简介
这是我见过最好的NumPy图解教程!NumPy是Python中用于数据分析、机器学习、科学计算的重要软件包。它极大地简化了向量和矩阵的操作及处理。《用python实现深度学习框架》用python 和numpy 实现了一个深度学习框架MatrixSlow
- 支持计算图的搭建、前向、反向传播
- 支持多种不同类型的节点,包括矩阵乘法、加法、数乘、卷积、池化等,还有若干激活函数和损失函数。比如向量操作pytorch 跟numpy 函数命名都几乎一样
- 提供了一些辅助类和工具函数,例如构造全连接层、卷积层和池化层的函数、各种优化器类、单机和分布式训练器类等,为搭建和训练模型提供便利
安装 Ubuntu 20.04 下的 PyTorch(CPU版)安装及配置
什么是pytorch
Pytorch详细介绍(上)Pytorch是一个很容易学习、使用和部署的深度学习库。PyTorch同时提供了更高性能的C++ API(libtorch)。Pytorch使用Tensor作为核心数据结构,Tensor(张量)是神经网络世界的Numpy,其类似与Numpy数组,但是又不同于Numpy数组。为了提高Tensor的计算速度,有大量的硬件和软件为了Tensor运算进行支持和优化。总得来说,Tensor具有如下特点:
- 具有类似Numpy的数据,Tensor可以与Numpy共享内存;
- 可以指定计算设备,例如,设定Tensor是在CPU上计算,还是在GPU上计算;
- Tensor可微分。
- 通过访问张量的device属性可以获取张量所在的设备
PyTorch工作流以及与每个步骤相关联的重要模块
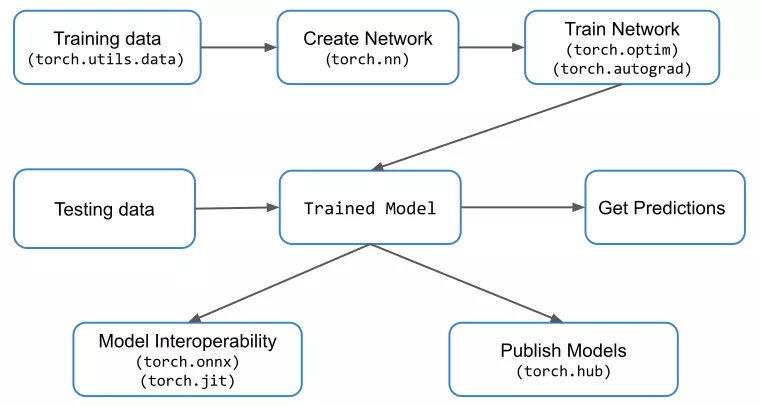
[源码解析] PyTorch 分布式(8) ——– DistributedDataParallel 之 论文篇
- PyTorch organizes values into Tensors which are generic n-dimensional arrays with a rich set of data manipulating operations.
- A Module defines a transform from input val- ues to output values, and its behavior during the forward pass is specified by its forward member function. A Module can contain Tensors as parameters. For example, a Linear Module contains a weight parameter and a bias parameter, whose forward function generates the output by multiplying the input with the weight and adding the bias. An application composes its own Module by stitching together native Modules (e.g., linear, convolution, etc.) and Functions (e.g., relu, pool, etc.) in the custom forward function.
- A typical training iteration contains a forward pass to generate losses using inputs and labels, a backward pass to compute gradients for parameters, and an optimizer step to update parameters using gradients. More specifically, during the forward pass, PyTorch builds an autograd graph to record actions performed. Then, in the backward pass, it uses the autograd graph to conduct backpropagation to generate gradients. Finally, the optimizer applies the gradients to update parameters. The training process repeats these three steps until the model converges.
数据读取
PyTorch 使用 Dataset 类与 DataLoader 类的组合,来得到数据迭代器。
- Dataset用来表示数据集。通过继承 Dataset 类来自定义数据集的格式、大小和其它属性,后面就可以供 DataLoader 类直接使用。
- 如果数据量很大,考虑到内存有限、I/O 速度等问题,在训练过程中不可能一次性的将所有数据全部加载到内存中,也不能只用一个进程去加载,所以就需要多进程、迭代加载,而 DataLoader 就是基于这些需要被设计出来的。DataLoader 是一个迭代器,最基本的使用方法就是传入一个 Dataset 对象,它会根据参数 batch_size 的值生成一个 batch 的数据,节省内存的同时,它还可以实现多进程、数据打乱等处理。
from torch.utils.data import DataLoader
tensor_dataloader = DataLoader(dataset=my_dataset, # 传入的数据集, 必须参数
batch_size=2, # 输出的batch大小
shuffle=True, # 数据是否打乱
num_workers=0) # 进程数, 0表示只有主进程
# 以循环形式输出
for data, target in tensor_dataloader:
print(data, target)
Torchvision 库中的torchvision.datasets包中提供了丰富的图像数据集的接口。常用的图像数据集,例如 MNIST、COCO 等,这个模块都为我们做了相应的封装。 它的工作方式是先从网络上把数据集下载到用户指定目录,然后再用它的加载器把数据集加载到内存中。最后,把这个加载后的数据集作为对象返回给用户。
# 以MNIST为例
import torchvision
mnist_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=None,
target_transform=None,
download=True)
模块
import torch.nn as nn
class LinearModel(nn.Module):
def __init__(self,ndim):
super(LinearModel,self).__init__()
self.ndim = ndim
# 需要使用nn.Parameter来包装这些参数,使之成为子模块(仅仅由参数构成的子模块),这是因为在后续训练的时候需要对参数进行优化,只有将张量转换为参数才能在后续的优化过程中被优化器访问到。
self.weight = nn.Parameter(torch.randn(ndim,1)) # 定义权重
self.bias = nn.Parameter(torch.randn(1)) # 定义偏置
def forward(self,x):
# y = Wx +b
return x.mm(self.weight) + self.bias
模块本身是一个类nn.Module,PyTorch的模型通过继承该类,在类的内部定义子模块的实例化,通过前向计算调用子模块,最后实现深度学习模型的搭建。
class Module:
dump_patches: bool = False
_version: int = 1
training: bool # 本网络是否正在训练
_is_full_backward_hook: Optional[bool]
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict() # 在训练过程中会随着 BP 而更新的参数
self._buffers = OrderedDict() # 在训练过程中不会随着 BP 而更新的参数
self._non_persistent_buffers_set = set()
self._backward_hooks = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict() # 本网络下属的子模块,采取迭代的方式进行定义
Module的成员变量主要分为状态参数和hooks函数。当一个模型的网络结构被定义之后,self._parameters 和 self._buffers的组合是一个模型的具体状态。
优化器
批量梯度下降(Batch gradient descent)用到数据集所有的数据 做梯度下降
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
这在解决实际问题时通常是不可能,想想Imagenet1000有100G以上的图像,内存装不下,速度也很慢。于是一次取一个样本,就有了随机梯度下降
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function , example , params)
params = params - learning_rate * params_grad
sgd方法缺点很明显,梯度震荡,所以就有了后来大家常用的小批量梯度下降算法(Mini-batch gradient descent)。
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
总结一下SGD算法的毛病
- 学习率大小和策略选择困难,想必动手经验丰富的自然懂。
- 学习率不够智能,对参数的各个维度一视同仁。
- 同时面临局部极值和鞍点的问题。
AI初识:为了围剿SGD大家这些年想过的那十几招 有Momentum 动量法、NAG算法、Adagrad法、Adadelta与Rmsprop、Adam方法等。 所以 优化器要专门作为一个模块抽出来。
使用gpu
torch.cuda用于设置 cuda 和运行cuda操作。它跟踪当前选定的GPU,默认情况下,用户分配的所有CUDA张量都将在该设备上创建。用户可以使用 torch.cuda.device 来修改所选设备。一旦分配了张量,可以对其执行操作,而不考虑所选设备,PyTorch 会把运行结果与原始张量放在同一设备上。
cpu = torch.device("cpu")
gpu = torch.device("cuda:0") # 使用第一个gpu
x = torch.rand(10)
x = x.to(gpu)
移动模型到GPU这个动作的背后究竟做了哪些操作?调用 cuda 或者 to 方法来移动模型到GPU,其实就是把模型的self._modules、self._parameters 和 self._buffers 移动到 GPU。实际上没有对 self._modules 进行移动。这个移动过程是递归调用的,是把模型每个子modules 的 _parameters 和 _buffers 都移动到了 GPU 之上。
class Module:
def to(self, *args, **kwargs):
def convert(t):
...
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
return self._apply(convert)
def _apply(self, fn):
for module in self.children():
module._apply(fn)
for key, param in self._parameters.items():
...
for key, buf in self._buffers.items():
if buf is not None:
self._buffers[key] = fn(buf)
return self
PyTorch在进行深度学习训练的时候,有4大部分的显存开销,分别是模型参数(parameters),模型参数的梯度(gradients),优化器状态(optimizer states)以及中间激活值(intermediate activations)
1.模型定义:定义了模型的网络结构,产生模型参数;
while(你想训练):
2.前向传播:执行模型的前向传播,产生中间激活值;
3.后向传播:执行模型的后向传播,产生梯度;
4.梯度更新:执行模型参数的更新,第一次执行的时候产生优化器状态。
用v0.1.0 来解释正向和反向传播
看了非常多文章, 找到一篇比价好的,从v0.1.0 视角讲,清晰很多。 读源码理解 Pytorch 的 autograd 机制 本文的目的是为了让大家能有个初步的理解,故使用的源码是 Pytorch v0.1.0。 那个时候 tensor 叫 Variable
import torch
from torch.autograd import Variable
y = Variable(torch.randn(0, 10)).view(1, 10)
x = Variable(torch.randn(0, 20)).view(1, 10)
W = Variable(torch.randn(1, 1), requires_grad=True)
learning_rate = 0.001
for _ in range(100000):
y_ = torchy.mm(W, x)
loss = torch.sum(torch.abs(y_ - y))
loss.backward()
W.data -= W.grad.data * learning_rate # 拿着梯度更新参数,对应高版本的 optimizer.step()
W.grad.data.zero_()
前向传播
在前向运算中 构建 计算图,以计算 y_-y 为例,在完成减法运算的同时,通过重写减法运算法带了私货:创建了Sub 实例 将Sub 与 y 与 y_ 对应的Function 关联起来 组成计算图。
y_-y
y_.sub(y)
Sub()(y_,y) # Variable 计算创建出一个 Function
Function.__call__
Function._do_forward(*input)
Sub.forward(*unpacked_input)
output = Variable(output_tensor, Sub) # 中间 Variable,虽然不可见,但是串联 Function 的桥梁
Sub.previous_functions = (y_.creator, y.creator)
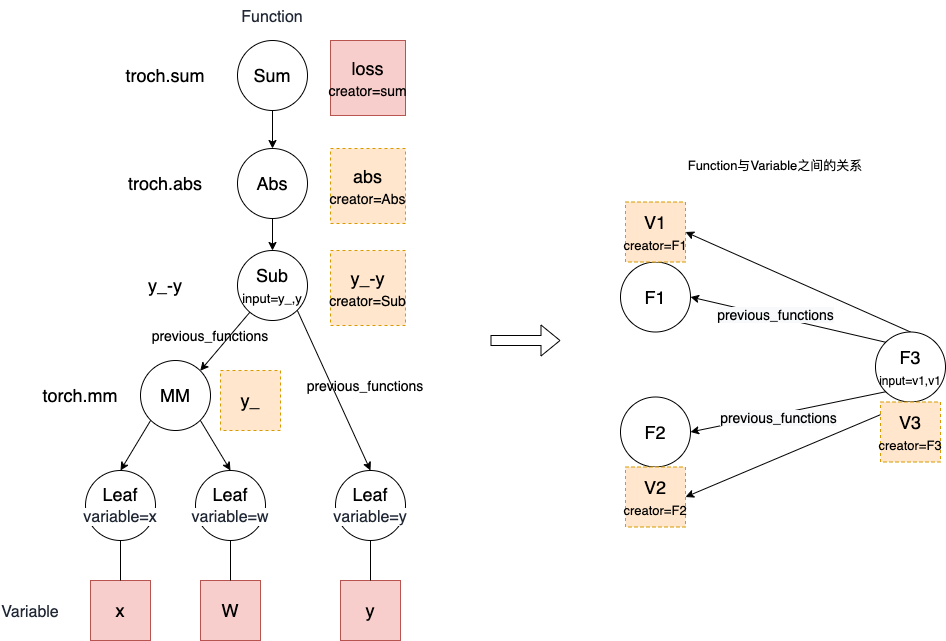
y_ - y,对应的方法是 __sub__,开头结尾都是双下划线的方法是 Python 语言中的 magic method,在这里 __sub__ 的作用是重写减法运算符。可以看到减法最终会调用的 Sub 这个类的实例
class Variable(object):
def __sub__(self, other):
return self.sub(other)
def sub(self, other):
if isinstance(other, Variable):
return Sub()(self, other)[0]
else:
return SubConstant(other)(self)[0]
class Sub(Function):
def forward(self, a, b):
return a.sub(b)
def backward(self, grad_output):
return grad_output, grad_output.neg()
Sub 的父类是 Function, Sub()(self, other) 也就是 Function.__call__ ==> Function._do_forward
class Function(object):
def __call__(self, *input):
return self._do_forward(*input)
def _do_forward(self, *input):
unpacked_input = tuple(arg.data for arg in input)
raw_output = self.forward(*unpacked_input)
if not isinstance(raw_output, tuple):
raw_output = (raw_output,)
self.needs_input_grad = tuple(arg.creator.requires_grad for arg in input)
self.requires_grad = any(self.needs_input_grad)
# 创建 Variable 时 将Function 作为Variable 的creator
output = tuple(Variable(tensor, self) for tensor in raw_output)
# 建立关联关系 ==> 构建 计算图
self.previous_functions = [(arg.creator, id(arg)) for arg in input]
self.output_ids = {id(var): i for i, var in enumerate(output)}
return output
...
反向传播
广度优先遍历所有 functions 并执行_do_backward:从 loss.creator 也就是图的终点Function 开始,拿到 previous_functions 执行 _do_backward,并将prev_fn.previous_functions 加入ready queue。
loss.backward
Variable.backward(self,grad)
Variable._execution_engine.run_backward(self, grad)
ExecutionEngine.run_backward(self,variable,grad)
dependencies = Variable._compute_dependencies(variable.creator) ## 从图的终点Function 开始广度优先遍历 所有functions 统计下信息
ready = [(variable.creator, (grad,))]
fn, grad = ready.pop()
while len(ready) > 0:
grad_input = fn._do_backward(*grad) # 执行各个Function 定义的 backward 方法
for (prev_fn, arg_id), d_prev_fn in zip(fn.previous_functions, grad_input): # 广度优先遍历所有 functions 并执行_do_backward
output_nr = self._free_backward_dependency(dependencies, prev_fn, fn, arg_id)
is_ready = self._is_ready_for_backward(dependencies, prev_fn)
if is_ready:
ready.append((prev_fn, (d_prev_fn,)))
- 反向传播传播的啥?

- 以减法
tmp = y_-y为例,反向 上游 tmp 的梯度 grad_output 通过 Sub.backward 传播 给y_的是grad_output * 1,给y 的是grad_output * -1,对应到链式法则 就是 $\frac{d_loss}{dy} = \frac{d_loss}{d_tmp} * \frac{d_tmp}{dy}$。 - 各种Function backward 的逻辑是: $\frac{dl}{df} * \frac{df}{d_input}$ (df 表示当前function),有几个input 算几个,代码上没按矩阵乘法形式来,直接给了结果。
- Function.input 可以存储input Variable,估计也可以存储其它状态,比如分段函数 可以在forward 时记录用了哪个分段,backward时就可以 用该分段的导数,这就解释了为什么分段函数也可以反向传播。可以对照 Sub/Mul/Div backward 方法找找感觉。
class Sub(Function):
def backward(self, grad_output):
return grad_output, grad_output.neg()
class Mul(Function):
def forward(self, a, b):
self.input = (a, b)
return a.mul(b)
def backward(self, grad_output):
a, b = self.input
return grad_output.mul(b), grad_output.mul(a)
class Div(Function):
def forward(self, a, b):
self.input = (a, b)
return a.div(b)
def backward(self, grad_output):
a, b = self.input
return grad_output.div(b), grad_output.neg().mul(a).div_(b).div_(b)
更新 Variable 中 grad 的逻辑在哪里呢?在 Leaf 这个特殊的 Function 里面。可以看到,相对于普通的计算 Function 来说,Leaf 在 backward 中做的事情是更新 grad。
class Leaf(Function):
def __init__(self, variable, requires_grad):
self.variable = variable
self.output_ids = {id(variable): 0}
self.previous_functions = []
self.requires_grad = requires_grad
self.backward_hooks = OrderedDict()
def _do_forward(self, *input):
raise NotImplementedError
def _do_backward(self, *grad_output):
assert len(grad_output) == 1
for hook in self.backward_hooks.values():
hook(grad_output, grad_output)
self.variable.grad.add_(grad_output[0])
return tuple()
对于backward_hooks, DDP 使用构造时注册的 autograd hooks 来触发梯度同步。当一个梯度准备好时,它在该梯度累加器上的相应 DDP 钩子将触发,在 autograd_hook 之中进行all-reduce。allreduce操作完成,将平均梯度写入param.grad所有参数的字段。所有进程的梯度都会reduce,更新之后,大家的模型权重都相同。所以在向后传播完成之后,跨不同DDP进程的对应的相同参数上的 grad 字段应该是相等的。
观察一个运行中的Tensor
Q = {Tensor}
data = {Tensor} tensor(-12.) # 该张量的数据
device = {device} cpu # 存放该张量的设备类型
dtype = {dtype} torch.float32 # 张量的数据类型
grad = {NoneType} None # 保存数据data对应的梯度,和数据data的形状一样
grad_fn = {SubBackward0} # grad_fn的作用是记录创建该张量时所用的函数,每一个前向传播操作的函数都有与之对应的反向传播函数用来计算输入的各个 variable 的梯度,这些函数的函数名通常以Backward结尾
metadata = {dict: 0} {}
next_functions = {tuple: 2}
0 = {tuple: 2} (<MulBackward0 object at 0x000001F9547A5848>, 0)
1 = {tuple: 2} (<PowBackward0 object at 0x000001F9547A53C8>, 0)
__len__ = {int} 2
requires_grad = {bool} True # 表示该Tensor是否需要求导,如否,在反向传播过程中,该节点所在的子图会被排除在计算过程之外。
is_cuda = {bool} False
is_leaf = {bool} False # 记录该张量是否是叶子节点
is_meta = {bool} False
is_mkldnn = {bool} False
is_mlc = {bool} False
is_quantized = {bool} False
is_sparse = {bool} False
is_sparse_csr = {bool} False
is_vulkan = {bool} False
is_xpu = {bool} False
layout = {layout} torch.strided
name = {NoneType} None
names = {tuple: 0} ()
ndim = {int} 0
output_nr = {int} 0
requires_grad = {bool} True
shape = {Size: 0} torch.Size([])
各种大杂烩
一文详解pytorch的“动态图”与“自动微分”技术 - DL-Practise的文章 - 知乎
- 我们手工编写的forward函数就是pytorch前向运行的动态图。当代码执行到哪一句的时候,网络就运行到哪一步。
- 实际上pytorch并没有显式的去构建一个所谓的动态图,本质就是按照forward的代码执行流程走了一遍而已。那么对于反向传播,因为我们没有构建反向传播的代码,pytorch也就无法像前向传播那样,通过我们手动编写的代码执行流进行反向传播。那么pytorch是如何实现精确的反向传播的呢?其实最大的奥秘就藏在tensor的grad_fn属性里面。Pytorch中的tensor对象都有一个叫做grad_fn的属性,它实际上是一个链表。grad_fn是python层的封装,其实现对应的就是pytorch源码在autograd下面的node对象,为C++实现
- Pytorch中的tensor有两种产生方式,一种是凭空创建的,例如一些op里面的params,训练的images,这些tensor,他们不是由其他tensor计算得来的,而是通过torch.zeros(),torch.ones(),torch.from_numpy()等凭空创建出来的。另外一种产生方式是由某一个tensor经过一个op计算得到,例如tensor a通过conv计算得到tensor b。其实这两种op创建方式对应的就是leaf节点(叶子节点)和非leaf(非叶子节点)。非leaf节点的grad_fn是有值的,因为它的梯度需要继续向后传播给创建它的那个节点。而leaf节点的grad_fn为None,因为他们不是由其他节点创建而来,他们的梯度不需要继续反向传播。
-
tensor的grad_fn是如何构建的?无论是我们自己编写的上层代码,还是在pytorch底层的op实现里面,并没有显示的去创建grad_fn,那么它是在何时,又是如何组装的?Pytorch会对所有底层算子进一个二次封装,在做完正常的op前向之后,增加了grad_fn的设置,next_functions的设置等流程。PS: grad_fn的作用是记录创建该张量时所用的函数
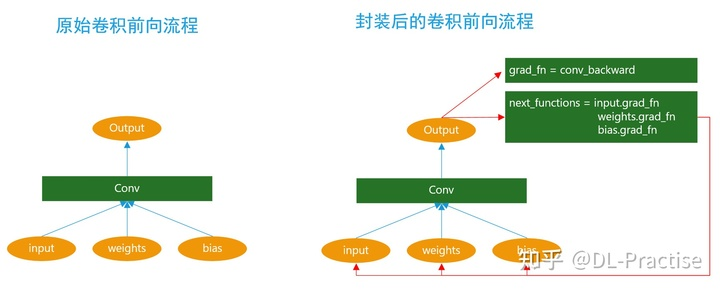
- 每一个前向传播操作的函数都有与之对应的反向传播函数用来计算输入的各个 variable 的梯度,这些函数的函数名通常以Backward结尾。比如 加法对应 AddBackward。 在pytorch v0.1.0 中
class Sub(Function): def forward(self, a, b): return a.sub(b) def backward(self, grad_output): return grad_output, grad_output.neg() torch.autograd.backward(z) == z.backward()是等价的,不管正向 反向传播套了多少壳,Pytorch中所有的计算其实都可以回归到Tensor上,矩阵计算。- optimizer.step()这个部分, 里面的逻辑也非常简单, 就是刚刚有AccumulateGrad( AccumulateGrad 会放在 backward 的最后一个 node 拿來做累加 grad) 到的训练参数,就代表需要update它的参数,在optimizer中就会去找那些需要更新。 对应到pytorch v0.1.0
w = Variable(w - 0.1 * w.grad.data,requires_grad=True)
《用python实现深度学习框架》:从计算图中作为结果的节点开始,依次从后向前,每个节点都将结果 对自己的雅克比矩阵 和 自己对父节点的雅克比矩阵 传给父节点,根据链式法则,父节点将这二者想乘就得到 结果对自己的雅克比矩阵。PS: 所以反向传播这块,虽然意思差不多,但各家实现差异还是蛮大的。
反向传播原理的演算上(比如基于两层感知机 推导loss 对每一个 w 的偏微分)、矩阵表达上、代码实现上(计算图, 不同的框架库也有不同的实现)形态是不同的,比较难理论与实际结合,这个在学习上要注意。
部署
如何部署 PyTorch 模型 TorchServe
其它
PyTorch Hub,通过PyTorch Hub,用户可以获得一系列预训练的深度学习模型,主要包括计算机视觉、自然语言处理、生成式模型和音频模型等,这些预训练模型的出现能有效地加快用户开发新型的深度学习模型,方便用户构建基线模型和复现深度学习模型的效果。
PyTorch Lightning工具学习Pytorch Lightning是在Pytorch基础上进行封装的库(可以理解为keras之于tensorflow),为了让用户能够脱离PyTorch一些繁琐的细节,专注于核心代码的构建,提供了许多实用工具,可以让实验更加高效。 文中以MNIST 为例列出了 使用原生pytorch 和PyTorch Lightning 的代码对比。
