简介
大神的一份学习笔记 https://github.com/hoanhan101/ultimate-go
Golang 官网的FAQ 也经常会有一些“灵魂追问”的解答。
Language Mechanics
Syntax
Go语言设计有很多硬性规则,这让代码格式化、代码分析、编译、单元测试比较方便。
与常见编程语言的不同之处:
- 变量类型 在变量右侧,https://blog.go-zh.org/gos-declaration-syntax 官方有给出解释,原因简单来说就是和C相比,在当参数是指针的复杂情况下,这种声明格式会相对好理解一点
- Go的赋值方式很多,据说在Go后续的优化中会只支持一种赋值方式。PS:“达成一个目的只允许有一种方法”,就是这么直接。
- iota 是 Go 语言的一个预定义标识符,它表示的是 const 声明块(包括单行声明)中,每个常量所处位置在块中的偏移值(从零开始)。这样我们就可以使用 Go 常量语法来实现枚举常量的定义。
- 赋值可以进行自动类型推断,在一个赋值语句中可以对多个变量进行同时赋值
- Go语言不允许隐式类型转换,别名和原有类型也不能进行隐式类型转换
- 支持指针类型,但不支持指针运算,也不能获取常量的指针,仅能修改指针指向的值。
- Go语言没有前置++,–
- 支持按位清零运算符
&^ - Go语言循环仅支持关键字 for
- 不需要用break 来明确退出一个case,case 可以多项
- 可以不设定switch 之后的条件表达式, 在此种情况下, 整个switch 结构与多个if else 的逻辑作用等同。
- For break and continue, the additional label lets you specify which loop you would like to refer to. For example, you may want to break/continue the outer loop instead of the one that you nested in.
RowLoop: for y, row := range rows { for x, data := range row { if data == endOfRow { break RowLoop } row[x] = data + bias(x, y) } } - go 关键字对应到 java 就像一个无限容量的 Executor,可以随时随地 submit Runable
Data Structures
| go | java | |
|---|---|---|
| list | slice | ArrayList |
| map | map | HashMap |
| 线程安全map | sync.Map | ConcurrentHashMap |
| 对象池 | 对带缓冲的channel进行封装 | commons-pool中的ObjectPool |
golang为什么将method写在类外? go表达的就是函数就是函数,数据就是数据。与数据绑定的函数提供t.foo()这种写法。但也仅此而已了。不要用面向对象语言的思想去学go,用c的思路去学go,golang之所以叫struct不叫class,go没有类,只是模拟它
数组
Deep Dive into Pointers, Arrays & SliceGo’s arrays are values rather than memory address.
var myarr = [...]int{1,2,3}
fmt.Println(myarr)
fmt.Println(&myarr)
//output
[1 2 3] // 打印的时候直接把值给打印出来了
&[1 2 3]
在 Go 中,与 C 数组变量隐式作为指针使用不同,Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。值类型还体现在
- 相同维数且包含相同个数元素的数组才可以比较
- 每个元素都相同的才相等
slice
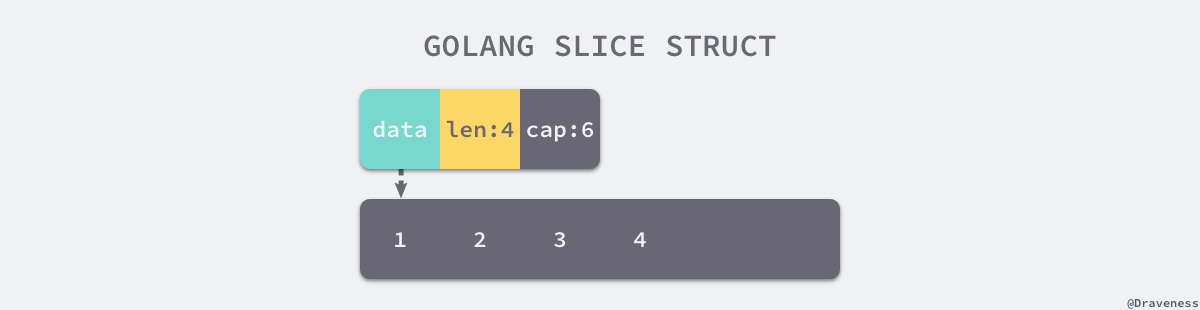
切片与数组的关系非常密切,切片引入了一个抽象层,提供了对数组中部分片段的引用,我们可以在运行区间可以修改它的长度,如果底层的数组长度不足就会触发扩容机制,切片中的数组就会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心底层的数组变化。
// $GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 可以用下标访问的元素个数
cap int // 底层数组长度
}
func makeslice(et *_type, len, cap int) unsafe.Pointer {...}
func makeslice64(et *_type, len64, cap64 int64) unsafe.Pointer {...}
// growslice handles slice growth during append.It is passed the slice element type, the old slice, and the desired new minimum capacity,and it returns a new slice with at least that capacity, with the old data copied into it.
func growslice(et *_type, old slice, cap int) slice {...}
func slicecopy(to, fm slice, width uintptr) int {...}
func slicestringcopy(to []byte, fm string) int {...}
扩容的本质过程:扩容实际上就是重新分配一块更大的内存,将原先的Slice数据拷贝到新的Slice中,然后返回新Slice,扩容后再将数据追加进去。
与java ArrayList相比,slice 本身不提供类似 Add/Set/Remove方法。只有一个builtin 的append和切片功能,因为不提供crud方法,slice 更多作为一个“受体”,与数组更近,与“ArrayList”更远。
// $GOROOT/src/builtin/builtin.go
// The append built-in function appends elements to the end of a slice. If it has sufficient capacity, the destination is resliced to accommodate the new elements. If it does not, a new underlying array will be allocated. Append returns the updated slice. It is therefore necessary to store the result of append, often in the variable holding the slice itself:
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
func append(slice []Type, elems ...Type) []Type
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组(下例中的arr)赋值给一个新的变量 ha,在赋值的过程中就发生了拷贝,所以我们遍历的切片已经不是原始的切片变量(arr)了。
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
之前将java 中的代码优化思路用到了 go 上,以为ss := make([]string, 5) 就是一个预分配了长度为5 的list,go 中这行代码 不仅分配了长度为5的空间,元素也赋值好了。
ss := make([]string, 5)
ss = append(ss, "abc")
fmt.Println(len(strs)) // 输出6
在 Go 语言中,数组更多是“退居幕后”,承担的是底层存储空间的角色。切片之于数组就像是文件描述符之于文件。也正是因为这一特性,切片才能在函数参数传递时避免较大性能开销。因为我们传递的并不是数组本身,而是数组的“描述符”,而这个描述符的大小是固定的
map
与常见编程语言的不同之处:
- 在访问的key不存在时,仍会返回零值,不能通过返回nil 来判断元素是否存在。
-
Map的value 可以是一个方法,与Go的Dock type 方式一起, 可以方便的实现单一方法对象的工厂模式。
m := map[int]func(op int) int{} m[1] = func(op int) int { return op } m[2] = func(op int) int { return op * op } m[3] = func(op int) int { return op * op * op } t.Log(m[1](2), m[2](2), m[3](2)) - Go的内置集合中没有Set实现, 可以
map[type]bool - map 类型对 value 的类型没有限制,但是对 key 的类型却有严格要求,因为 map 类型要保证 key 的唯一性。Go 语言中要求,key 的类型必须支持“==”和“!=”两种比较操作符。
- map 实例不是并发写安全的,也不支持并发读写。Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型
- 考虑到 map 可以自动扩容,map 中数据元素的 value 位置可能在这一过程中发生变化,所以 Go 不允许获取 map 中 value 的地址,这个约束是在编译期间就生效的。
对于slice 来说, index, value 可以视为一个kv
for k,v := range map{}
for i,v := range slice{}
map是由 Go 编译器与运行时联合实现的。Go 编译器在编译阶段会将语法层面的 map 操作,重写为运行时对应的函数调用。语法层面 map 类型变量一一对应的是 runtime.hmap 的实例。
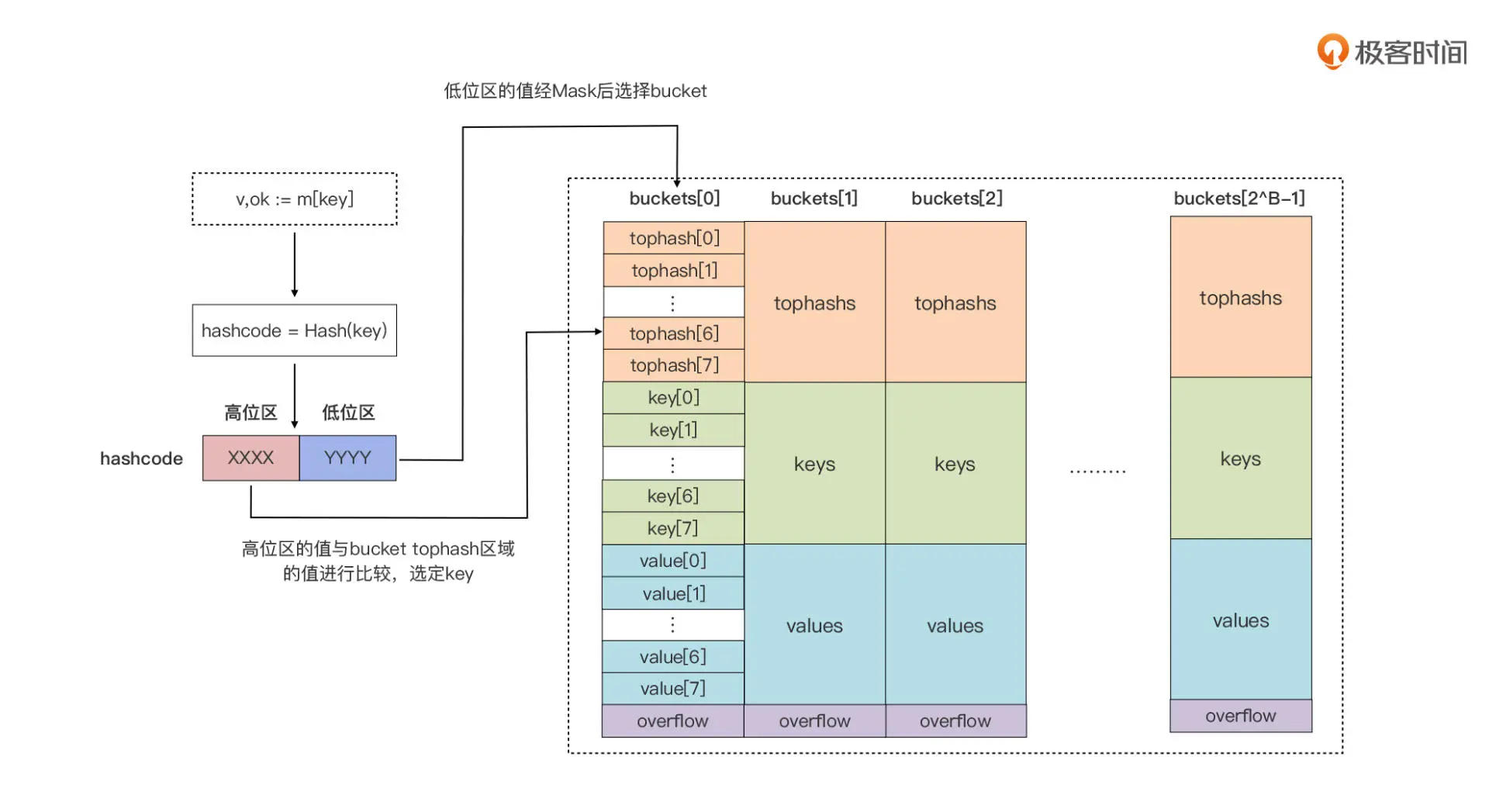
- 与java map 类似,基于 bucket 数组
- 定位
- 对key 做hashcode ,运行时会把 hashcode“一分为二”来看待,其中低位区的值用于选定 bucket,高位区的值用于在某个 bucket 中确定 key 的位置。每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,这样就避免了逐个 key 进行比较这种代价较大的操作。尤其是当 key 是 size 较大的字符串类型时,好处就更突出了。这是一种以空间换时间的思路。PS:有点两次hash的意思
- key 和 value 分开存储,而不是采用一个 kv 接着一个 kv 的 kv 紧邻方式存储,这带来的其实是算法上的复杂性,但却减少了因内存对齐带来的内存浪费。例如,有这样一个类型的 map:
map[int64]int8,如果按照 key/value/key/value/… 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 key/key/…/value/value/…,则只需要在最后添加 padding。 - 当我们声明一个 map 类型变量,比如
var m map[string]int时,Go 运行时就会为这个变量对应的特定 map 类型,生成一个 runtime.maptype 实例。 存储key value 类型及类型大小等信息,用以辅助 key value 的定位
- 如果 key 或 value 的数据长度大于一定数值,那么运行时不会在 bucket 中直接存储数据,而是会存储 key 或 value 数据的指针。
- 对于新老bucket,扩容时 真正的排空和迁移工作是在 assign 和 delete 时逐步进行的。
string
Go原生支持字符串(比如底层结构有专门字段存储字符串长度),string 类型的数据是不可变的,string 是值类型, 其默认初始化值为空字符串,不是nil
// $GOROOT/src/reflect/value.go
// StringHeader是一个string的运行时表示
type StringHeader struct {
Data uintptr // 真实的字符串值数据就存储在一个被 Data 指向的底层数组中
Len int
}
了解了 string 类型的实现原理后,我们还可以得到这样一个结论,那就是我们直接将 string 类型通过函数 / 方法参数传入也不会带来太多的开销。因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。其传递的开销也是恒定的,不会随着字符串大小的变化而变化。PS: go 中都是值传递,是不是可以认为,如果不想因为值传递 copy 太多数据,可以值传递的数据结构 不能直接 包含 指向的数据
与常见编程语言的不同之处:
- string 是数据类型, 不是引用或指针类型
- string 是只读的byte slice,len函数 返回的是byte 数
- string的 byte 数组可以存放任何数据
函数和方法
函数
函数是 Go 代码中的基本功能逻辑单元,它承载了 Go 程序的所有执行逻辑。可以说,Go 程序的执行流本质上就是在函数调用栈中上下流动,从一个函数到另一个函数。
与常见编程语言的不同之处:
- 可以返回多个值
- 所有的参数传递都是值传递:slice,map,channel 会有传引用的错觉
- 函数是一等公民 ==> 对象之间的复杂关系可以由函数来部分替代
- 函数可以作为变量的值
- 函数可以作为参数和返回值
比如通过函数式编程来实现装饰模式,让一个函数具有计时能力
func timeSpent(inner func(op int) int) func(op int) int {
return func(n int) int {
start := time.Now()
ret := inner(n)
fmt.Println("time spent:", time.Since(start).Seconds())
return ret
}
}
嫌弃这个方法定义太长的话可以
type IntConv func(op int) int
func timeSpent(inner IntConv) IntConv {
return func(n int) int {
start := time.Now()
ret := inner(n)
fmt.Println("time spent:", time.Since(start).Seconds())
return ret
}
}
- 调用者 caller 会将参数值写入到栈上,被调用函数 callee 实际上操作的是调用者 caller 栈帧上的参数值。
- 在进行调用指针接收者(pointer receiver)方法调用的时候,实际上是先复制了结构体的指针到栈中,然后在方法调用中全都是基于指针的操作。
方法
接收者的本质
方法带不带指针:(p *Person) refers to a pointer to the created instance of the Person struct. it is like using the keyword this in Java or self in Python when referring to the pointing object.
(p Person) is a copy of the value of Person ia passed to the function. any change that you make in p if you pass it by value won’t be reflected in source p. C++ 中的对象在调用方法时,编译器会自动传入指向对象自身的 this 指针作为方法的第一个参数。Go 语言中的方法的本质就是,一个以方法的 receiver 参数作为第一个参数的普通函数。这种等价转换是由 Go 编译器在编译和生成代码时自动完成的。
在一些框架代码中,会将指针接收者命名为 this,很有感觉
func (this *Person)GetFullName() string{
return fmt.Println("%s %s",this.Name,this.Surname)
}
值接收者和指针接收者
结构体方法是要将接收器定义成值,还是指针。这本质上与函数参数应该是值还是指针是同一个问题。
func (p *Person)GetFullName() string{
return fmt.Println("%s %s",p.Name,p.Surname)
}
func (p Person)GetFullName() string{
return fmt.Println("%s %s",p.Name,p.Surname)
}
func GetFullName(p *Person) string{
return fmt.Println("%s %s",p.Name,p.Surname)
}
func GetFullName(p Person) string{
return fmt.Println("%s %s",p.Name,p.Surname)
}
深度解密Go语言之关于 interface 的 10 个问题如果实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的方法。方法集合在 Go 语言中的主要用途就是判断某个类型是否实现了某个接口。*T 类型的方法集合包含所有以 *T 为 receiver 参数类型的方法,以及所有以 T 为 receiver 参数类型的方法。
选择 receiver 参数类型的原则
- 如果 Go 方法要把对 receiver 参数代表的类型实例的修改,反映到原类型实例上,那么我们应该选择 *T 作为 receiver 参数的类型。
- 如果 receiver 参数类型的 size 较大,以值拷贝形式传入就会导致较大的性能开销,这时我们选择 *T 作为 receiver 类型可能更好些
- T 类型是否需要实现某个接口。比如demo 中,T 没有实现 Interface 类型方法列表中的 M2,因此类型 T 的实例 t 不能赋值给 Interface 变量。
type Interface interface { M1() M2() } type T struct{} func (t T) M1() {} func (t *T) M2() {} func main() { var t T var pt *T var i Interface i = pt i = t // cannot use t (type T) as type Interface in assignment: T does not implement Interface (M2 method has pointer receiver) }
Error Handling
「错误」一词在不同编程语言中存在着不同的理解和诠释。 在 Go 语言里,错误被视普普通通的 —— 值。
import errors
err := errors.New(xx)
err := fmt.Errorf(xx)
import github.com/pkg/errors
err := errors.New(xx) // error 包含stack trace
与常见编程语言的不同之处:
- 没有异常机制。之前的语言 函数只支持一个返回值, 业务逻辑返回与错误返回会争用这一个“名额”,后来支持抛异常,算是解决了“争用”,但大量的try catch 引入了新的问题(至少Go作者不喜欢)。Go 支持了多返回值,从另一种视角解决了业务逻辑返回与错误返回“争用”问题。
- 不像java 单独把Exception 拎出来说事儿。错误 error 在 Go 中表现为一个内建的接口类型,任何实现了
Error() string方法的类型都能作为 error 类型进行传递,成为错误值。// $GOROOT/src/builtin/builtin.go type interface error { Error() string } - 可以通过
errors.New和fmt.Errorf来快速创建错误实例。 但它们给错误处理者提供的错误上下文(Error Context)只限于以字符串形式呈现的信息,这也就意味着,错误值构造方不经意间的一次错误描述字符串的改动,都会造成错误处理方处理行为的变化,并且这种通过字符串比较的方式,对错误值进行检视的性能也很差。 - 可以在代码中预创建一些错误
var LessThanTwoError = errors.New("n should be not less than 2"),以便比对和复用。 不过,对于 API 的开发者而言,暴露“哨兵”错误值也意味着这些错误值和包的公共函数 / 方法一起成为了 API 的一部分。一旦发布出去,开发者就要对它进行很好的维护。而“哨兵”错误值也让使用这些值的错误处理方对它产生了依赖。 - 在一些场景下,错误处理者需要从错误值中提取出更多信息,帮助他选择错误处理路径,显然这两种方法就不能满足了。这个时候,我们可以自定义错误类型来满足这一需求。
// $GOROOT/src/net/net.go type OpError struct { Op string Net string Source Addr Addr Addr Err error } - 也可以将某个包中的错误类型归类,统一提取出一些公共的错误行为特征,并将这些错误行为特征放入一个公开的接口类型中。
// $GOROOT/src/net/net.go type Error interface { error Timeout() bool Temporary() bool }
常见的策略包含哨兵错误、自定义错误以及隐式错误三种。
- 哨兵错误,通过特定值表示成功和不同错误,依靠调用方对错误进行检查
if err === ErrSomething { return errors.New("EOF") },这种错误处理的方式引入了上下层代码的依赖,如果被调用方的错误类型发生了变化, 则调用方也需要对代码进行修改。为了安全起见,变量错误类型可以修改为常量错误 - 自定义错误,
if err, ok := err.(SomeErrorType); ok { ... }, 这类错误处理的方式通过自定义的错误类型来表示特定的错误,同样依赖上层代码对错误值进行检查, 不同的是需要使用类型断言进行检查。好处在于,可以将错误包装起来,提供更多的上下文信息, 但错误的实现方必须向上层公开实现的错误类型,不可避免的同样需要产生依赖关系。 - 隐式错误,
if err != nil { return err },直接返回错误的任何细节,直接将错误进一步报告给上层。这种情况下, 错误在当前调用方这里完全没有进行任何加工,与没有进行处理几乎是等价的, 这会产生的一个致命问题在于:丢失调用的上下文信息,如果某个错误连续向上层传播了多次, 那么上层代码可能在输出某个错误时,根本无法判断该错误的错误信息究竟从哪儿传播而来。
error 可以嵌套,比如 err2 := fmt.Errorf("wrap err1: %w", err1)。从 Go 1.13 版本开始,
- 标准库 errors 包提供了 Is 函数用于错误处理方对错误值的检视。如果 error 类型变量的底层错误值是一个包装错误(Wrapped Error),errors.Is 方法会沿着该包装错误所在错误链(Error Chain),与链上所有被包装的错误(Wrapped Error)进行比较,直至找到一个匹配的错误为止。
// 类似 if err == ErrOutOfBounds{ … } if errors.Is(err, ErrOutOfBounds) { // 越界的错误处理 } - 标准库 errors 包提供了As函数给错误处理方检视错误值。As函数类似于通过类型断言判断一个 error 类型变量是否为特定的自定义错误类型,如下面代码所示:
// 类似 if e, ok := err.(*MyError); ok { … } var e *MyError if errors.As(err, &e) { // 如果err类型为*MyError,变量e将被设置为对应的错误值 }
我们在一个项目中使用错误机制,最核心的几个需求是:附加信息;附加堆栈。官方的 error 库传递的信息太少一直是被诟病的一点,推荐在应用层使用 github.com/pkg/errors 来替换官方的 error 库,fmt 包在打印 error 之前会判断当前打印的对象是否实现了 Formatter 接口,而 github.com/pkg/errors 中提供的各种初始化 error 方法(包括 errors.New)封装了一个 fundamental 结构,这个结构就是实现了 Formatter 接口。
Go Test 和 Benchmark
我们测试一个函数的功能,就必须要运行该函数,而这往往是由main函数开始触发的。在大型项目中,测试一个函数的功能,总是劳驾main函数很不方便,于是我们可以使用go test功能。
假设存在a.go文件(文件中包含Add方法),我们只要在相同目录下创建a_test.go文件,在该目录下运行go test即可。(这将运行该目录下所有”_test”后缀文件中的带有“Test”前缀的方法)
package main
import (
"fmt"
"testing"
)
// 功能测试
func TestAdd(t *testing.T) {
t.Log("hello","world")
re := Add(3,4)
if re != 7{
t.Error("error")
}
assert.Equal(re,7)
}
// 性能测试
func BenchmarkAdd(b *testing.B) {
b.ResetTimer()
...// 测试代码
b.StopTimer()
}
