简介
k8s.io/client-go
/rest
/informer
/core
/v1
/pod.go
/interface.go
/interface.go
/factory.go // 定义sharedInformerFactory struct
/tools
/cache // informer 机制的的重点在cache 包里
/shared_informer.go // 定义了 sharedIndexInformer struct
/controller.go
/reflector.go
/delta_fifo.go
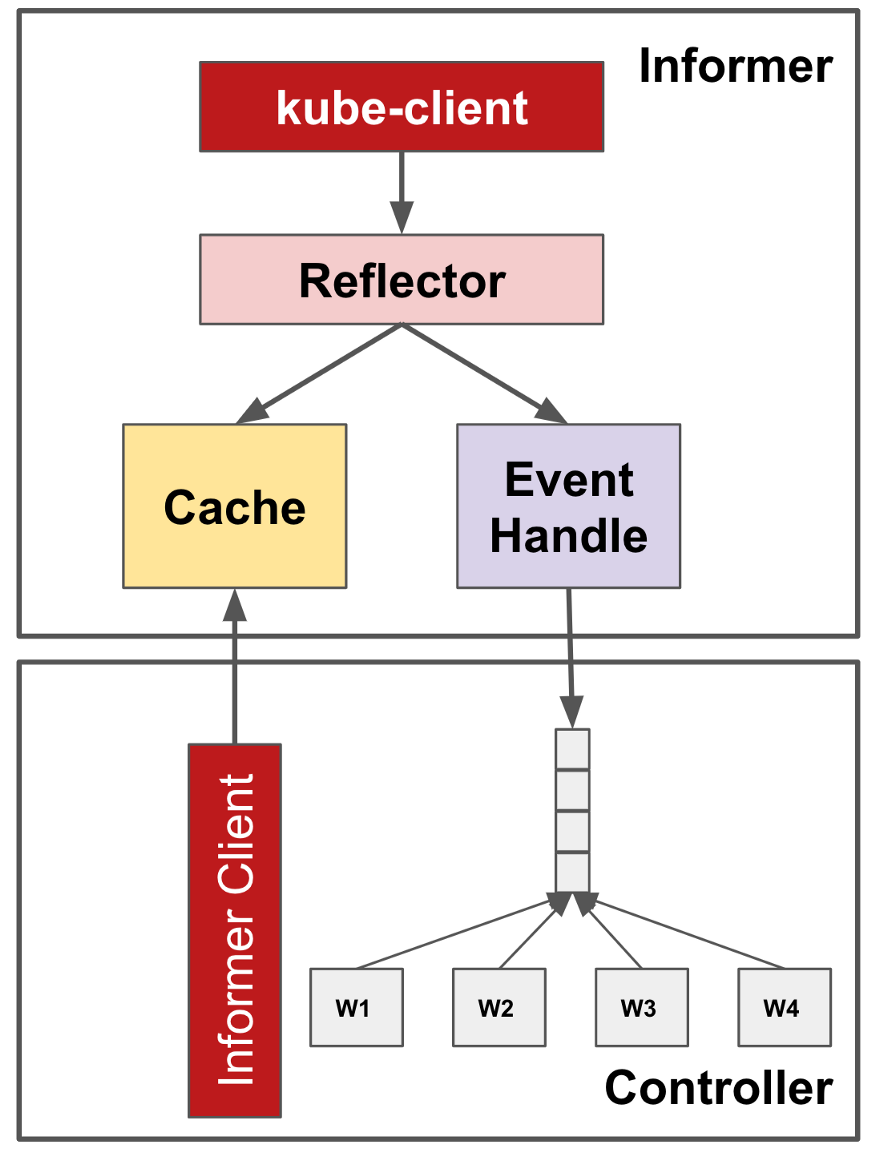
Informer
Pinterest如何平稳扩展K8s?控制器框架为优化读取操作提供了一个利用 informer-reflector-cache 的、可共享的缓存架构。Informer 通过 kube-apiserver 监控目标对象,Reflector 将目标对象的变更反应到底层缓存(Cache)中,并将观测到的事件传播给事件处理程序。同一控制器中的多个组件可以为 OnCreate、OnUpdate,以及 OnDelete 事件注册 Informer 事件处理程序,并从 Cache 中获取对象(而非是直接从 Kube-apiserver 中获取)。这样一来,就减少了很多不必要或多余的调用。
Kubernetes: Controllers, Informers, Reflectors and StoresKubernetes offers these powerful structures to get a local representation of the API server’s resources.The Informer just a convenient wrapper to automagically syncs the upstream data to a downstream store and even offers you some handy event hooks.
实际使用中 每一个资源对象(比如Pod、Deployment)都对应一个Informer,底层都用到了SharedIndexInformer
Kubernetes Informer 详解 Informer 只会调用 Kubernetes List 和 Watch 两种类型的 API,Informer 在初始化的时,先调用 Kubernetes List API 获得某种 resource 的全部 Object(真的只调了一次),缓存在内存中; 然后,调用 Watch API 去 watch 这种 resource,去维护这份缓存; 之后,Informer 就不再调用 Kubernetes 的任何 API。
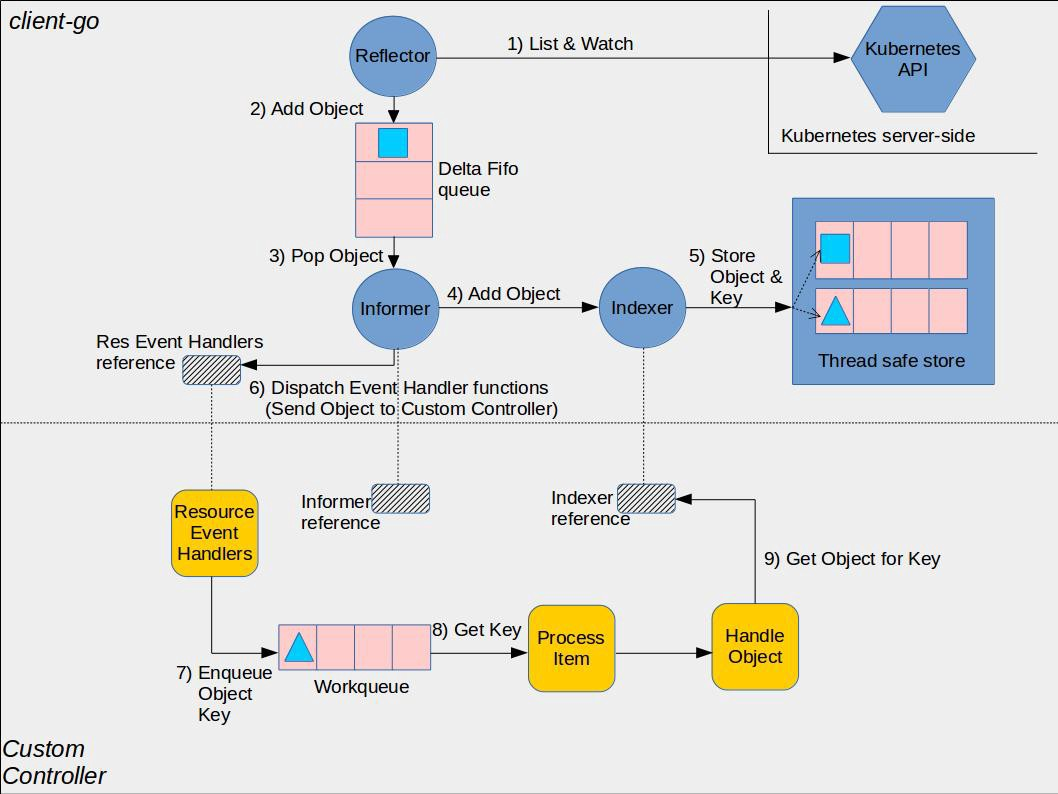
informer 机制主要两个流程
- Reflector 通过ListWatcher 同步apiserver 数据(只启动时搞一次),并watch apiserver ,将event 加入到 Queue 中
- controller 从 Queue中获取event,更新存储,并触发Processor 业务层注册的 ResourceEventHandler
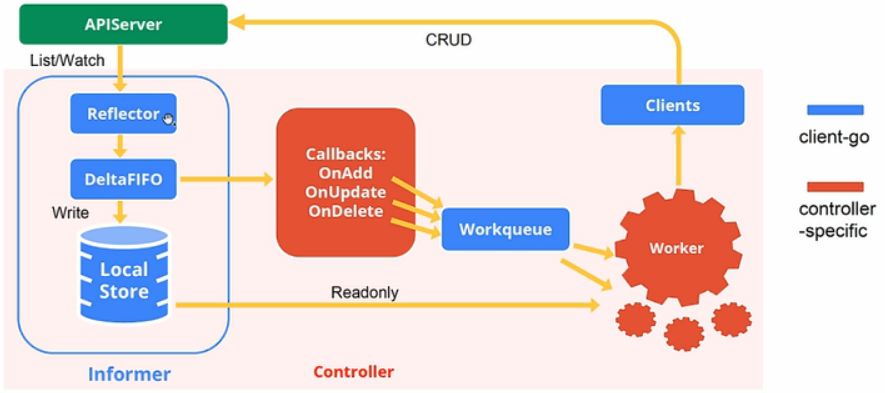
Reflector
// k8s.io/client-go/tools/cache/reflector.go
type Reflector struct {
name string
expectedTypeName string
expectedType reflect.Type // 放到 Store 中的对象类型
expectedGVK *schema.GroupVersionKind
// 与 watch 源同步的目标 Store
store Store
// 用来执行 lists 和 watches 操作的 listerWatcher 接口(最重要的)
listerWatcher ListerWatcher
WatchListPageSize int64
...
Reflector 对象通过 Run 函数来启动监控并处理监控事件
// k8s.io/client-go/tools/cache/reflector.go
// Run 函数反复使用 ListAndWatch 函数来获取所有对象和后续的 deltas。
// 当 stopCh 被关闭的时候,Run函数才会退出。
func (r *Reflector) Run(stopCh <-chan struct{}) {
wait.BackoffUntil(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.backoffManager, true, stopCh)
}
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
var resourceVersion string
options := metav1.ListOptions{ResourceVersion: r.relistResourceVersion()}
if err := func() error {
var list runtime.Object
listCh := make(chan struct{}, 1)
go func() {
pager := pager.New(...)
pager.PageSize = xx
list, paginatedResult, err = pager.List(context.Background(), options)
close(listCh) //close listCh后,下面的select 会解除阻塞
}()
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
...
r.setLastSyncResourceVersion(resourceVersion)
return nil
}()
// 处理resync 逻辑
for {
options = metav1.ListOptions{...}
w, err := r.listerWatcher.Watch(options)
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {...}
}
}
func (r *Reflector) watchHandler(start time.Time, w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
meta, err := meta.Accessor(event.Object)
newResourceVersion := meta.GetResourceVersion()
switch event.Type {
case watch.Added:
err := r.store.Add(event.Object)
case watch.Modified:
err := r.store.Update(event.Object)
case watch.Deleted:
err := r.store.Delete(event.Object)
case watch.Bookmark:
// A `Bookmark` means watch has synced here, just update the resourceVersion
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
}
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
if rvu, ok := r.store.(ResourceVersionUpdater); ok {
rvu.UpdateResourceVersion(newResourceVersion)
}
}
}
return nil
}
Reflector.Run ==> pager.List + listerWatcher.Watch ==> Reflector.watchHandler ==> store.Add/Update/Delete ==> DeltaFIFO.Add obj 加入DeltaFIFO
首先通过Reflector的 relistResourceVersion 函数获得Reflector relist 的资源版本,如果资源版本非 0,则表示根据资源版本号继续获取,当传输过程中遇到网络故障或者其他原因导致中断,下次再连接时,会根据资源版本号继续传输未完成的部分。
ResourceVersion(资源版本号)非常重要,Kubernetes 中所有的资源都拥有该字段,它标识当前资源对象的版本号,每次修改(CUD)当前资源对象时,Kubernetes API Server 都会更改 ResourceVersion,这样 client-go 执行 Watch 操作时可以根据ResourceVersion 来确定当前资源对象是否发生了变化。
DeltaFIFO 和 FIFO 一样也是一个队列,DeltaFIFO里面的元素是一个 Delta。DeltaFIFO实现了Store和 Queue Interface。生产者为Reflector,消费者为 Pop() 函数。
// k8s.io/client-go/tools/cache/delta_fifo.go
type Delta struct {
Type DeltaType
Object interface{}
}
type DeltaFIFO struct {
items map[string]Deltas // 存储key到元素对象的Map,提供Store能力
queue []string // key的队列,提供Queue能力
...
}
ADD/UPDATE 时判断items 是否包含元素,若包含则更新,不包含则加入items并写入queue。DELETE时直接从items 中移除,queue中不管。因此 items和queue中所包含的Key可能不一致,会定期resync。
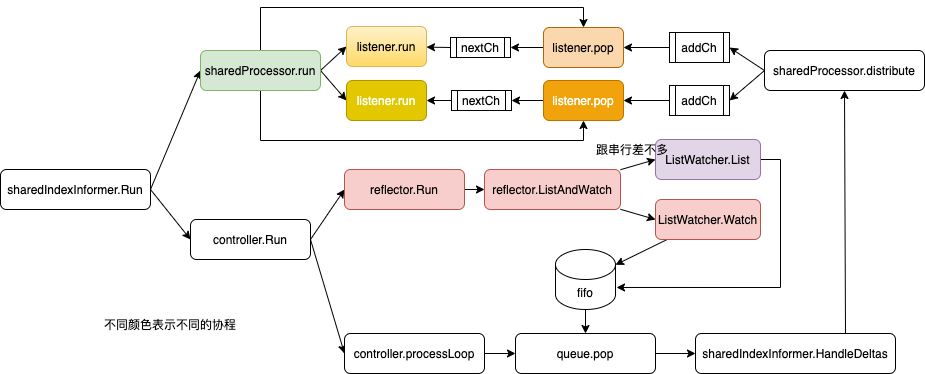
Watch event 消费
sharedIndexInformer.Run ==> controller.Run ==> controller.processLoop ==> for Queue.Pop 也就是 sharedIndexInformer.HandleDeltas ==> 更新LocalStore + processor.distribute
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
isSync := d.Type == Sync
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {...}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {...}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {...}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
processor 是如何处理数据的
两条主线
- sharedIndexInformer.HandleDeltas ==> sharedProcessor.distribute ==> 多个 processorListener.addCh 往channel 里塞数据。
- sharedIndexInformer.Run ==> sharedProcessor.run ==> sharedProcessor.pop 消费channel数据 这里要注意的是,sharedProcessor.distribute 是将消息分发给多个processorListener, processorListener.pop 必须处理的非常快,否则就会阻塞distribute 执行。
// k8s.io/client-go/tools/cache/shared_informer.go
type sharedProcessor struct {
listenersStarted bool
listenersLock sync.RWMutex
listeners []*processorListener
syncingListeners []*processorListener
clock clock.Clock
wg wait.Group
}
func (p *sharedProcessor) distribute(obj interface{}, sync bool) {
for _, listener := range p.listeners {
// 加入到processorListener 的addCh 中,随后进入pendingNotifications,因为这里不能阻塞
listener.add(obj)
}
}
// k8s.io/client-go/tools/cache/shared_informer.go
type processorListener struct {
nextCh chan interface{}
addCh chan interface{}
handler ResourceEventHandler
pendingNotifications buffer.RingGrowing
...
}
func (p *processorListener) add(notification interface{}) {
p.addCh <- notification
}
func (p *sharedProcessor) run(stopCh <-chan struct{}) {
func() {
for _, listener := range p.listeners {
p.wg.Start(listener.run) // 消费nextCh
p.wg.Start(listener.pop) // 消费addCh 经过 mq 转到 nextCh
}
p.listenersStarted = true
}()
...
}
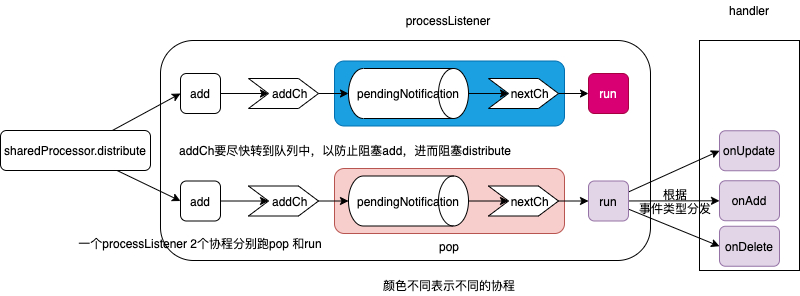
消息流转的具体路径:addCh ==> notificationToAdd ==> pendingNotifications ==> notification ==> nextCh。 搞这么复杂的原因就是:pop作为addCh 的消费逻辑 必须非常快,而下游nextCh 的消费函数run 执行的速度看业务而定,中间要通过pendingNotifications 缓冲。
func (p *processorListener) pop() {
var nextCh chan<- interface{}
var notification interface{} // 用来做消息的中转,并在最开始的时候标记pendingNotifications 为空
for {
// select case channel 更多是事件驱动的感觉,哪个channel 来数据了或者可以 接收数据了就处理哪个 case 内逻辑
select {
case nextCh <- notification:
// Notification dispatched
notification, ok = p.pendingNotifications.ReadOne()
if !ok { // Nothing to pop
nextCh = nil // Disable this select case
}
case notificationToAdd, ok := <-p.addCh:
if notification == nil { // No notification to pop (and pendingNotifications is empty)
// Optimize the case - skip adding to pendingNotifications
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}
func (p *processorListener) run() {
stopCh := make(chan struct{})
wait.Until(func() {
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
close(stopCh)
}, 1*time.Second, stopCh)
}
一个eventhandler 会被封装为一个processListener,一个processListener 对应两个协程,run 协程负责 消费pendingNotifications 所有event 。pendingNotifications是一个ring buffer, 默认长度为1024,如果被塞满,则扩容至2倍大小。如果event 处理较慢,则会导致pendingNotifications 积压,event 处理的延迟增大。PS:业务实践上确实发现了 pod 因各种原因大量变更, 叠加 event 处理慢 导致pod ready 后无法及时后续处理的情况
watch 是如何实现的?
K8s 如何提供更高效稳定的编排能力?K8s Watch 实现机制浅析从 HTTP 说起: HTTP 发送请求 Request 或服务端 Response,会在 HTTP header 中携带 Content-Length,以表明此次传输的总数据长度。如果服务端提前不知道要传输数据的总长度,怎么办?
- HTTP 从 1.1 开始增加了分块传输编码(Chunked Transfer Encoding),将数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。数据块长度以十六进制的形式表示,后面紧跟着
\r\n,之后是分块数据本身,后面也是\r\n,终止块则是一个长度为 0 的分块。为了实现以流(Streaming)的方式 Watch 服务端资源变更,HTTP1.1 Server 端会在 Header 里告诉 Client 要变更 Transfer-Encoding 为 chunked,之后进行分块传输,直到 Server 端发送了大小为 0 的数据。 - HTTP/2 并没有使用 Chunked Transfer Encoding 进行流式传输,而是引入了以 Frame(帧) 为单位来进行传输,其数据完全改变了原来的编解码方式,整个方式类似很多 RPC协议。Frame 由二进制编码,帧头固定位置的字节描述 Body 长度,就可以读取 Body 体,直到 Flags 遇到 END_STREAM。这种方式天然支持服务端在 Stream 上发送数据,不需要通知客户端做什么改变。K8s 为了充分利用 HTTP/2 在 Server-Push、Multiplexing 上的高性能 Stream 特性,在实现 RESTful Watch 时,提供了 HTTP1.1/HTTP2 的协议协商(ALPN, Application-Layer Protocol Negotiation) 机制,在服务端优先选中 HTTP2。
HTTP1.1例子: 当客户端调用watch API时,apiserver 在response的HTTP Header中设置Transfer-Encoding的值为chunked,表示采用分块传输编码,客户端收到该信息后,便和服务端保持该链接,并等待下一个数据块,即资源的事件信息。例如:
$ curl -i http://{kube-api-server-ip}:8080/api/v1/watch/pods?watch=yes
HTTP/1.1 200 OK
Content-Type: application/json
Transfer-Encoding: chunked
Date: Thu, 02 Jan 2019 20:22:59 GMT
Transfer-Encoding: chunked
{"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}}
{"type":"ADDED", "object":{"kind":"Pod","apiVersion":"v1",...}}
{"type":"MODIFIED", "object":{"kind":"Pod","apiVersion":"v1",...}}
从k8s.io/apimachinery/pkg/watch 返回的watch.Interface
type Interface interface{
Stop()
ResultChan() <- Event
}
type Event struct{
Type EventType // ADDED/MODIFIED/DELETED/ERROR
Object runtime.Object
}
Kubernetes List-Watch 机制原理与实现 - chunked
resync机制
Informer 中的 Reflector 通过 List/watch 从 apiserver 中获取到集群中所有资源对象的变化事件(event),将其放入 Delta FIFO 队列中(以 Key、Value 的形式保存),触发 onAdd、onUpdate、onDelete 回调将 Key 放入 WorkQueue 中。同时将 Key 更新 Indexer 本地缓存。Control Loop 从 WorkQueue 中取到 Key,从 Indexer 中获取到该 Key 的 Value,进行相应的处理。
我们在使用 SharedInformerFactory 去创建 SharedInformer 时,需要填一个 ResyncDuration 的参数
// k8s.io/client-go/informers/factory.go
// NewSharedInformerFactory constructs a new instance of sharedInformerFactory for all namespaces.
func NewSharedInformerFactory(client kubernetes.Interface, defaultResync time.Duration) SharedInformerFactory {
return NewSharedInformerFactoryWithOptions(client, defaultResync)
}
这个参数指的是,多久从 Indexer 缓存中同步一次数据到 Delta FIFO 队列,重新走一遍流程
type DeltaFIFO struct {
...
knownObjects KeyListerGetter // 实质是indexer
}
// k8s.io/client-go/tools/cache/delta_fifo.go
// 重新同步一次 Indexer 缓存数据到 Delta FIFO 队列中
func (f *DeltaFIFO) Resync() error {
// 遍历 indexer 中的 key,传入 syncKeyLocked 中处理
keys := f.knownObjects.ListKeys()
for _, k := range keys {
f.syncKeyLocked(k)
}
return nil
}
func (f *DeltaFIFO) syncKeyLocked(key string) error {
obj, exists, err := f.knownObjects.GetByKey(key)
// 如果发现 FIFO 队列中已经有相同 key 的 event 进来了,说明该资源对象有了新的 event,
// 在 Indexer 中旧的缓存应该失效,因此不做 Resync 处理直接返回 nil
id, err := f.KeyOf(obj)
if len(f.items[id]) > 0 {
return nil
}
// 重新放入 FIFO 队列中
err := f.queueActionLocked(Sync, obj)
return nil
}
为什么需要 Resync 机制呢?因为在处理 SharedInformer 事件回调时,可能存在处理失败的情况,定时的 Resync 让这些处理失败的事件有了重新 onUpdate 处理的机会。那么经过 Resync 重新放入 Delta FIFO 队列的事件,和直接从 apiserver 中 watch 得到的事件处理起来有什么不一样呢?
// k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
// from oldest to newest
for _, d := range obj.(Deltas) {
// 判断事件类型,看事件是通过新增、更新、替换、删除还是 Resync 重新同步产生的
switch d.Type {
case Sync, Replaced, Added, Updated:
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
err := s.indexer.Update(d.Object)
isSync := false
switch {
case d.Type == Sync:
// 如果是通过 Resync 重新同步得到的事件则做个标记
isSync = true
case d.Type == Replaced:
...
}
// 如果是通过 Resync 重新同步得到的事件,则触发 onUpdate 回调
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
err := s.indexer.Add(d.Object)
s.processor.distribute(addNotification{newObj: d.Object}, false)
}
case Deleted:
err := s.indexer.Delete(d.Object)
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
从上面对 Delta FIFO 的队列处理源码可看出,如果是从 Resync 重新同步到 Delta FIFO 队列的事件,会分发到 updateNotification 中触发 onUpdate 的回调
informer 类图和序列图
