简介
从容错性强弱的角度来串一下一致性协议
从容错性角度来串一下一致性协议
| 表现 | 算法 | |
|---|---|---|
| 无法容错 | XA/TCC | 当然,也可以采用一些补偿机制稍稍 容忍些超时类的问题 |
| 非拜占庭错误 | 节点故障或网络不通,只是收不到它的消息了,而不会收到来自它的错误消息。相反,只要收到了来自它的消息,那么消息本身是「忠实」的。 | paxos |
| 拜占庭错误 | 1. 叛徒的恶意行为,在不同的将军看来,叛徒可能发送完全不一致的作战提议。 2. 虽然并非恶意,出现故障(比如信道不稳定)导致的随机错误或消息损坏 |
|
| 拜占庭将军问题 | 叛徒发送前后不一致的作战提议,属于拜占庭错误; 而不发送任何消息,属于非拜占庭错误。 |
BTF |
BFT的算法应该可以解决任何错误下的分布式一致性问题,也包括Paxos所解决的问题。那为什么不统一使用BFT的算法来解决所有的分布式一致性问题呢?为什么还需要再费力气设计Paxos之类的一些算法呢?
- 提供BFT这么强的错误容忍性,肯定需要付出很高的代价。比如需要消息的大量传递。
- 对于运行环境的假设(assumption),具体到Lamport在论文中给出的解决「拜占庭将军问题」的算法,它还对运行环境的假设(assumption)有更强的要求。比如BTF 有一条: The absence of a message can be detected ==> 依赖某种超时机制 ==> 各节点时钟同步 ==> 同步模型。
一致性算法
下面看下 《区块链核心算法解析》 中的思维线条
-
两节点
- 客户端服务端,如何可靠通信?如何处理消息丢失问题
- 请求-确认,客户端一段时间收不到 确认则重发,为数据包标记序列号解决重发导致的重复包问题。这也是tcp 的套路
- 单客户端-多服务端
-
多客户端-多服务端
- 多服务端前 加一个 单一入口(串行化器), 所以的客户端先发给 串行化器,再分发给服务端。即主从复制思路==> 串行化器单点问题
-
客户端先协调好,由一个客户端发命令
- 抽取独立的协调器。2pc/3pc 思路
- 客户端向所有的服务端申请锁,谁先申请到所有服务器的锁,谁说了算。缺点:客户端拿到锁后宕机了,尴尬!
- 票的概念,弱化形式的锁。paxos 套路(当然,具体细节更复杂)
- 广播多轮投票。随机共识算法,不准确描述:假设只对01取得共识,第一轮每个节点随机选定一个值,广播给其它所有节点,节点收到超过半数其它节点的值,如果恰好是同一个值,则节点改变自己本轮的“意见”,重新广播该值。
tips
- paxos 无法保证确定性,即理论上存在一直无法达成一致、不停地投票的情况
- paxos/随机共识算法等 假定 参与节点都按规则 运行
- 《分布式协议与算法实战》Basic Paxos 实现了容错,在少于一半的节点出现故障时,集群也能工作。它不像分布式事务算法那样,必须要所有节点都同意后才提交操作,因为“所有节点都同意”这个原则,在出现节点故障的时候会导致整个集群不可用。
基于拜占庭节点的一致性
漫谈分布式系统、拜占庭将军问题与区块链拜占庭节点:节点可能不按规则行事,甚至故意发送错误数据,多个拜占庭节点也可能串谋。
基于拜占庭节点达成共识
- 拜占庭容错(BFT)算法,一系列算法的统称。网络中节点的数量和身份必须是提前确定好的
-
POW,间接共识,先选谁说了算,再达成共识。
- 这个算法具有不对称性,也就是说,工作对于请求方是有难度的,对于验证方则是比较简单的,易于验证的。
- 计算出符合条件的哈希值后,矿工就会把这个信息广播给集群中所有其他节点,其他节点验证通过后,会将这个区块加入到自己的区块链中,最终形成一串区块链
- 如果攻击者掌握了较多的算力,能挖掘一条比原链更长的攻击链,并将攻击链向全网广播,这时呢,按照约定,节点将接受更长的链,也就是攻击链,丢弃原链。
解决拜占庭问题,笔者感觉有几个点
- 消息签名:签名消息约束了叛徒的作恶行为,比如,叛徒可以不响应,可以相互勾结串通,但叛徒无法篡改和伪造忠将的消息。
- 广播和转发,一个将军的命令发给所有其它将军,A将收到的B 将军的信息也转发给其他所有将军。从信息论的角度来说,就是信息尽可能的冗余。熵是对不确定性的度量。从控制论的角度来看,应叫不确定性。当我们不知道某事物具体状态,却知道它有几种可能性时,显然,可能性种类愈多,不确定性愈大。不确定性愈大的事物,我们最后确定了、知道了,这就是说我们从中得到了愈多的信息,也就是信息量大。
区块链采取的解决方案是工作量证明。一台服务器要想在分布式集群中记录数据(即所谓分布式记账),必须进行一个规模庞大的计算,比如计算一个 256Bit 的 hash 值,这个值的前若干位必须为 0。比特币区块链就是采用类似这样的工作量证明算法,为了进行这样的 hash 计算,目前比特币区块链消耗的电量相当于一个中等规模国家的用电量。通过这种工作量证明方式,保证了恶意服务器要想伪造篡改数据,必须拥有强大的计算能力(占整个集群服务器计算能力的 51% 以上),而只要我们认为大多数服务器是善意的,那么这样的区块链分布式集群就是可靠的。
区块链到底是什么?有人说是个无法篡改的超级账本,也有人说是个去中心化的交易系统,还有人说它是构建数字货币的底层工具。但是,从技术的角度来说,它首先是个解决了拜占庭将军问题的分布式网络,在完全开放的环境中,实现了数据的一致性和安全性。而其它的属性,都附着于这一技术本质之上。
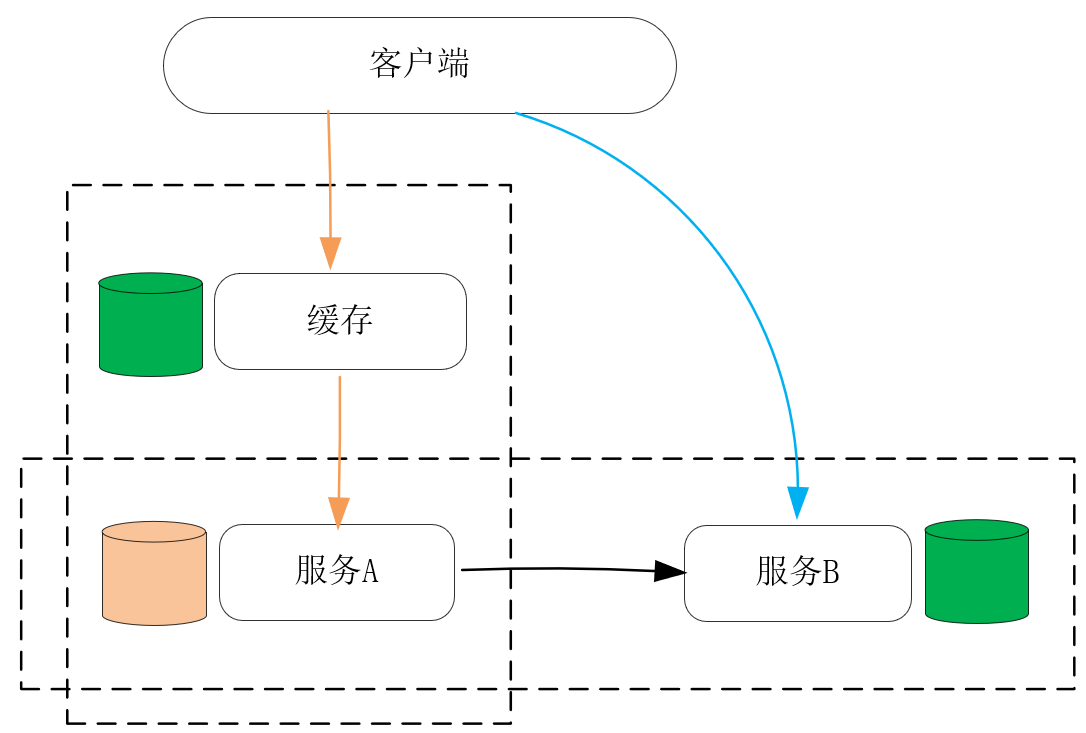
怎样舍弃一致性提升性能?
服务的性能,主要体现在请求的时延和系统的并发性这两个方面,我通常会把分布式系统分为纵向、横向两个维度,其中纵向是请求的处理路径,横向则是同类服务之间的数据同步路径。这样,在纵向上在离客户端更近的位置增加数据的副本,并把它存放在处理速度更快的物理介质上,就可以作为缓存降低请求的时延;而在横向上对数据增加副本,并在这些主机间同步数据,这样工作在数据副本上的进程也可以同时对客户端提供服务,这就增加了系统的并发性。