简介
linux网络编程中,各层有各层的struct,但有一个struct是各层通用的,这就是描述接收和发送数据的struct sk_buff.
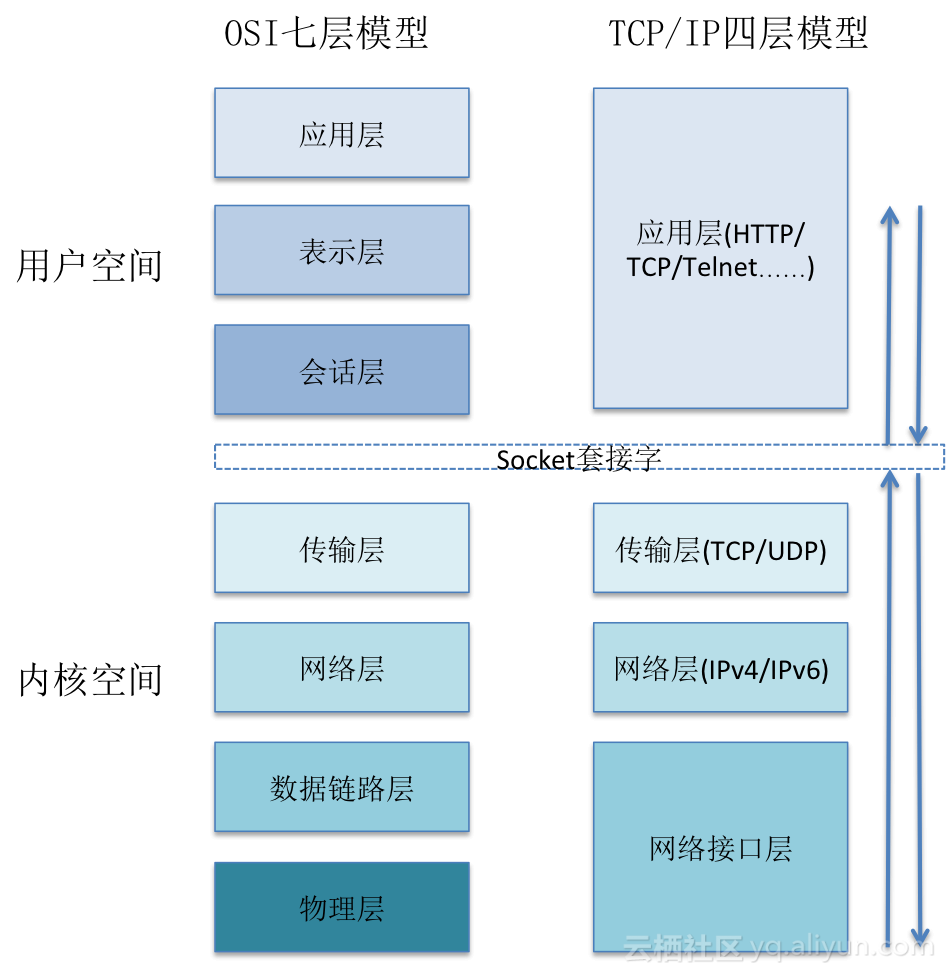
2019.7.5补充:应用层和内核互通的机制是通过 Socket 系统调用,经常有人会问,Socket 属于哪一层?其实它哪一层都不属于,它属于操作系统的概念,而非网络协议分层的概念。只不过操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。
从 TCP/IP 协议栈的角度来看,传输层以上的都是应用程序的一部分,Linux 与传统的 UNIX 类似,TCP/IP 协议栈驻留在内核中,与内核的其他组件共享内存。传输层以上执行的网络功能,都是在用户地址空间完成的。
TCP 层会根据 TCP 头中的序列号等信息,发现它是一个正确的网络包,就会将网络包缓存起来,等待应用层的读取。应用层通过 Socket 监听某个端口,因而读取的时候,内核会根据 TCP 头中的端口号,将网络包发给相应的Socket。
宏观
创建
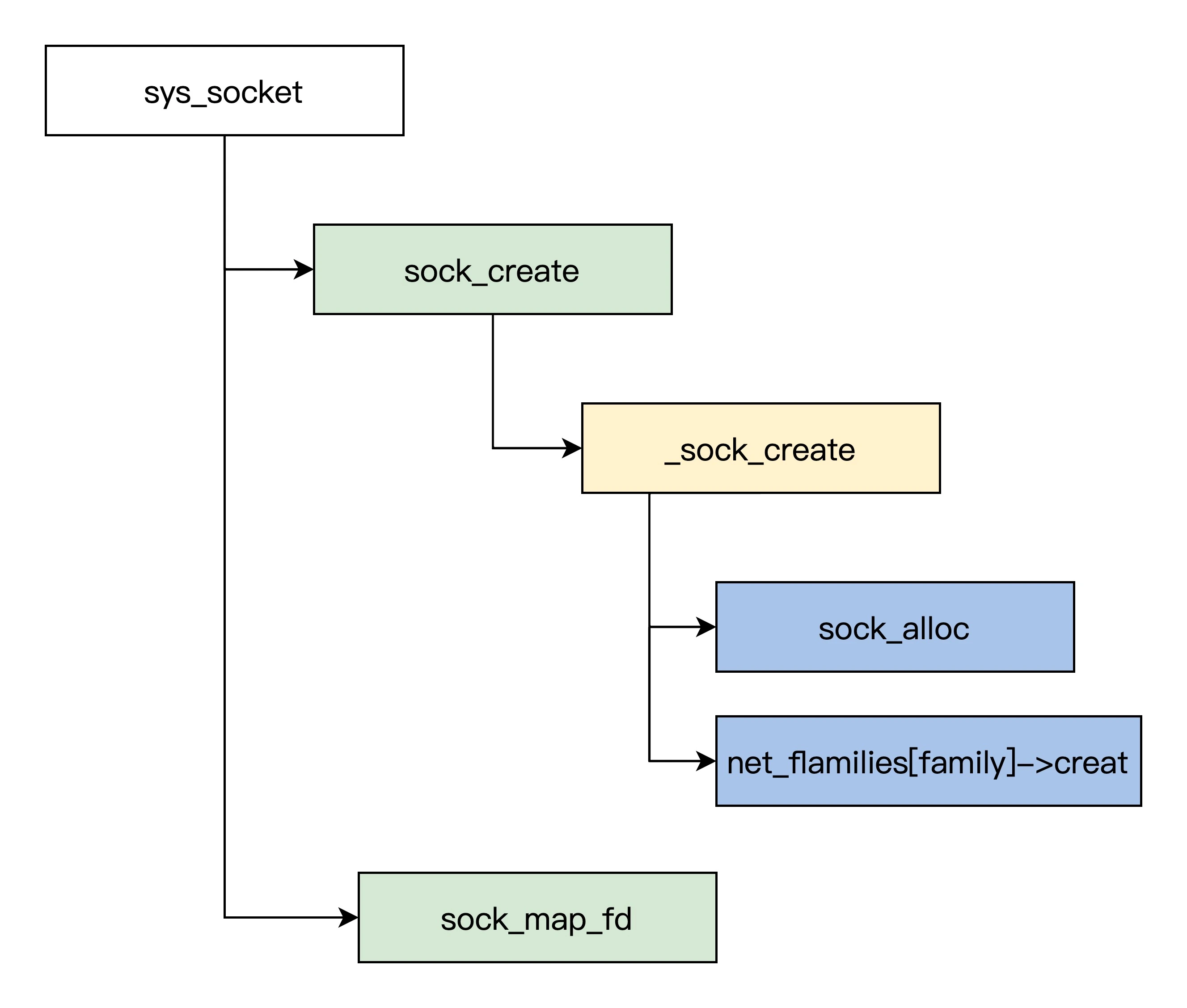
sock_create 函数完成通用套接字创建、初始化任务后,再调用特定协议族(上图net_families[family])的套接字创建函数,对于 TCP/IP 协议栈,协议族将设置为 AF_INET。
建立连接
那些你不知道的TCP冷门知识!在Linux中,一般情况下都是内核代理三次握手的,当client端调用 connect() 之后内核负责发送SYN,接收SYN-ACK,发送ACK。然后 connect() 系统调用才会返回,客户端侧握手成功。而服务端的Linux内核会在收到SYN之后负责回复SYN-ACK再等待ACK之后才会让 accept() 返回,从而完成服务端侧握手。于是Linux内核就需要引入半连接队列(用于存放收到SYN,但还没收到ACK的连接)和全连接队列(用于存放已经完成3次握手,但是应用层代码还没有完成 accept() 的连接)两个概念,用于存放在握手中的连接。
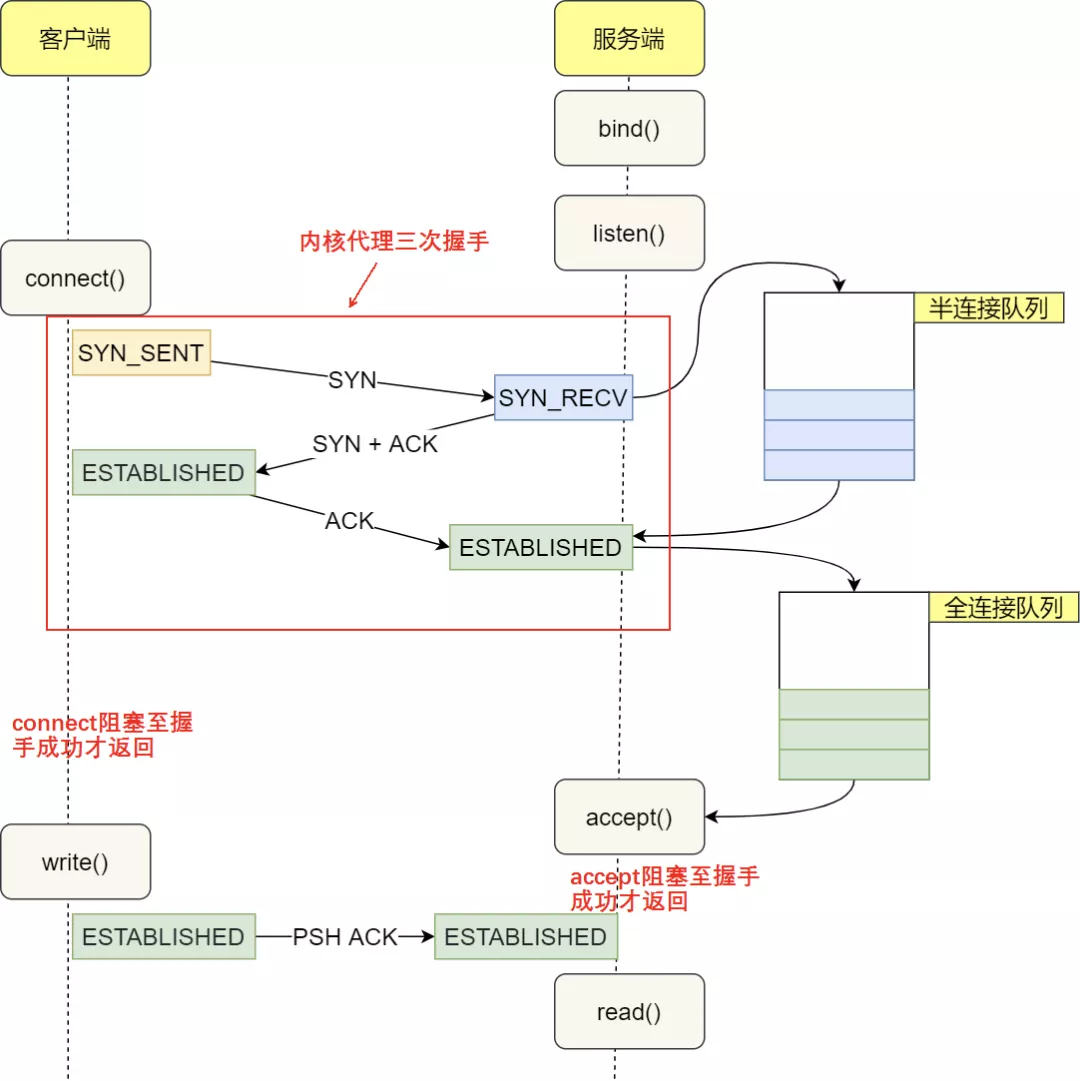
sync 和accept 队列的长度,sync 的重试次数都可以设置。如果应用程序处理较慢,会导致accept 队列。sync 攻击(伪造很多客户端ip 发送sync请求,但不发送ack)会导致sync 队列满。
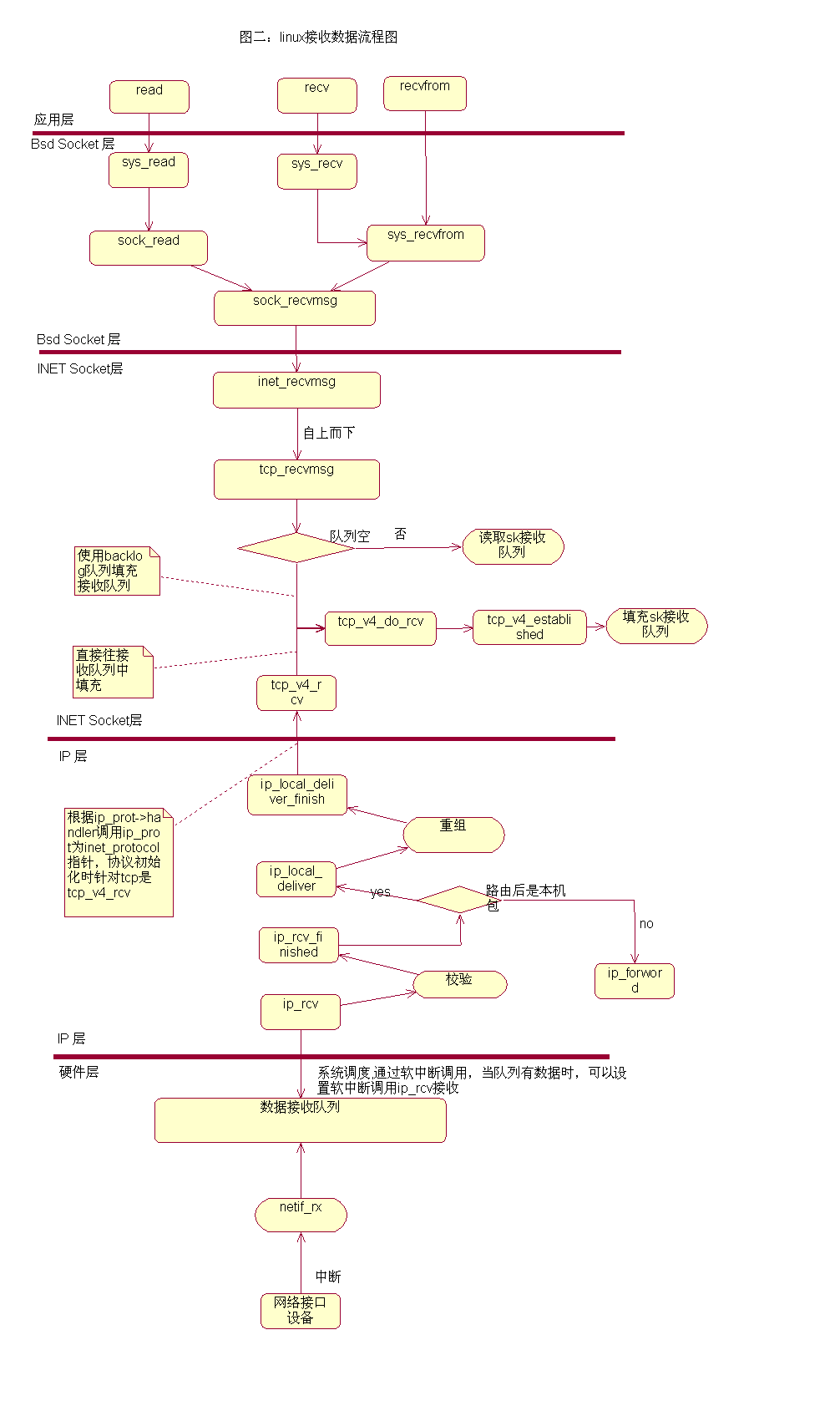
数据接收过程
容器网络一直在颤抖,罪魁祸首竟然是 ipvs 定时器在内核中,网络设备驱动是通过中断的方式来接受和处理数据包。当网卡设备上有数据到达的时候,会触发一个硬件中断来通知 CPU 来处理数据,此类处理中断的程序一般称作 ISR (Interrupt Service Routines)。ISR 程序不宜处理过多逻辑,否则会让设备的中断处理无法及时响应。因此 Linux 中将中断处理函数分为上半部和下半部。上半部是只进行最简单的工作,快速处理然后释放 CPU。剩下将绝大部分的工作都放到下半部中,下半部中逻辑由内核线程选择合适时机进行处理。 Linux 2.4 以后内核版本采用的下半部实现方式是软中断,由 ksoftirqd 内核线程全权处理, 正常情况下每个 CPU 核上都有自己的软中断处理数队列和 ksoftirqd 内核线程。
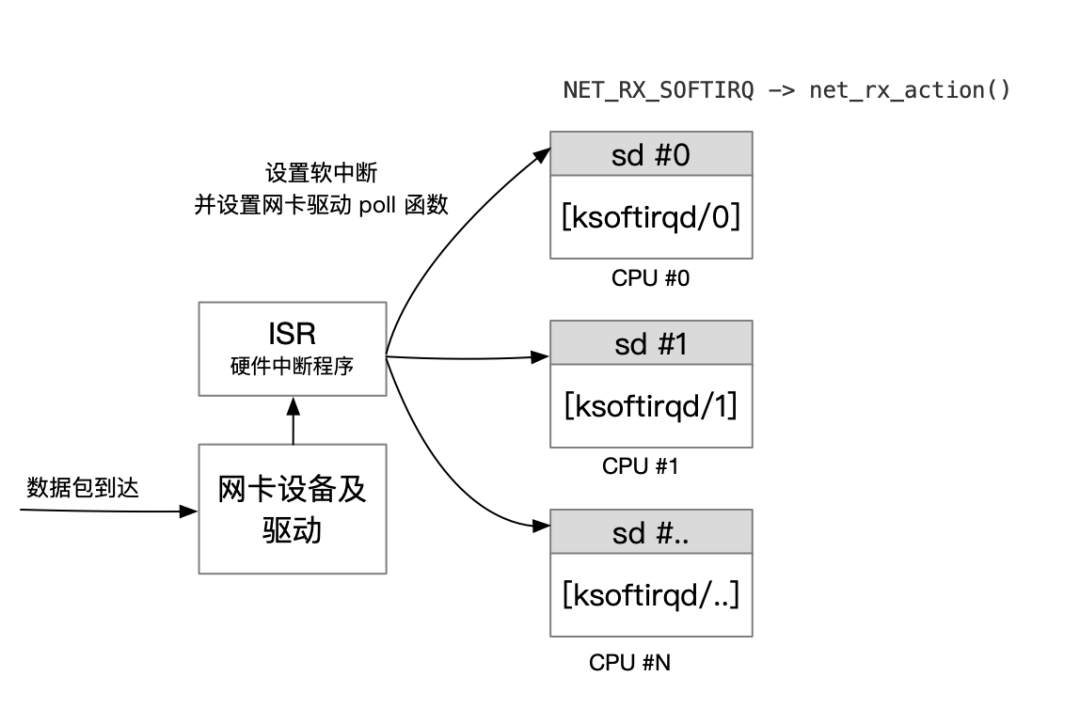
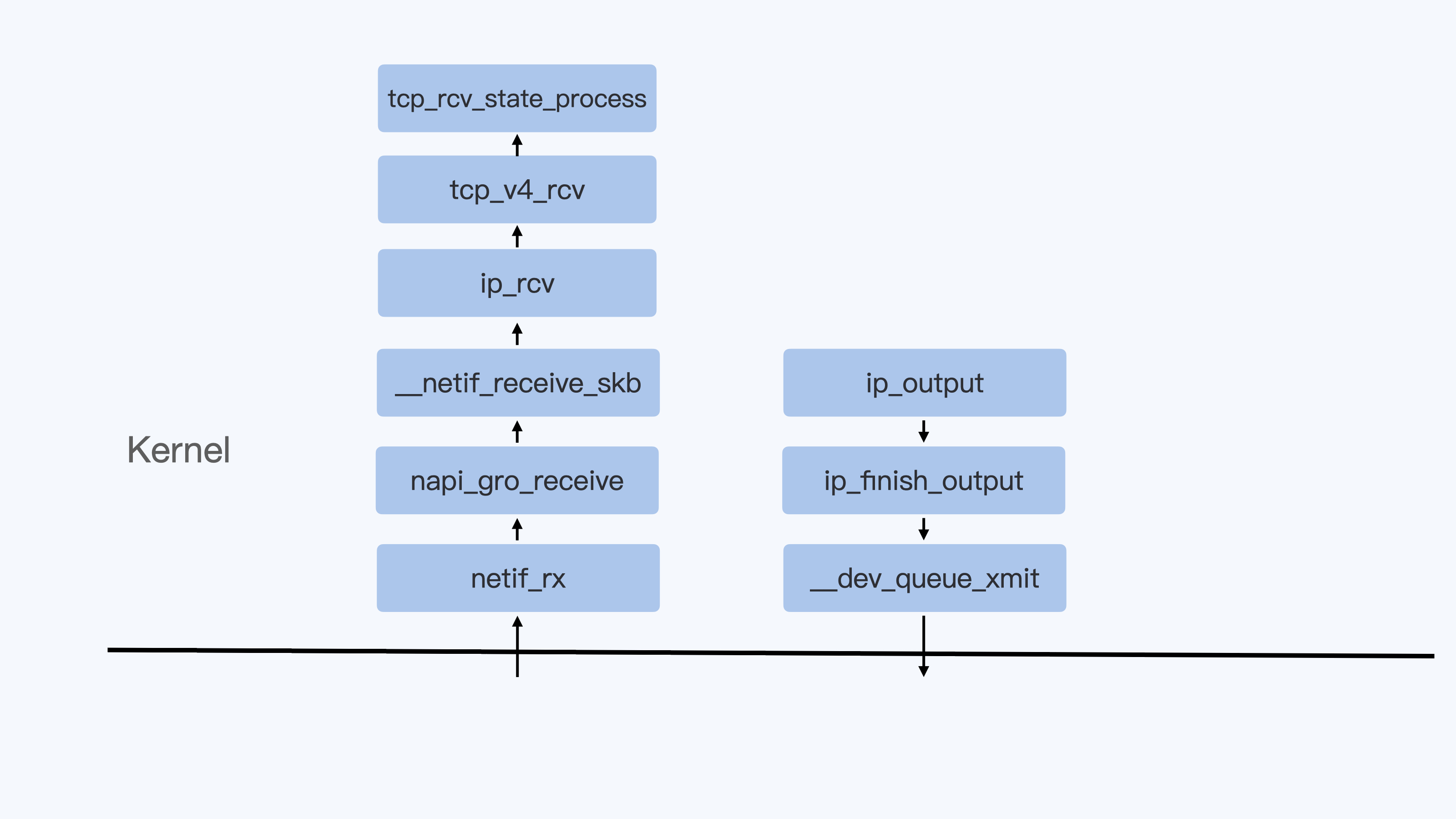
网络相关的中断程序在网络子系统初始化的时候进行注册, NET_RX_SOFTIRQ 的对应函数为 net_rx_action() ,在 net_rx_action() 函数中会调用网卡设备设置的 poll 函数,批量收取网络数据包并调用上层注册的协议函数进行处理,如果是为 ip 协议,则会调用 ip_rcv,上层协议为 icmp 的话,继续调用 icmp_rcv 函数进行后续的处理。
struct sock {
...
struct sk_buff_head write_queue, receive_queue;
...
}
硬件监听物理介质,进行数据的接收,当接收的数据填满了缓冲区,硬件就会产生中断,中断产生后,系统会转向中断服务子程序。在中断服务子程序中,数据会从硬件的缓冲区复制到内核的空间缓冲区,并包装成一个数据结构(sk_buff),然后调用对驱动层的接口函数netif_rx()将数据包发送给链路层。从链路层向网络层传递时将调用ip_rcv函数。该函数完成本层的处理后会根据IP首部中使用的传输层协议来调用相应协议的处理函数(比如UDP对应udp_rcv、TCP对应tcp_rcv)。
如果在IP数据报的首部标明的是使用TCP传输数据,则在上述函数中会调用tcp_rcv函数。该函数的大体处理流程为:
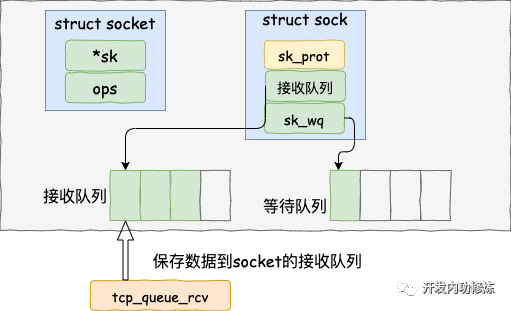
所有使用TCP 协议的套接字对应sock 结构都被挂入tcp_prot(proto 结构)之sock_array 数组中,采用以本地端口号为索引的插入方式,所以当tcp_rcv 函数接收到一个数据包,在完成必要的检查和处理后,其将以TCP 协议首部中目的端口号(对于一个接收的数据包而言,其目的端口号就是本地所使用的端口号)为索引,在tcp_prot 对应sock 结构之sock_array 数组中得到正确的sock 结构队列,再辅之以其他条件遍历该队列进行对应sock 结构的查询,在得到匹配的sock 结构后,将数据包挂入该sock 结构中的缓存队列中(由sock 结构中receive_queue 字段指向),从而完成数据包的最终接收。
struct prot{
...
struct sock * sock_array[SOCK_ARRAY_SIZE]; // 注意是一个数组指针,一个主机有多个端口,一个端口可以建立多个连接,因而有多个struct sock
}
总结来看,数据接收的流程是 sk_buff ==> prot 某个端口的sock_array中的某个sock 的sk_buff 队列。
上文中还有一个比较重要的点是,根据接收的数据,如何找到其对应的struct sock。从中也应该可以了解到,端口的本质含义。
当用户需要接收数据时,首先根据文件描述符inode得到socket结构和sock结构(socket结构在用户层,sock在内核层,两者涉及到数据在内核态和用户态的拷贝),然后从sock结构中指向的队列recieve_queue中读取数据包,将数据包COPY到用户空间缓冲区。数据就完整的从硬件中传输到用户空间。这样也完成了一次完整的从下到上的传输。

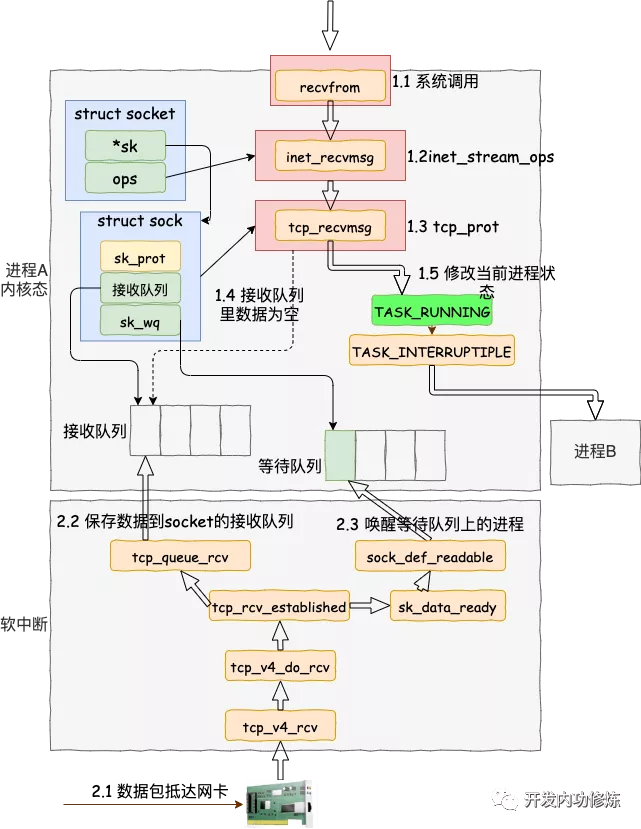
从 tcp 协议栈的处理入口函数 tcp_v4_rcv 开始说:在 tcp_v4_rcv 中首先根据收到的网络包的 header 里的 source 和 dest 信息来在本机上查询对应的 socket。 tcp_v4_do_rcv ==> tcp_rcv_established ==> tcp_queue_rcv 将接收数据放到 socket 的接收队列上。接着再调用 sk_data_ready 来唤醒在 socket上等待的用户进程。sk_data_ready 是一个函数指针,执行sock 初始化时设定的函数。
深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO汇总一下
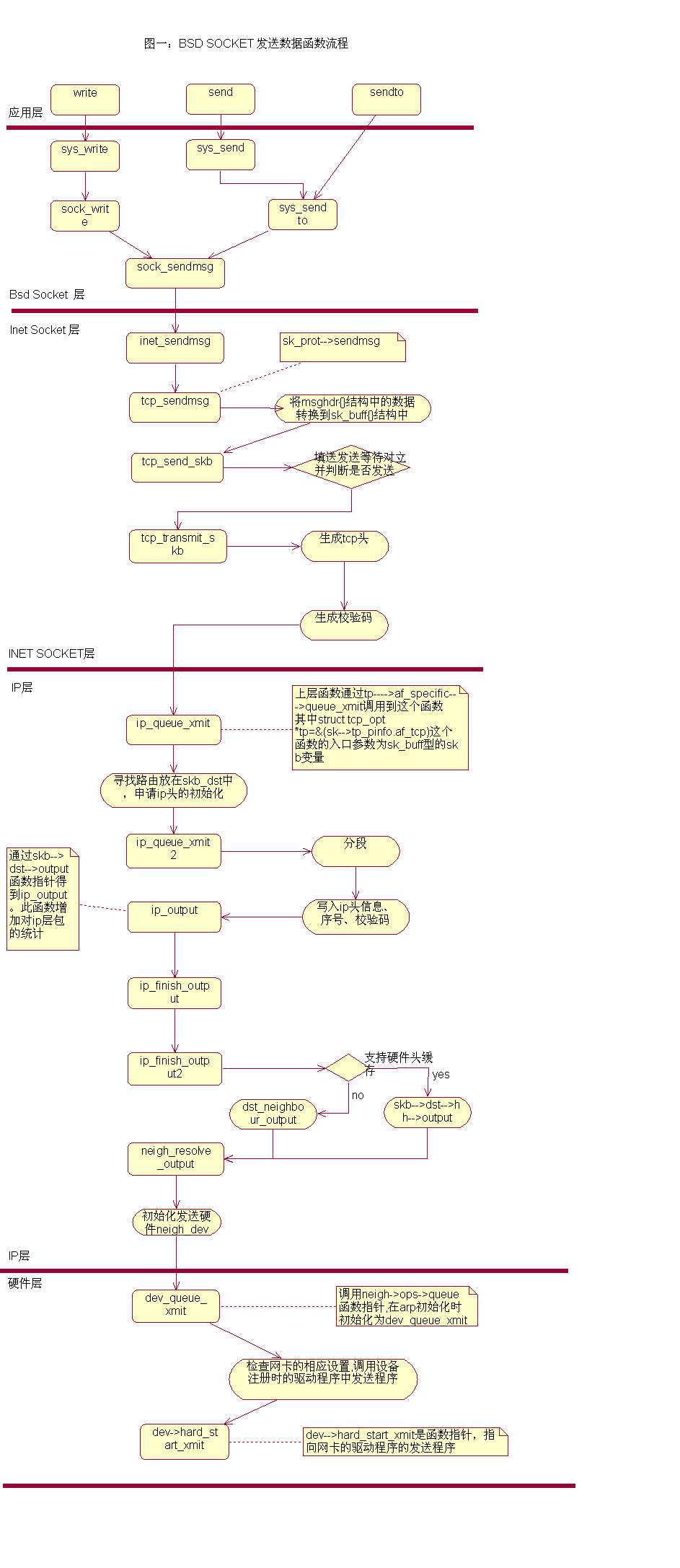
数据的发送
用户在初始化socket之后,会得到一个fd,socket.write ==> sock.write ==> inet.write ==> tcp.write ==> ip_queue_xmit ==> dev_queue_xmit ==> ei_start_xmit.
传输层将用户的数据包装成sk_buff 下放到ip层,在ip层,函数ip_queue_xmit()的功能是将数据包进行一系列复杂的操作,比如是检查数据包是否需要分片。同时,根据目的ip、iptables等规则,选取一个dev发送数据。

linux1.2.13
首先,我们从device struct开始。struct反映了很多东西,比如看一下linux的进程struct,就很容易理解进程为什么能干那么多事情。
linux会维护一个device struct list,通过它能找到所有的网络设备。device struct 和设备不是一对一关系。
include/linux/netdevice.h
struct device{
/*
* This is the first field of the "visible" part of this structure
* (i.e. as seen by users in the "Space.c" file). It is the name
* the interface.
*/
char *name;
/* I/O specific fields - FIXME: Merge these and struct ifmap into one */
unsigned long rmem_end; /* shmem "recv" end */
unsigned long rmem_start; /* shmem "recv" start */
unsigned long mem_end; /* shared mem end */
unsigned long mem_start; /* shared mem start */
// device 只是一个struct,可能几个struct共用一个物理网卡
unsigned long base_addr; /* device I/O address */
// 赋给中断号
unsigned char irq; /* device IRQ number */
/* Low-level status flags. */
volatile unsigned char start, /* start an operation */
tbusy, /* transmitter busy */
interrupt; /* interrupt arrived */
struct device *next;
/* The device initialization function. Called only once. */
// 初始化函数
int (*init)(struct device *dev);
/* Some hardware also needs these fields, but they are not part of the
usual set specified in Space.c. */
unsigned char if_port; /* Selectable AUI, TP,..*/
unsigned char dma; /* DMA channel */
struct enet_statistics* (*get_stats)(struct device *dev);
/*
* This marks the end of the "visible" part of the structure. All
* fields hereafter are internal to the system, and may change at
* will (read: may be cleaned up at will).
*/
/* These may be needed for future network-power-down code. */
unsigned long trans_start; /* Time (in jiffies) of last Tx */
unsigned long last_rx; /* Time of last Rx */
unsigned short flags; /* interface flags (a la BSD) */
unsigned short family; /* address family ID (AF_INET) */
unsigned short metric; /* routing metric (not used) */
unsigned short mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len; /* hardware hdr length */
void *priv; /* pointer to private data */
/* Interface address info. */
unsigned char broadcast[MAX_ADDR_LEN]; /* hw bcast add */
unsigned char dev_addr[MAX_ADDR_LEN]; /* hw address */
unsigned char addr_len; /* hardware address length */
unsigned long pa_addr; /* protocol address */
unsigned long pa_brdaddr; /* protocol broadcast addr */
unsigned long pa_dstaddr; /* protocol P-P other side addr */
unsigned long pa_mask; /* protocol netmask */
unsigned short pa_alen; /* protocol address length */
struct dev_mc_list *mc_list; /* Multicast mac addresses */
int mc_count; /* Number of installed mcasts*/
struct ip_mc_list *ip_mc_list; /* IP multicast filter chain */
/* For load balancing driver pair support */
unsigned long pkt_queue; /* Packets queued */
struct device *slave; /* Slave device */
// device的数据缓冲区
/* Pointer to the interface buffers. */
struct sk_buff_head buffs[DEV_NUMBUFFS];
/* Pointers to interface service routines. */
// 打开设备
int (*open)(struct device *dev);
// 关闭设备
int (*stop)(struct device *dev);
// 调用具体的硬件将数据发到物理介质上,网络栈最终调用它发数据
int (*hard_start_xmit) (struct sk_buff *skb, struct device *dev);
int (*hard_header) (unsigned char *buff,struct device *dev,unsigned short type,void *daddr,void *saddr,unsigned len,struct sk_buff *skb);
int (*rebuild_header)(void *eth, struct device *dev,unsigned long raddr, struct sk_buff *skb);
unsigned short (*type_trans) (struct sk_buff *skb, struct device *dev);
#define HAVE_MULTICAST
void (*set_multicast_list)(struct device *dev, int num_addrs, void *addrs);
#define HAVE_SET_MAC_ADDR
int (*set_mac_address)(struct device *dev, void *addr);
#define HAVE_PRIVATE_IOCTL
int (*do_ioctl)(struct device *dev, struct ifreq *ifr, int cmd);
#define HAVE_SET_CONFIG
int (*set_config)(struct device *dev, struct ifmap *map);
};
耐心的看完这个结构体,网络部分的初始化就是围绕device struct的创建及其中字段(和函数)的初始化.
linux内核与网络驱动程序的边界:linux内核准备好device struct和dev_base指针(这句不准确,或许是ethdev_index[]),kernel启动时,执行驱动程序事先挂好的init函数,init函数初始化device struct并挂到dev_base上(或ethdev_index上)。
ei开头的都是驱动程序自己的函数。
接收数据
device struct 初始化时,会为这个设备生成一个irq(中断号),为irq其绑定ei_interrutp(网卡的中断处理函数),同时会建立一个irq与device的映射。接收到数据后,触发ei_interrutp, ei_interrutp根据中断号得到device,执行ei_receive(device), ei_receive 将数据拷贝到 数据接收队列(元素为 sk_buff,具有prev和next指针,struct device 维护了 sk_buff_head),执行内核的netif_rx,netif_rx 触发软中断 执行net_bh,net_bh 遍历 packet_type list 查看数据 符合哪个协议(不是每次都遍历),执行packet_type.func将数据包传递给网络层协议接收函数,packet_type.func 的可选值 arp_rcv,ip_rcv. ip_rcv中带有device 参数,用于校验数据包的mac 地址是否在 device.mc_list 之内,及检查是否开启IP_FORWARD等。

收到数据包的几种情况
- 来的网络包正是服务端期待的下一个网络包 seq = rcv_nxt
- end_seq < rcv_nxt 服务端期待 5,但来了一个3,说明3和4的ack 客户端没有收到,服务端应重新发送
- seq 不小于 rcv_nxt + tcp_receive_window,说明客户端发送得太猛了。本来 seq 肯定应该在接收窗口里面的,这样服务端才来得及处理,结果现在超出了接收窗口,说明客户端一下子把服务端给塞满了。这种情况下,服务端不能再接收数据包了,只能发送 ACK了,在 ACK 中会将接收窗口为 0 的情况告知客户端,客户就知道不能再发送了。这个时候双方只能交互窗口探测数据包,直到服务端因为用户进程把数据读走了,空出接收窗口,才能在 ACK里面再次告诉客户端,又有窗口了,又能发送数据包了。
- seq < rcv_nxt 但 end_seq > rcv_nxt,说明从 seq 到 rcv_nxt 这部分网络包原来的 ACK 客户端没有收到,所以客户端重新发送了一次,从 rcv_nxt到 end_seq 时新发送的
- 乱序包
Socket 读取
- VFS 层:read 系统调用找到 struct file,根据里面的 file_operations 的定义,调用 sock_read_iter 函数。sock_read_iter 函数调用 sock_recvmsg 函数
- Socket 层:从 struct file 里面的 private_data 得到 struct socket,根据里面 ops 的定义,调用 inet_recvmsg 函数
- Sock 层:从 struct socket 里面的 sk 得到 struct sock,根据里面 sk_prot 的定义,调用 tcp_recvmsg 函数。
- TCP 层:tcp_recvmsg 函数会依次读取 receive_queue 队列、prequeue 队列和 backlog 队列。
socket.read 的本质就是去内核读取 receive_queue 队列、prequeue 队列和 backlog 队列 中的数据。如果实在没有数据包,则调用 sk_wait_data,等待在那里
发送数据
由网络协议栈调用hard_start_xmit(初始化时,驱动程序将ei_start_xmit函数挂到其上)
总的来说,kernel有几个extern的struct、pointer和func,驱动程序初始化完毕后,为linux内核准备了一个device struct list(驱动程序自己有一些功能函数,挂到device struct的函数成员上)。收到数据时,kernel的extern func(比如netif_rx)在中断环境下被驱动程序调用。发送数据时,则由内核网络协议栈调用device.hard_start_xmit,进而执行驱动程序函数。
不同的缓存方式 and 处理网络包的三个主体
io数据的读写,不会一个字节一个字节的来,所以数据会缓存(缓冲)。
| 管理程序 | 备注 | |
|---|---|---|
| 硬件/驱动程序缓存区 | 由驱动程序管理 | 粗略的说,所谓发送,就是将数据拷贝到相关的硬件寄存器,并触发驱动程序发送。 |
| 内核空间缓存区 | 由内核管理 | |
| 用户空间缓存区 | 由用户程序管理 |
针对内核空间缓存区
- linux文件操作中,会专门开辟一段内存,用来存储磁盘文件系统的超级块和部分磁盘块,通过文件path ==> fd ==> inode ==> … ==> 块索引 找到块的数据并读写。磁盘块的管理是公共的、独立的,fd记录自己相关的磁盘块索引即可。fd不用这个磁盘块了,除非系统剩余内存不够,这个磁盘块数据不会被释放,下次用到时还能用。即便fd只要一部分数据,系统也会自动加载相关的多个磁盘块到内存。
- linux网络操作中,通过socket fd ==> sock ==> write_queue, receive_queue 在缓存读写的数据。sk_buff 的管理是sock各自为政。
这其中的不同,值得品味。一个重要原因是,因为linux事先加载了超级块数据,可以根据需要,精确的指定加载和写入多少数据。而对于网络编程来说,一次能读取和写出多少,都是未知的,每个sock都不同。
(较高版本linux)网络包的接收过程,这里面涉及三个队列:
- backlog 队列
- prequeue 队列
- sk_receive_queue 队列
为什么接收网络包的过程,需要在这三个队列里面倒腾过来、倒腾过去呢?这是因为,同样一个网络包要在三个主体之间交接。
- 软中断的处理过程。我们在执行tcp_v4_rcv 函数的时候,依然处于软中断的处理逻辑里,所以必然会占用这个软中断。
- 用户态进程。如果用户态触发系统调用 read 读取网络包,也要从队列里面找。
- 内核协议栈。哪怕用户进程没有调用 read读取网络包,当网络包来的时候,也得有一个地方收着。
发送与接收成本 和 优化
linux 一次发送或接收处理链路还是比较长的,且需要在内核态与用户态之间做内存拷贝、上下文切换、软硬件中断等。以对我们最直观的内存拷贝为例,正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%
虽然Linux设计初衷是以通用性为目的的,但随着Linux在服务器市场的广泛应用,其原有的网络数据包处理方式已很难跟上人们对高性能网络数据处理能力的诉求。在这种背景下DPDK应运而生,其利用UIO技术,在Driver层直接将数据包导入到用户态进程,绕过了Linux协议栈,接下来由用户进程完成所有后续处理,再通过Driver将数据发送出去。原有内核态与用户态之间的内存拷贝采用mmap将用户内存映射到内核,如此就规避了内存拷贝、上下文切换、系统调用等问题,然后再利用大页内存、CPU亲和性、无锁队列、基于轮询的驱动模式、多核调度充分压榨机器性能,从而实现高效率的数据包处理。
DPDK全称Intel Data Plane Development Kit,是Intel提供的数据平面开发工具集,为Intel Architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持。VPP是the vector packet processor的简称,是一套基于DPDK的网络帧处理解决方案,是一个可扩展框架,提供开箱即用的交换机/路由器功能。是Linux基金会下开源项目FD.io的一个子项目,由思科贡献的开源版本,目前是FD.io的最核心的项目。
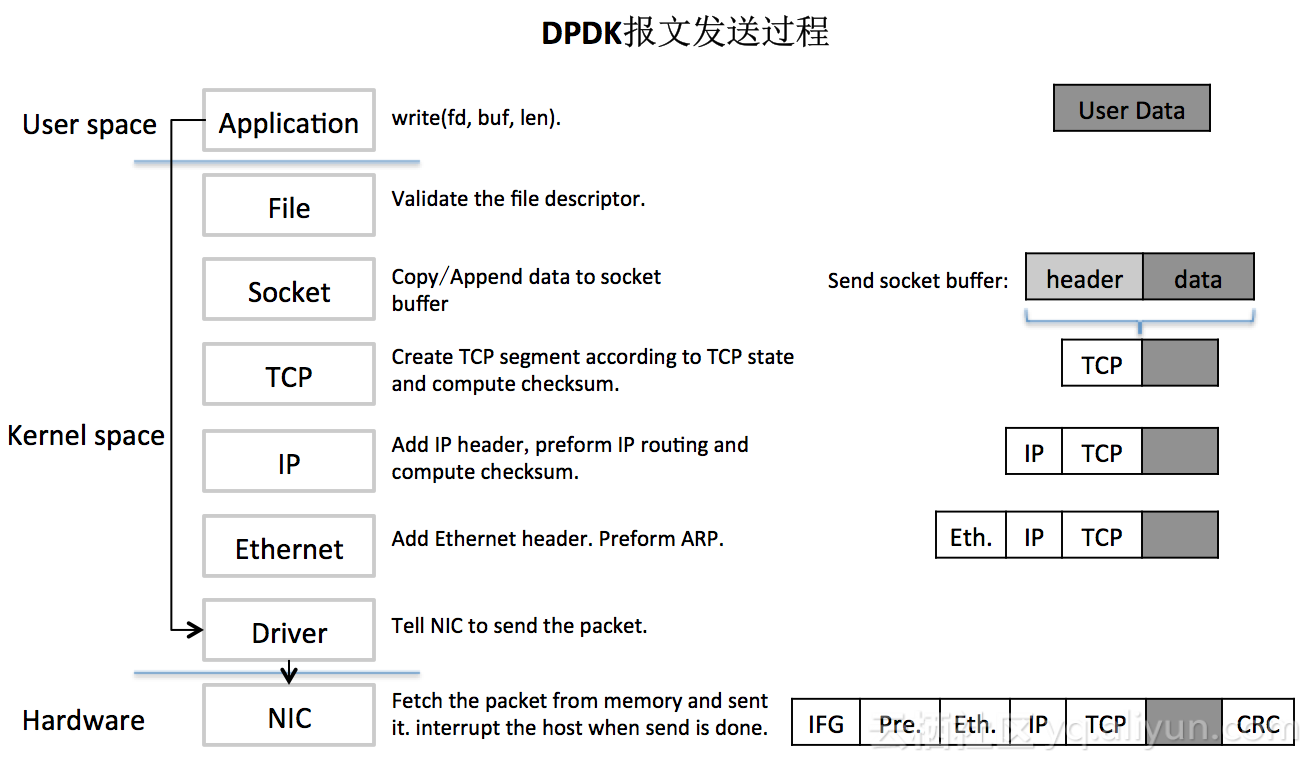

通过对比得知,DPDK拦截中断,不触发后续中断流程,并绕过内核协议栈,通过UIO(Userspace I/O)技术将网卡收到的报文拷贝到应用层处理,报文不再经过内核协议栈。减少了中断,DPDK的包全部在用户空间使用内存池管理,内核空间与用户空间的内存交互不用进行拷贝,只做控制权转移,减少报文拷贝过程,提高报文的转发效率。
DPDK能够绕过内核协议栈,本质上是得益于 UIO 技术,UIO技术也不是DPDK创立的,是内核提供的一种运行在用户空间的I/O技术,Linux系统中一般的驱动设备都是运行在内核空间,在用户空间用的程序调用即可,UIO则是将驱动的很少一部分运行在内核空间,绝大多数功能在用户空间实现,通过 UIO 能够拦截中断,并重设中断回调行为,从而绕过内核协议栈后续的处理流程。