lifecycle的前提下,调用http reload 接口,curl -X POST http://ip:9090/-/reload
整体流程
- 从配置文件加载采集配置
- 通过服务发现探测有哪些需要抓取的对象
- 周期性得往抓取对象发起抓取请求,得到数据
- 将数据写入本地盘或者写往远端存储
具体的说:服务发现 ==> targets ==> relabel ==> 抓取 ==> metrics_relabel ==> 缓存 ==> 2小时落盘。Prometheus Relabeling 重新标记的使用
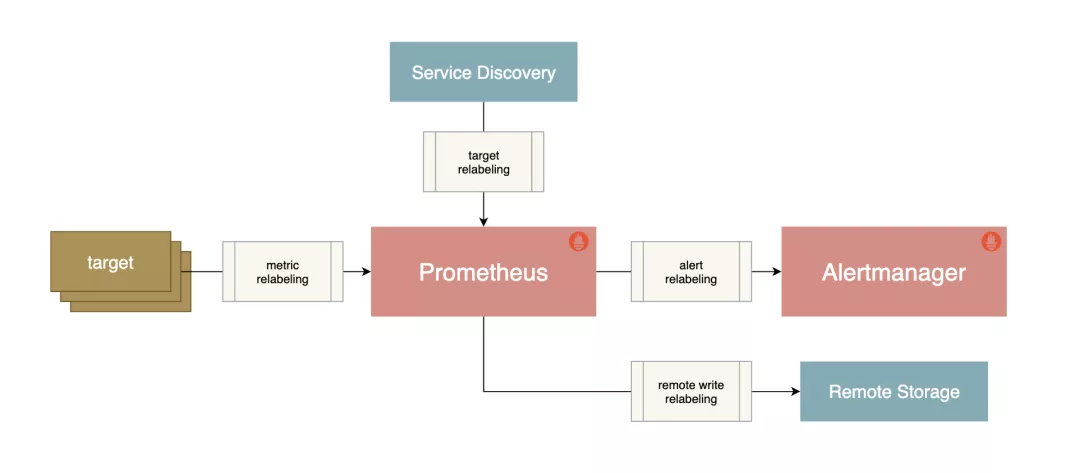
prometheus 服务发现
在基于云(IaaS或者CaaS)的基础设施环境中用户可以像使用水、电一样按需使用各种资源(计算、网络、存储)。按需使用就意味着资源的动态性,这些资源可以随着需求规模的变化而变化。这种按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服务)都在动态的变化。对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标即可, 这种模式被称为服务发现。
服务发现方式
-
基于文件,通过任意的方式将监控Target的信息写入文件,Prometheus会定时从文件中读取最新的Target信息
global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 15s scrape_configs: - job_name: 'file_ds' file_sd_configs: - files: - targets.json - 基于DNS
-
基于consul
- job_name: node_exporter metrics_path: /metrics scheme: http consul_sd_configs: - server: localhost:8500 services: - node_exporter在consul_sd_configs定义当中通过server定义了Consul服务的访问地址,services则定义了当前需要发现哪些类型服务实例的信息,这里限定了只获取node_exporter的服务实例信息。
- 平台提供的api,比如Kubernetes.
```yaml
- job_name: ‘kubernetes-cadvisor’
kubernetes_sd_configs:
- api_server: ‘http://localhost:8080’; role: node/service/ingress/pod/endpoints tls_config: ca_file: xx bearer_token_file: xx ```
- job_name: ‘kubernetes-cadvisor’
kubernetes_sd_configs:
data model
Prometheus 采用多维时间序列数据模型。这个时间序列数据模型结合了时间序列名称和称为标签(label)的键/值对,这些标签提供了维度(为特定时间序列添加上下文)。每个时间序列由名称和标签的组合唯一标识(从技术上讲,名称本身也是名为__name__的标签)。时间序列的真实值是采样(sample)的结果,它包括两部分:一个float 64类型的数值;一个毫秒精度的时间戳。
Prometheus fundamentally stores all data as time series: streams of timestamped values belonging to the same metric and the same set of labeled dimensions. time series 最直观的数据格式是(t0,v0),(t1,v1),(t2,v2)... 一个time series 属于一个metric + labels。 我们日常看到的格式是(metric name, label.., value) ,因为 数据产生的时候是没有时间的,等prometheus 抓取落盘后 会有一个抓取的时间。
我们访问 http://ip:9090/metrics 来看一次实际的数据scrape返回结果
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 1.3428e-05
go_gc_duration_seconds{quantile="0.25"} 3.5274e-05
go_gc_duration_seconds{quantile="0.5"} 5.292e-05
go_gc_duration_seconds{quantile="0.75"} 6.7349e-05
go_gc_duration_seconds{quantile="1"} 0.000192367
go_gc_duration_seconds_sum 0.00562896
go_gc_duration_seconds_count 101
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 175
# HELP prometheus_sd_discovered_targets Current number of discovered targets.
# TYPE prometheus_sd_discovered_targets gauge
prometheus_sd_discovered_targets{config="6577653216d30e75870c4b843dfbafd6",name="notify"} 1
prometheus_sd_discovered_targets{config="cadvisor",name="scrape"} 16
以prometheus_sd_discovered_targets{config="6577653216d30e75870c4b843dfbafd6",name="notify"} 1(称之为sample) 为例
- prometheus_sd_discovered_targets 叫metric name
config="6577653216d30e75870c4b843dfbafd6"属于<label name>=<label value>从上述例子看,label 可以没有- 最后的数值是一个 float64 value
Prometheus Server 对http://ip:9090/metrics 返回的数据 不是直接原样存储
-
标签共有两大类:插桩标签(instrumentation label)和目标标签(target label),插桩标签来自被 监控的资源,目标标签由Prometheus在抓取期间和之后添加。When Prometheus scrapes a target, it attaches some labels automatically to the scraped time series which serve to identify the scraped target:
- job: The configured job name that the target belongs to.
- instance: The
<host>:<port>part of the target’s URL that was scraped.
-
自动生成几个 sample 来描述此次scrape,比如
# if the instance is healthy, i.e. reachable, or 0 if the scrape failed. 可以用来监控instance 是否可用 up{job="<job-name>", instance="<instance-id>"}: 1 # duration of the scrape. scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}: xx
带有__前缀的标签名称保留给Prometheus内部使用
其它
后台ui
Prometheus服务器还提供了一套内置查询语言PromQL、一个表达式浏览器以及 一个用于浏览服务器上数据的图形界面。
假设prometheus 运行在localhost:9090,则访问localhost:9090 可以直接打开其后台ui
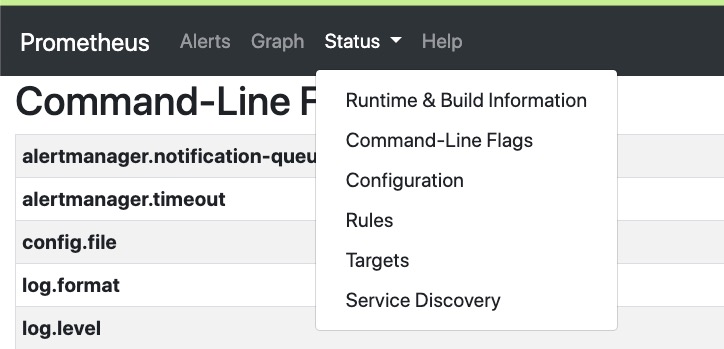
后台ui包括几个菜单,localhost:9090 加上菜单名 即可直接打开 对应菜单,比如 localhost:9090/alerts 即可打开 Alerts菜单
- Alerts 当前的报警配置 及报警状态
- Graph 对prometheus 抓取的数据进行查询
- Status 有几个子菜单
- Runtime & Build Information 当前prometheus 进程的构建和运行时信息
- Command-Line Flags 启动当前prometheus 进程时的命令行参数
- Configuration 启动当前prometheus 进程时的配置
- Rules, Prometheus uses rules to create new time series and to generate alerts.
- Targets 可以看到当前Prometheus 抓取的Target的状态,以UP 和 Down区分
- Service Discovery 基本对应 配置文件中的 job_name
PromQL/Prometheus expression language
QUERYING PROMETHEUS提供了 对时间序列数据的丰富的查询、聚合以及逻辑运行能力。即便一个表达语言,那也是麻雀虽小五脏俱全,字面量、运算符、语法规则、函数等都有,虽然没有编程语言全面,但也像SQL一样很完备了
http_requests_total{code="200",handler="/api/v1/label/:name/values",instance="0.0.0.0:9099",job="prometheus"} 802
http_requests_total{code="200",handler="/api/v1/query",instance="0.0.0.0:9099",job="prometheus"} 188683
http_requests_total{code="200",handler="/api/v1/query_range",instance="0.0.0.0:9099",job="prometheus"} 121281
http_requests_total{code="200",handler="/api/v1/series",instance="0.0.0.0:9099",job="prometheus"} 12512
http_requests_total{code="200",handler="/config",instance="0.0.0.0:9099",job="prometheus"} 1
http_requests_total{code="200",handler="/flags",instance="0.0.0.0:9099",job="prometheus"} 2
http_requests_total{code="200",handler="/graph",instance="0.0.0.0:9099",job="prometheus"} 11
http_requests_total{code="200",handler="/metrics",instance="0.0.0.0:9099",job="prometheus"} 17605
http_requests_total{code="200",handler="/rules",instance="0.0.0.0:9099",job="prometheus"}
Time series Selectors 从time series 中选择需要的数据
在 Prometheus 的表达语言中,一个表达式或子表达式可以计算为以下四种类型之一:
- 瞬时向量(Instant vector):一组时间序列,每个时间序列包含一个样本,所有样本共享相同的时间戳。基于metric name 、label 做选择,以下3个实例
## 根据metric name 选择 http_requests_total ## 根据metric name + label 选择 http_requests_total{job="prometheus",group="canary"} ## label 支持多个运算符 http_requests_total{environment=~"staging|testing|development",method!="GET"} - 范围向量(Range vector):一组时间序列,其中包含每个时间序列随时间变化的一系列数据点。
# 使用[]指定一个range duration http_requests_total{job="prometheus"}[5m] - 标量(Scalar):一个简单的数字浮点值。
- 字符串(String):一个简单的字符串值,目前未使用。
对metric 的操作
- OPERATORS 是正经的官方文档,各种操作说明都有
- Prometheus语法初探相同label 值的两个 瞬时向量 之间 可以进行加减乘除,如果两个metric label 有差异,可以使用 ignoring 或 on。如果 算术运算的两个metric 数量不同,可以使用 group_left/group_right,指定结果集个数 以左右哪个metric 为准。
method_code:http_errors:rate5m{method="get", code="500"} 24 method_code:http_errors:rate5m{method="get", code="404"} 30 method_code:http_errors:rate5m{method="put", code="501"} 3 method_code:http_errors:rate5m{method="post", code="500"} 6 method_code:http_errors:rate5m{method="post", code="404"} 21 method:http_requests:rate5m{method="get"} 600 method:http_requests:rate5m{method="del"} 34 method:http_requests:rate5m{method="post"} 120 # Example query method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m # Result {method="get"} 0.04 // 24 / 600 {method="post"} 0.05 // 6 / 120 - 相同label 值的两个 瞬时向量 之间 可以进行集合运算 and/or/unless。 分别返回 vector1 and vector2 的交集/或集/差集等。
- 函数 分为用于瞬时向量的函数 和用于 区间向量的函数
- 小技巧,很多时候两个 metric 完全不同,只有一两个label 相同,此时可以使用 on 对两个metric 进行运算,也可以 使用
max(xx) by(label)将向量转换为一个新向量。
rules
Prometheus uses rules to create new time series and to generate alerts. rule 分为两种类型:RecordingRule 和 AlertingRule
Recording rules allow you to precompute frequently needed or computationally expensive expressions and save their result as a new set of time series. Querying the precomputed result will then often be much faster than executing the original expression every time it is needed. This is especially useful for dashboards, which need to query the same expression repeatedly every time they refresh. dashboard每次query,一下子计算上千条time series 肯定会很耗时,因此可以预置一些规则,比如每5分钟汇总一次,即可大大减少计算最终结果时的数据量。
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg(irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
记录规则命名的推荐格式level:metric:operations
- level 表示聚合级别,以及规则的输出标签
- metric 是指标名称
- operations 应用于指标的操作列表