简介
在1.13 版本中,kubelet 大约有13个mannager 保证pod 正常运行
// Run starts the kubelet reacting to config updates
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
...
// Start the cloud provider sync manager
go kl.cloudResourceSyncManager.Run(wait.NeverStop)
if err := kl.initializeModules(); err != nil {...}
// Start volume manager
go kl.volumeManager.Run(kl.sourcesReady, wait.NeverStop)
// Start syncing node status immediately, this may set up things the runtime needs to run.
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
go kl.fastStatusUpdateOnce()
// start syncing lease
go kl.nodeLeaseController.Run(wait.NeverStop)
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
// Start loop to sync iptables util rules
go wait.Until(kl.syncNetworkUtil, 1*time.Minute, wait.NeverStop)
// Start a goroutine responsible for killing pods (that are not properly handled by pod workers).
go wait.Until(kl.podKiller, 1*time.Second, wait.NeverStop)
// Start component sync loops.
kl.statusManager.Start()
kl.probeManager.Start()
// Start syncing RuntimeClasses if enabled.
go kl.runtimeClassManager.Run(wait.NeverStop)
// Start the pod lifecycle event generator.
kl.pleg.Start()
kl.syncLoop(updates, kl)
}
// initializeModules will initialize internal modules that do not require the container runtime to be up. 启动不需要container runtime 的组件
func (kl *Kubelet) initializeModules() error {
// Prometheus metrics.
metrics.Register(...)
// Setup filesystem directories.
if err := kl.setupDataDirs(); err != nil {...}
// Start the image manager.
kl.imageManager.Start()
// Start the certificate manager if it was enabled.
kl.serverCertificateManager.Start()
// Start out of memory watcher.
if err := kl.oomWatcher.Start(kl.nodeRef); err != nil {...}
// Start resource analyzer
kl.resourceAnalyzer.Start()
}
pleg
kubernetes 问题排查: 系统时间被修改导致 sandbox 冲突
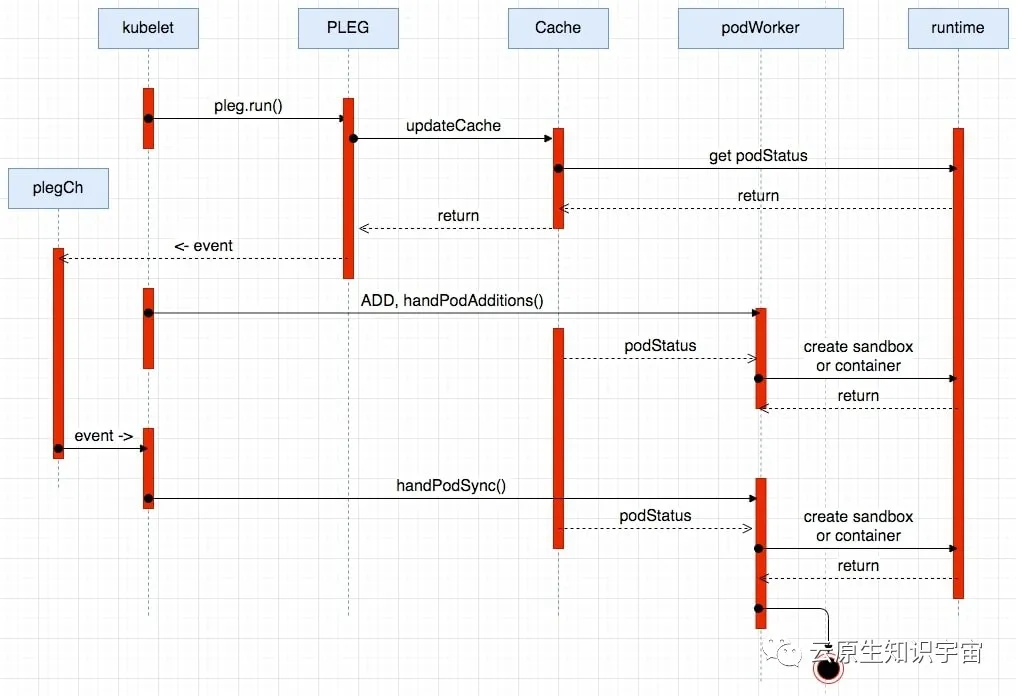
kubelet 启动之后,会运行起 PLEG 组件,定期的缓存 pod 的信息(包括 pod status)。在 PLEG 的每次 relist 逻辑中,会对比 old pod 和 new pod,检查是否存在变化,如果新旧 pod 之间存在变化,则开始执行下面两个逻辑:
- 更新内部缓存 cache。在更新缓存 updateCache 的逻辑中,会调用 runtime 的相关接口获取到与 pod 相关的 status 状态信息,然后缓存到内部cache中,最后发起通知 ( podWorker 会发起订阅) 。
- 生成 event 事件,比如 containerStart 等,最后再投递到 eventChannel 中,供 podWorker 来消费。
podWorker 的工作就是负责 pod 在节点上的正确运行(比如挂载 volume,新起 sandbox,新起 container 等),一个 pod 对应一个 podWorker,直到 pod 销毁。
源码文件
k8s.io/kubernetes
/cmd/kubelet
/app
/kubelet.go
/pkg/kubelet
/pleg
/doc.go
/generic.go
/pleg.go
...
/kubelet.go

GenericPLEG 通过 runtime/cri 获取pod 信息(输入),与本地存储的上一次pod 数据作对比,通过eventChannel 对外发出 PodLifecycleEvent 事件(输出)
func (g *GenericPLEG) Start() {
go wait.Until(g.relist, g.relistPeriod, wait.NeverStop)
}
// relist queries the container runtime for list of pods/containers, compare
// with the internal pods/containers, and generates events accordingly.
func (g *GenericPLEG) relist() {
...
// Get all the pods.
podList, err := g.runtime.GetPods(true)
pods := kubecontainer.Pods(podList)
g.podRecords.setCurrent(pods)
// Compare the old and the current pods, and generate events. eventsByPodID 存储了可能的新事件
eventsByPodID := map[types.UID][]*PodLifecycleEvent{}
for pid := range g.podRecords {
oldPod := g.podRecords.getOld(pid)
pod := g.podRecords.getCurrent(pid)
// Get all containers in the old and the new pod.
allContainers := getContainersFromPods(oldPod, pod)
for _, container := range allContainers {
events := computeEvents(oldPod, pod, &container.ID)
for _, e := range events {
updateEvents(eventsByPodID, e)
}
}
}
// If there are events associated with a pod, we should update the podCache.
for pid, events := range eventsByPodID {
pod := g.podRecords.getCurrent(pid)
if g.cacheEnabled() {...}
// Update the internal storage and send out the events.
g.podRecords.update(pid)
for i := range events {
// Filter out events that are not reliable and no other components use yet.
if events[i].Type == ContainerChanged {
continue
}
select {
case g.eventChannel <- events[i]:
default:...
}
}
}
...
}
pleg 本地 对pod 数据的缓存结构 type podRecords map[types.UID]*podRecord
type podRecord struct {
old *kubecontainer.Pod
current *kubecontainer.Pod
}
probeManager
k8s.io/kubernetes
/cmd/kubelet
/app
/kubelet.go
/pkg/kubelet
/prober
/prober.go
/prober_manager.go
/worker.go
...
/kubelet.go
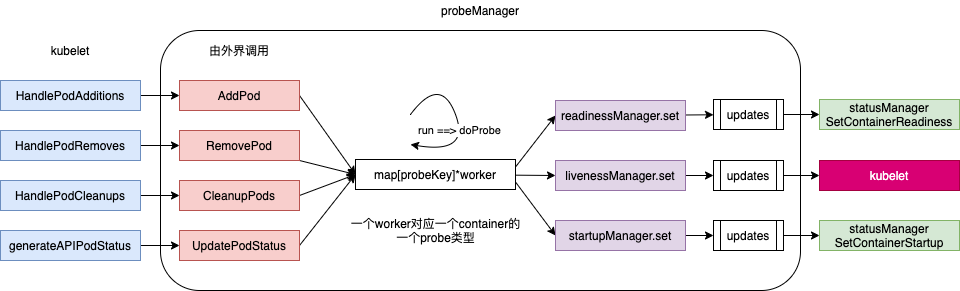
源码中关于Manager interface的注释:Manager manages pod probing. It creates a probe “worker” for every container that specifies a probe (AddPod). The worker periodically probes its assigned container and caches the results. The manager use the cached probe results to set the appropriate Ready state in the PodStatus when requested (UpdatePodStatus). 一个container的一个probe 对应一个worker,worker 周期性的探测,并将结果发往channel,由感兴趣的组件监听。
type manager struct {
// Map of active workers for probes
workers map[probeKey]*worker
// Lock for accessing & mutating workers
workerLock sync.RWMutex
// The statusManager cache provides pod IP and container IDs for probing.
statusManager status.Manager
// readinessManager manages the results of readiness probes
readinessManager results.Manager
// livenessManager manages the results of liveness probes
livenessManager results.Manager
// startupManager manages the results of startup probes
startupManager results.Manager
// prober executes the probe actions. 实际负责探测逻辑
prober *prober
}
statusManager
源码文件
k8s.io/kubernetes
/cmd/kubelet
/app
/kubelet.go
/pkg/kubelet
/status
/generate.go
/status_manager.go
...
/kubelet.go
statusManager 负责维护状态信息,并把 pod 状态更新到 apiserver,但是它并不负责监控 pod 状态的变化,而是提供对应的接口供其他组件调用
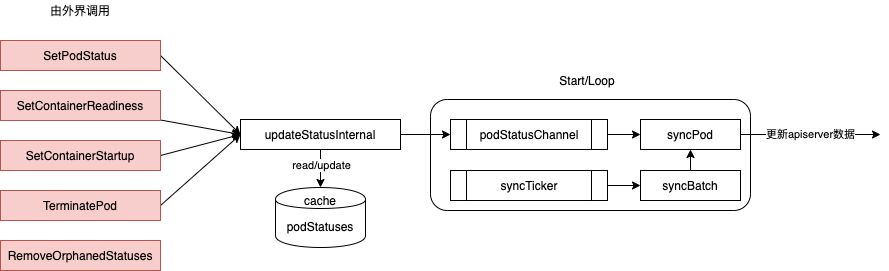
type manager struct {
kubeClient clientset.Interface
podManager kubepod.Manager
// Map from pod UID to sync status of the corresponding pod.
podStatuses map[types.UID]versionedPodStatus
podStatusesLock sync.RWMutex
podStatusChannel chan podStatusSyncRequest
// Map from (mirror) pod UID to latest status version successfully sent to the API server.
// apiStatusVersions must only be accessed from the sync thread.
apiStatusVersions map[kubetypes.MirrorPodUID]uint64
podDeletionSafety PodDeletionSafetyProvider
}
func (m *manager) updateStatusInternal(pod *v1.Pod, status v1.PodStatus, forceUpdate bool) bool {...}
func (m *manager) syncBatch() {...}
func (m *manager) syncPod(uid types.UID, status versionedPodStatus) {...}
kubelet 垃圾收集
- 容器GC:退出的容器也会继续占用系统资源,比如还会在文件系统存储很多数据、Docker 应用也要占用 CPU 和内存去维护这些容器。Docker 本身并不会自动删除已经退出的容器,因此 kubelet 就负起了这个责任。kubelet 容器的回收是为了删除已经退出的容器以节省节点的空间,提升性能。容器 GC 虽然有利于空间和性能,但是删除容器也会导致错误现场被清理,不利于 debug 和错误定位,因此不建议把所有退出的容器都删除。因此容器的清理需要一定的策略,主要是告诉 kubelet 你要保存多少已经退出的容器(有一些对应的参数)。
- 镜像GC:镜像主要占用磁盘空间,虽然 docker 使用镜像分层可以让多个镜像共享存储,但是长时间运行的节点如果下载了很多镜像也会导致占用的存储空间过多。如果镜像导致磁盘被占满,会造成应用无法正常工作。docker 默认也不会做镜像清理,镜像一旦下载就会永远留在本地,除非被手动删除。镜像的清理和容器不同,是以占用的空间作为标准的,用户可以配置当镜像占据多大比例的存储空间时才进行清理。清理的时候会优先清理最久没有被使用的镜像,镜像被 pull 下来或者被容器使用都会更新它的最近使用时间(有一些对应的参数)。
// k8s.io/kubernetes/pkg/kubelet/kubelet.go
func (kl *Kubelet) StartGarbageCollection() {
go wait.Until(func() {
if err := kl.containerGC.GarbageCollect(); err != nil {...}
}, ContainerGCPeriod, wait.NeverStop)
go wait.Until(func() {
if err := kl.imageManager.GarbageCollect(); err != nil {...}
}, ImageGCPeriod, wait.NeverStop)
}
源码文件
k8s.io/kubernetes
/cmd/kubelet
/app
/kubelet.go
/pkg/kubelet
/container
/container_gc.go
/image_gc_manager.go
...
/kubelet.go
几个关键点
- 无论移除容器,还是移除镜像,都是由kubelet 调用runtime 执行的
- 容器回收简单一些,直接调用runtime 接口即可,镜像回收则根据磁盘使用率的上下限 HighThresholdPercent 和 LowThresholdPercent 来决定。
// container_gc.go
func (cgc *realContainerGC) GarbageCollect() error {
return cgc.runtime.GarbageCollect(cgc.policy, cgc.sourcesReadyProvider.AllReady(), false)
}
// image_gc_manager.go
func (im *realImageGCManager) GarbageCollect() error {
// Get disk usage on disk holding images.
fsStats, err := im.statsProvider.ImageFsStats()
capacity = int64(*fsStats.CapacityBytes)
available = int64(*fsStats.AvailableBytes)
// If over the max threshold, free enough to place us at the lower threshold.
usagePercent := 100 - int(available*100/capacity)
if usagePercent >= im.policy.HighThresholdPercent {
amountToFree := capacity*int64(100-im.policy.LowThresholdPercent)/100 - available
im.policy.HighThresholdPercent, amountToFree, im.policy.LowThresholdPercent)
freed, err := im.freeSpace(amountToFree, time.Now())
}
return nil
}
func (im *realImageGCManager) freeSpace(bytesToFree int64, freeTime time.Time) (int64, error) {
imagesInUse, err := im.detectImages(freeTime)
// Get all images in eviction order.
images := make([]evictionInfo, 0, len(im.imageRecords))
for image, record := range im.imageRecords {
if isImageUsed(image, imagesInUse) {
klog.V(5).Infof("Image ID %s is being used", image)
continue
}
images = append(images, evictionInfo{
id: image,
imageRecord: *record,
})
}
sort.Sort(byLastUsedAndDetected(images))
// Delete unused images until we've freed up enough space.
for _, image := range images {
err := im.runtime.RemoveImage(container.ImageSpec{Image: image.id})
...
}
return spaceFreed, nil
}
cadvisor
google/cadvisor由谷歌开源,使用Go开发,cadvisor不仅可以搜集一台机器上所有运行的容器信息,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,还提供基础查询界面和http接口,方便其他组件进行数据抓取。在K8S中集成在Kubelet里作为默认启动项,k8s官方标配。
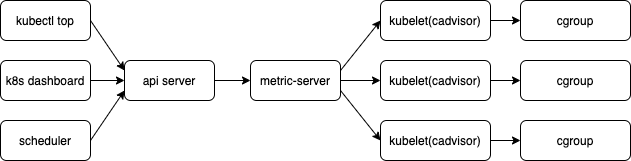
资源使用情况的监控可以通过 Metrics API的形式获取,具体的组件为Metrics Server(以Deployment 形式存在)。Metrics server复用了api-server的库来实现自己的功能,比如鉴权、版本等,为了实现将数据存放在内存中吗,去掉了默认的etcd存储,引入了内存存储。因为存放在内存中,因此监控数据是没有持久化的,可以通过第三方存储来拓展
$ k get deployment -n kube-system | grep metric
kube-state-metrics 1/1 1 1 61d
metrics-server 1/1 1 1 30d
启动链路:Kubelet.Run ==> Kubelet.updateRuntimeUp ==> Kubelet.initializeRuntimeDependentModules ==> Kubelet.cadvisor.Start
k8s.io/kubernetes
/cmd/kubelet
/app
/kubelet.go
/pkg/kubelet
/cadvisor
/cadvisor_linux.go // 定义cadvisorClient struct
/types.go
...
/kubelet.go
几乎cadvisorClient/Interface 所有的方法调用都转给了 cadvisor 包的manger struct

cpu 管理
其它
- PodManager, Pod 在内存中的管理结构,crud 访问kubelet 内存中的Pod 都通过它(线程安全),包括mirror Pod 和static Pod
type Manager interface { // GetPods returns the regular pods bound to the kubelet and their spec. GetPods() []*v1.Pod GetPodByFullName(podFullName string) (*v1.Pod, bool) GetPodByName(namespace, name string) (*v1.Pod, bool) GetPodByUID(types.UID) (*v1.Pod, bool) ... // AddPod adds the given pod to the manager. AddPod(pod *v1.Pod) // UpdatePod updates the given pod in the manager. UpdatePod(pod *v1.Pod) // DeletePod deletes the given pod from the manager. DeletePod(pod *v1.Pod) MirrorClient } - OOM killer
- 输入:监听
/dev/kmsg文件,捕获Killed process日志记录,从中拿到进程id(及contaienrName)。github.com/euank/go-kmsg-parse监听文件输出日志channel,github.com/google/cadvisor/utils/oomparser消费channel 过滤 oom 信息 - 输出:kubelet 记录event
- 输入:监听
-
eviction manager, 磁盘/内存/cpu 变化时触发
managerImpl.synchronize拿到一个 需要被驱逐的pod(对当前所有Pod排序,找最前面那个,不同的资源紧张时 使用的排序规则不同) 数据并使用Kubelet.podResourcesAreReclaimed处理一下。