简介
Kubernetes应用管理深度剖析以分布式系统为代表的有状态应用,并不像Web应用一样“开箱即用”,这些系统需要特定应用领域的知识才能正确扩展,升级和重新配置,同时防止数据丢失或不可用。Operator 其实并不是一个工具,而是为了解决一个问题而存在的一个思路,将特定于应用程序的操作知识编码到软件中,利用功能强大的Kubernetes抽象来正确地运行和管理应用程序。
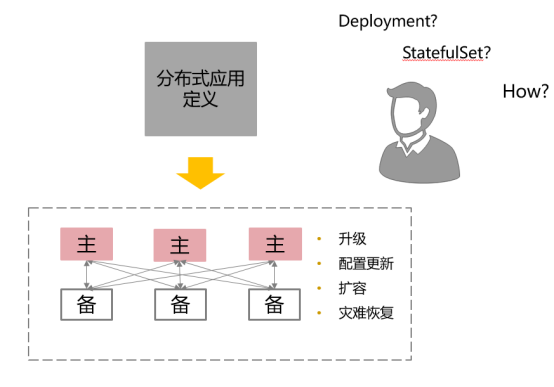
Operator 是使用自定义资源(CR,本人注:CR 即 Custom Resource,是 CRD 的实例)管理应用及其组件的自定义 Kubernetes 控制器。高级配置和设置由用户在 CR 中提供。Kubernetes Operator 基于嵌入在 Operator 逻辑中的最佳实践,将高级指令转换为低级操作。Kubernetes Operator 监视 CR 类型并采取特定于应用的操作,确保当前状态与该资源的理想状态相符。
- 什么是低级操作? 假设我们要部署一套 Elasticsearch 集群,通常要在 StatefulSet 中定义相当多的细节,比如服务的端口、Elasticsearch 的配置、更新策略、内存大小、虚拟机参数、环境变量、数据文件位置等等,里面的细节配置非常多。根本原因在于 Kubernetes 完全不知道 Elasticsearch 是个什么东西,所有 Kubernetes 不知道的信息、不能启发式推断出来的信息,都必须由用户在资源的元数据定义中明确列出,必须一步一步手把手地“教会”Kubernetes 部署 Elasticsearch,这种形式就属于咱们刚刚提到的“低级操作”。PS:YAML Engineer
- 有了 Elasticsearch Operator 的CR,就相当于 Kubernetes 已经学会怎样操作 Elasticsearch 了。知道了所有它相关的参数含义与默认值,就不需要用户再手把手地教了,这种就是所谓的“高级指令”。
```yaml
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch-cluster
spec:
version: 7.9.1
nodeSets:
- name: default count: 3 config: node.master: true node.data: true node.ingest: true node.store.allow_mmap: false ```
Operator 将简洁的高级指令转化为 Kubernetes 中具体操作的方法,跟 Helm 或 Kustomize 的思路并不一样:
- Helm 和 Kustomize 最终仍然是依靠 Kubernetes 的内置资源,来跟 Kubernetes 打交道的,是一种标准化的普适性工具,把你的 K8S 资源模板化,yaml资源定义与配置分离,方便共享,进而在不同的配置中重用。
- Operator 则是要求开发者自己实现一个专门针对该自定义资源的控制器,在控制器中维护自定义资源的期望状态,以便自动化管理。Operator与特定应用是一对一的关系。
Helm与Operator并不是完全独立的,很多Operator能做的事情,如应用集群初始化配置、监控更新等通过一些init Container,以及Helm的Hook机制等,最终也能够达到同等效果。只不过这些配置可能显得极为复杂且不易维护,得不偿失;此外,两者还可能有结合的场景,比如市面上很多开源项目的Operator本身就是通过Helm进行部署和管理的。
operator 本质上不创造和提供新的服务,它只是已有 Kubernetes pod/service 等的组合(也是依靠 Kubernetes 的内置资源),但这种“抽象”大大简化了运维操作,否则这些逻辑都要由上层发布系统实现。通过程序编码来扩展 Kubernetes,比只通过内置资源来与 Kubernetes 打交道要灵活得多。比如,在需要更新集群中某个 Pod 对象的时候,由 Operator 开发者自己编码实现的控制器,完全可以在原地对 Pod 进行重启,不需要像 Deployment 那样,必须先删除旧 Pod,然后再创建新 Pod。
Kubernetes 集群真正的能力(mount目录、操作GPU等)要通过 Kubelet 去支持。
内涵
kube-native way of managing the lifecycle of service in Kubernetes
An Operator is a method of packaging, deploying and managing a Kubernetes application. A Kubernetes application is an application that is both deployed on Kubernetes and managed using the Kubernetes APIs and kubectl tooling.
An Operator is an application-specific controller that extends the Kubernetes API to create, configure and manage instances of complex stateful applications on behalf of a Kubernetes user. It builds upon the basic Kubernetes resource and controller concepts, but also includes domain or application-specific knowledge to automate common tasks better managed by computers.
Redis Enterprise Operator for Kuberneteskube-native way of managing the lifecycle of service in Kubernetes:Although Kubernetes is good at scheduling resources and recovering containers gracefully from a failure, it does not have primitives that understand the internal lifecycle of a data service.
使用etcd-operator在集群内部署etcd集群Operator 本身在实现上,其实是在 Kubernetes 声明式 API 基础上的一种“微创新”。它合理的利用了 Kubernetes API 可以添加自定义 API 类型的能力,然后又巧妙的通过 Kubernetes 原生的“控制器模式”,完成了一个面向分布式应用终态的调谐过程。
| spring | kubernetes | |
|---|---|---|
| 核心 | ioc模式 | 声明式api + controller模式 |
| 常规使用 | <bean> FactoryBean等 |
pod 及之上扩展的deployment等 |
| 扩展 | 自定义namespace及NamespaceHandler | CRD |
| 微创新 | 比如整合rabbitmq <rabbit:template> |
etcd/redis operator |
Linux 提供了一个 vfs 接口,任何资源都是File, 提供Open/Close/Create/Read/Write 5个基本api, 从linux 内置文件、Socket 到外设的各种显示器、键盘、鼠标 都统一到一个vfs体系之下。 PS:开发提供一个fs驱动,用户就可以通过读写文件实现特定的业务逻辑,比如cgroup/内存文件系统/网络通信/共享文件系统等。
| Linux vfs | Kubernetes 控制器模式 | |
|---|---|---|
| 作用 | 管理文件、网络和“外设” | 管理builtin 及Custom Resource |
| 理念 | 一切皆文件 | 一切皆Resource |
| 注册 | 注册设备到vfs | 注册API 到apiserver |
| 差异化 | 驱动程序 比如文件的Open和Socket Open操作就不同 |
Controller |
分布式系统的标准化交付
当我们聊 Kubernetes Operator 时,我们在聊些什么
如果说 Docker 是奠定的单实例的标准化交付,那么 Helm 则是集群化多实例、多资源的标准化交付。
Operator 则在实现自动化的同时实现了智能化。其主要的工作流程是根据当前的状态,进行智能分析判断,并最终进行创建、恢复、升级等操作。而位于容器中的脚本,因为缺乏很多全局的信息,仅靠自身是无法无法达实现这些全部的功能的。而处于第三方视角的 Operator,则可以解决这个问题。他可以通过侧面的观察,获取所有的资源的状态和信息,并且跟预想 / 声明的状态进行比较。通过预置的分析流程进行判断,从而进行相应的操作,并最终达到声明状态的一个目的。这样所有的运维逻辑就从镜像中抽取出来,集中到 Operator 里去。层次和逻辑也就更加清楚,容易维护,也更容易交付和传承。
以往的高可用、扩展收缩,以及故障恢复等等运维操作,都通过 Operator 进行沉淀下来。从长期来看,将会推进 Dev、Ops、DevOps 的深度一体化。将运维经验、应用的各种方案和功能通过代码的方式进行固化和传承,减少人为故障的概率,提升整个运维的效率。Controller 和 Operator 的关系有点类似于标准库和第三方库的关系
原理
Kubernetes Operator 快速入门教程以定制化开发一个 AppService 为例,描述了从零创建一个AppService Operator 的过程
apiVersion: app.example.com/v1
kind: AppService
metadata:
name: nginx-app
spec:
size: 2
image: nginx:1.7.9
ports:
- port: 80
targetPort: 80
nodePort: 30002
脚手架
部署
Operator patternThe most common way to deploy an Operator is to add the Custom Resource Definition and its associated Controller to your cluster. The Controller will normally run outside of the control plane, much as you would run any containerized application. For example, you can run the controller in your cluster as a Deployment. Operator Controller 物理存在是一个bin文件,将Operator 以Deployment/容器的方式 运行在Kubernetes 集群中,无需更改Kubernetes 本身。
我们都知道在 Kubernetes 上安装应用可以使用 Helm 直接安装各种打包成 Chart 形式的 Kubernetes 应用,但随着 Kubernetes Operator 的流行,Kubernetes 社区又推出了 OperatorHub,你可以在这里分享或安装 Operator:https://www.operatorhub.io。
示例
在k8s上部署一个etcd
有几种方法
- 找一个etcd image,组织一个pod,进而写一个 deployment.yaml,kubectl apply 一下
- 使用helm
- kubernetes operator etcd Operator。
apiVersion: etcd.database.coreos.com/v1beta2 kind: EtcdCluster metadata: name: example spec: size: 3 version: 3.2.13
使用etcd operator 有一个比较好玩的地方,仅需调整 size 和 version 配置,就可以控制etcd cluster 个数和版本,比第一种方法方便的多了。
redis
网易有道Redis云原生实战 在operator 中处理掉哨兵/集群模式、持久化、 节点故障、 迁移、扩缩容等问题。
apiVersion: Redis.io/v1beta1
kind: RedisCluster
metadata:
name: my-release
spec:
size: 3
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 1000m
memory: 1Gi
config:
maxclients: "10000"
微服务
来看一个Operator的示例:基于Operator 实现微服务的运维 MicroServiceDeploy 的 CR(custom resource)
apiVersion: custom.ops/v1
kind: MicroServiceDeploy
metadata:
name: ms-sample-v1s0
spec:
msName: "ms-sample" # 微服务名称
fullName: "ms-sample-v1s0" # 微服务实例名称
version: "1.0" # 微服务实例版本
path: "v1" # 微服务实例的大版本,该字符串将出现在微服务实例的域名中
image: "just a image url" # 微服务实例的镜像地址
replicas: 3 # 微服务实例的 replica 数量
autoscaling: true # 该微服务是否开启自动扩缩容功能
needAuth: true # 访问该微服务实例时,是否需要租户 base 认证
config: "password=88888888" # 该微服务实例的运行时配置项
creationTimestamp: "1535546718115" # 该微服务实例的创建时间戳
resourceRequirements: # 该微服务实例要求的机器资源
limits: # 该微服务实例会使用到的最大资源配置
cpu: "2"
memory: 4Gi
requests: # 该微服务实例至少要用到的资源配置
cpu: "2"
memory: 4Gi
idle: false # 是否进入空载状态
以上一个 resource 实际上创建了很多其他的 Kubernetes resource,这些 Kubernetes resource 才真正构成了该微服务实际的能力
- 对于一个微服务而言必备的 Service, ServiceAccount 和 Deployment。
- 代表运行时配置项的ConfigMap
- 资源管理 ResourceQuota
- HPA自动扩缩容