问题列表
- 问题列表
- 容器有时会莫名其妙重启
- cpu
- 监控jvm
- jar冲突
- Container stuck, can’t be stopped or killed, can’t exec into it either
- docker 停住
- docker pull 镜像失败
- 项目启动是访问mysql 失败
容器有时会莫名其妙重启
环境:marathon + mesos + docker 集群
现象:容器有时会莫名其妙重启
debug过程
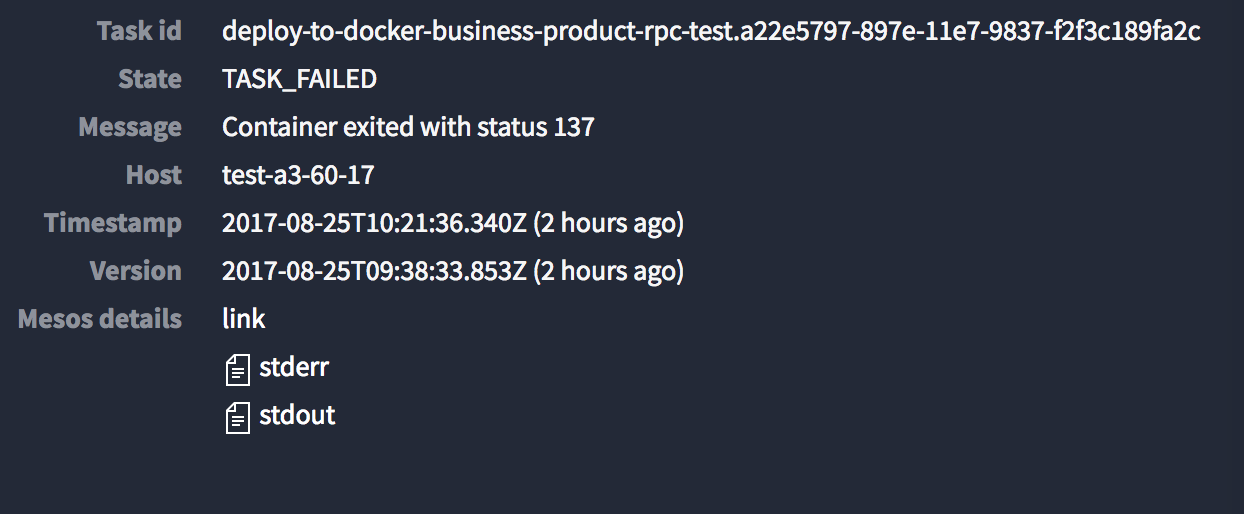
-
marathon debug tab页发现:Container exited with status 137
-
根据mesos link 查看error日志,无收获
-
找到最后一次失败所在的物理机
test-a3-60-17,并登陆 -
docker ps -a找到那个失败的容器id812c82c5a7a5,并未发现异常日志,应该不是容器业务本身的原因。 -
复制容器id,
cat /var/log/messages | grep 812c82c5a7a5 -n确定相关日志的大致行号范围 -
sed -n 'start_line,end_line p' /var/log/messages看看docker最后发出该容器的信息之前,都发生了什么。
日志内容为
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff816861cc>] dump_stack+0x19/0x1b
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff81681177>] dump_header+0x8e/0x225
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff811842b6>] ? find_lock_task_mm+0x56/0xc0
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff8118476e>] oom_kill_process+0x24e/0x3c0
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff8118420d>] ? oom_unkillable_task+0xcd/0x120
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff810937ee>] ? has_capability_noaudit+0x1e/0x30
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff811f3131>] mem_cgroup_oom_synchronize+0x551/0x580
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff811f2580>] ? mem_cgroup_charge_common+0xc0/0xc0
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff81184ff4>] pagefault_out_of_memory+0x14/0x90
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff8167ef67>] mm_fault_error+0x68/0x12b
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff81691ed5>] __do_page_fault+0x395/0x450
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff81691fc5>] do_page_fault+0x35/0x90
Aug 25 18:21:35 test-a3-60-17 kernel: [<ffffffff8168e288>] page_fault+0x28/0x30
Aug 25 18:21:35 test-a3-60-17 kernel: Task in /docker/812c82c5a7a5ae054e6f242215bdc4415a2d9b690768962a7bcd8d4676b16f60 killed as a result of limit of /docker/812c82c5a7a5ae054e6f242215bdc4415a2d9b690768962a7bcd8d4676b16f60
Aug 25 18:21:35 test-a3-60-17 kernel: memory: usage 4194304kB, limit 4194304kB, failcnt 25581
Aug 25 18:21:35 test-a3-60-17 kernel: memory+swap: usage 4194304kB, limit 8388608kB, failcnt 0
Aug 25 18:21:35 test-a3-60-17 kernel: kmem: usage 0kB, limit 9007199254740988kB, failcnt 0
Aug 25 18:21:35 test-a3-60-17 kernel: Memory cgroup stats for /docker/812c82c5a7a5ae054e6f242215bdc4415a2d9b690768962a7bcd8d4676b16f60: cache:52KB rss:4194252KB rss_huge:1277952KB mapped_file:0KB swap:0KB inactive_anon:939800KB active_anon:3254256KB inactive_file:8KB active_file:0KB unevictable:0KB
Aug 25 18:21:35 test-a3-60-17 kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
Aug 25 18:21:35 test-a3-60-17 kernel: [76513] 0 76513 6553193 1047384 2363 0 0 java
Aug 25 18:21:35 test-a3-60-17 kernel: Memory cgroup out of memory: Kill process 76756 (java) score 1001 or sacrifice child
Aug 25 18:21:35 test-a3-60-17 kernel: Killed process 76513 (java) total-vm:26212772kB, anon-rss:4189536kB, file-rss:0kB, shmem-rss:0kB
Aug 25 18:21:35 test-a3-60-17 dockerd: time="2017-08-25T18:21:35.949063698+08:00" level=error msg="containerd: deleting container" error="exit status 1: \"container 812c82c5a7a5ae054e6f242215bdc4415a2d9b690768962a7bcd8d4676b16f60 does not exist\\none or more of the container deletions failed\\n\""
Aug 25 18:21:35 test-a3-60-17 mesos-slave[2905]: I0825 18:21:35.965833 2952 slave.cpp:3634] Handling status update TASK_FAILED (UUID: 031c0691-0dd0-4030-872e-d7d210c554c4) for task deploy-to-docker-business-product-rpc-test.a22e5797-897e-11e7-9837-f2f3c189fa2c of framework d637e32a-a1df-43eb-adaf-b1d2e3d6235a-0000 from executor(1)@192.168.60.17:38672
可以看到,在mesos和docker containerd对812c82c5a7a5做出反应之前,kernel因为内存限制的缘故,kill掉了一个进程。如果有机会找到76513和812c82c5a7a5的对应关系,问题基本就可以确认了。(补充:可以使用docker ps -q | xargs docker inspect --format ', ' | grep pid查看)
解决方法:增加内存
但是!
java项目增大内存是不解决问题的
提到docker 与 虚拟机的区别时, 常常会说“虚拟”和“隔离”的区别。假设一个16g内存的物理机,那么创建一个2g内存的虚拟机和2g内存容器,其jvm的表现便会有所不同。Java inside docker: What you must know to not FAIL some applications that collect information from the execution environment have been implemented before the existence of cgroups. Tools like ‘top‘, ‘free‘, ‘ps‘, and even the JVM ** is not optimized for executing inside a container**, a highly-constrained Linux process. Let’s check it out.
- 在 Docker 里跑 Java,趟坑总结, jvm无法感知到自己在容器中进行,默认堆的上限是物理机内存的四分之一,当容器的jvm没有设置xmx,即便容器内存设置的很大,也没有解决问题,导致容器会周期性重启(没有gc,逐渐累积到容器内存的限制值)。
- Java and Docker, the limitations 在java9/10 以后jvm 对container提供了原生支持,默认开启jvm useContainerSupport参数。There’s an experimental support in the JVM that has been included in JDK9 to support cgroup memory limits in container (i.e. Docker) environments. Check it out: http://hg.openjdk.java.net/jdk9/jdk9/hotspot/rev/5f1d1df0ea49 Java 8 终于支持 Docker
- 在docker中使用java的内存情况提到了容器内存与jvm堆内存的基本关系。
Max memory = [-Xmx] + [-XX:MaxPermSize] + number_of_threads * [-Xss].在设置jvm启动参数的时候 -Xmx的这个值一般要小于docker限制内存数,个人觉得 -Xmx:docker的比例为 4/5 - 3/4
jvm useContainerSupport 试验代码
public class App {
public static void main( String[] args ){
Runtime rt = Runtime.getRuntime();
System.out.println( "max memory: " + rt.maxMemory() / 1024 / 1024 );
}
}
运行一个java 容器,限制内存为512m,docker run -m=512m java bash,执行javac App.java;java App 输出 max memory: 123, 即123m,说明jvm 知道自己在容器中。
2020.12.23补充:java 现有的对容器的支持,例如useContainerSupport/XX:MaxRAMPercentage 等支持限定了堆内内存,并没有一个参数可以限定java 进程可以使用的总内存。 实践中出现了堆外内存使用较多 超过容器限制 进而导致java 进程被干掉的情况,因此需要 使用 -XX:MaxDirectMemorySize 限制下堆外内存。
2020.7.11补充: 之前一直尝试为java项目设置“最佳内存”,副作用就是项目负载飙升时容易OOM,后来发现,其实多给点内存也没关系。测试环境很多项目生存周期也不长,并且jvm也没有想象的那样,会贪婪地吃掉 配置的xmx所有的内存。对java 项目,prometheus 专门提供了相关的jmx exporter,可以对jvm 进行监控,进而对jvm的工作状态有一个深入的了解。 有越来越多的面向容器使用的os 开始支持 进程获取容器的cpu 和内存数据 容器场景选择什么 Linux 版本?
容器jvm最佳实践 非常好,提到了 UseAdaptiveSizePolicy 参数,可以使用 jstat -gc $pid 2s 查看真实的jvm 各个区域大小 及回收次数,rtt 值跟younggc 时间和频次有很大关系。
cpu
jvm 在容器内看到的cpu数不准确,会导致什么问题呢?jvm 以及很多 Java sdk 会根据系统的 CPU 数来决定创建多少线程,比如ParallelGC线程数,这就会导致JVM启动过多的GC线程,直接的结果就导致GC性能下降。Java服务的感受就是延时增加,监控曲线突刺增加,吞吐量下降。
Linux有两种IO:Direct IO和Buffered IO。Direct IO直接写磁盘,Duffered IO会先写到缓存再写磁盘,大部分场景下都是Buffered IO。美团使用的Linux内核3.X,社区版本中所有容器Buffer IO共享一个内核缓存,并且缓存不隔离,没有速率限制,导致高IO容器很容易影响同主机上的其他容器。
很多方面,容器内应用无法感知容器的存在,此外,容器间也在不常见的地方相互影响着。此时需要更改glibc、更深入点比如内核等。
监控jvm
手把手教你使用 Prometheus 监控 JVMJMX-Exporter 提供了两种用法:
- 启动独立进程。JVM 启动时指定参数,暴露 JMX 的 RMI 接口,JMX-Exporter 调用 RMI 获取 JVM 运行时状态数据,转换为 Prometheus metrics 格式,并暴露端口让 Prometheus 采集。
- JVM 进程内启动(in-process)。JVM 启动时指定参数,通过 javaagent 的形式运行 JMX-Exporter 的 jar 包,进程内读取 JVM 运行时状态数据,转换为 Prometheus metrics 格式,并暴露端口让 Prometheus 采集。 官方不推荐使用第一种方式,一方面配置复杂,另一方面因为它需要一个单独的进程,而这个进程本身的监控又成了新的问题
jar冲突
tomcat启动遇到NoSuchMethodError错误的排查思路
Understanding class path wildcards
The order in which the JAR files in a directory are enumerated in the expanded class path is not specified and may vary from platform to platform and even from moment to moment on the same machine. A well-constructed application should not depend upon any particular order. If a specific order is required, then the JAR files can be enumerated explicitly in the class path.
大意为:同一个目录下,jvm加载jar包顺序是无法保证的,每个系统的都不一样,甚至同一个系统不同的时刻加载都不一样。
所以问题便来了,很多开发经常抱怨:为什么我的代码可以本地启动成功,到docker环境就不可以。
为此,对于java 启动命令 java -cp /app/resources:/app/classes:/app/libs/.* $mainclass 将其扩充为 java -cp /app/resources:/app/classes:$custom_classpath:/app/libs/.* $mainclass。同一个/app/libs/.* 中的jar 加载顺序无法保证,那便将自定义classpath 提前。
Container stuck, can’t be stopped or killed, can’t exec into it either
jdk6 编译的项目运行在jdk8上
- 代码本身经由jdk6编译,运行在jdk8上
- 代码依赖的jar由jdk6编译
在docker-ce 1.3 以下会出现docker ps可以看到,但容器内jvm进程已经退出的情况。升级到docker-ce 1.7 仍未解决该问题。
2017.12.05 更新
现象描述:
- marathon ==> mesos 尝试杀死容器,但杀死失败
docker ps可以看到容器docker exec无法进入容器docker rm可以移除容器-
journalctl -xe -u docker.service可以看到:time="2017-12-05T10:14:01.066063275+08:00" level=info msg="Container 8f8020e79b13bcbf40298d3c9680cd1a838e16dc810ef3b1357eb3e75f78ef99 failed to exit within 120 seconds time="2017-12-05T10:14:01.066755930+08:00" level=warning msg="container kill failed because of 'container not found' or 'no such process': Cannot kill container 8f8020 time="2017-12-05T10:14:11.067151142+08:00" level=info msg="Container 8f8020e79b13 failed to exit within 10 seconds of kill - trying direct SIGKILL" time="2017-12-05T12:52:58.017517865+08:00" level=error msg="Error running exec in container: containerd: container not found"
通过观察容器中运行的tomcat日志,可以看到,10:12,docker向容器发送 term signal,tomcat 开始stop,docker logs --tail 200 8f8020e79b13日志如下
[album-facade]10:12:02 420 INFO org.springframework.beans.factory.support.DefaultListableBeanFactory:444 - Destroying singletons in org.springframework.beans.factory.support.DefaultListableBeanFactory@b342fcf: defining beans [mvcContentNegotiationManager,org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping#0,org.springframework.format.support.FormattingConversionServiceFactoryBean#0,org.springframework.web.servlet.mvc.method.annotation.RequestM...
Dec 5, 2017 10:12:05 AM org.apache.catalina.loader.WebappClassLoader checkThreadLocalMapForLeaks
SEVERE: The web application [/album-facade] created a ThreadLocal with key of type [java.lang.ThreadLocal] (value [java.lang.ThreadLocal@64de4a8c]) and a value of type [com.ibatis.sqlmap.engine.mapping.result.ResultObjectFactoryUtil.FactorySettings] (value [com.ibatis.sqlmap.engine.mapping.result.ResultObjectFactoryUtil$FactorySettings@70748134]) but failed to remove it when the web application was stopped. This is very likely to create a memory leak.
Dec 5, 2017 10:12:15 AM org.apache.coyote.http11.Http11Protocol destroy
INFO: Stopping Coyote HTTP/1.1 on http-8080
tomcat花了12秒停掉,但是docker认为容器还未停掉,等了120s到10:14,尝试kill,10s后仍然失败,然后任何对容器的操作就container not found。可能原因:移除容器的操作确实开始执行,但到了某一个步骤卡住或失败,导致一部分数据结构显示docker还在,但另一个部分数据结构已经删掉了。
docker认为容器一直“活着”,但主进程已经退出了。所以,主进程退出不等于容器退出。主进程退出后,docker还要回收各种资源,比如volume等等,耗时太长,或者干脆操作失败。
docker kill 失败,docker rm 成功,具体原因仍需解决!
Can’t stop docker container #35933 仍待解决。
2018.05.22补充, mesos 升级为1.6.0 时,可以强杀 该容器,算是变相解决了该问题。
docker 停住
环境:
- ubuntu 16.04
- kernel 4.4.0
- docker 17.09-ce
12月13日下午排查时发现
- docker 日志停留在 12.12 18.52
- docker rm 容器无法remove掉
- docker 无法停掉,
systemctl stop docker卡住 - kill docker 所有进程,
rm /var/lib/docker时,部分文件无法删除,deivce or resource is busy /var/log/kern.log大量的[1055520.745390] unregister_netdevice: waiting for veth54a2de6 to become free. Usage count = 1 Dec 13 15:53:58 test-a1-60-36 kernel: [1055530.985735] unregister_netdevice: waiting for veth54a2de6 to become free. Usage count = 1 Dec 13 15:54:09 test-a1-60-36 kernel: [1055541.226086] unregister_netdevice: waiting for veth54a2de6 to become free. Usage count = 1 Dec 13 15:54:19 test-a1-60-36 kernel: [1055551.466446] unregister_netdevice: waiting for veth54a2de6 to become free. Usage count = 1
发现物理机有一个容器日志打了4t
解决 Swarm Kernel Panic after “unregister_netdevice”,升级了内核版本到4.14.5
docker pull 镜像失败
一开始认为是权限不够,后来发现同样配置的其它机器没有问题,同时将images server地址配置为了insecurity-registry。后来一个很偶然的原因发现整个物理机的磁盘都满了。
df -h 查看整个磁盘的占用情况。docker 还有一个现象
Filesystem Size Used Avail Use% Mounted on
udev 32G 0 32G 0% /dev
tmpfs 6.3G 675M 5.7G 11% /run
/dev/sda3 7.1T 217G 6.5T 4% /
tmpfs 32G 12K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/sda2 181M 126M 43M 75% /boot
overlay 7.1T 217G 6.5T 4% /var/lib/docker/overlay2/45cdd4a0e6f230a0018ed098edb136b56b4994143eb585f9f5fa5eb36921825d/merged
shm 64M 0 64M 0% /var/lib/docker/containers/7ec38089c44abdd72b4fa208f66415bbd6fe49d1bf468419764ed50724f932a2/shm
overlay 7.1T 217G 6.5T 4% /var/lib/docker/overlay2/49f77221ecc6424de4a3523862a16b1a061621f25f1d1537f519eb33ac2d9e55/merged
shm 64M 0 64M 0% /var/lib/docker/containers/4d50cb3eb2cd73c0e951df190299c0e0fdff87dd51c4a371c5b8a0c15706435b/shm
overlay 7.1T 217G 6.5T 4% /var/lib/docker/overlay2/0f5d0f0db15bb500ad4c881ad200934d0ab9f2511e2be17dca3ec456e0ea5829/merged
shm 64M 0 64M 0% /var/lib/docker/containers/ae687ad77a157b2b1e1ad8137a1fec92f65926c66fd0675eac6f1b908d98eedf/shm
具体到某一个/var/lib/docker/overlay2/45cdd4a0e6f230a0018ed098edb136b56b4994143eb585f9f5fa5eb36921825d/merged 之类的文件夹,其磁盘使用情况与物理机磁盘/dev/sda3 是一致的。笔者一开始不知道这个情况,尝试分析 45cdd4a0e6f 归哪个容器所有:docker ps | awk '{print $1}' | xargs docker inspect | grep 45cdd4a0e6f
发现磁盘占满后,du -sh * 逐步查看耗费空间最大的文件(不要直接使用du -sh /)
$ cd /
$ du -sh *
$ cd /var
$ du -sh *
$ cd /var/log
$ du -sh *
后来发现是某一个项目日志打的太多了,在此建议测试环境配置定时任务,周期性的清理掉项目的日志。
项目启动是访问mysql 失败
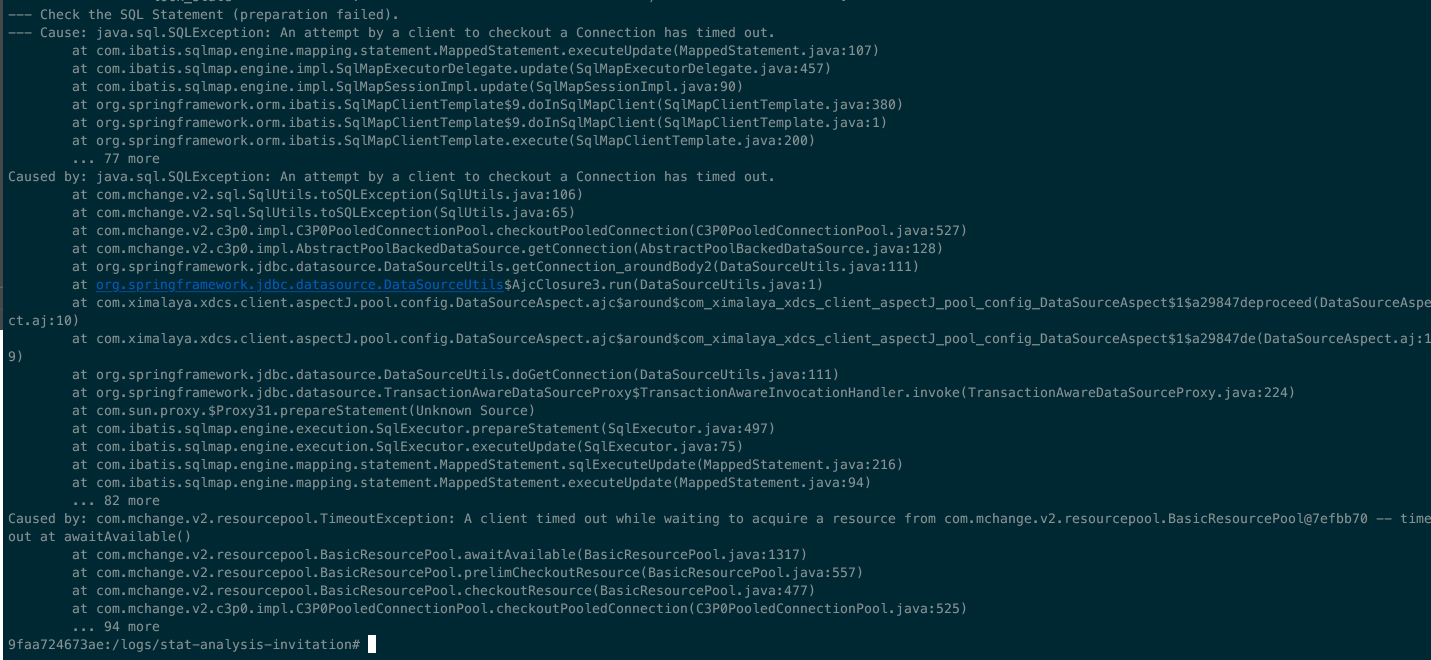
运行在 docker 18.03.0-ce 的服务,启动时报连接 mysql 超时(如上图所示)。而较老版本17.09.0-ce 则无此问题。
第一回合
怀疑项目启动连接数据库时,容器还未准备好网络。
因此呢,可以修改 c3p0 连接池配置,使 initialPoolSize=0。initialPoolSize 表示连接池初始化时创建的连接数,为0后,c3p0会在第一次接收用户请求时 才建立连接。
结果,没有用
第二回合
验证办法,实现一个BeanFactoryPostProcessor子类,其回调方法 postProcessBeanFactory 执行一个类似ping 的方法
public void ping() {
int timeOut = 3000; //超时应该在3钞以上
boolean status = false; // 当返回值是true时,说明host是可用的,false则不可。
try {
status = InetAddress.getByName("192.168.x.x").isReachable(timeOut);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("docker is reachable " + status);
log.info("docker is reachable {}", status);
}
java doc 对 postProcessBeanFactory 的解释 为 Modify the application context’s internal bean factory after its standard initialization. All bean definitions will have been loaded, but no beans will have been instantiated yet. 意图就是在 jdbc 初始化连接池之前,执行ping方法
结果:可以ping 通,说明不是docker 网络的问题
第三回合
怀疑是 c3p0 配置的问题,以此为出发点 google 一下,c3p0的连接池优化导致的异常 对照实际项目配置,发现确实略短,改大后,问题解决。
- 原有配置
jdbc.checkoutTimeout=1000 - 修改后
jdbc.checkoutTimeout=60000
以当下粗浅的理解,checkoutTimeout 表示从连接池中 获取 连接的最大允许时间。若连接池有空闲连接,则直接返回,否则还需要 与远程db 建连接,耗时时间就会略长。