简介
本文主要来自极客时间《深入浅出计算机组成原理》,相关书籍《编码:隐匿在计算机软硬件背后的语言》
从电路开始讲计算机底层实现原理 有几个gif非常贴切。
- 门电路——信号的关联
- 加法器——信号的计算
- 时钟——信号的震荡
- RAM——保存信号
- 程序——自动化。控制单元该怎么实现呢?只要给定输入信号,约定输出信号,任何组件都可以造出来。PS:信号的流动
入门
一些比较有意思的表述:
- 存放在内存里的程序和数据,需要被 CPU 读取,CPU 计算完之后,还要把数据写回到内存。然而 CPU 不能直接插到内存上,反之亦然。于是,就带来了最后一个大件——主板。主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。芯片组控制了数据传输的流转,也就是数据从哪里到哪里的问题。总线则是实际数据传输的高速公路。因此,总线速度(Bus Speed)决定了数据能传输得多快。
- 手机里只有 SD 卡(Secure Digital Memory Card)这样类似硬盘功能的存储卡插槽,并没有内存插槽、CPU 插槽这些东西。没错,因为手机尺寸的原因,手机制造商们选择把 CPU、内存、网络通信,乃至摄像头芯片,都封装到一个芯片,然后再嵌入到手机主板上。这种方式叫 SoC,也就是 System on a Chip(系统芯片)。
- 冯·诺依曼体系结构(Von Neumann architecture),也叫存储程序计算机。
- 可编程。计算机是由各种门电路组合而成的,然后通过组装出一个固定的电路板,来完成一个特定的计算程序。一旦需要修改功能,就要重新组装电路。这样的话,计算机就是“不可编程”的。计算器的本质是一个不可编程的计算机
- 存储。一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。程序本身是存储在计算机的内存里,可以通过加载不同的程序来解决不同的问题。
任何一台计算机的任何一个部件都可以归到运算器、控制器、存储器、输入设备和输出设备中,而所有的现代计算机也都是基于这个基础架构来设计开发的。具体来说,学习组成原理,其实就是学习控制器、运算器、内存的工作原理。PS:这就叫框定了模型
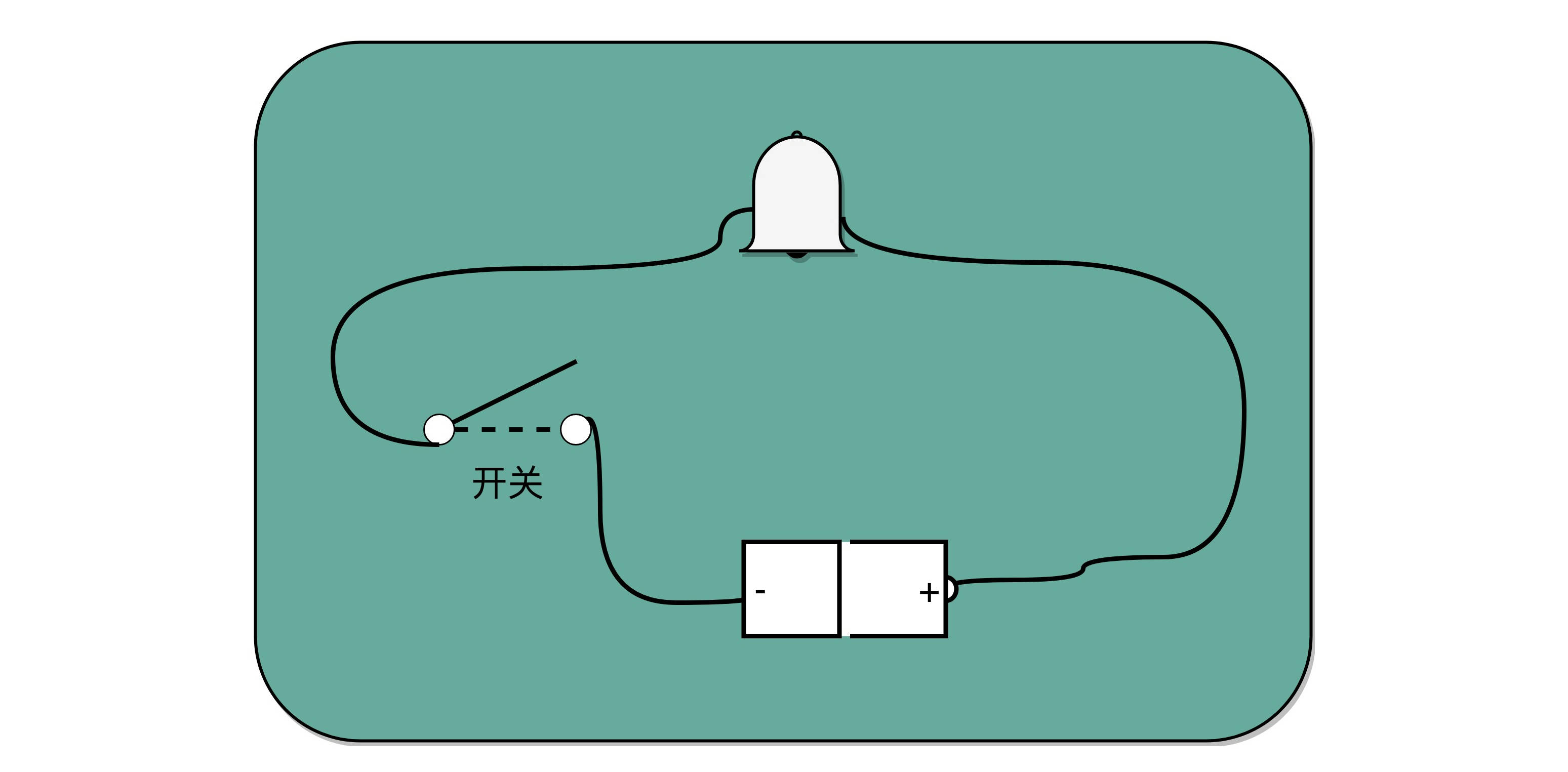
电报是现代计算机的一个最简单的原型
制造一台电报机非常容易。电报机本质上就是一个“蜂鸣器 + 长长的电线 + 按钮开关”。蜂鸣器装在接收方手里,开关留在发送方手里。双方用长长的电线连在一起。当按钮开关按下的时候,电线的电路接通了,蜂鸣器就会响。短促地按下,就是一个短促的点信号;按的时间稍微长一些,就是一个稍长的划信号。有了电报机,只要铺设好电报线路,就可以传输我们需要的讯息了。
虽然一个按钮开关的电报机很“容易”操作,但是却不“方便”操作。因为电报员要熟记每一个字母对应的摩尔斯电码,并且需要快速按键来进行输入,一旦输错很难纠正。但是,因为电路之间可以通过与、或、非组合完成更复杂的功能,我们完全可以设计一个和打字机一样的电报机,每按下一个字母按钮,就会接通一部分电路,然后把这个字母的摩尔斯电码输出出去。
cpu 四大基本电路
CPU 也可以想象成我们熟悉的软件,一样能抽象成几大模块,然后再进行模块化开发。其实 CPU 其实就是一些简单的门电路像搭积木一样搭出来的。从最简单的门电路,搭建成半加器、全加器,然后再搭建成完整功能的 ALU。这些电路里呢,有完成各种实际计算功能的组合逻辑电路,也有用来控制数据访问,创建出寄存器和内存的时序逻辑电路。
- 组合逻辑电路。ALU 的功能就是在特定的输入下,没有状态的,根据组合电路的逻辑,生成特定的输出。
- 锁存器和 D 触发器电路。我们需要有一个电路,能够存储到上一次的计算结果。这个计算结果并不一定要立刻拿到电路的下游去使用,但是可以在需要的时候拿出来用。这也是现代计算机体系结构中的“冯·诺伊曼”机的一个关键,就是程序需要可以“存储”,而不是靠固定的线路连接或者手工拨动开关,来实现计算机的可存储和可编程的功能。
- 计数器电路。需要有一个“自动”的电路,按照固定的周期,不停地实现 PC 寄存器自增,自动地去执行“取指令 - 指令译码 - 执行指令“的步骤。我们的程序执行,并不是靠人去拨动开关来执行指令的。我们希望有一个“自动”的电路,不停地去一条条执行指令。
- 译码器电路。我们需要有一个“译码”的电路。无论是对于指令进行 decode,还是对于拿到的内存地址去获取对应的数据或者指令,我们都需要通过一个电路找到对应的数据。
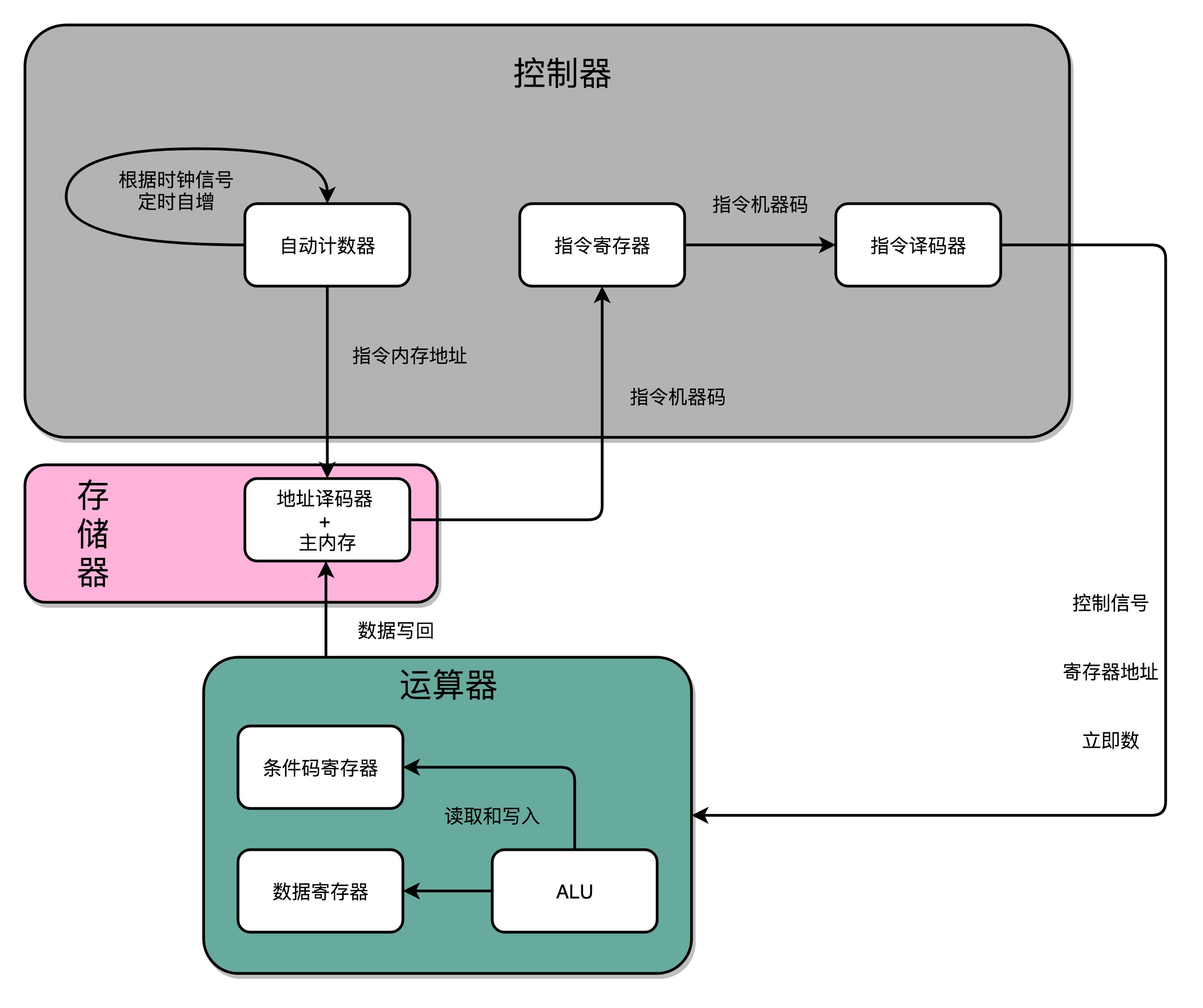
把这四类电路,通过各种方式组合在一起,就能最终组成功能强大的 CPU 了。我们通过一个自动计数器的电路,来实现一个PC寄存器,不断生成下一条要执行的计算机指令的内存地址,然后通过地址译码器,从内存里读出对应的指令,写入到D触发器实现的指令寄存器中,再通过另外一个指令译码器,把它解析成我们需要执行的指令和操作数的地址,这些就是计算器中的控制器。我们把opcode和对应的操作数,发送给ALU进行计算,得到计算结果,再写回到寄存器以及内存里,这就是运算器。时钟信号,则提供了协调这样一条条指令的执行时间和先后顺序的机制。PS:每一个电路又都是几个基本电路的组合,比如 基本电路>门电路>全加器>加法器
在最简单的情况下,我们需要让每一条指令,从程序计数,到获取指令、执行指令,都在一个时钟周期内完成。如果 PC 寄存器自增地太快,程序就会出错。因为前一次的运算结果还没有写回到对应的寄存器里面的时候,后面一条指令已经开始读取里面的数据来做下一次计算了。这个时候,如果我们的指令使用同样的寄存器,前一条指令的计算就会没有效果,计算结果就错了。在这种设计下,我们需要在一个时钟周期里,确保执行完一条最复杂的 CPU 指令,也就是耗时最长的一条 CPU 指令。这样的 CPU 设计,我们称之为单指令周期处理器(Single Cycle Processor)。
基本电路的基本电路
开关 A,一开始是断开的,由我们手工控制;另外一个开关 B,一开始是合上的,磁性线圈对准一开始就合上的开关 B。于是,一旦我们合上开关 A,磁性线圈就会通电,产生磁性,开关 B 就会从合上变成断开。一旦这个开关断开了,电路就中断了,磁性线圈就失去了磁性。于是,开关 B 又会弹回到合上的状态。
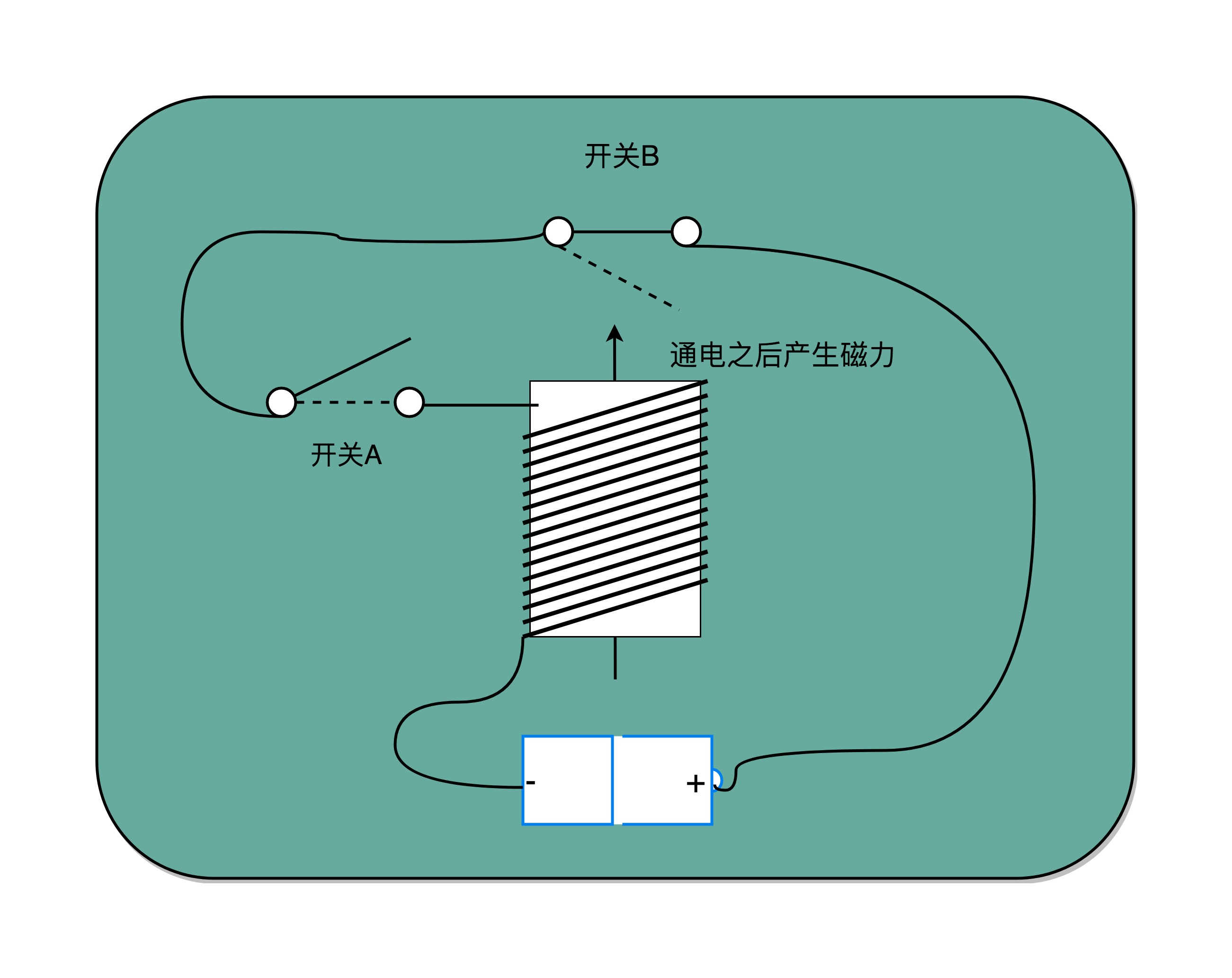
开关 A 闭合(也就是相当于接通电路之后),开关 B 就会不停地在开和关之间切换,这个不断切换的过程,对于下游电路来说,就是不断地产生新的 0 和 1 这样的信号。如果你在下游的电路上接上一个灯泡,就会发现这个灯泡在亮和暗之间不停切换。
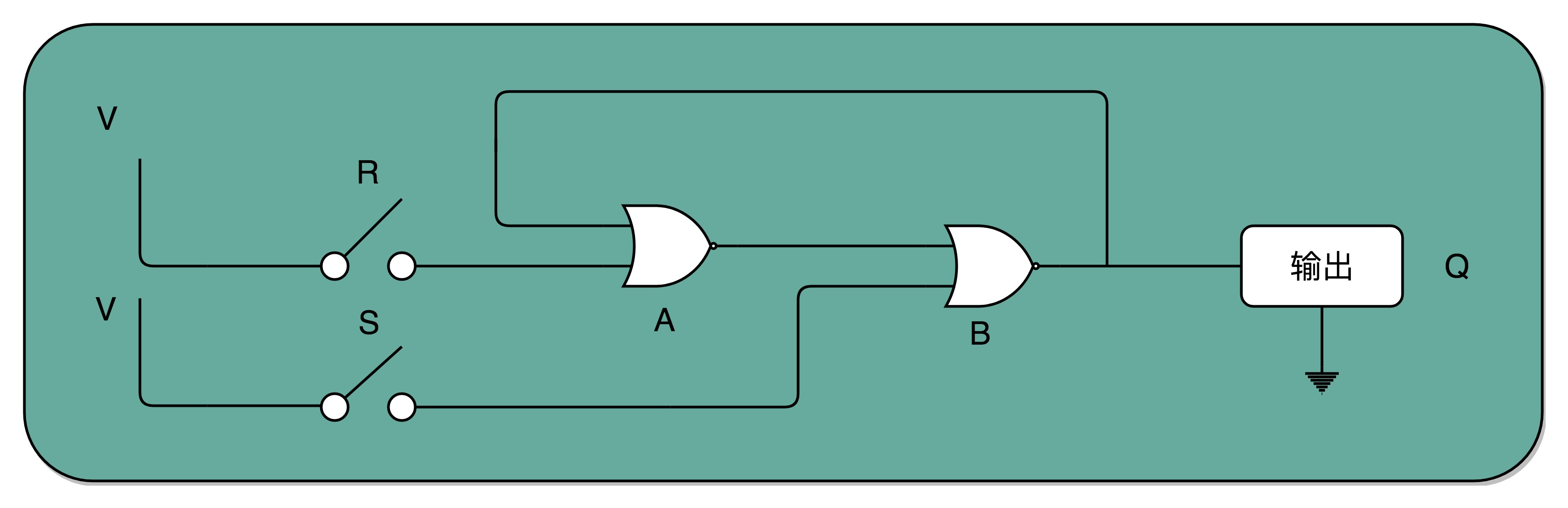
R-S 触发器
- 接通开关 R,输出变为 1,即使断开开关,输出还是 1 不变。
- 接通开关 S,输出变为 0,即使断开开关,输出也还是 0。 也就是,当两个开关都断开的时候,最终的输出结果,取决于之前动作的输出结果,这个也就是我们说的记忆功能。PS: 所谓记忆电路,就是电路会持续输出电路上一次改动的输出结果(毕竟输出重新作为了输入) CPU 的工作原理是什么?
电路竟然具备存储信息的能力了。现在为保存信息你需要同时设置S端和R端,但你的输入是有一个(存储一个bit位嘛),当D为0时,整个电路保存的就是0,否则就是1。
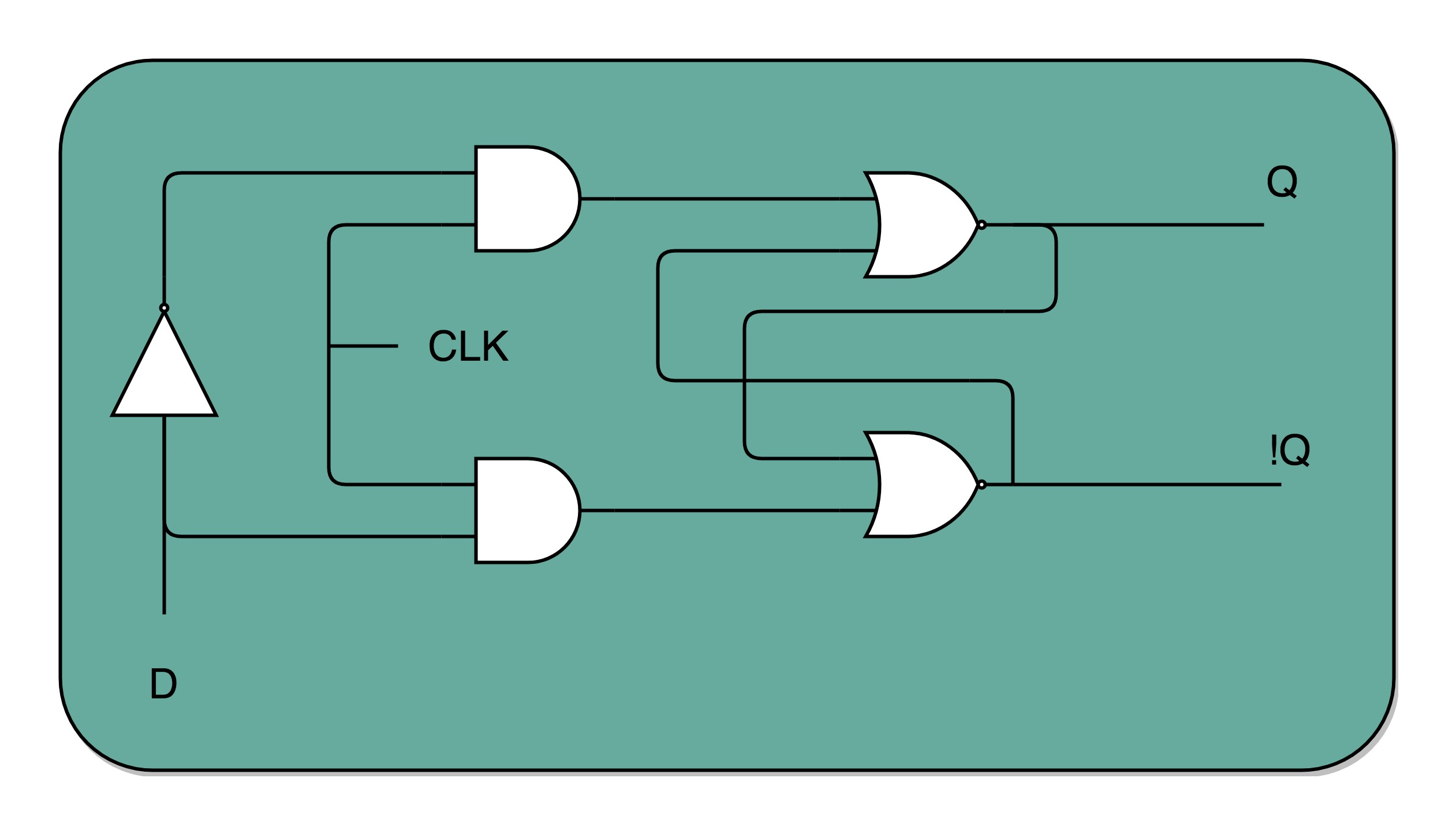
在R-S 触发器电路里加两个与门和一个小小的时钟信号,我们就可以实现一个利用时钟信号来操作一个电路了。这个电路可以帮我们实现什么时候可以往 Q 里写入数据。当时钟信号 CLK 在低电平的时候,与门的输入里有一个 0,两个实际的 R 和 S 后的与门的输出必然是 0。也就是说,无论我们怎么按 R 和 S 的开关,根据 R-S 触发器的真值表,对应的 Q 的输出都不会发生变化。PS:时钟信号和你真正要写入的信号求与,可以让你的输入信号都是0。
一个 D 型触发器,只能控制 1 个比特的读写,但是如果我们同时拿出多个 D 型触发器并列在一起,并且把用同一个 CLK 信号控制作为所有 D 型触发器的开关,这就变成了一个 N 位的 D 型触发器,也就可以同时控制 N 位的读写。
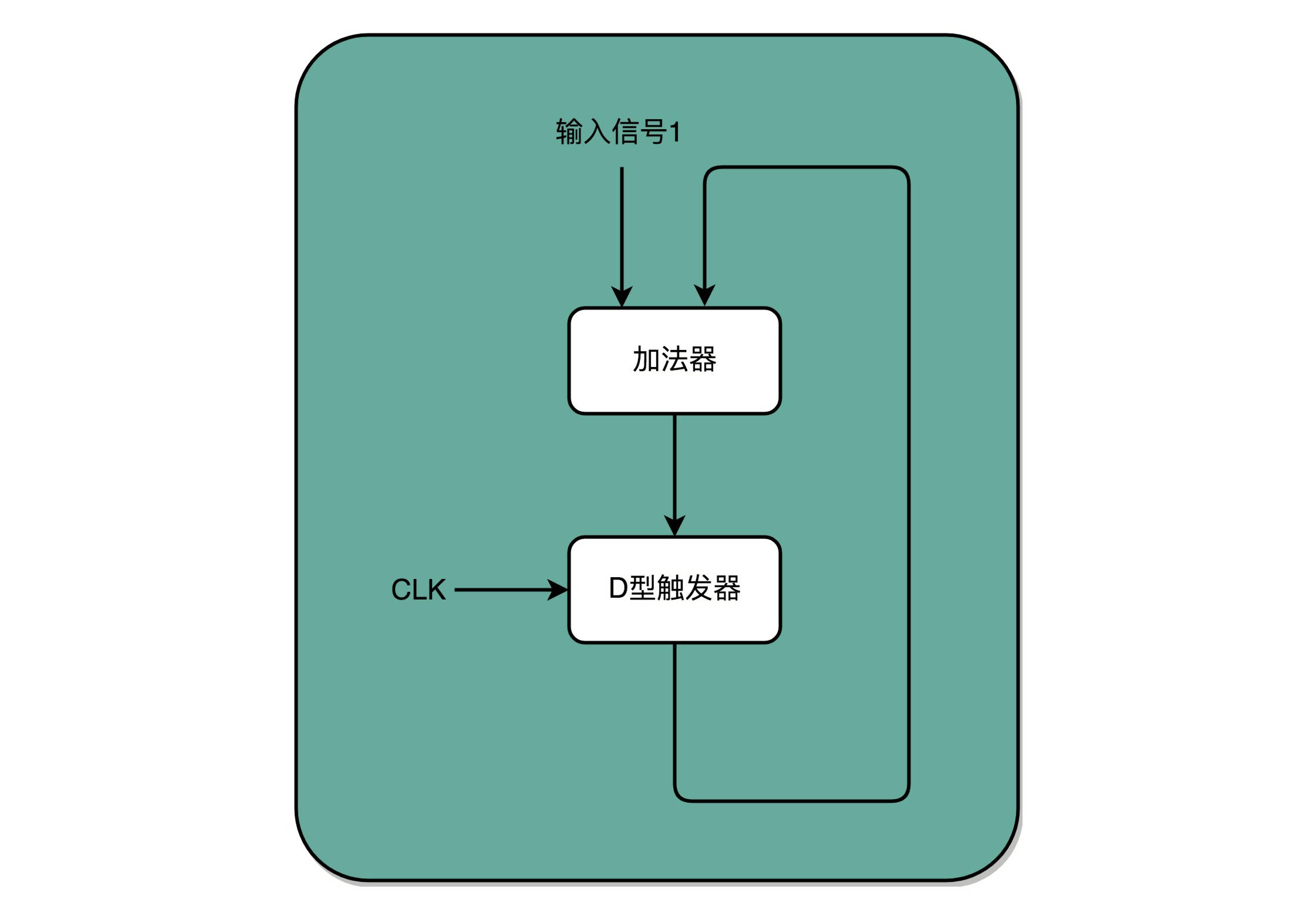
有了时钟信号,我们可以提供定时的输入;有了 D 型触发器,我们可以在时钟信号控制的时间点写入数据。加法器的两个输入,一个始终设置成 1,另外一个来自于一个 D 型触发器 A。我们把加法器的输出结果,写到这个 D 型触发器 A 里面。于是,D 型触发器里面的数据就会在固定的时钟信号为 1 的时候更新一次。这样,我们就有了一个每过一个时钟周期,就能固定自增 1 的自动计数器了。这个自动计数器,可以拿来当我们的 PC 寄存器。每次自增之后,我们可以去对应的 D 型触发器里面取值,这也是我们下一条需要运行指令的地址。
读写数据所需要的译码器:现在,我们的数据能够存储在 D 型触发器里了。如果我们把很多个 D 型触发器放在一起,就可以形成一块很大的存储空间,甚至可以当成一块内存来用。那我们怎么才能知道,写入和读取的数据,是在这么大的内存的哪几个比特呢?
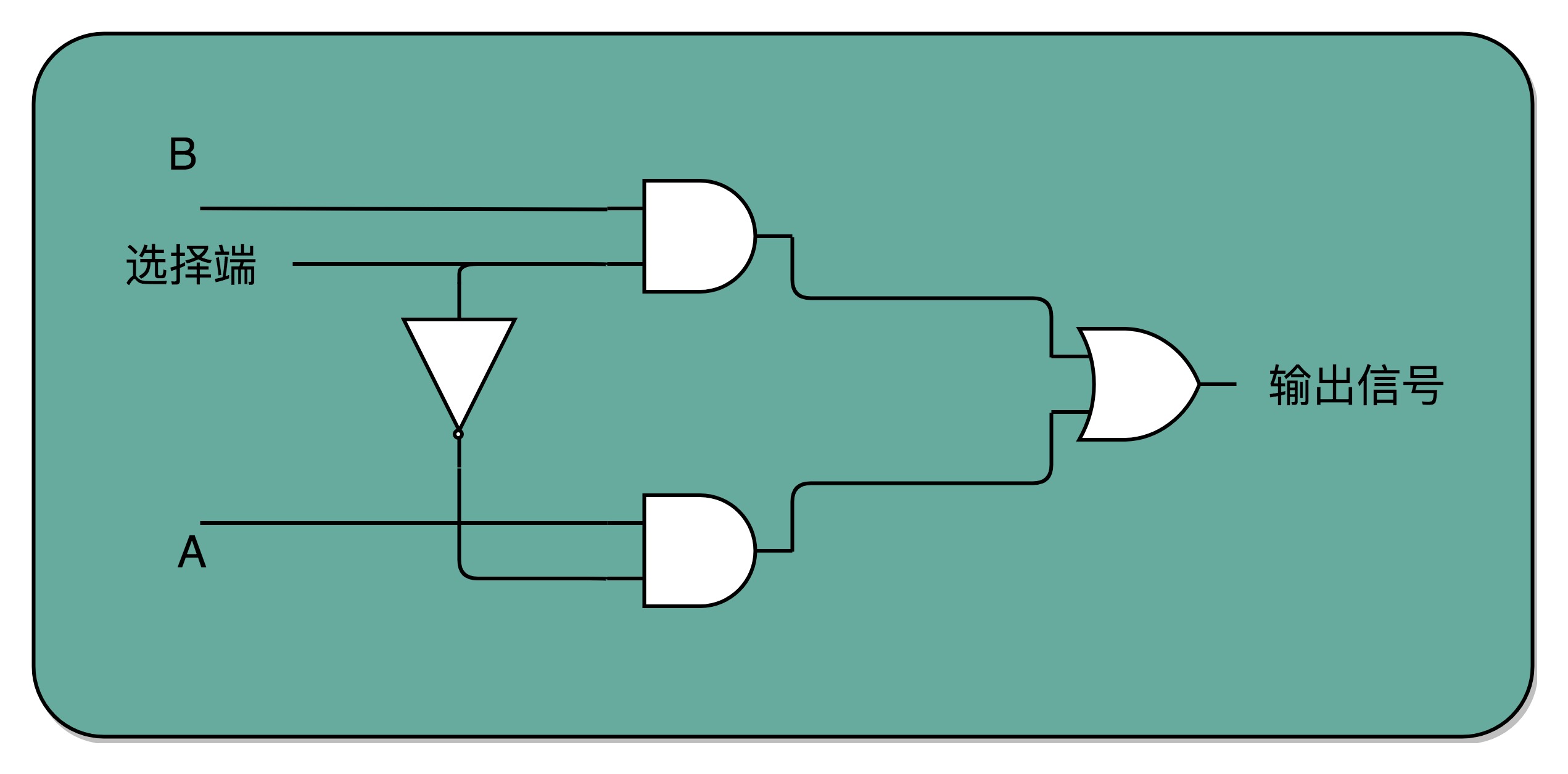
如果把“寻址”这件事情退化到最简单的情况,就是在两个地址中,去选择一个地址。我们通过一个反相器、两个与门和一个或门,就可以实现一个 2-1 选择器。通过控制反相器的输入是 0 还是 1,能够决定对应的输出信号,是和地址 A,还是地址 B 的输入信号一致。PS:这个2-1选择器打个比方就是,如果AB 两根线都通电/想数据输出,我可以通过“一根线” 决定让AB 哪根线出去。一个byte 8根线,则需要3根线即可决定谁“输出”。3根线是8根线的开关,它的值可以视为一个地址,而不是真的是一个“物理地址”。按地址取数据不是数据的搬运,是电流的组合的结果。
总结:
- 01输入经过门电路可以转换为输出,输出可以作为另一个门电路的输入
- 门电路的组合(与或非异或等) 有以下可能
- 输入 单纯的是 逻辑算术运算的 “因子”
- 时钟的01输入 与常规01输入求与 可以使得01输入有效或无效,或者说让输入有“节奏”
- 上一次输出原样作为电路的一部分输入,可以产生“记忆”的效果
- 某个输入可以让其它输入有效或无效,即起到选择作用
在我们的想象中,物理机机器内部似乎要维护一张大而全的指令集表,每次cpu 读入一个机器指令时,去扫描这张指令集表,从而识别机器码,并进一步判断该操作码后是否有操作数。而事实上,cpu 内置的“指令集” 是硬件结构/数字电路。只要向cpu 传递一个指令,cpu 便可以根据预先设定好的电路进行解码(高低电平),然后操作对应的寄存器或者某些电路 去读取该操作码后面的操作数。同时,另一些电路支持读取当前机器指令的下一条指令。 如此一来,cpu 便能完成取指 ==> 译码 ==> 执行 ==> 取指的循环了。PS:从内存中取数 可以认为是 让 所有的 存储电路有选择的输出,内存地址每一根线即开关。那么译码(地址+时钟)也可以认为 让所有电路有选择的 触发,指令代码的每一位即开关。
画电路图
Verilog 是一种优秀的硬件描述语言,它可以用类似 C 语言的高级语言设计芯片,从而免去了徒手画门电路的烦恼。
/*----------------------------------------------------------------
Filename: alu.v
Function: 设计一个N位的ALU(实现两个N位有符号整数加 减 比较运算)
-----------------------------------------------------------------*/
module alu(ena, clk, opcode, data1, data2, y);
//定义alu位宽
parameter N = 32; //输入范围[-128, 127]
//定义输入输出端口
input ena, clk;
input [1 : 0] opcode;
input signed [N - 1 : 0] data1, data2; //输入有符号整数范围为[-128, 127]
output signed [N : 0] y; //输出范围有符号整数范围为[-255, 255]
//内部寄存器定义
reg signed [N : 0] y;
//状态编码
parameter ADD = 2'b00, SUB = 2'b01, COMPARE = 2'b10;
//逻辑实现
always@(posedge clk)
begin
if(ena)
begin
casex(opcode)
ADD: y <= data1 + data2; //实现有符号整数加运算
SUB: y <= data1 - data2; //实现有符号数减运算
COMPARE: y <= (data1 > data2) ? 1 : ((data1 == data2) ? 0 : 2); //data1 = data2 输出0; data1 > data2 输出1; data1 < data2 输出2;
default: y <= 0;
endcase
end
end
endmodule
其它
- 晶体管可以实现 AND、OR、NOT
- 给定足够的AND、OR以及NOT门,就可以实现任何一个逻辑函数,{AND、OR、NOT}就是逻辑完备的
- 一个与门和一个异或门就可以实现二进制加法,有了加法任何算术运算就ok了
- 两个NAND门的组合可以实现记忆一个bit的效果(NAND由与或非门组合而成) ==> 电路有了记忆能力 ==> 寄存器和内存就出来了。
cpu空闲的时候在干嘛?内核设计者创建了一个叫做空闲任务的进程,在 Linux 下就是第 0号进程。当其它进程都处于不可运行状态时,调度器就从队列中取出空闲进程运行,显然,空闲进程永远处于就绪状态,且优先级最低,空闲进程是一个不断执行 halt 指令的循环。 这条指令会让部分CPU进入休眠状态,从而极大减少对电力的消耗,通常这条指令也被放到循环中执行。halt 指令是特权指令,也就是说只有在内核态下 CPU 才可以执行这条指令,程序员写的应用都运行在用户态,因此你没有办法在用户态让 CPU 去执行这条指令。