简介
《Linux内核设计的艺术》基于linux0.11内核,借助简单明了的代码,很直接的阐述了现代操作系统的一些基本思想。一位大佬对 linux 解读也非常不错 sunym1993/flash-linux0.11-talk
2018.10.12 补充,The Linux Kernel,基于内核2.0.33, 当你对0.xx,1.xx 版本的内核有一定了解之后,可以尝试深入一下,了解下前人的演进思路。
汇编阶段/为main函数运行做准备
从大的方向说,整个linux启动过程中,分别是BIOS、汇编程序、OS三方在使用内存。因为计算机只能执行内存中的程序,它们在运行的时候,往内存里加载了什么很大程度上说明了它们要做什么。
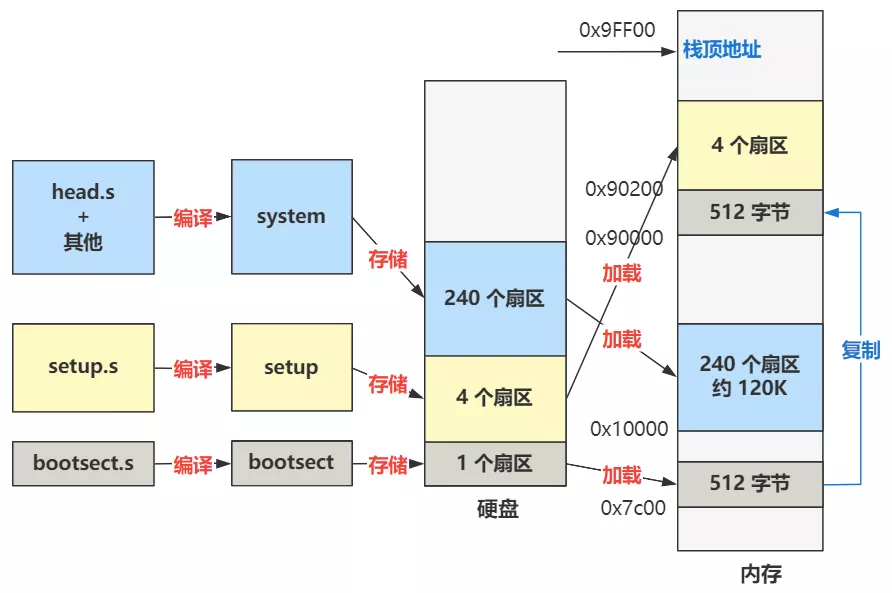
bios ==> bootsect.s ==> setup.s ==> 要和其他全部操作系统代码做链接的 head.s。就是逐渐进入保护模式,并设置分段、分页、中断等机制的地方。最终的内存布局变成了这个样子。
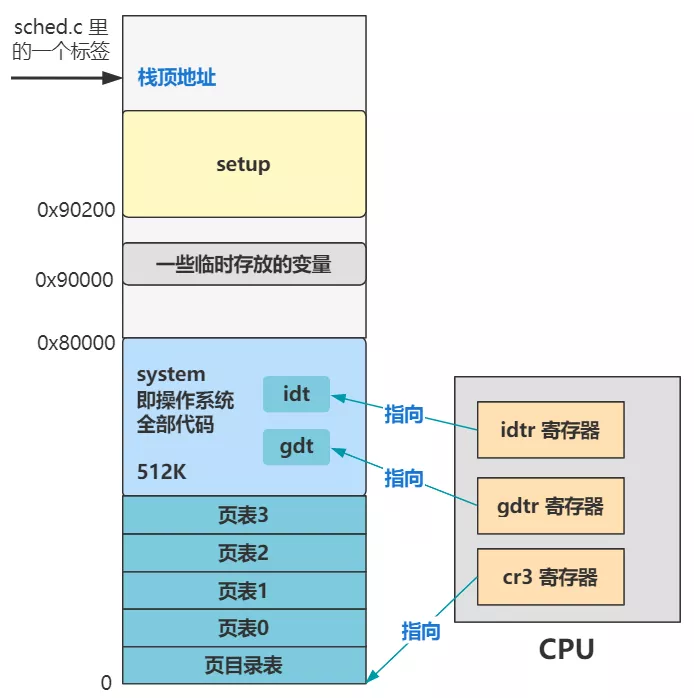
我们的学习过程,主心骨其实就是看看,操作系统在经过一番折腾后,又在内存中建立了什么数据结构,而这些数据结构后面又是如何用到的。
中断的设置,就引出了 CPU 与操作系统处理中断的流程。分段和分页的设置,引出了逻辑地址到物理地址的转换:逻辑地址到线性地址的转换,依赖 Intel 的分段机制;而线性地址到物理地址的转换,依赖 Intel 的分页机制。分段和分页,就是 Intel 管理内存的两大利器,也是内存管理最最最最底层的支撑。而 Intel 本身对于访问内存就分成三类:代码、数据、栈。而 Intel 也提供了三个段寄存器来分别对应着三类内存:
- 代码段寄存器(cs),cs:eip 表示了我们要执行哪里的代码。
- 数据段寄存器(ds),ds:xxx 表示了我们要访问哪里的数据。
- 栈段寄存器(ss),ss:esp 表示了我们的栈顶地址在哪里。
分段和分页,以及这几个寄存器的设置,其实本质上就是安排我们今后访问内存的方式,做了一个初步规划,包括去哪找代码、去哪找数据、去哪找栈,以及如何通过分段和分页机制将逻辑地址转换为最终的物理地址。 c 语言虽然很底层了,但也有其不擅长的事情,就交给汇编语言来做,所以我称第一部分为进入内核前的苦力活。PS: 汇编代码的画风就是 几个段寄存器操作指令 + 寄存器对应的xx段操作指令,比如设置堆栈寄存器 + 执行堆栈操作(push)
《Linux内核设计的艺术》os的加载
- OS代码在磁盘中,计算机却只能执行内存中的程序。
- 一般程序的运行是执行main函数,操作系统的运行也是执行main函数。一般程序由操作系统加载,操作系统没办法,只有由汇编程序加载。而汇编程序由谁加载呢?BIOS。
- BIOS也是一个OS,其工作是将磁盘的第一扇区内容加载到内存(所以叫bootsect.s,即boot sector)。
- 因为第一扇区承载的代码有限,所以加载os的汇编程序分为几个,依次接力执行。
C阶段/操作系统是一个main函数
摘自loveveryday/linux0.11 短短几行,包含了操作系统的全部核心思想。
// init/main.c
void main(void){
// 参数的取值和计算, setup.s 将获取的信息保存在 内存地址 0x90000 处
...
// 各种初始化 init 操作
mem_init(main_memory_start,memory_end);
trap_init(); // 陷阱门(硬件中断向量)初始化。(kernel/traps.c)
blk_dev_init(); // 块设备初始化。(kernel/blk_dev/ll_rw_blk.c)
chr_dev_init(); // 字符设备初始化。(kernel/chr_dev/tty_io.c)空,为以后扩展做准备。
tty_init(); // tty 初始化。(kernel/chr_dev/tty_io.c)
time_init(); // 设置开机启动时间 -> startup_time。
sched_init(); // 调度程序初始化(加载了任务0 的tr, ldtr) (kernel/sched.c)
buffer_init(buffer_memory_end);// 缓冲管理初始化,建内存链表等。(fs/buffer.c)
hd_init(); // 硬盘初始化。(kernel/blk_dev/hd.c)
floppy_init(); // 软驱初始化。(kernel/blk_dev/floppy.c)
sti(); // 所有初始化工作都做完了,开启中断。
// 切换到用户态模式,下面过程通过在堆栈中设置的参数,利用中断返回指令切换到任务0。
move_to_user_mode(); // 移到用户模式。(include/asm/system.h)
if (!fork()) { // fork对新进程进行了设置,使其可以独立运行
init(); // 如果是在进程0中,fork返回进程1的进程号1,进而跳过init。如果在进程1中,则fork返回0,执行init。
}
/*
* 注意!! 对于任何其它的任务,'pause()'将意味着我们必须等待收到一个信号才会返
* 回就绪运行态,但任务0(task0)是唯一的意外情况(参见'schedule()'),因为任
* 务0 在任何空闲时间里都会被激活(当没有其它任务在运行时),
* 因此对于任务0'pause()'仅意味着我们返回来查看是否有其它任务可以运行,如果没
* 有的话我们就回到这里,一直循环执行'pause()'。
*/
for(;;) pause();
}
void init(void){
// 读取硬盘参数包括分区表信息并建立虚拟盘和安装根文件系统设备。
// 该函数是在25 行上的宏定义的,对应函数是sys_setup(),在kernel/blk_drv/hd.c。
setup((void *) &drive_info);
(void) open("/dev/tty0",O_RDWR,0); // 用读写访问方式打开设备“/dev/tty0”,
// 这里对应终端控制台。
// 返回的句柄号0 -- stdin 标准输入设备。
(void) dup(0); // 复制句柄,产生句柄1 号-- stdout 标准输出设备。
(void) dup(0); // 复制句柄,产生句柄2 号-- stderr 标准出错输出设备。
...
if (!(pid=fork())) {
// 以下为进程2执行的内容
close(0);
if (open("/etc/rc",O_RDONLY,0))
_exit(1); // 如果打开文件失败,则退出(/lib/_exit.c)。
execve("/bin/sh",argv_rc,envp_rc); // 装入/bin/sh 程序并执行。(/lib/execve.c)
_exit(2); // 若execve()执行失败则退出(出错码2,“文件或目录不存在”)。
}
// 下面是父进程执行的语句。wait()是等待子进程停止或终止,其返回值应是子进程的
// 进程号(pid)。这三句的作用是父进程等待子进程的结束。&i 是存放返回状态信息的
// 位置。如果wait()返回值不等于子进程号,则继续等待。
if (pid>0)
while (pid != wait(&i))
{ /* nothing */;}
...
}
所以说,操作系统是一个main函数。PS,主进程衍生出许多子进程,跟主线程衍生出许多子线程很像。
| 寻址模式 | 访问权限 | 主要工作 | 效果 | 其它 | |
|---|---|---|---|---|---|
| 汇编加载os | bootsect.s、setup.s实模式;head.s保护模式 | 内核态 | 加载OS,设置GDT,抛弃BIOS中断体系建立新的,初始化页目录表和4张页表 | 初步建立进程管理信息数据结构,部分基本的中断,关中断,准备好保护模式(需要GDT)和分页模式,为main(只能运行在32位保护模式)函数/第一个进程的执行做好准备 | 通过物理地址访问外设 |
| 进程0 | 保护模式 | 内核态 | 初始化内存管理结构、挂接中断服务程序、支持访问硬盘等 | 支持系统调用(中断 ==> 中断处理 ==> 内核)等 | 进程0的task_struct、tss、ldt在代码设计阶段就设置好的 |
| 进程1 | 保护模式 | 用户态 | 安装根文件系统,打开终端设备文件等 | 以文件的形式和外设交流,比如:进程2可以执行bash | |
| 进程2 | 保护模式 | 用户态 | 加载shell程序等 |
2019.4.22补充:其实你看C系Redis源码分析 也是类似,先初始化domain内的各种抽象,然后开始干活,只是linux 的各种“抽象”偏硬件。
redis.c
int main(int argc, char **argv) {
...
// 初始化服务器
initServerConfig();
...
// 将服务器设置为守护进程
if (server.daemonize) daemonize();
// 创建并初始化服务器数据结构
initServer();
...
// 运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
// 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
return 0
}
OS驱动进程执行,中断驱动OS执行
- 操作系统本身是个可执行代码,根据pc的指向执行,特别的是os可以自己更改pc的值(jump命令),所以不同于一般的功能代码。
- 为了支持多任务,os除了提供进程管理数据结构来维护进程的边界外,还必须防止一个进程自high(比如陷入死循环)。而对于一个死循环进程,os是没办法管理的。因此,必须周期性的将控制权移交到os手中。
- 代码是由进程驱动的,操作系统则是由中断驱动的(用户输入引发的IO中断以及时钟中断)。中断有上下文,进程也有上下文,进程和io中断之间以发送和接收缓冲区沟通。
- os会将自己一部分函数挂在中断向量上。中断控制器可编程,彼此会相互影响。也可以说,中断是client,OS是server,OS是挂在中断向量上的中断处理程序的集合。
- 中断相当于硬件的call,因为中断不可预见,自然OS保存不了中断的现场。中断call的上下文由cpu维护,中断和进程的执行是独立的。
从这个角度讲,BIOS和OS都是OS,它们都有中断向量表,但因为BIOS不用支持多任务,所以不需要有GDT,BIOS不需要进程调度,所以不需要时钟。但它们都需要处理磁盘中断,在BIOS退出运行后,汇编程序借助BIOS的磁盘中断程序来加载磁盘上的OS和访问显示器。
现代操作系统最重要的特征——支持实时多任务,所以必然支持保护和分页。笔者在从Go并发编程模型想到的中也提到,我们在编写线程安全代码碰到的一切问题,本源是进程调度引发的进程执行中断。所以,支持多任务是现代操作系统复杂性的根本原因,也是我们理解OS大部分设计意图的出发点。直接体现在进程管理信息数据结构的设计上。
进程管理信息数据结构
本段摘自page43
task_struct
Linux0.11是一个支持多进程的现代操作系统,这就意味着,各个用户进程在运行过程中,彼此不能相互干扰,这样才能保证进程在主机中的正常运算。然而,进程自身并没有一个天然的边界来对其进行保护,要靠系统人为地给他设计一套边界来保护它,这套边界就是系统为进程提供的进程管理信息数据结构。这套进程管理信息数据结构包括:
- 进程管理结构task_struct,task_struct每个进程所独有的结构,标识了进程的各项属性值,包括剩余时间片、进程执行状态、局部数据描述符表LDT和任务状态描述符表TSS(两个表的指针)等。
- 进程槽task[64]
- 全局描述符表GDT,GDT存储着一套针对所有进程的索引结构,通过索引项,系统可以间接地与每个进程的中的LDT和TSS建立关系。
它们都是由于系统对多进程的支持才存在的,如果没有多进程,它们就没有存在的必要了。
GDTR、LDTR、TR
此处,笔者学到的一点是:对于进程切换,以前只考虑切换寄存器的值(即TSS数据),并没有考虑到LDTR、LDT等变化。这部分参见GDT、GDTR、LDT、LDTR的学习
进程最终是要编译成汇编程序(汇编语言到二进制没有复杂的语法解析等)来执行的,一个汇编程序由代码段、数据段和堆栈段等组成。PS:结合硬件对软件设计的影响 又有一点软硬件融合的味道。
| 硬件的支持(从上到下为新增) | 数据结构支持(要硬件参与解析) | 执行步骤 | 备注 | |
|---|---|---|---|---|
| 顺序的二进制程序 | PC寄存器、数据寄存器 | OS根据PC寄存器指向,一步步向下执行 | 数据地址直接写在代码 | |
| 分段程序 | 各种段寄存器 | 多个段寄存器,OS根据es:pc指向,一步步向下运行 | 段内地址可以从0开始 | |
| 多个分段程序 | GDTR、LDTR、TR等 | GDT、LDT、TSS等 | 1. LDTR ==> GDT ==> LDT ==> 数据段、代码段、堆栈段等; 2.TR ==> GDT ==> TSS |
我们可以看到:
- 有了GDTR,系统在初始化时,就不必将GDT置于特定的位置。(IDTR和IDT(中断向量表)的关系也是如此),由此我们可以揣摩一些硬件和OS数据结构的关系:它们协作起来支持某个机制。
- 知道了GDT等是干什么的,就可以顺畅的分析OS启动时为什么要初始化GDT,OS进程初始化时,为什么要设置LDT。
其它
从中可以看到
- 理解了进程管理信息数据结构、保护模式这一套理念后,就可以理解汇编程序(bootsect.s,setup.s,head.s)的大部分工作意图。书中P40的两个问题非常有价值:为什么没有最先调用main函数?为什么加载工作完成后,仍然没有执行main函数,而是打开A20、pe和pg,建立IDT和GDT…,然后才开始执行main函数?
- 从linux0.11看,根文件系统和一般文件系统的区别是,包含一些init可执行文件,比如bash。
- 启动过程就是不停向上抽象的过程。比如,一开始只能通过汇编物理地址访问外设,后来可以文件形式访问外设;一开始用BIOS默认的中断体系,当OS自己的中断体系建立后,就可以软中断提供系统调用。