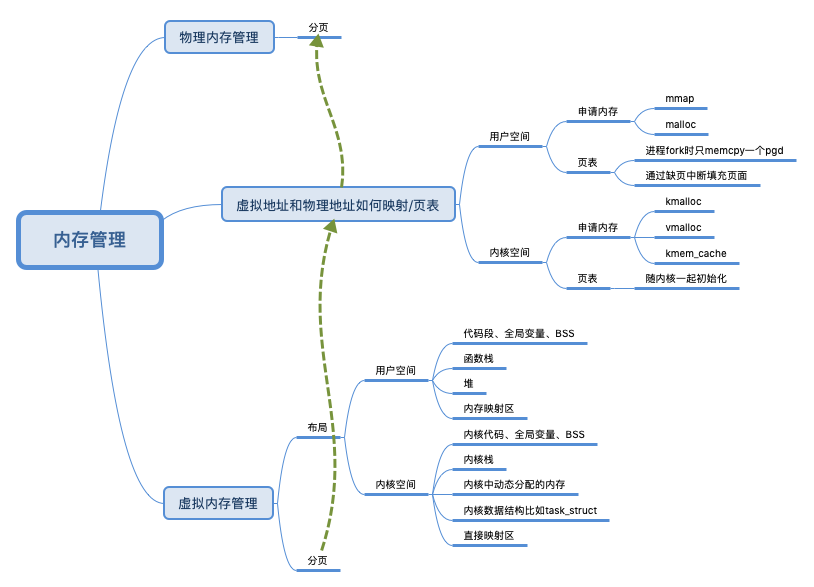
简介
管理内存前先划分出三个边界值 未读,建议细读
为了保证操作系统的稳定性和安全性。用户程序不可以直接访问硬件资源,如果用户程序需要访问硬件资源,必须调用操作系统提供的接口,这个调用接口的过程也就是系统调用(用户写的代码最终也会被编译为机器指令,用户代码不允许出现in/out 等访问硬件的指令,想执行这些指令只能“委托”系统人员写的内核代码。或者说,假设机器支持100条指令,开发只能使用其中六七十个,高级语言经过编译器的翻译后不会使用这些指令,但在汇编时代,用户提交的汇编代码指令是可以随便用的)。每一次系统调用都会存在两个内存空间之间的相互切换(比如栈切换等),通常的网络传输也是一次系统调用,通过网络传输的数据先是从内核空间接收到远程主机的数据,然后再从内核空间复制到用户空间,供用户程序使用。这种从内核空间到用户空间的数据复制很费时,虽然保住了程序运行的安全性和稳定性,但是牺牲了一部分的效率。
进程“独占”虚拟内存及虚拟内存划分
如何分配用户空间和内核空间的比例也是一个问题,是更多地分配给用户空间供用户程序使用,还是首先保住内核有足够的空间来运行。在当前的Windows 32位操作系统中,默认用户空间:内核空间的比例是1:1,而在32位Linux系统中的默认比例是3:1(3GB用户空间、1GB内核空间)(这里只是地址空间,映射到物理地址,可没有某个物理地址的内存只能存储内核态数据或用户态数据的说法)。
| 用户地址空间 | 内核地址空间 | 备注 | |
|---|---|---|---|
| 地址类型 | 虚拟地址 | 虚拟地址 | 都要经过 MMU 的翻译,变成物理地址 |
| 生存期 | 随进程创建产生 | 持续存在 | |
| 共享 | 进程独占 | 所有进程共享 | |
| 对应物理空间 | 分散且不固定 | 提前固定下来一片连续的物理地址空间,所有进程共享 |
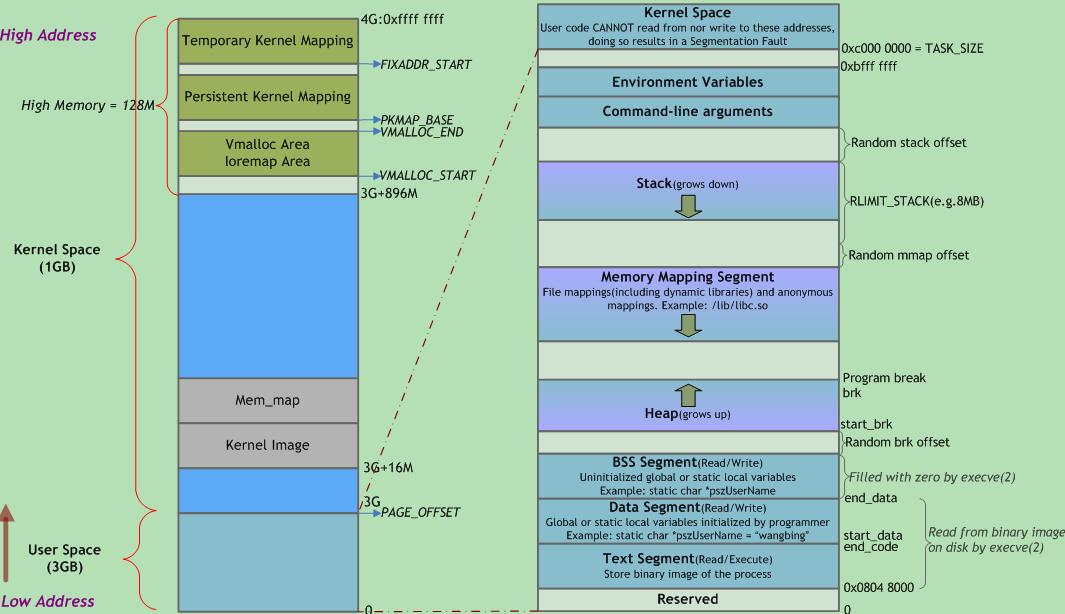
左右两侧均表示虚拟地址空间,左侧以描述内核空间为主,右侧以描述用户空间为主。
| 内存区域 | 日常看到的 |
|---|---|
| Text Segment Data Segment BSS Segment |
Text Segment 是存放二进制可执行代码 Data Segment 存放静态常量 BSS Segment 存放未初始化的静态变量 正是ELF二进制执行文件的三个部分 |
| 堆 | malloc |
| Memory Mapping Segment | 用来把文件映射进内存用的 动态链接库/so文件就是加载到这里 |
| 栈 | 函数栈 |
在内核里面也会有内核的代码,同样有 Text Segment、Data Segment 和 BSS Segment,别忘了内核代码也是 ELF 格式的。
你真的理解内存分配吗?对于内存的访问,用户态的进程使用虚拟地址,内核的也基本都是使用虚拟地址
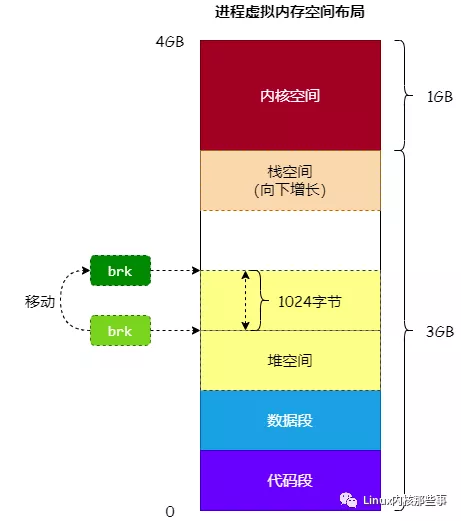
通过 malloc 函数申请的内存地址是由 堆空间 分配的(其实还有可能从 mmap 区分配),在内核中,使用一个名为 brk 的指针来表示进程的 堆空间 的顶部。malloc 函数就是通过移动 brk 指针来实现申请和释放内存的,Linux 提供了一个名为 brk() 的系统调用来移动 brk 指针。
彭东《操作系统实战》案例操作系统
物理内存管理数据结构及初始化
彭东《操作系统实战》案例操作系统 定义了几个数据结构来管理内存
- memarea_t 结构表示一个内存区,逻辑上的概念,并不是硬件上必需的,按功能划分对应硬件区、内核区、应用区。比如虚拟地址主要依赖于 CPU 中的 MMU,但有很多外部硬件能直接和内存交换数据,常见的有 DMA,并且它只能访问低于 24MB 的物理内存。
- msadsc_t 表示一个内存页,包含页的状态、页的地址、页的分配记数、页的类型、页的链表。物理内存页有多少就需要有多少个 msadsc_t 结构。
//内存空间地址描述符标志 typedef struct s_MSADFLGS { u32_t mf_olkty:2; //挂入链表的类型 u32_t mf_lstty:1; //是否挂入链表 u32_t mf_mocty:2; //分配类型,被谁占用了,内核还是应用或者空闲 u32_t mf_marty:3; //属于哪个区 u32_t mf_uindx:24; //分配计数 }__attribute__((packed)) msadflgs_t; //物理地址和标志 typedef struct s_PHYADRFLGS { u64_t paf_alloc:1; //分配位 u64_t paf_shared:1; //共享位 u64_t paf_swap:1; //交换位 u64_t paf_cache:1; //缓存位 u64_t paf_kmap:1; //映射位 u64_t paf_lock:1; //锁定位 u64_t paf_dirty:1; //脏位 u64_t paf_busy:1; //忙位 u64_t paf_rv2:4; //保留位 u64_t paf_padrs:52; //页物理地址位 }__attribute__((packed)) phyadrflgs_t; //内存空间地址描述符 typedef struct s_MSADSC { list_h_t md_list; //链表 spinlock_t md_lock; //保护自身的自旋锁 msadflgs_t md_indxflgs; //内存空间地址描述符标志 phyadrflgs_t md_phyadrs; //物理地址和标志 void* md_odlink; //相邻且相同大小msadsc的指针 }__attribute__((packed)) msadsc_t; - 组织内存页就是组织 msadsc_t 结构,它其中需要锁、状态、msadsc_t 结构数量,挂载 msadsc_t 结构的链表、和一些统计数据——bafhlst_t。
- 有了 bafhlst_t 数据结构,我们只是有了挂载 msadsc_t 结构的地方,这并没有做到科学合理。但是,如果我们把多个 bafhlst_t 数据结构组织起来,形成一个 bafhlst_t 结构数组,并且把这个 bafhlst_t 结构数组放在一个更高的数据结构中,这个数据结构就是内存分割合并数据结构——memdivmer_t。为什么要用分割和合并呢?这其实取意于我们的内存分配、释放算法,对这个算法而言分配内存就是分割内存,而释放内存就是合并内存。如果 memdivmer_t 结构中 dm_mdmlielst 数组只是一个数组,那是没有意义的。我们正是要通过 dm_mdmlielst 数组,来划分物理内存地址不连续的 msadsc_t 结构。每个内存区 memarea_t 结构中包含一个内存分割合并 memdivmer_t 结构,而在 memdivmer_t 结构中又包含 dm_mdmlielst 数组。在 dm_mdmlielst 数组中挂载了多个 msadsc_t 结构。
确定了用分页方式管理内存,并且一起动手设计了表示内存页、内存区相关的内存管理数据结构。在代码中实际操作的数据结构必须在内存中有相应的变量,这个由初始化函数解决。内核初始化时会调用 init_memmgr
void init_memmgr(){
// 初始化内存页结构
init_msadsc();
//初始化内存区结构
init_memarea();
//处理内存占用,标记哪些 msadsc_t 结构对应的物理内存被内核占用了,这些被标记 msadsc_t 结构是不能纳入内存管理结构中去的。
init_search_krloccupymm(&kmachbsp);
//合并内存页到内存区中,把所有的空闲 msadsc_t 结构按最大地址连续的形式组织起来,挂载到 memarea_t 结构下的 memdivmer_t 结构中,对应的 dm_mdmlielst 数组中。
init_merlove_mem();
init_memmgrob(); //物理地址转为虚拟地址,便于以后使用
return;
}
内存管理代码的结构是:接口函数调用框架函数,框架函数调用核心函数。可以发现,这个接口函数返回的是一个 msadsc_t 结构的指针。如果能在 dm_mdmlielst 数组中找到对应请求页面数的 msadsc_t 结构就直接返回,如果没有就寻找下一个 dm_mdmlielst 数组中元素,依次迭代直到最大的 dm_mdmlielst 数组元素,然后依次对半分割,直到分割到请求的页面数为止。释放时会查找相邻且物理地址连续的 msadsc_t 结构,进行合并,合并工作也是迭代过程,直到合并到最大的连续 msadsc_t 结构或者后面不能合并为止,最后把这个合并到最大的连续 msadsc_t 结构,挂载到对应的 dm_mdmlielst 数组中。释放算法核心逻辑是要对空闲页面进行合并,合并成更大的连续的内存页面。
//内存分配页面框架函数
msadsc_t *mm_divpages_fmwk(memmgrob_t *mmobjp, uint_t pages, uint_t *retrelpnr, uint_t mrtype, uint_t flgs)
{
//返回mrtype对应的内存区结构的指针
memarea_t *marea = onmrtype_retn_marea(mmobjp, mrtype);
if (NULL == marea)
{
*retrelpnr = 0;
return NULL;
}
uint_t retpnr = 0;
//内存分配的核心函数
msadsc_t *retmsa = mm_divpages_core(marea, pages, &retpnr, flgs);
if (NULL == retmsa)
{
*retrelpnr = 0;
return NULL;
}
*retrelpnr = retpnr;
return retmsa;
}
//内存分配页面接口
//mmobjp->内存管理数据结构指针
//pages->请求分配的内存页面数
//retrealpnr->存放实际分配内存页面数的指针
//mrtype->请求的分配内存页面的内存区类型
//flgs->请求分配的内存页面的标志位
msadsc_t *mm_division_pages(memmgrob_t *mmobjp, uint_t pages, uint_t *retrealpnr, uint_t mrtype, uint_t flgs)
{
if (NULL == mmobjp || NULL == retrealpnr || 0 == mrtype)
{
return NULL;
}
uint_t retpnr = 0;
msadsc_t *retmsa = mm_divpages_fmwk(mmobjp, pages, &retpnr, mrtype, flgs);
if (NULL == retmsa)
{
*retrealpnr = 0;
return NULL;
}
*retrealpnr = retpnr;
return retmsa;
}
//释放内存页面核心
bool_t mm_merpages_core(memarea_t *marea, msadsc_t *freemsa, uint_t freepgs)
{
bool_t rets = FALSE;
cpuflg_t cpuflg;
//内存区加锁
knl_spinlock_cli(&marea->ma_lock, &cpuflg);
//针对一个内存区进行操作
rets = mm_merpages_onmarea(marea, freemsa, freepgs);
//内存区解锁
knl_spinunlock_sti(&marea->ma_lock, &cpuflg);
return rets;
}
//释放内存页面框架函数
bool_t mm_merpages_fmwk(memmgrob_t *mmobjp, msadsc_t *freemsa, uint_t freepgs)
{
//获取要释放msadsc_t结构所在的内存区
memarea_t *marea = onfrmsa_retn_marea(mmobjp, freemsa, freepgs);
if (NULL == marea)
{
return FALSE;
}
//释放内存页面的核心函数
bool_t rets = mm_merpages_core(marea, freemsa, freepgs);
if (FALSE == rets)
{
return FALSE;
}
return rets;
}
//释放内存页面接口
//mmobjp->内存管理数据结构指针
//freemsa->释放内存页面对应的首个msadsc_t结构指针
//freepgs->请求释放的内存页面数
bool_t mm_merge_pages(memmgrob_t *mmobjp, msadsc_t *freemsa, uint_t freepgs)
{
if (NULL == mmobjp || NULL == freemsa || 1 > freepgs)
{
return FALSE;
}
//调用释放内存页面的框架函数
bool_t rets = mm_merpages_fmwk(mmobjp, freemsa, freepgs);
if (FALSE == rets)
{
return FALSE;
}
return rets;
}
从 MMU 角度看,内存是以页为单位的,但内核中有大量远小于一个页面的内存分配请求。我们用一个内存对象来表示,把一个或者多个内存页面分配出来,作为一个内存对象的容器,在这个容器中容纳相同的内存对象,为此需定义内存对象以及内存对象管理容器的数据结构、初始化、分配、释放、扩容函数。
typedef struct s_FREOBJH{
list_h_t oh_list; //链表
uint_t oh_stus; //对象状态
void* oh_stat; //对象的开始地址
}freobjh_t;
//管理内存对象容器占用的内存页面所对应的msadsc_t结构
typedef struct s_MSCLST
{
uint_t ml_msanr; //多少个msadsc_t
uint_t ml_ompnr; //一个msadsc_t对应的连续的物理内存页面数
list_h_t ml_list; //挂载msadsc_t的链表
}msclst_t;
//内存对象容器
typedef struct s_KMSOB
{
list_h_t so_list; //链表
spinlock_t so_lock; //保护结构自身的自旋锁
uint_t so_stus; //状态与标志
uint_t so_flgs;
adr_t so_vstat; //内存对象容器的开始地址
adr_t so_vend; //内存对象容器的结束地址
size_t so_objsz; //内存对象大小
size_t so_objrelsz; //内存对象实际大小
uint_t so_mobjnr; //内存对象容器中总共的对象个数
uint_t so_fobjnr; //内存对象容器中空闲的对象个数
list_h_t so_frelst; //内存对象容器中空闲的对象链表头
list_h_t so_alclst; //内存对象容器中分配的对象链表头
list_h_t so_mextlst; //内存对象容器扩展kmbext_t结构链表头
uint_t so_mextnr; //内存对象容器扩展kmbext_t结构个数
msomdc_t so_mc; //内存对象容器占用内存页面管理结构
void* so_privp; //本结构私有数据指针
void* so_extdp; //本结构扩展数据指针
}kmsob_t;
虚拟地址空间的数据结构及初始化
由于虚拟地址空间非常巨大,我们绝不能像管理物理内存页面那样,一个页面对应一个结构体。虚拟地址空间往往是以区为单位的,比如栈区、堆区,指令区、数据区,这些区内部往往是连续的,区与区之间却间隔了很大空间。
// kmvarsdsc_t 表示一个虚拟地址区间
typedef struct KMVARSDSC{
spinlock_t kva_lock; //保护自身自旋锁
u32_t kva_maptype; //映射类型
list_h_t kva_list; //链表
u64_t kva_flgs; //相关标志
u64_t kva_limits;
void* kva_mcstruct; //指向它的上层结构
adr_t kva_start; //虚拟地址的开始
adr_t kva_end; //虚拟地址的结束
kvmemcbox_t* kva_kvmbox; //管理这个结构映射的物理页面
void* kva_kvmcobj;
}kmvarsdsc_t;
// virmemadrs_t管理了整个虚拟地址空间的 kmvarsdsc_t 结构
typedef struct s_VIRMEMADRS
{
spinlock_t vs_lock; //保护自身的自旋锁
u32_t vs_resalin;
list_h_t vs_list; //链表,链接虚拟地址区间
uint_t vs_flgs; //标志
uint_t vs_kmvdscnr; //多少个虚拟地址区间
mmadrsdsc_t* vs_mm; //指向它的上层的数据结构
kmvarsdsc_t* vs_startkmvdsc; //开始的虚拟地址区间
kmvarsdsc_t* vs_endkmvdsc; //结束的虚拟地址区间
kmvarsdsc_t* vs_currkmvdsc; //当前的虚拟地址区间
adr_t vs_isalcstart; //能分配的开始虚拟地址
adr_t vs_isalcend; //能分配的结束虚拟地址
void* vs_privte; //私有数据指针
void* vs_ext; //扩展数据指针
}virmemadrs_t;
// 虚拟地址空间作用于应用程序,而应用程序在操作系统中用进程表示。当然,一个进程有了虚拟地址空间信息还不够,还要知道进程和虚拟地址到物理地址的映射信息,应用程序文件中的指令区、数据区的开始、结束地址信息。这些信息综合起来,才能表示一个进程的完整地址空间。
typedef struct s_MMADRSDSC
{
spinlock_t msd_lock; //保护自身的自旋锁
list_h_t msd_list; //链表
uint_t msd_flag; //状态和标志
uint_t msd_stus;
uint_t msd_scount; //计数,该结构可能被共享
sem_t msd_sem; //信号量
mmudsc_t msd_mmu; //MMU相关的信息
virmemadrs_t msd_virmemadrs; //虚拟地址空间
adr_t msd_stext; //应用的指令区的开始、结束地址
adr_t msd_etext;
adr_t msd_sdata; //应用的数据区的开始、结束地址
adr_t msd_edata;
adr_t msd_sbss;
adr_t msd_ebss;
adr_t msd_sbrk; //应用的堆区的开始、结束地址
adr_t msd_ebrk;
}mmadrsdsc_t;
// 因为一个物理页msadsc_t 可能会被多个虚拟地址空间共享,所以没直接把 msadsc_t挂载到 kmvarsdsc_t 结构中去。一个 kmvarsdsc_t 结构,必须要有一个 kvmemcbox_t 结构,才能分配物理内存。
typedef struct KVMEMCBOX
{
list_h_t kmb_list; //链表
spinlock_t kmb_lock; //保护自身的自旋锁
refcount_t kmb_cont; //共享的计数器
u64_t kmb_flgs; //状态和标志
u64_t kmb_stus;
u64_t kmb_type; //类型
uint_t kmb_msanr; //多少个msadsc_t
list_h_t kmb_msalist; //挂载msadsc_t结构的链表
kvmemcboxmgr_t* kmb_mgr; //指向上层结构
void* kmb_filenode; //指向文件节点描述符
void* kmb_pager; //指向分页器 暂时不使用
void* kmb_ext; //自身扩展数据指针
}kvmemcbox_t;
//分配虚拟地址空间的核心函数
adr_t vma_new_vadrs_core(mmadrsdsc_t *mm, adr_t start, size_t vassize, u64_t vaslimits, u32_t vastype){}
//释放虚拟地址空间的核心函数
bool_t vma_del_vadrs_core(mmadrsdsc_t *mm, adr_t start, size_t vassize){}
//缺页异常处理接口
sint_t vma_map_fairvadrs(mmadrsdsc_t *mm, adr_t vadrs){ }
// 一个进程持有一个 mmadrsdsc_t 结构的指针,在这个结构中有虚拟地址区间结构和 MMU 相关的信息
typedef struct s_THREAD
{
spinlock_t td_lock; //进程的自旋锁
list_h_t td_list; //进程链表
uint_t td_flgs; //进程的标志
uint_t td_stus; //进程的状态
uint_t td_cpuid; //进程所在的CPU的id
uint_t td_id; //进程的id
uint_t td_tick; //进程运行了多少tick
uint_t td_privilege; //进程的权限
uint_t td_priority; //进程的优先级
uint_t td_runmode; //进程的运行模式
adr_t td_krlstktop; //应用程序内核栈顶地址
adr_t td_krlstkstart; //应用程序内核栈开始地址
adr_t td_usrstktop; //应用程序栈顶地址
adr_t td_usrstkstart; //应用程序栈开始地址
mmadrsdsc_t* td_mmdsc; //地址空间结构
context_t td_context; //机器上下文件结构
objnode_t* td_handtbl[TD_HAND_MAX];//打开的对象数组
}thread_t;
每个进程拥有 x86 CPU 的整个虚拟地址空间,这个虚拟地址空间被分成了两个部分,上半部分是所有进程都共享的内核部分 ,里面放着一份内核代码和数据,下半部分是应用程序,分别独立,互不干扰。从进程的虚拟地址空间开始,而进程的虚拟地址是由 kmvarsdsc_t 结构表示的,一个 kmvarsdsc_t 结构就表示一个已经分配出去的虚拟地址空间。一个进程所有的 kmvarsdsc_t 结构,要交给进程的 mmadrsdsc_t 结构中的 virmemadrs_t 结构管理。为了管理虚拟地址空间对应的物理内存页面,我们建立了 kvmembox_t 结构,它由 kvmemcboxmgr_t 结构统一管理。在 kvmembox_t 结构中,挂载了物理内存页面对应的 msadsc_t 结构。
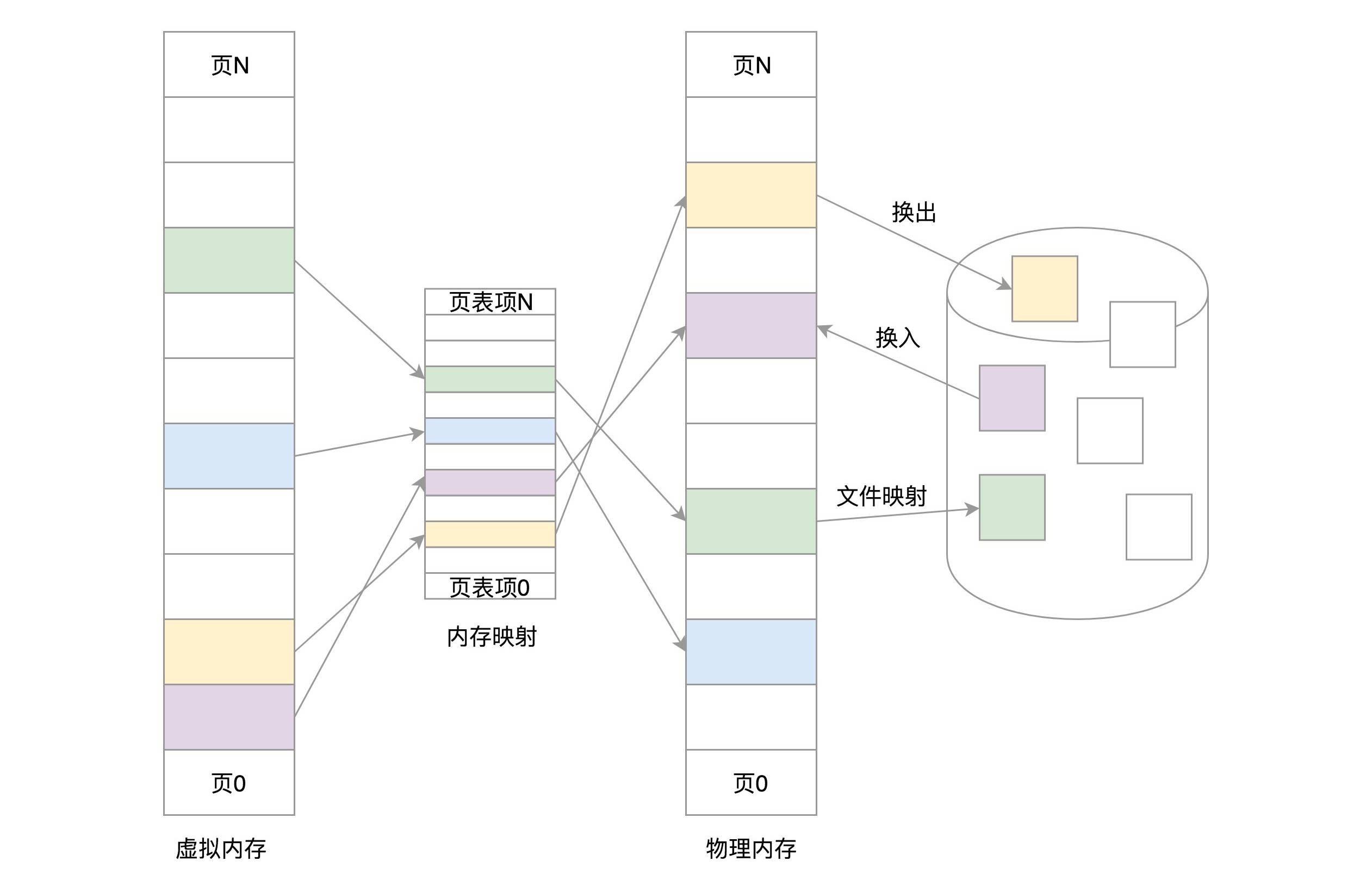
整个虚拟地址空间就是由一个个虚拟地址区间组成的。那么不难猜到,分配一个虚拟地址空间就是在整个虚拟地址空间分割出一个区域,而释放一块虚拟地址空间,就是把这个区域合并到整个虚拟地址空间中去。我们分配一段虚拟地址空间,并没有分配对应的物理内存页面,而是等到真正访问虚拟地址空间时,才触发了缺页异常。查找缺页地址对应的 kmvarsdsc_t 结构,没找到说明没有分配该虚拟地址空间,那属于非法访问不予处理;然后,查找 kmvarsdsc_t 结构下面的对应 kvmemcbox_t 结构,它是用来挂载物理内存页面的;最后,分配物理内存页面并建立 MMU 页表映射关系,即调用物理页分配接口分配一个物理内存页面并把对应的 msadsc_t 结构挂载到 kvmemcbox_t 结构上,接着获取 msadsc_t 结构对应内存页面的物理地址,最后是调用 hal_mmu_transform 函数完成虚拟地址到物理地址的映射工作,它主要是建立 MMU 页表。
Linux 系统中用来管理物理内存页面的伙伴系统,以及负责分配比页更小的内存对象的 SLAB 分配器。
Linux代码上的体现
// 持有task_struct 便可以访问进程在内存中的所有数据
struct task_struct {
...
struct mm_struct *mm;
struct mm_struct *active_mm;
...
void *stack; // 指向内核栈的指针
}
Linux使用mm_struct来表示进程的地址空间,该描述符表示着进程所有地址空间的信息
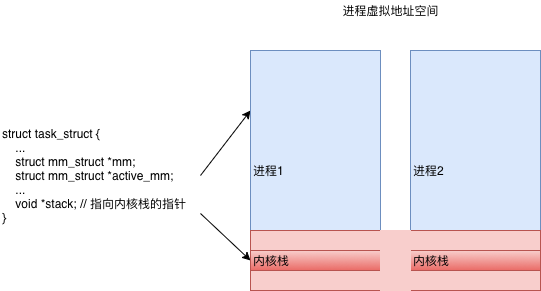
在用户态,进程觉着整个空间是它独占的,没有其他进程存在。但是到了内核里面,无论是从哪个进程进来的,看到的都是同一个内核空间,看到的都是同一个进程列表。虽然内核栈是各用个的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。
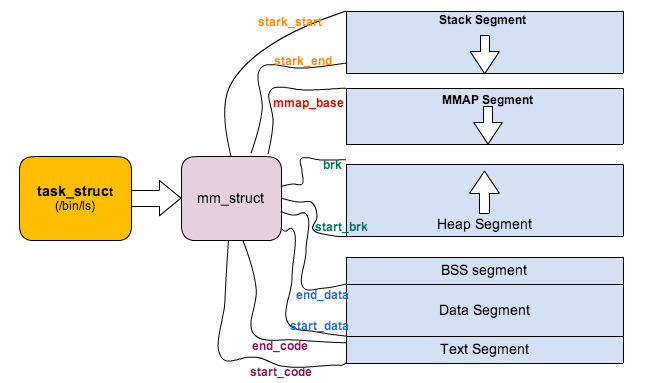
页表的位置
每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶级的 pgd 存放在 task_struct 中的 mm_struct 的 pgd 变量里面。
在一个进程新创建的时候,会调用 fork,对于内存的部分会调用 copy_mm,里面调用 dup_mm。
// Allocate a new mm structure and copy contents from the mm structure of the passed in task structure.
static struct mm_struct *dup_mm(struct task_struct *tsk){
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}
除了创建一个新的 mm_struct,并且通过memcpy将它和父进程的弄成一模一样之外,我们还需要调用 mm_init 进行初始化。接下来,mm_init 调用 mm_alloc_pgd,分配全局页目录项,赋值给mm_struct 的 pdg 成员变量。
static inline int mm_alloc_pgd(struct mm_struct *mm){
mm->pgd = pgd_alloc(mm);
return 0;
}
一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表
如果是用户态进程页表,会有 mm_struct 指向进程顶级目录 pgd,对于内核来讲,也定义了一个 mm_struct,指向 swapper_pg_dir(指向内核最顶级的目录 pgd)。
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
// pgd 页表最顶级目录
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
页表的应用
一个进程 fork 完毕之后,有了内核页表(内核初始化时即弄好了内核页表, 所有进程共享),有了自己顶级的 pgd,但是对于用户地址空间来讲,还完全没有映射过(用户空间页表一开始是不完整的,只有最顶级目录pgd这个“光杆司令”)。这需要等到这个进程在某个 CPU 上运行,并且对内存访问的那一刻了
当这个进程被调度到某个 CPU 上运行的时候,要调用 context_switch 进行上下文切换。对于内存方面的切换会调用 switch_mm_irqs_off,这里面会调用 load_new_mm_cr3。
cr3 是 CPU 的一个寄存器,它会指向当前进程的顶级 pgd。如果 CPU 的指令要访问进程的虚拟内存,它就会自动从cr3 里面得到 pgd 在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
这里需要注意两点。第一点,cr3 里面存放当前进程的顶级 pgd,这个是硬件的要求。cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址。第二点,用户进程在运行的过程中,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
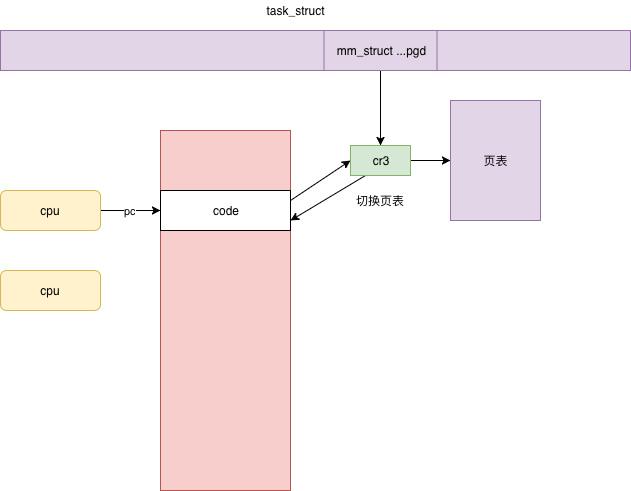
这就可以解释,为什么页表数据在 task_struct 的mm_struct里却又 可以融入硬件地址翻译机制了。
通过缺页中断来“填充”页表
如果对没有进行映射的虚拟内存地址进行读写操作,那么将会发生 缺页异常。Linux 内核会对 缺页异常 进行修复,修复过程如下:获取触发 缺页异常 的虚拟内存地址(读写哪个虚拟内存地址导致的)。查看此虚拟内存地址是否被申请(是否在 brk 指针内),如果不在 brk 指针内,将会导致 Segmention Fault 错误(也就是常见的coredump),进程将会异常退出。如果虚拟内存地址在 brk 指针内,那么将此虚拟内存地址映射到物理内存地址上,完成 缺页异常 修复过程,并且返回到触发异常的地方进行运行。
内存管理并不直接分配物理内存,只有等你真正用的那一刻才会开始分配。只有访问虚拟内存的时候,发现没有映射多物理内存,页表也没有创建过,才触发缺页异常。进入内核调用 do_page_fault,一直调用到 __handle_mm_fault,__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address){
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
// 判断缺页是否发生在内核
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
// 找到待访问地址所在的区域 vm_area_struct
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags){
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}
以handle_pte_fault 的一种场景 do_anonymous_page为例:先通过 pte_alloc 分配一个页表项,然后通过 alloc_zeroed_user_highpage_movable 分配一个页,接下来要调用 mk_pte,将页表项指向新分配的物理页,set_pte_at 会将页表项塞到页表里面。
static int do_anonymous_page(struct vm_fault *vmf){
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
地址空间内的栈
栈是主要用途就是支持函数调用。
大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。
用户栈和内核栈的切换
删改自进程内核栈、用户栈
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
如何相互切换呢?
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态执行时,在内核态执行的最后,将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,一旦进程从内核态返回到用户态后,内核栈中保存的信息无效,会全部恢复。因此,每次进程从用户态陷入内核的时候得到的内核栈都是空的,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
为什么需要单独的进程内核栈?
内核地址空间所有进程空闲,但内核栈却不共享。为什么需要单独的进程内核栈?因为同时可能会有多个进程在内核运行。
所有进程运行的时候,都可能通过系统调用陷入内核态继续执行。假设第一个进程 A 陷入内核态执行的时候,需要等待读取网卡的数据,主动调用 schedule() 让出 CPU;此时调度器唤醒了另一个进程 B,碰巧进程 B 也需要系统调用进入内核态。那问题就来了,如果内核栈只有一个,那进程 B 进入内核态的时候产生的压栈操作,必然会破坏掉进程 A 已有的内核栈数据;一但进程 A 的内核栈数据被破坏,很可能导致进程 A 的内核态无法正确返回到对应的用户态了。
进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
进程切换带来的用户栈切换和内核栈切换
// 持有task_struct 便可以访问进程在内存中的所有数据
struct task_struct {
...
struct mm_struct *mm;
struct mm_struct *active_mm;
...
void *stack; // 指向内核栈的指针
}
从进程 A 切换到进程 B,用户栈要不要切换呢?当然要,在切换内存空间的时候就切换了,每个进程的用户栈都是独立的,都在内存空间里面。
那内核栈呢?已经在 __switch_to 里面切换了,也就是将 current_task 指向当前的 task_struct。里面的 void *stack 指针,指向的就是当前的内核栈。
内核栈的栈顶指针呢?在 __switch_to_asm 里面已经切换了栈顶指针,并且将栈顶指针在 __switch_to加载到了 TSS 里面。
用户栈的栈顶指针呢?如果当前在内核里面的话,它当然是在内核栈顶部的 pt_regs 结构里面呀。当从内核返回用户态运行的时候,pt_regs 里面有所有当时在用户态的时候运行的上下文信息,就可以开始运行了。
主线程的用户栈和一般现成的线程栈
| 用户栈 | 进程主线程 | 一般线程 |
|---|---|---|
| 栈地址 | 进程用户栈 | 在进程的堆里面创建的 |
| 指令指针初始位置 | main函数 | 为线程指定的函数 |
对应着jvm 一个线程一个栈
中断栈
Java和操作系统交互细节中断有点类似于我们经常说的事件驱动编程,而这个事件通知机制是怎么实现的呢,硬件中断的实现通过一个导线和 CPU 相连来传输中断信号,软件上会有特定的指令,例如执行系统调用创建线程的指令,而 CPU 每执行完一个指令,就会检查中断寄存器中是否有中断,如果有就取出然后执行该中断对应的处理程序。
当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。ARM 架构就没有独立的中断栈。
活学活用
- OOM Killer 在 Linux 系统里如果内存不足时,会杀死一个正在运行的进程来释放一些内存。
- Linux 里的程序都是调用 malloc() 来申请内存,如果内存不足,直接 malloc() 返回失败就可以,为什么还要去杀死正在运行的进程呢?Linux允许进程申请超过实际物理内存上限的内存。因为 malloc() 申请的是内存的虚拟地址,系统只是给了程序一个地址范围,由于没有写入数据,所以程序并没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。