简介
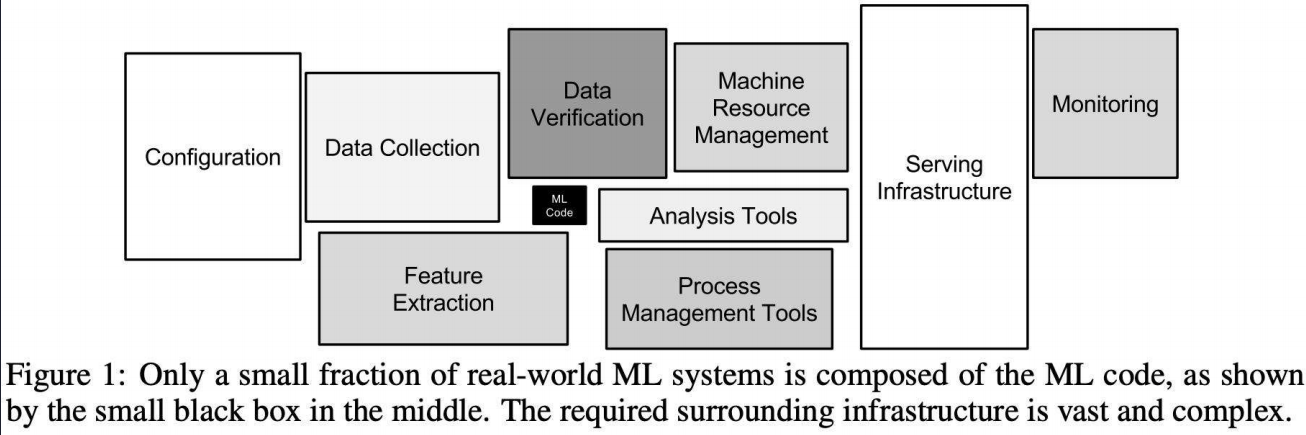
《人工智能云平台原理、设计与应用》近年来涌现了很多智能算法,这些算法需要软件的支撑,没有软件的支撑,理论很难与应用相结合,新硬件也很难为应用提速,所以巨头们推出了TensorFlow、Pytorch等开源框架,然而这些框架不足以支撑人工智能全流程生产化应用,它们仅面向个人开发者和研究人员,管理少数计算设备资源,无法在云计算资源上提供面向多租户的智能应用全流程服务。欠缺诸如海量样本数据管理与共享存储、集群管理、任务调度、快速训练与部署、运行时监控等能力,缺乏人工智能生产流程的抽象、定义和规范,导致用户形成生产力的成本过高。
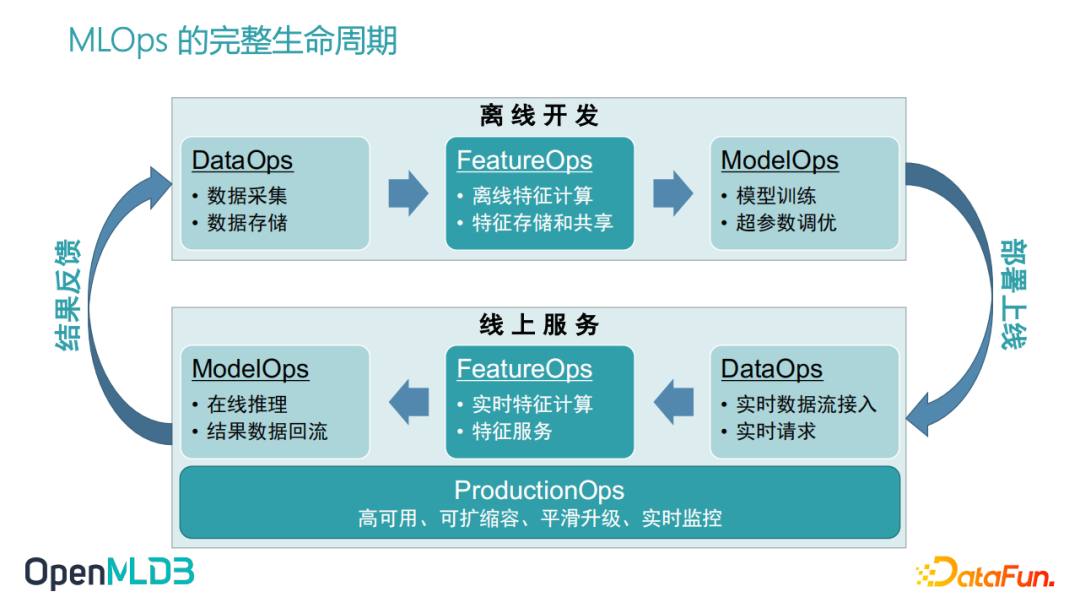
海量数据标注 + 大规模计算 + 工程化(python或c++)=AI系统,也被称为MLaaS/MLOps。
AI 平台可能是云原生技术栈上最具”可玩性”的一种场景。种类繁多的异构资源和通讯形式、调度策略、常规业务不需要的拓扑感知、花式任务编排、数据密集型有状态应用、天然离/在线混部。
虎牙
手动时代
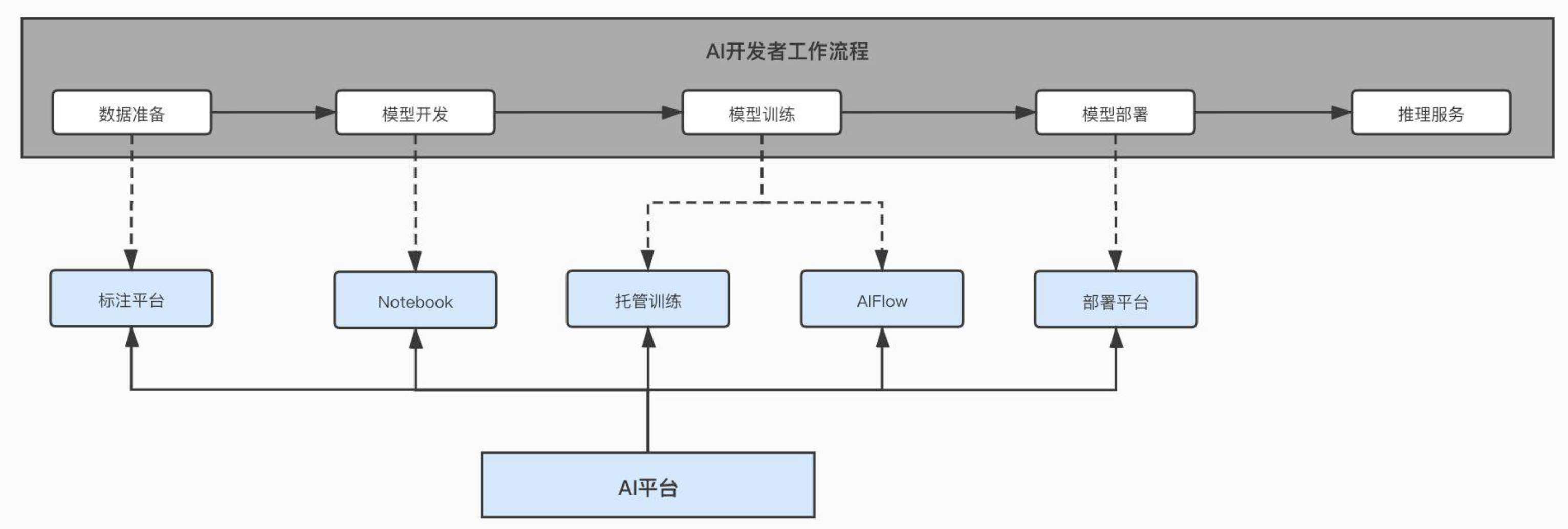
AI平台的定位:面向算法工程师,围绕AI 模型的全生命周期去提供一个一站式的机器学习服务平台。
腾讯
高性能深度学习平台建设与解决业务问题实践构建公司统一的大规模算力,方便好用的提供GPU

阿里
KubeDL 加入 CNCF Sandbox,加速 AI 产业云原生化
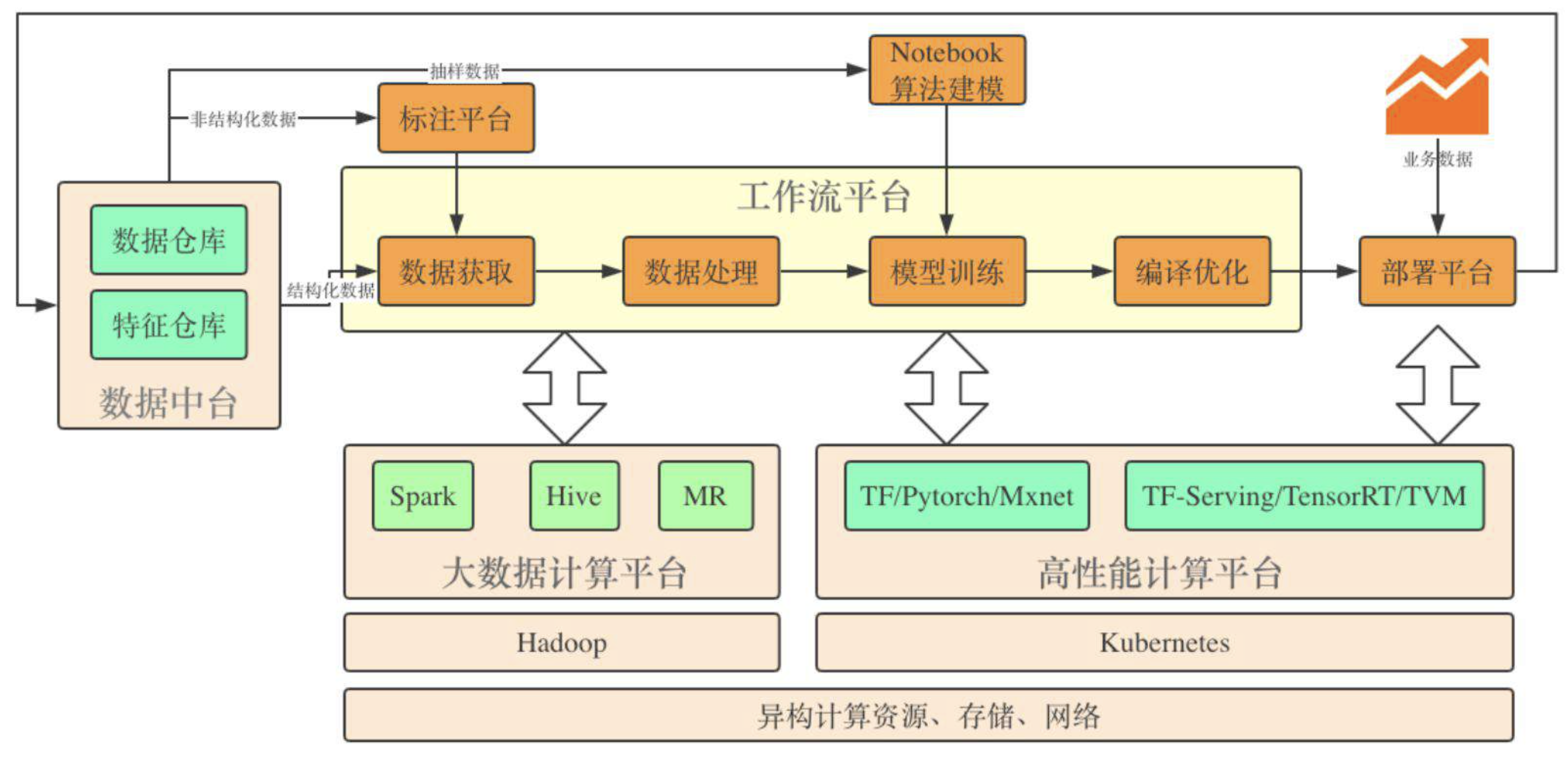
从算法工程师着手设计第一层神经网络结构,到最终上线服务于真实的应用场景,除 AI 算法的研发外还需要大量基础架构层面的系统支持,包括数据收集和清理、分布式训练引擎、资源调度与编排、模型管理,推理服务调优,可观测等。众多系统组件的协同组成了完整的机器学习流水线。
具体的说
- 数据抽取组件->实现样本数据筛选
- 画像组件->实现样本数据与画像字段的关联
- 特征组件->实现画像数据到特征数据格式的转换
- 切分组件->实现样本抽样
- 深度组件->实现用户自定义模型训练
- 预测组件->验证模型指标
- 部署组件->模型部署上线
- 串联上述所有组件的工作流组件,以支持算法工程师 模型训练部署的整个过程。PS: 具体实现上设计到 自己实现或使用工作流引擎。 自动化能自动的,加速能加速的,减少模型耗时,加快算法工程师的产出效率,并以此为前提提高资源利用率。
摆脱 AI 生产“小作坊”:如何基于 Kubernetes 构建云原生 AI 平台在初期,用户利用 Kubernetes,Kubeflow,nvidia-docker 可以快速搭建 GPU 集群,以标准接口访问存储服务,自动实现 AI 作业调度和 GPU 资源分配,训练好的模型可以部署在集群中,这样基本实现了 AI 开发和生产流程。紧接着,用户对生产效率有了更高要求,也遇到更多问题。比如 GPU 利用率低,分布式训练扩展性差,作业无法弹性伸缩,训练数据访问慢,缺少数据集、模型和任务管理,无法方便获取实时日志、监控、可视化,模型发布缺乏质量和性能验证,上线后缺少服务化运维和治理手段,Kubernetes 和容器使用门槛高,用户体验不符合数据科学家的使用习惯,团队协作和共享困难,经常出现资源争抢,甚至数据安全问题等等。从根本上解决这些问题,AI 生产环境必然要从“单打独斗的小作坊”模式,向“资源池化+AI 工程平台化+多角色协作”模式升级。我们将云原生 AI 领域聚焦在两个核心场景:持续优化异构资源效率,和高效运行 AI 等异构工作负载。
- 优化异构资源效率
- 运行 AI 等异构工作负载,兼容 Tensorflow,Pytorch,Horovod,ONNX,Spark,Flink 等主流或者用户自有的各种计算引擎和运行时,统一运行各类异构工作负载流程,统一管理作业生命周期,统一调度任务工作流,保证任务规模和性能。一方面不断提升运行任务的性价比,另一方面持续改善开发运维体验和工程效率。
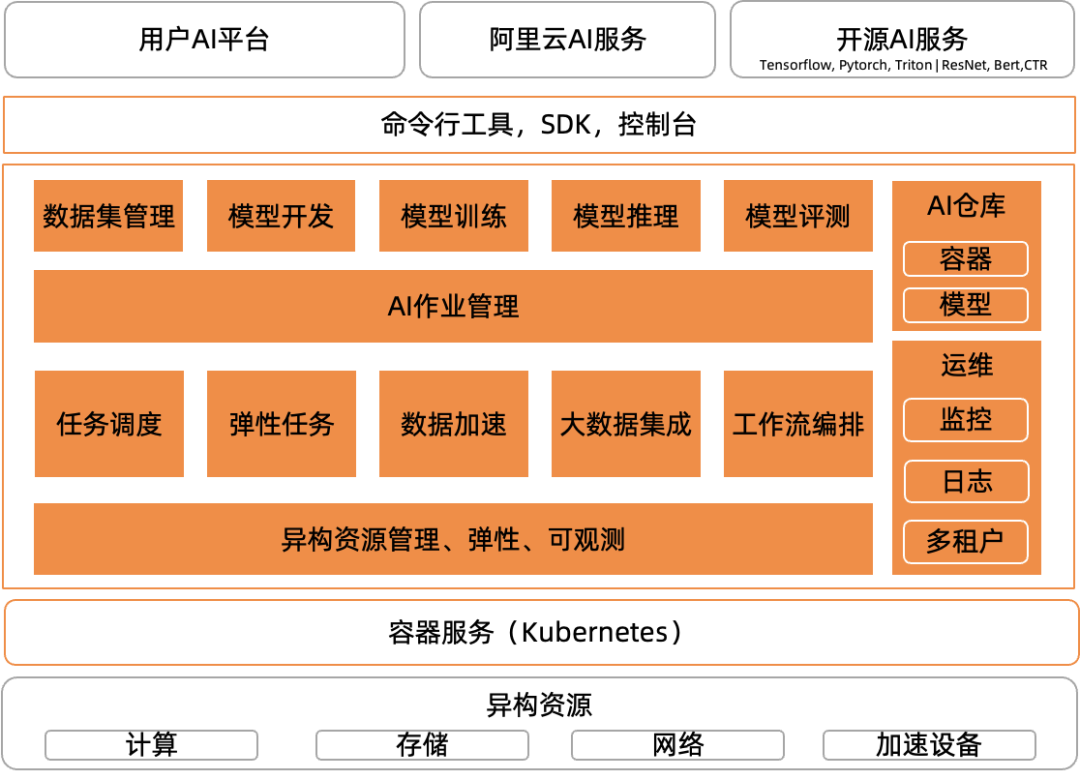
用户体验:对于数据科学家和算法工程师开发训练 AI 模型来说,Kubernetes 的语法和操作却是一种“负担”。他们更习惯在 Jupyter Notebook 等 IDE 中调试代码,使用命令行或者 Web 界面提交、管理训练任务。任务运行时的日志、监控、存储接入、GPU 资源分配和集群维护,最好都是内置的能力,使用工具就可以简单操作。因此要提供命令行工具/SDK/运维大盘/开发控制台来满足用户的各种需要。 AI 作业生命周期管理(Arena)
vivo
训练平台 + 推理平台 + 容器平台(日常维护cli ==> 白屏化)
算力的易用性
- 分布式训练
- 交互式调试
- 容量托管
- 训练sdk
算力的灵活调度
- 基于容器的资源调度
- 在离线统一资源池
- 混合云 vivo AI 计算平台的 ACK 混合云实践
- 基于GPU 拓扑的调度
算力的高效利用
- 资源分配:弹性伸缩、算力超卖(多个容器使用一张卡,GPU隔离)
- 资源使用:训练/推理加速,训练容错
- 弹性训练 vivo AI 计算平台弹性分布式训练的探索和实践
- 训练性能剖析
- GPU 远程调用
- 数据编排和加速
vivo推荐中台升级路:机器成本节约75%,迭代周期低至分钟级玲珑·推荐中台主要为数据及算法工程师提供从算法策略到 A/B 实验的工程架构解决方案、通用的特征服务和样本生产服务、模型的离线训练到上线部署全生命周期管理、高性能推理等能力。玲珑·推荐中台包含四大模块:推荐中心、特征中心、模型中心、端云协同推荐。
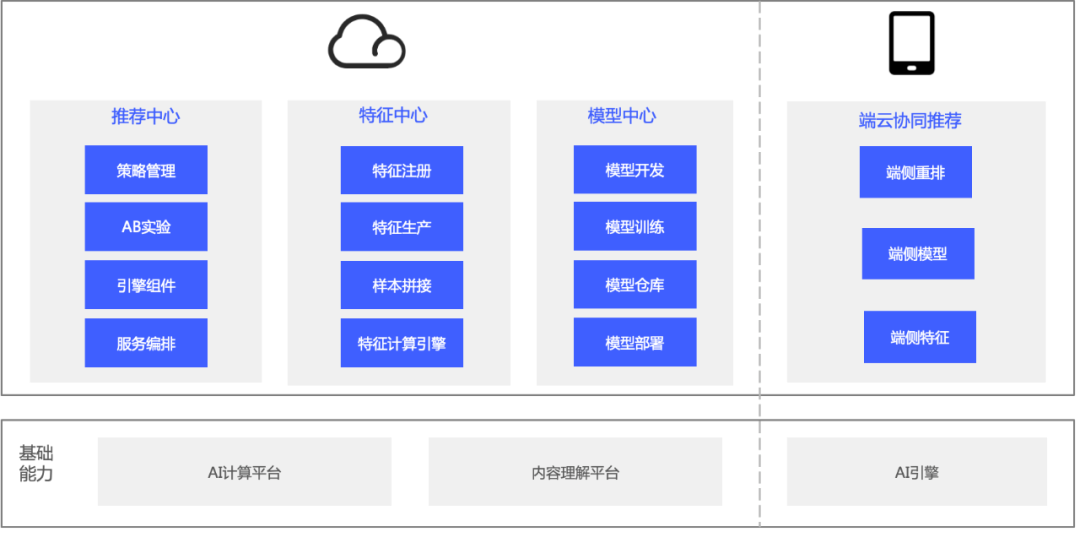
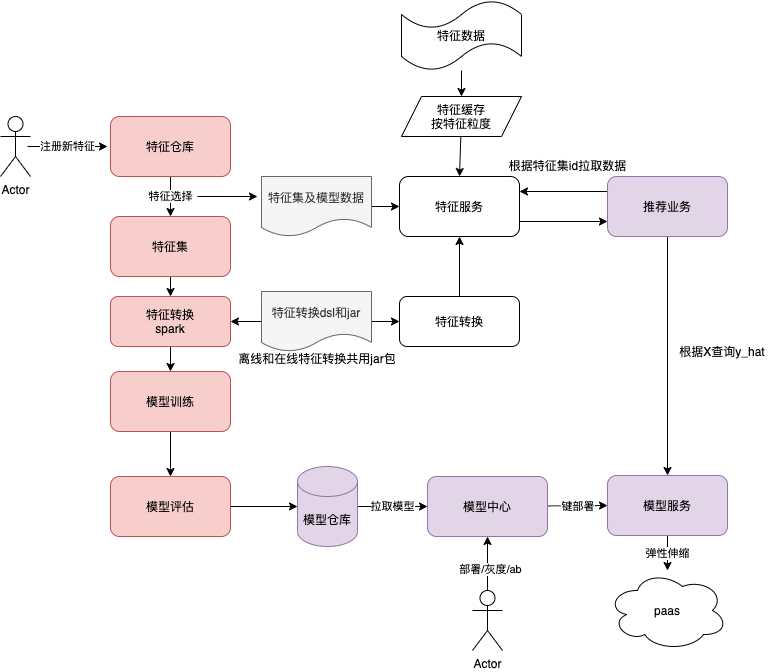
具体一点
腾讯
美团
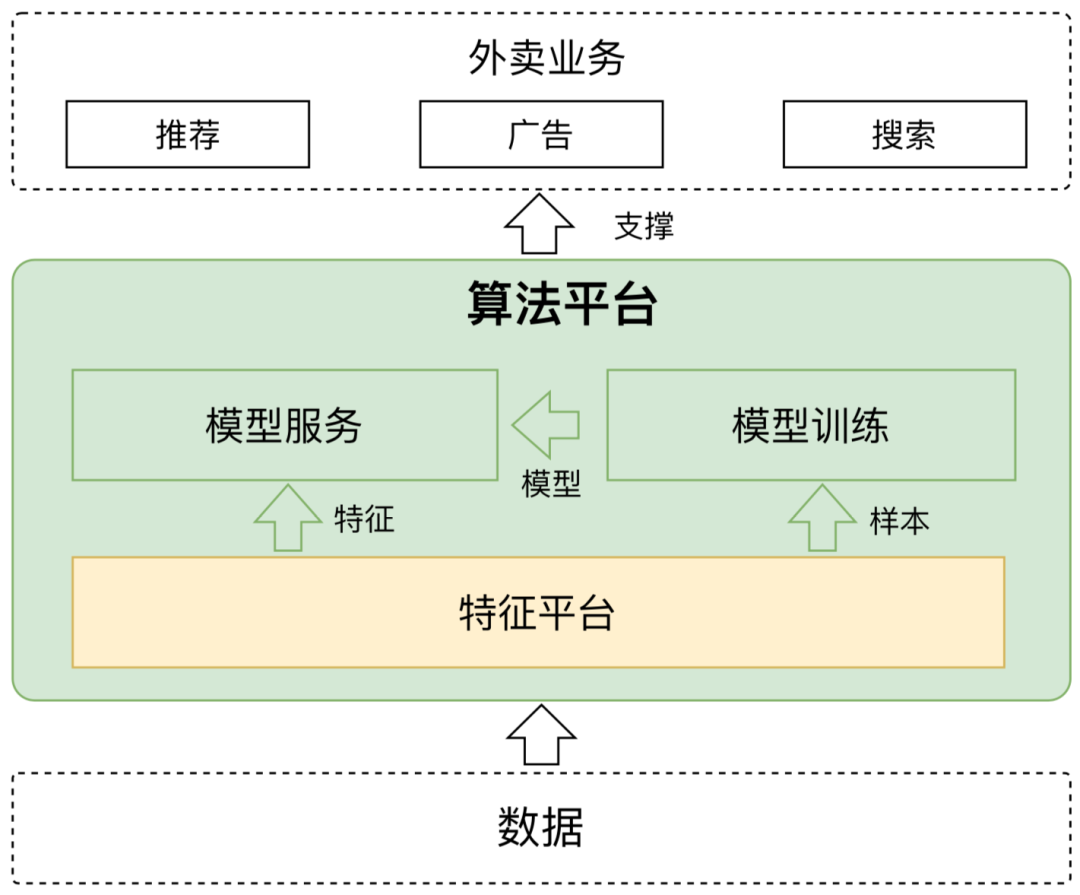
其它
深度学习平台的搭建,将遇到诸多挑战,主要体现在以下方面:
- 数据管理自动化。在深度学习的业务场景中,从业人员会花费大量的时间获取和转换建立模型需要的数据。数据处理过程中还将产生新的数据,这些数据不单单应用于本次训练,很可能用于后续推理过程。并且新 生成的数据不需要传给数据源,而是希望放置在新的存储空间。这需要基础平台提供可扩展的存储系统。PS: 手动命令行、页面、代码上传、下载,pod 随时可以访问,分布式训练任务多pod 之间也要共享一些临时的存储文件。 AI 数据编排与加速(Fluid)
- 资源的有效利用。深度学习相关的应用是资源密集型,资源使用波动大,存在峰值和谷值。在应用开始运行的时候,快速获取计算资源;在应用结束后,回收不适用的计算资源对于资源利用率的提升相当重要。数据处理、模型训练和推理所使用的计算资源类型和资源占用时间有所不同,这就需要计算平台提供弹性的资源供应机制。
- 屏蔽底层技术的复杂性
如何跟公有云协同 vivo AI 计算平台的 ACK 混合云实践
AI 中台具备六大能力。
- 统一的存储空间,支持多数据源导入。
- Pipeline 可视化工作流管理与执行,支持数据科学家从数据建模阶段开始的可视化管理,节省成本,快速体现数据科学家的价值。深入探索云原生流水线的架构设计
- 基于容器的计算资源分配和软件库安装,支持 TensorFlow、PyTorch 等各种框架。
- 支持 GPU、TPU、CPU 框架和基于异构计算的模型管理。
- 模型管理,支持新手快速上手,无需通过自己实现原始算法,只需要理解算法原理就可以通过调参实现。
- AI Serving,模型一键封装为 API,一键部署。
- 在 Pipeline 中,我们对一个任务执行的抽象是 ActionExecutor。一个执行器只要实现单个任务的创建、启动、更新、状态查询、删除等基础方法,就可以注册成为一个 ActionExecutor。
- Engine 层负责流水线的推进,包括:Queue Manager 队列管理器,支持队列内工作流的优先级动态调整、资源检查、依赖检查等。Dispatcher 任务分发器,用于将满足出队条件的流水线分发给合适的 Worker 进行推进。Reconciler 协调器,负责将一条完整的流水线解析为 DAG 结构后进行推进,直至终态。
- 模块内部使用插件机制,对接各种任务运行时。
- 在一条流水线中,节点间除了有依赖顺序之外,一定会有数据传递的需求。上下文传递,后置任务可以引用前置任务的“值”和“文件”
- Pipeline 之所以好用,是因为它提供了灵活一致的流程编排能力,并且可以很方便地对接其他单任务执行平台,这个平台本身不需要有流程编排的能力。调度时,根据任务类型智能调度到对应的任务执行器上,包括 K8sJob、Metronome Job、Flink Job、Spark Job 等等。
- 这里简单列举一些比较常见的功能特性:
- 配置即代码
- 扩展市场丰富
- 可视化编辑
- 支持嵌套流水线
- 灵活的执行策略,支持 OnPush / OnMerge 等触发策略
- 支持工作流优先队列
- 多维度的重试机制
- 定时流水线及定时补偿功能
- 动态配置,支持“值”和“文件”两种类型,均支持加密存储,确保数据安全性
- 上下文传递,后置任务可以引用前置任务的“值”和“文件”
- 开放的 OpenAPI 接口,方便第三方系统快速接入