简介
整体思路
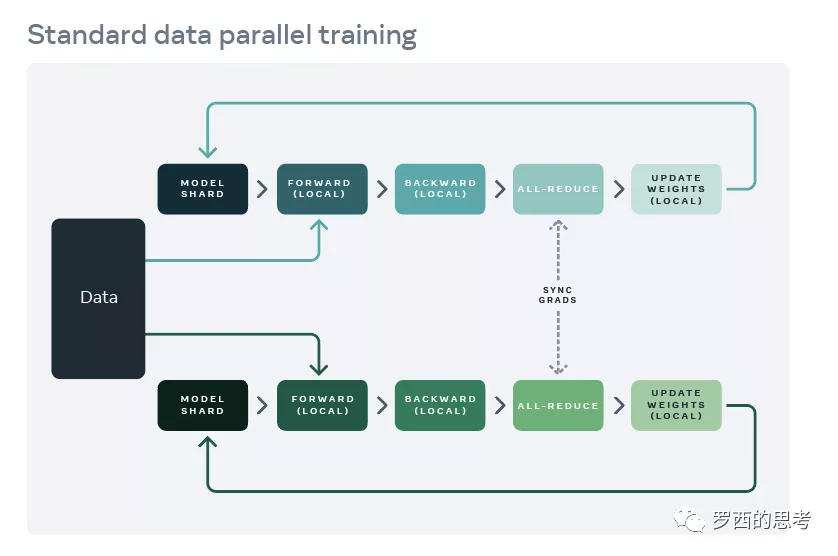
DDP系列第一篇:入门教程多机多卡
- 分布式训练的几个选择:
- 模型并行 vs 数据并行
- PS 模型 vs Ring-Allreduce 。 Allreduce operation can not start until all processes join, it is considered to be a synchronized communication, as opposed to the P2P communication used in parameter servers.
- 假设 有两台机子,每台8张显卡,那就是2x8=16个进程,并行数是16。DDP 推荐每个进程一张卡,在16张显卡,16的并行数下,DDP会同时启动16个进程。rank表示当前进程的序号(0~16),用于进程间通讯。local_rank 表示每台机子上的进程的序号(0~7),也用来指定机器上的gpu 序号。用起来 就是一行代码,
model = DDP(model, device_ids=[local_rank], output_device=local_rank),后续的模型关于前向传播、后向传播的用法,和单机单卡完全一致。DDP系列第二篇:实现原理与源代码解析 - 每个进程跑的是同一份代码,进程从外界(比如环境变量)获取 rank/master_addr/master_port 等参数,rank = 0 的进程为 master 进程
[源码解析] PyTorch 分布式(8) ——– DistributedDataParallel 之 论文篇应用程序开发通常从本地模型开始,然后在必要时扩展。所以需要有一个从本地模型开始,修改代码以适应分布式的过程。为了避免这个从本地模型到分布式模型的过渡期间太过麻烦,API在应用程序代码中是非侵入性的。
单机单卡
单机单卡训练步骤:定义网络,定义dataloader,定义loss和optimizer,开训
BATCH_SIZE = 256
EPOCHS = 5
if __name__ == "__main__":
# 1. define network
device = "cuda"
net = torchvision.models.resnet18(num_classes=10)
net = net.to(device=device)
# 2. define dataloader
trainset = torchvision.datasets.CIFAR10(...)
train_loader = torch.utils.data.DataLoader(
trainset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
pin_memory=True,
)
# 3. define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(
net.parameters(),
lr=0.01,
momentum=0.9,
weight_decay=0.0001,
nesterov=True,
)
print(" ======= Training ======= \n")
# 4. start to train
net.train()
for ep in range(1, EPOCHS + 1): # 控制在全部数据上训练的次数
for idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets) # 获得输出结果和样本值的损失函数
optimizer.zero_grad()
loss.backward() # 根据loss 进行反向梯度传播
optimizer.step() # 用计算的梯度去做优化
单机多卡
如果是单机多卡,定义网络时加入 net = nn.DataParallel(net)
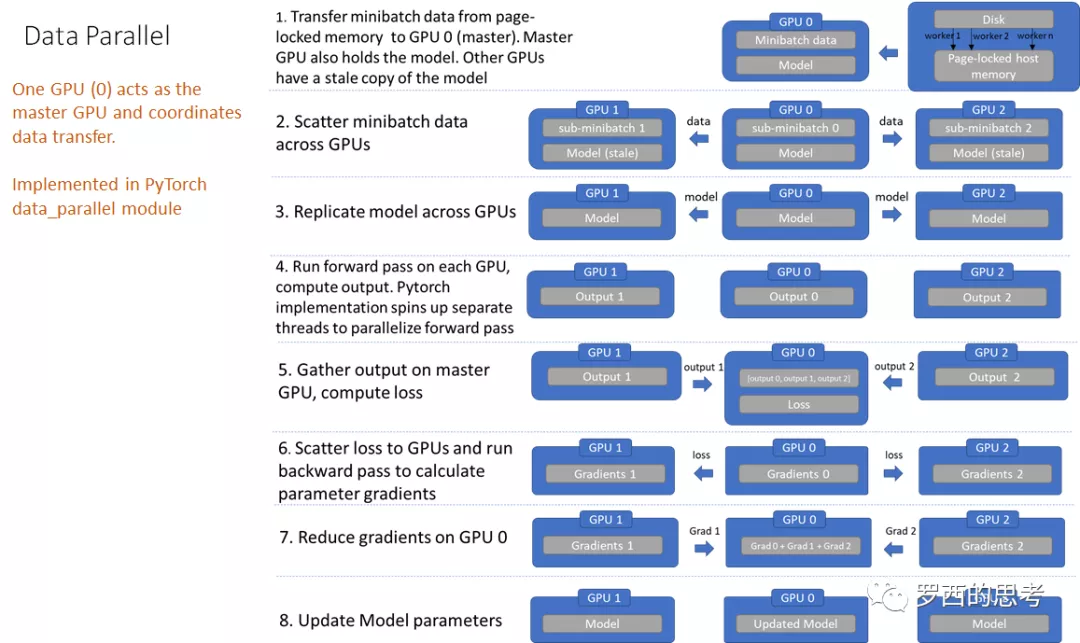
PyTorch 分布式(2) —– DataParallel(上) 缺点很多。
分布式训练
pytorch ddp论文:During distributed training, each pro- cess has its own local model replica and local optimizer. In terms of correctness, distributed data parallel training and local training must be mathematically equivalent. DDP guarantees the correctness by making sure that all model replicas start from the exact same model state, and see the same parameter gradients after every backward pass. Therefore, even though optimizers from different processes are all independent, they should be able to bring their local model replicas to the same state at the end of every iteration.
PyTorch 分布式(5) —— DistributedDataParallel 总述&如何使用
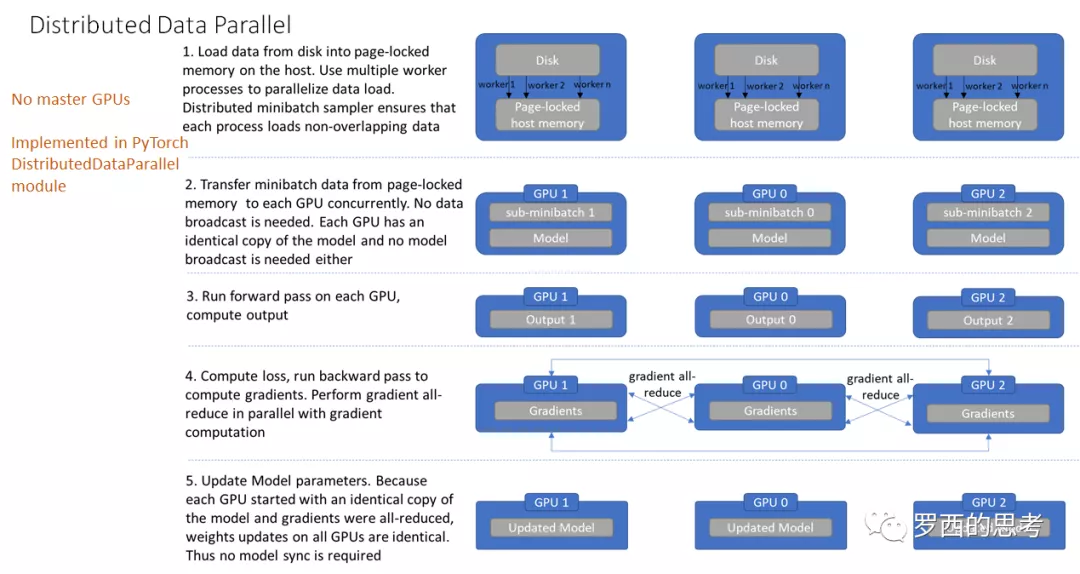
- 加载模型阶段。每个GPU都拥有模型的一个副本,所以不需要拷贝模型。rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的模型都拥有一样的初始化值。
- 加载数据阶段。DDP 不需要广播数据,而是使用多进程并行加载数据。在 host 之上,每个worker进程都会把自己负责的数据从硬盘加载到 page-locked memory。DistributedSampler 保证每个进程加载到的数据是彼此不重叠的。
- 前向传播阶段。在每个GPU之上运行前向传播,计算输出。每个GPU都执行同样的训练,所以不需要有主 GPU。
- 计算损失。在每个GPU之上计算损失。
- 反向传播阶段。运行后向传播来计算梯度,在计算梯度同时也对梯度执行all-reduce操作。每一层的梯度不依赖于前一层,所以梯度的All-Reduce和后向过程同时计算,以进一步缓解网络瓶颈。在后向传播的最后,每个节点都得到了平均梯度,这样模型参数保持同步。关于AllReduce
- 更新模型参数阶段。因为每个GPU都从完全相同的模型开始训练,并且梯度被all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,也就不需要模型同步了
模板代码
import torch.distributed as dist
import torch.utils.data.distributed
parser = argparse.ArgumentParser(description='PyTorch distributed training on cifar-10')
parser.add_argument('--rank', default=0,help='rank of current process')
parser.add_argument('--word_size', default=2,help="word size")
parser.add_argument('--init_method', default='tcp://127.0.0.1:23456',help="init-method")
args = parser.parse_args()
...
dist.init_process_group(backend='nccl', init_method=args.init_method, rank=args.rank, world_size=args.word_size)
...
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=download, transform=transform)
## 数据并行需要进行数据切片
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset,num_replicas=args.world_size,rank=rank)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, sampler=train_sampler)
...
net = Net()
net = Net().to(device) # device 代表到某个 gpu 或cpu 上
## 使用DistributedDataParallel 修饰模型
net = torch.nn.parallel.DistributedDataParallel(net)
- 用dist.init_process_group初始化分布式环境
- 一般来说,nccl 用于 GPU 分布式训练,gloo 用于 CPU 进行分布式训练。
- 这个调用是阻塞的,必须等待所有进程来同步,如果任何一个进程出错,就会失败。
- 数据侧,我们nn.utils.data.DistributedSampler来给各个进程切分数据,只需要在dataloader中使用这个sampler就好
- 使用 DDP 时,不再是从主 GPU 分发数据到其他 GPU 上,而是各 GPU 从自己的硬盘上读取属于自己的那份数据。
- 训练循环过程的每个epoch开始时调用train_sampler.set_epoch(epoch),(主要是为了保证每个epoch的划分是不同的)其它的训练代码都保持不变。
- 举个例子:假设10w 数据,10个实例。单机训练任务一般采用batch 梯度下降,比如batch=100。分布式后,10个实例每个训练1w,这个时候每个实例 batch 是100 还是 10 呢?是100,batch 的大小取决于 每个实例 GPU 显存能放下多少数据。
- 模型侧,我们只需要用DistributedDataParallel包装一下原来的model
pytorch 中的任何 net 都 是 torch.nn.Module 的子类,DistributedDataParallel 也是 torch.nn.Module 子类,任何 torch.nn.Module 子类 都可以覆盖 __init__ 和 forward方法 ,DistributedDataParallel 可以从 net 拿到模型数据(以及 在哪个gpu 卡上运行) ,也可以 从指定或默认的 process_group 获取信息。最后在__init__ 和 forward 中加入 同步梯度的逻辑,完美的将 同步梯度的逻辑 隐藏了起来。
实际例子
BATCH_SIZE = 256
EPOCHS = 5
if __name__ == "__main__":
# 0. set up distributed device
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(rank % torch.cuda.device_count())
dist.init_process_group(backend="nccl")
device = torch.device("cuda", local_rank) # 把模型放置到特定的GPU上
print(f"[init] == local rank: {local_rank}, global rank: {rank} ==")
# 1. define network
net = torchvision.models.resnet18(pretrained=False, num_classes=10)
net = net.to(device)
# DistributedDataParallel
net = DDP(net, device_ids=[local_rank], output_device=local_rank)
# 2. define dataloader
trainset = torchvision.datasets.CIFAR10(...)
# DistributedSampler
# we test single Machine with 2 GPUs so the [batch size] for each process is 256 / 2 = 128
train_sampler = torch.utils.data.distributed.DistributedSampler(
trainset,
shuffle=True,
)
train_loader = torch.utils.data.DataLoader(
trainset,
batch_size=BATCH_SIZE,
num_workers=4,
pin_memory=True,
sampler=train_sampler,
)
# 3. define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(
net.parameters(),
lr=0.01 * 2,
momentum=0.9,
weight_decay=0.0001,
nesterov=True,
)
if rank == 0:
print(" ======= Training ======= \n")
# 4. start to train
net.train() # 标记为训练模式,推理时使用 net.eval()
for ep in range(1, EPOCHS + 1):
train_loss = correct = total = 0
# set sampler
train_loader.sampler.set_epoch(ep)
for idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad() # 将梯度归零
loss.backward() # 反向传播计算得到每个参数的梯度值
optimizer.step() # 通过梯度下降执行一步参数更新,optimizer只负责通过梯度下降进行优化,而不负责产生梯度,梯度是tensor.backward()方法产生的。
train_loss += loss.item()
total += targets.size(0)
correct += torch.eq(outputs.argmax(dim=1), targets).sum().item()
# 输出loss 和 正确率
if rank == 0:
print("\n ======= Training Finished ======= \n")
每条命令表示一个进程。若已开启的进程未达到 word_size 的数量,则所有进程会一直等待
对训练的影响
假设10w 数据,单机训练任务一般采用batch 梯度下降,比如batch=100。分布式后10个实例,每个实例训练1w。
- 如果每个实例 batch 是100 ,根据pytorch 数据并行的原理,每个实例每次batch 训练后向传播会交换一次梯度,得到的梯度是每个实例上梯度的均值,也就是说你有10个实例,这个梯度均值就是1000个样本的梯度均值。学习率一般也要相应调整。
- 一般 每个实例的batch = 单机batch / world_size
DDP 总体实现
DDP implementation lives in both Python and C++ files, with Python exposing the API and composing non-performance-critical components, and C++ serving the core gradient reduction algorithm. The Python API calls into C++ core through Pybind11.
本地模型 Module 定义如下,经过 DDP 的封装,便成为一个有分布式能力的Module了。
class Module:
dump_patches: bool = False
_version: int = 1
training: bool # 本网络是否正在训练
_is_full_backward_hook: Optional[bool]
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict() # 在训练过程中会随着 BP 而更新的参数
self._buffers = OrderedDict() # 在训练过程中不会随着 BP 而更新的参数, running variance,running mean etc
self._non_persistent_buffers_set = set()
self._backward_hooks = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict() # 本网络下属的子模块,采取迭代的方式进行定义
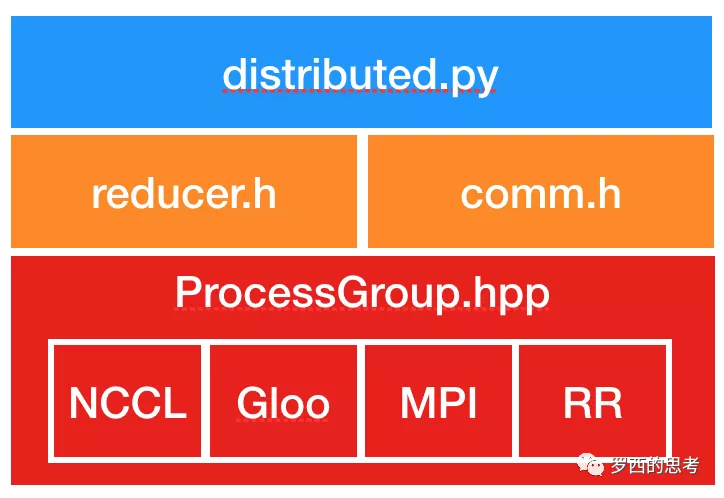
PyTorch 分布式(9) —– DistributedDataParallel 之初始化一次DistributedDataParallel迭代中的步骤如下
- Prerequisite:DDP 依赖 c10dProcessGroup进行通信。因此,应用程序必须ProcessGroup在构建 DDP 之前创建实例。
- Constuctor
- rank=0 进程会引用本地模块,把模型state_dict()参数广播到所有进程之中,这样可以保证所有进程使用同样初始化数值和模型副本进行训练。
- 每个 DDP 进程创建一个 local Reducer,为了提高通信效率,Reducer将参数梯度组织成桶,一次reduce一个桶。Reducer还在构造期间注册 autograd 钩子,每个参数一个钩子。当梯度准备好时,将在向后传递期间触发这些钩子。
- Forward Pass: [源码解析] PyTorch 分布式(12)—–DistributedDataParallel 之 前向传播
- 每个进程读去自己的训练数据,DistributedSampler确保每个进程读到的数据不同。
- DDP 获取输入并将其传递给本地模型。模型进行前向计算,结果设置为 out。模型网络输出不需要gather到 rank 0进程了,这与 DP不同。
- Backward Pass:
- backward()在 loss 上直接调用该函数 Tensor,这是 DDP 无法控制的,DDP 使用构造时注册的 autograd hooks 来触发梯度同步。当一个梯度准备好时,它在该梯度累加器上的相应 DDP 钩子将触发。
- 在 autograd_hook 之中进行all-reduce。假设参数index是param_index,则利用param_index获取到参数,标示为ready,如果某个桶里面梯度都ready,则该桶是ready。当一个桶中的梯度都准备好时,会 在该桶上Reducer启动异步allreduce以计算所有进程的梯度平均值。如果所有桶都ready,则等待所有 all-reduce 完成。当所有桶都准备好时,Reducer将阻塞等待所有allreduce操作完成。完成此操作后,将平均梯度写入param.grad所有参数的字段。所有进程的梯度都会reduce,更新之后,大家的模型权重都相同。所以在向后传播完成之后,跨不同DDP进程的对应的相同参数上的 grad 字段应该是相等的。
- 不需要像 DP 那样每次迭代之后还要广播参数。但是 Buffers 还是需要在每次迭代由 rank 0 进程广播到其他进程之上。
- Optimizer Step: 从优化器的角度来看,它正在优化本地模型。
单机场景下,pytorch 封装了torch.autograd包,torch.autograd is PyTorch’s automatic differentiation engine that powers neural network training.torch.autograd 封装了前向后向传播逻辑(实现自动微分),所谓分布式首先是 autograd engine的分布式。PyTorch 分布式 Autograd (1) —- 设计
- 分布式RPC框架
- 前向传播期间的 Autograd 记录
- 分布式 Autograd 上下文
- 分布式反向传播
- 分布式优化器
PyTorch 分布式 Autograd (2) —- RPC基础 是一个系列文章,有兴趣可以细读下, 比较有价值的点就是 有很多low leve api 代码示例,可以看下较为原汁原味的 分布式前后向传播过程。比如
# 代码目的是让两个 worker 之间就通过 RPC 进行协作。
def my_add(t1, t2):
return torch.add(t1, t2)
def worker0():
# On worker 0:
# Setup the autograd context. Computations that take
# part in the distributed backward pass must be within
# the distributed autograd context manager.
with dist_autograd.context() as context_id:
t1 = torch.rand((3, 3), requires_grad=True)
t2 = torch.rand((3, 3), requires_grad=True)
# 第一阶段:RPC操作,构建依赖基础
# Perform some computation remotely.
t3 = rpc.rpc_sync("worker1", my_add, args=(t1, t2))
# Perform some computation locally based on remote result.
t4 = torch.rand((3, 3), requires_grad=True)
t5 = torch.mul(t3, t4)
# Compute some loss.
loss = t5.sum()
# 第二阶段,执行后向传播
# Run the backward pass.
dist_autograd.backward(context_id, [loss])
# Retrieve the gradients from the context.
dist_autograd.get_gradients(context_id)
print(loss)
ProcessGroup
Collective communication包含多个sender和多个receiver,一般的通信原语包括 broadcast,gather,all-gather,scatter,reduce,all-reduce,reduce-scatter,all-to-all等。再对照 ProcessGroup python 定义,ProcessGroup可以看做对 Collective Communication Library 的封装。
多个process 组成一个process_group,比如每个group 持有一个tensor,想计算tensor的和,可以借助p2p先汇总到一个 process 上求和再广播(如果tensor很大呢?),但其实可以边communication边computation,来挖掘性能和节约带宽。
PyTorch 分布式(7) —– DistributedDataParallel 之进程组
如何让 worker 在建立ProcessGroup之前发现彼此?
- init_method,开始的前提:如何联系到其它机器上的进程。
- Shared file-system initialization:init_method=’file:///mnt/nfs/sharedfile’
- dist.init_process_group(backend, init_method=’tcp://10.1.1.20:23456’,ank=args.rank, world_size=4)
- dist.init_process_group(backend, init_method=’env://’,ank=args.rank, world_size=4) 这个进程会自动读取环境变量 MASTER_ADDR/MASTER_PORT/WORLD_SIZE/RANK
- store ,有TcpStore 和EtcdStore 可以发挥类似 etcd 用来发挥的作用:服务发现及分布式键值存储
store 和 init_method 是互斥的。store 先于 ProcessGroup 创建和初始化。PS: 随着版本的迭代,变动较大,不纠结了
init_process_group ==> ` rendezvous_iterator = rendezvous(init_method, rank, world_size, timeout=timeout)` 使用了rendezvous 机制,与elastic agent 共用 TcpStore(默认是共用的,也可以不共用), 此处的 rendezvous_handler 是一个函数(返回store/rank/world_size),与elastic agent 使用的 RendezvousHandler 不同。
# /pytorch/torch/distributed/rendezvous.py
def rendezvous(url: str, rank: int = -1, world_size: int = -1, **kwargs) -> (store, rank, world_size):
...
return _rendezvous_handlers[result.scheme](url, **kwargs)
# 如果 env TORCHELASTIC_USE_AGENT_STORE=true,则此处创建的 是 TCPStore client
def _create_c10d_store(hostname, port, rank, world_size, timeout) -> Store:
def _file_rendezvous_handler(url: str, **kwargs):
...
store = FileStore(path, world_size)
...
def _tcp_rendezvous_handler(url: str, timeout: timedelta = default_pg_timeout, **kwargs):
...
_create_c10d_store(hostname, port, rank, world_size, timeout) -> Store:
...
def _env_rendezvous_handler(url: str, timeout: timedelta = default_pg_timeout, **kwargs):
...
_create_c10d_store(hostname, port, rank, world_size, timeout) -> Store:
...
def register_rendezvous_handler(scheme, handler):
register_rendezvous_handler("tcp", _tcp_rendezvous_handler)
register_rendezvous_handler("env", _env_rendezvous_handler)
register_rendezvous_handler("file", _file_rendezvous_handler)
ProcessGroup 如何被使用
Collective functionsif the system we use for distributed training has 2 nodes, each of which has 8 GPUs. On each of the 16 GPUs, there is a tensor that we would like to all-reduce. The following code can serve as a reference:
# Code running on Node 0
import torch
import torch.distributed as dist
dist.init_process_group(backend="nccl",
init_method="file:///distributed_test",
world_size=2,
rank=0)
tensor_list = []
for dev_idx in range(torch.cuda.device_count()):
tensor_list.append(torch.FloatTensor([1]).cuda(dev_idx))
dist.all_reduce_multigpu(tensor_list)
# Code running on Node 1
import torch
import torch.distributed as dist
dist.init_process_group(backend="nccl",
init_method="file:///distributed_test",
world_size=2,
rank=1)
tensor_list = []
for dev_idx in range(torch.cuda.device_count()):
tensor_list.append(torch.FloatTensor([1]).cuda(dev_idx))
dist.all_reduce_multigpu(tensor_list)
After the call, all 16 tensors on the two nodes will have the all-reduced value of 16
抛开概念,从代码看其本质。processgroup 就是给每一个训练的 process 建立一个Communication thread。主线程(Computation thread)在前台进行训练,这个Communication thread 在后台做通信(比如交流梯度)。
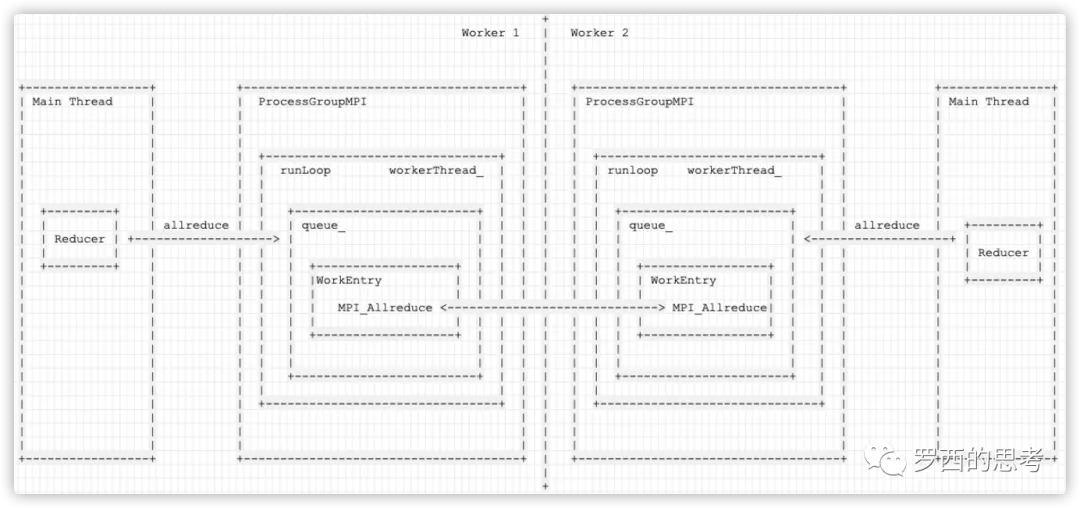
可以看下 ProcessGroup 的接口定义(从理论上,Ring AllReduce 分为Split/ScatterReudce/AllGather 三个步骤,不同框架命名会有差异)
# torch/_C/_distributed_c10d.py
class ProcessGroup(__pybind11_builtins.pybind11_object):
def allgather(self, *args, **kwargs):
def allgather_coalesced(self, output_lists, *args, **kwargs):
def allreduce(self, *args, **kwargs):
def allreduce_coalesced(self, tensors, *args, **kwargs):
def alltoall(self, *args, **kwargs):
def alltoall_base(self, *args, **kwargs):
def barrier(self, opts, *args, **kwargs):
def broadcast(self, *args, **kwargs):
def gather(self, *args, **kwargs):
def monitored_barrier(self, timeout=None, *args, **kwargs):
def rank(self):
def recv(self, arg0, *args, **kwargs):
def recv_anysource(self, arg0, *args, **kwargs):
def reduce(self, *args, **kwargs):
def reduce_scatter(self, *args, **kwargs):
def scatter(self, *args, **kwargs):
def send(self, arg0, *args, **kwargs):
def size(self):
def _allgather_base(self, output, *args, **kwargs):
def _get_sequence_number_for_group(self):
def _set_sequence_number_for_group(self):
ddp 初始化时 对模型参数进行广播 会调用到 process_group->broadcast(vec),反向传播 需要对梯度做 all-reduce 时候,Reducer会调用 process_group_->allreduce(tensors) 进行处理。
backend 是一个逻辑上的概念。本质上后端是一种IPC通信机制。对于用户来说,就是采用那种方式来进行集合通信,从代码上看,就是走什么流程(一系列流程),以及后端使用 ProcessGroupMPI 还是 ProcessGroupGloo …..。各主机之间需要进行通信。因此,需要指定通信的协议架构等。torch.distributed 对其进行了封装。提供了分布式通信原语
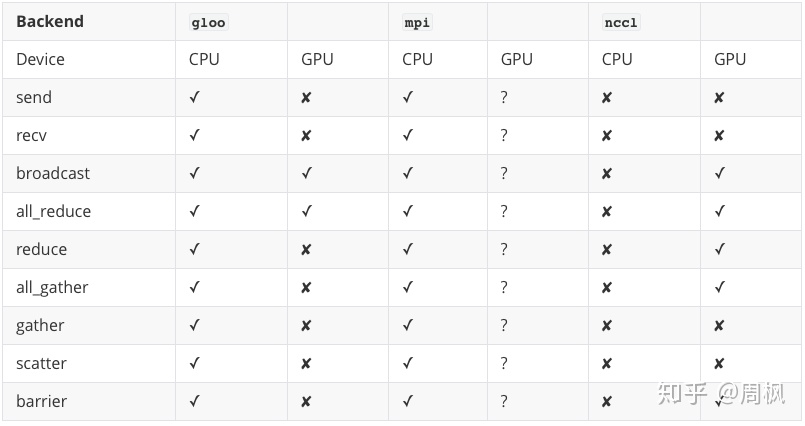
其它
DDP 在启动时 将 rank=0 的state_dict() 广播到其他worker,以保证所有worker的模型初始状态相同。需要广播的 state_dict 是什么?pytorch 的 state_dict 是一个字典对象,其将模型的每一层与它的对应参数建立映射关系,比如 model 每一层的weights及偏置等等。只有那些参数可以训练的层(比如卷积层,线性层等)才会被保存到模型的state_dict中,池化层、BN层这些本身没有参数的层就不会保存在 state_dict 之中,比如针对下面模型。
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
state_dict 如下:
self.module.state_dict() = {OrderedDict: 4}
'net1.weight' = {Tensor: 10} tensor([[ 0.2687, 0.0840, -0.1032, 0.3079, 0.0385, -0.0495, -0.3068, -0.1271,\n -0.1067, -0.1966],\n [-0.1203, 0.1789, 0.0666, 0.1882, 0.1335, 0.1921, -0.1145, -0.1781,\n 0.0661, -0.2339],\n [ 0.1865, -0.2076, 0.2071, 0
'net1.bias' = {Tensor: 10} tensor([ 0.2146, -0.1599, 0.2350, -0.2843, -0.0773, -0.2151, 0.1864, -0.3068,\n -0.2093, 0.1365])
'net2.weight' = {Tensor: 5} tensor([[ 0.1922, -0.0148, -0.1884, 0.2124, -0.1361, 0.0172, -0.2371, 0.1946,\n 0.2047, -0.2697],\n [-0.2690, 0.1372, 0.2269, 0.0436, -0.1353, -0.2054, -0.2418, -0.2300,\n 0.1987, 0.0007],\n [ 0.0995, -0.2659, -0.2374, -0
'net2.bias' = {Tensor: 5} tensor([0.1488, 0.0791, 0.1667, 0.1449, 0.0545])