简介
为什么需要关注软件架构许多软件开发人员不信任架构实践,他们相信,如果他们遵循这些实践,可能需要很长时间才能交付一些甚至可能不是客户想要的东西。他们更愿意专注于理解客户的需求,并通过小而快速的敏捷迭代过程来交付产品。他们当中有一些人相信,只要遵循了这些过程,架构自然会“出现”,而不需要有意识地进行计划或架构设计。这种架构方法通常可以交付满足客户所需的产品,这是一个好的开始。但是,如果不显式考虑产品的可持续性,它就有可能衰退,导致产品在自然退役前无法维护。
- 如果我们正在做的事情是我们非常了解的,并且已经做过很多次了,那么预先设计方法就很有效。例如,建造摩天大楼、挖运河、生产产品或建造桥梁。我们可以应用“最佳实践”,并依赖过去已经在这些事情上验证过的有效方法。
- 如果我们正在处理一些东西是全新的,并且我们不太了解,或者变化太快以至于还没有“最佳实践”,那么预先设计就不起作用了。在这种情况下,作为科学革命基础的可控性实验可以帮助我们更深入地理解问题和可能的解决方案。最终的解决方案“出现”了,只是它沿着有意识的实验的路径向我们招手。问题在于,可控性实验可能无法在合理的时间内产生可持续的解决方案,并且可能需要进行可接受的返工。 软件架构实践可以通过更早地提出更好的问题来指导实验,以减少交付可持续产品的时间和成本,并仍然可以保留敏捷方法的优势。架构的本质由一组定义和约束产品技术面的决策组成。这些决策专注于产品如何处理质量属性需求(QAR), 如性能、安全性或可伸缩性。此外,如果架构设计没有强有力地实现组件的抽象和隔离,重构的成本可能会飙升。
广义地说,实现“可持续性”是软件产品架构工作的重点。如果软件产品能够满足当前需求 (包括 QAR),而不损害满足未来需求的能力,则可以认为该软件产品是可持续的。不幸的是,随着功能增强的实现和新设计决策的制定,软件系统会随着时间的推移而“磨损”,这可能会延展甚至破坏最初的架构设计。常见的“磨损”原因包括:
- 由于维护系统的开发人员对系统缺乏理解,最初的设计决策也就过时了。与系统设计相关的决策和假设很少会被准确地记录下来。当人们不再针对系统提出问题或回答问题时,软件系统就开始衰退了。提出问题是评估软件系统健康状况的一种重要技术,如果有知识资源可以回答这些问题的话。
- 技术债务的累积会导致系统维护不再可行或不再具有成本效益,并且无法实现新的功能。
- 开发人员试图重用不同组件的代码块,他们认为可以通过对复用代码进行微小的改动来实现新功能。遗憾的是,他们可能无法完全理解原始代码所依赖的架构上下文,也意识不到在不同的组件中重用代码可能会在以后产生不必要的副作用,例如性能、可伸缩性或可用性问题。这些软件变更增加了技术债务,并降低了系统的整体质量,除非技术债务能够迅速得到解决。
- 技术的发展导致一些软件系统运行在不是为它们设计的技术平台上。一些较老的软件系统经历了“灾难性的成功”,因为它们持续存在的时间比最初计划的要长得多,而且它们的技术债务已经变得非常沉重、难以解决且代价巨大,“偿还”起来非常困难。偿还技术债务的成本可能与完全替换该软件系统的成本类似,甚至有过之而无不及。
- 失败的假设。逻辑的主体,包括软件系统,最终会因为假设的失败而崩溃,软件开发人员可能没有意识到他们所做的假设。隐藏的假设可以被认为是对系统的约束。关键在于要清楚地阐明所有的假设,并保持信息的更新。质量属性需求本身也是一种需要进行验证的假设,它们的实现需要经过经验的测试和确认,如果可能的话,可以使用自动化。性能、可伸缩性、弹性 (例如,使用类似于 Netflix 猴子军团的框架) 和安全性都是很好的例子。质量属性自动化测试的目标是持续对假设 (例如,实现 QAR 仍然是现实的吗?) 进行测试,并用以指导软件系统的演化。
多个范畴的生命周期
人一生的生命周期被各种不同的场景、任务、角色、身份切分成了各不相同的生命周期,其中有核心生命周期,有非核心生命周期,有些必须自己做(读书、生活、谈恋爱),有些可以交给别人做。
在人类历史中,随着工作越来越复杂、工作任务越来越多,人类协作越来越精细,然后就产生了分工,分工就是人类因为协作产生的生命周期的切分。
明确了生命周期这个概念就会意识到,随着事物的发展,把它的一部分职能从其核心生命周期切分出去,构造出新的生命周期,能够帮助这一事物明确自身的核心生命周期、明确自己的职责和权力,有更多时间用在自己擅长的事情上。
代码、技术、业务和管理
要分得清楚访问代码、业务代码、存储代码、胶水代码各自应在哪些层级,它们应该是什么角色,而不是所有代码散乱的混在一起,看起来似乎按照经典的MVC分层,实际上业务代码却同时出现在controller/service/dao,这样其实并没有明确的划分。
正确的做法应该是controller完成访问逻辑;DAO完成存储逻辑;service完成胶水逻辑,承上启下,利用DTO转换访问参数、执行业务逻辑、调用DAO映射存储模型、再利用DTO把业务处理结果转换为响应结果,业务逻辑在业务模型中实现。如果把业务逻辑跟业务数据在一起实现就是充血模型,进一步深化就是DDD模式。
如果把业务逻辑跟业务数据在一起实现就是充血模型,进一步深化就是DDD模式。只有这样才完成了明确的软件层次划分,每层各司其职、权责对等,否则就是大泥球。 明白了这一点,自然就能分得清楚业务的事务跟关系数据库的事务不是一回事,也就不会考虑完成业务上的事务要依赖关系数据库事务确保数据完整性。
完全可以把二者分开,利用更符合业务规律的做法去实现,甚至业务本身已经有成熟的方案确保数据完整性,而不再需要依赖关系数据库事务。在业务上对关系数据库事务ACID特性的依赖既然不再是必须,对拥有ACID特性的数据库依赖自然也就不再是必须,完全可以根据业务需要选择合适的存储方案。
业务模型和具体实现不再依赖于某些具体方案的技术特性,实现了业务与技术的解耦,也就更容易实现横向扩展。现在又发现横向扩展也是自然界的一个基本特性。无数基本粒子构成原子、无数原子构成一个具体的宏观物体,一个人不够用就增加更多人。如果一个系统的规模在横向扩展上达到了瓶颈,不能再靠简单的增加数量获得提升的时候,一定是这个系统的组织架构存在某些不合理因素。
说到这里自然就要说到业务和技术的关系。前面说到软件是现实世界的映射抽象,由虚拟人代替自然人去完成一些工作。要做好软件自然就要理解业务,对业务的理解越深刻就越有可能做出优秀的软件。
但是现实世界太复杂了,随着业务发展,软件规模会越来越大,复杂性越来越高,一个人难以胜任全部架构工作,于是就产生了架构师团队,架构师也有了更细致的分工。架构师的生命周期也相应发生了拆分,也就产生了业务架构、应用架构、系统架构。
架构师为了能够实现自己的架构思想,自然需要与职能对等的权力。所以架构师其实不是一个纯粹的技术职位,而是拥有管理职能的职位,而不同角色的架构师对技术的要求也不尽相同。
《架构整洁之道》的作者Uncle Bob说的那样:“架构师的工作不是作出决策,而是尽可能久地推迟决策,在现在不作出重大决策的情况下构建程序,以便以后有足够信息时再作出决策。
《郭东白的架构课》
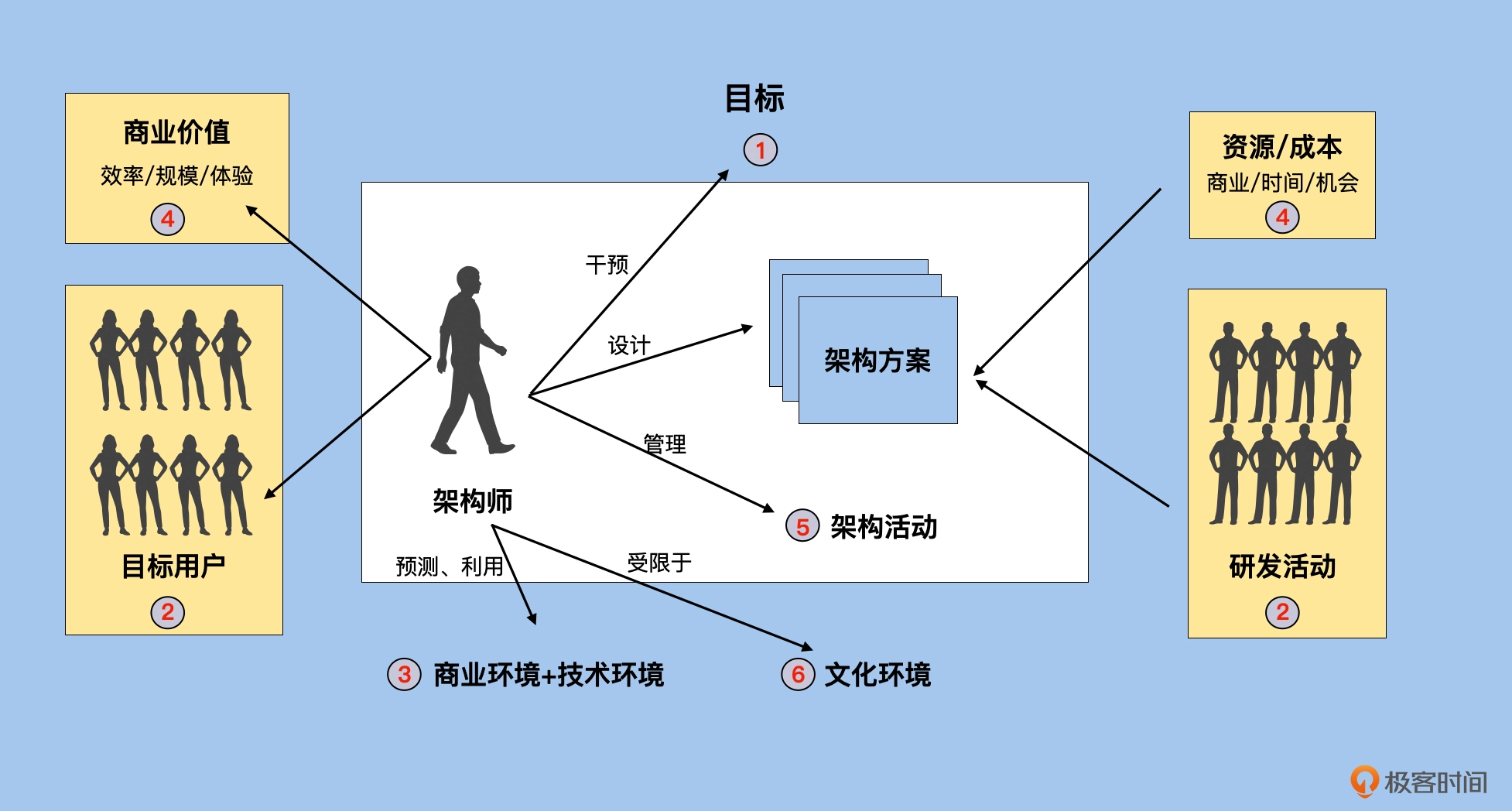
一名软件架构师要为相对复杂的业务制定,并且引导实施一个结构化的软件方案。这个发现最终方案和推动实施的过程,就是架构活动。这个方案需要和企业目标一致,与商业、软件环境相匹配,并且还需要满足各种资源的约束条件。而你作为一个架构师,要在这些方案中找到那个能够最小化资源和成本,最大化商业价值,以及最大化目标用户满意度的方案。最终,你还要组织技术团队交付这个架构设计方案。
- 在一个企业内,大多数研发任务的交付都与架构师无关。多数时间,研发团队开发的软件解决方案和软件产品是用来服务用户的,不需要架构师的参与。但当面对跨多个团队,或者是大面积的技术改造时,就需要架构师参与到其中,来完成软件研发任务的交付。
- 架构师对研发活动没有完全的决策权。也就是说,架构师无法决定研发项目的选择、优先级、排期、代码实现方式等等。架构师仅仅可以关注、影响和干预这些因素。
- 做成一件事情,如果周边条件成熟,环境好,那么事情就会进行得很顺利。反过来,如果条件不成熟,或者你逆势而为,那就会很艰难。
- 天时,这里指的是商业环境和技术环境的变化趋势。环境复杂多变,那么看清楚变化趋势的本质,就可以让我们的架构决策顺势而为,借助于环境的变化来成就我们的团队、企业。
- 地利,就是你作为一个架构师待的地方,你所在企业的文化环境,这是我们作为架构师无法改变的部分。虽然没法改变,但“良禽择木而栖”。
- 人和,架构活动中涉及的人主要是研发人员和目标用户。在输入端,架构师需要与多个研发团队协作,因而理解研发方的核心诉求就尤为关键。在输出端,架构师产出方案的最终评判即目标用户的长期满意度。因此深度洞察用户的人性就是保证架构活动成功的关键所在。
- 生存法则指的是我们作为架构师在设计架构方案和组织架构活动时必须要尊重的一些原则。如果违背这些原则,那么作为一个架构师的生存就会受到威胁。
- 有且仅有一个正确的目标。这是架构活动的起点,也是甄别架构方案的主要输入
- 尊重和顺应人性。从人性角度出发来做决策,才能保障最终面向用户的方案具有长期正确性,以及面向研发同学的实施过程具有可行性。
- 在有限资源下最大化商业价值。
- 必须要考虑到所依赖的商业和技术模块的生命周期。在架构设计的过程中,架构师会有一个相对确定的商业和技术选择空间。一般情况下,要选择已经有规模优势或者是即将有规模优势的技术,而不是选择那些接近衰老期的技术。
- 不断干预活动的目标和内容,同时为企业注入外部适应性,最终正确的架构选型会因为有很强的外部适应性而长期存在。
- 在一个相对安全的文化环境中探索未知,文化环境是架构师最难影响的,因而架构师要有足够的判断力,认清自己所在的文化环境是否有利于探索正确的架构方案,不要在一个错误的环境中浪费自己的宝贵生命。
其它
- 当我们去研究各个大战的最后胜出者时会发现,他们都不是靠全程饱和攻击取胜的,而是靠对阶段性精确目标的最大化投入从而在惨烈竞争中胜出的。在充分竞争环境下胜出的公司,几乎没有任何一个是通过大范围的搜索商业模式去寻找增长的。在你的决策范围内,如果你不做取舍,那么就只能让别人来替你做取舍。
- 架构其实也一模一样。架构师必须尽量保障整个架构活动有且仅有一个正确的目标,且这个目标必须和公司的战略意图相匹配。显然,未来充满不确定性,终极目标很难验证,但通过反复问自己这个问题,我们就可以不断逼近这个唯一且正确的架构目标。
- 讲真话的时候,不是你在反对你的上级,而是你在用一个架构原则来判断另外一个人的决策质量。
- 架构目标的决策,对于一个人或一个团队的影响是巨大的。所以当你有了一个正确的关于架构目标的决策,要知道这只是一个起点。你还要认真思考这个决策的实施路径,让大家团结在正确的架构目标上,而不是你自己一个人举着架构目标,变成孤家寡人。不要全盘否定别人的观点,而是站在他的视角,看到、并理解他的出发点的正确部分是什么。
架构师需要做的是,在一个相对复杂的问题上引导实施一个结构化的解决方案。这个方案的参与者是一群人,所以架构师的产出不完全靠自己,而是靠撬动一群人来完成架构目标。
- 确保最终架构方案的可行性。
- 确保参与方达成一个合理的实施路径,最终能够完成实施。
- 确保设计方案可以最大化解决方案的结构性。 事实上,这三个条件很难被同时满足。架构师之所以参与一个方案,往往有这么几个原因:已经有现成的方案,但比较复杂;参与团队众多,但各个团队的优先级不一样;公司压力大,能够投入到现存方案的人力资源有限。
其它
- I claim that you want to start communicating between independent modules no sooner than you absolutely HAVE to, and that you should avoid splitting things up until you really need to, because that communication complexity often swamps the complexity of the actual pieces involved in it.(让我们认识到一种现象,把复杂系统拆分成模块,似乎并没有降低整个系统的复杂度。它降低的只是子系统的复杂度。而整个系统的复杂度,反而会由于拆分后的模块之间,不得不进行交互,变得更加复杂。)
- The fundamental organization of a system, embodied in its components, their relationships to each other and the environment, and the principles governing its design and evolution. Architecture = Structure of Component + Relationships + Principles & Guidelines。
- 架构的本质是为了管理复杂性;架构的本质就是对系统进行有序化重构,不断减少系统的“熵”,使系统不断进化;架构的本质就是对系统进行有序化重构,以符合当前业务的发展,并可以快速扩展。架构的过程其实就是建模的过程。
- 架构的核心目的:管理复杂性,效率最大化。架构的两个主要变化来源:一个是以改善软件质量为目的的内在结构性变化;另外一个是以满足客户需求为目的的外在功能性变化。
我对技术架构的理解与架构师角色的思考每时每刻都在发生技术的升级和变革,需要持续不断地学习,才能对老的架构有新的认识,对于老问题产生新的解法。为什么你能解决这个问题,并且能解决这一类问题?一定是需要你看的多,想的多,这背后是大量的实践和知识的积累,并且是站在过去的肩膀上。 架构师需要什么样的能力?
- 发现问题,
- 对于一个局部/全局的问题,需要有发现的眼光,更应该有发现未发生问题的能力
- 每天都会面对很多问题,哪些需要治标,哪些需要治本,这个是发现问题的基本判断力。
- 定义/分析问题。将发现的问题,进行抽象和归纳,定义出问题的基本要素,同时定义问题的短期和长期方案,推进技术的进步。
- 解决问题
- 制定问题的实施路径和解决方案,怎么把这个问题说清楚,切中问题的点,协同团队和上下游推进问题的解决
- 架构师需要能救火,但不仅仅是救眼前的火,更应该救未来的火。
徐文浩:在公司里,我每天在做的,其实主要就是两件事情。
- 一件事情,我称之为“让事情按次发生”,主要是规划和推动公司里想要做的事情,推动产品结合业务往前走。
- 另一件事情,我称之为“面对问题,解决问题”,主要是给各种突发的、意料之外的问题找解决办法。
如何设计一个复杂的业务系统?软件架构设计本身就是一个复杂的事情,但其实业界已有一个共识,那就是“通过组件化完成关注点的分离从而降低局部复杂度”。