前言
文章部分内容来自对 《Redis设计与实现》的学习
Redis设计与实现
从本书的最大的收获就是作者提的几个问题,感觉也是学习redis的精髓
- Redis 的五种数据类型分别是由什么数据结构实现的?
- Redis 的字符串数据类型既可以储存字符串(比如 “hello world” ), 又可以储存整数和浮点数(比如 10086 和 3.14 ), 甚至是二进制位(使用 SETBIT 等命令), Redis 在内部是怎样储存这些不同的值的?
- Redis 的一部分命令只能对特定数据类型执行(比如 APPEND 只能对字符串执行, HSET 只能对哈希表执行), 而另一部分命令却可以对所有数据类型执行(比如 DEL 、 TYPE 和 EXPIRE ), 不同的命令在执行时是如何进行类型检查的? Redis 在内部是否实现了一个类型系统?
- Redis 的数据库是怎样储存各种不同数据类型的键值对的? 数据库里面的过期键又是怎样实现自动删除的?
- 除了数据库之外, Redis 还拥有发布与订阅、脚本、事务等特性, 这些特性又是如何实现的?
- Redis 使用什么模型或者模式来处理客户端的命令请求? 一条命令请求从发送到返回需要经过什么步骤?
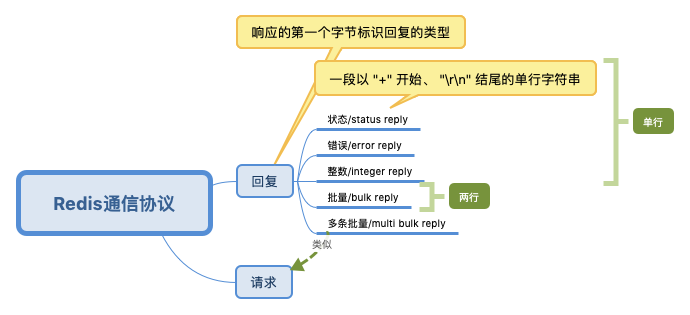
RESP 协议
Redis 协议在以下三个目标之间进行折中:
- 易于实现
- 可以高效地被计算机分析(parse)
- 可以很容易地被人类读懂。不是提供一个
byte[]让客户端随便用
图解Redis通信协议Redis客户端和服务端之间使用一种名为RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信
客户端和服务器通过 TCP 连接来进行数据交互, 服务器默认的端口号为 6379 。客户端和服务器发送的命令或数据一律以 \r\n (CRLF)结尾。
把一些数据结构存在本机或存在远程主机,有一些隐含的意味:
- “本机的”,或者说一个编程语言支持的数据结构包括:基本数据类型,复合类型(string,list,map等)。基本数据类型往往用不着跨主机存储,因为不值当。
- 对于本地访问内存而言,访问一个数据结构要指明两个要素:内存地址和类型。内存地址说明去哪取数据,类型说明取多少数据,取出的数据如何处理。访问远端内存类似,只不过”地址“不再是一个内存地址,而是一个具备唯一性的key,由远端主机完成key到该主机的内存地址的映射。
请求
请求协议的一般形式
*<参数数量> CR LF
$<参数 1 的字节数量> CR LF
<参数 1 的数据> CR LF
...
$<参数 N 的字节数量> CR LF
<参数 N 的数据> CR LF
比如对于命令 set mykey myvalue,实际协议值"*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n"
print 出来是
*3 # 表示3个参数
$3 # 表示第一个参数长度为3
SET # set 命令
$5 # 表示第二个参数长度为5
mykey # 第二个参数值
$7 # 表示第三个参数长度为7
myvalue # 表示第三个参数值
回复
多条批量回复是由多个回复组成的数组, 数组中的每个元素都可以是任意类型的回复, 包括多条批量回复本身。
命令/对象/数据结构之间的关系
struct redisServer {
// ...
redisDb *db; // 一个数组,保存着服务器中的所有数据库
int dbnum; // 服务器的数据库数量,默认16
// ...
}
typedef struct redisDb {
// ...
dict *dict; // 数据库键空间,保存着数据库中的所有键值对
dict *expires; // 过期字典,保存着键的过期时间
}
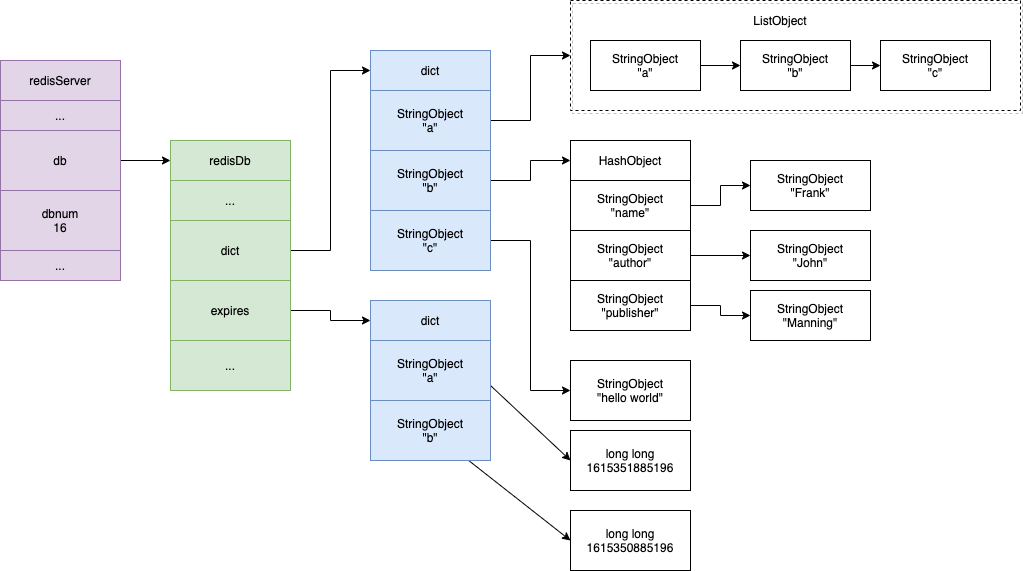
一组redis 命令对应一个对象,对象的存储结构为了性能与空间的平衡,采用encoding策略,根据存储内容的空间大小使用不同的数据结构。
数据结构
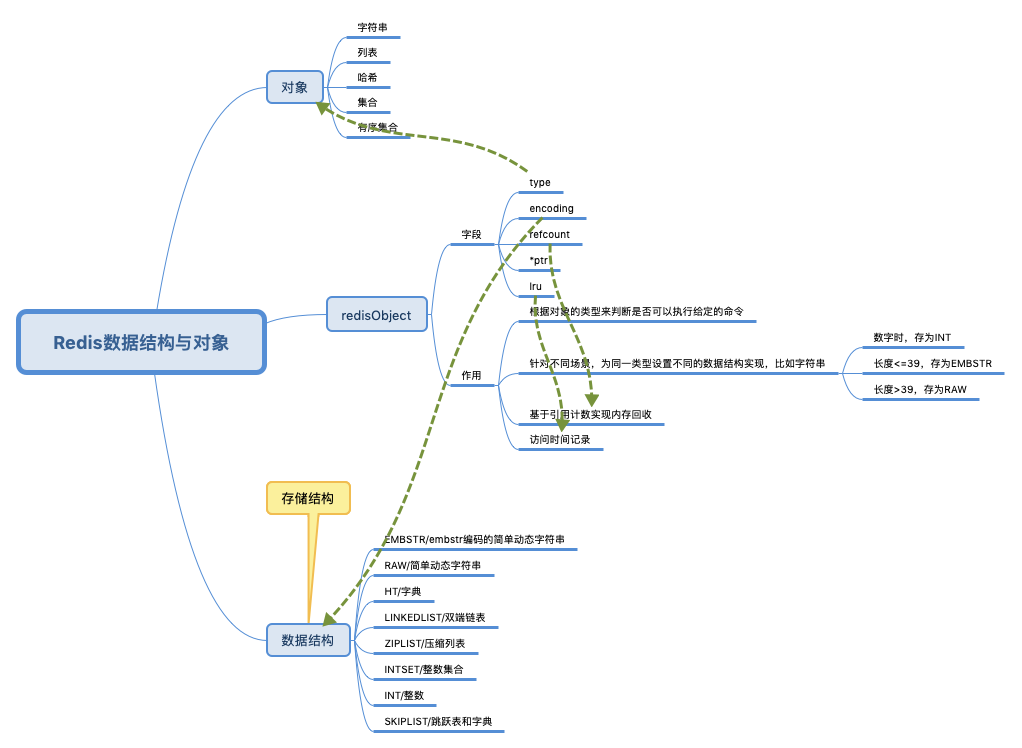
reids 是一个内存数据库、非关系型数据库、支持多种数据结构,in-memory data structure store,当我在说这些名词时,我在说什么?
丰富的数据类型,带来丰富的命令,以字符串为例,一般编程语言对字符串提供多少方法, redis 就大体支持多少字符串操作命令,比如append 等,就好像本地内存提供的操作能力一样(实际上更多,比如过期、订阅等),除了redisTemplate封了一下网络访问外没啥区别。
String msg = "hello world";
String msg = redisTemplate.opsForValue().get("msg");
String msg = "hello " + "world";
redisTemplate.opsForValue().append(msg,"world");
int msg = 1;
String msg = redisTemplate.opsForValue().get("msg");
int msg = msg + 1;
int msg = redisTemplate.opsForValue().increment("msg",1);
命令与数据数据类型有对应(多对多)关系(比如set 处理不了集合),数据类型根据不同情况可以使用不同的数据结构来存储。比如在java 中 List<String> list = new ArrayList/LinkedList<String>() list 的实现方式是在代码中直接指定的。而redis 的list 会自动根据元素特点决定使用ziplist 或linkedlist。
为什么Redis是单线程的
Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。通常来说,单线程的处理能力要比多线程差很多,但是 Redis 却能使用单线程模型达到每秒数十万级别的处理能力,这是为什么呢?其实,这是 Redis 多方面设计选择的一个综合结果。
- 纯内存操作
- 高效的数据结构,例如哈希表和跳表
- 多路复用机制 深度解析单线程的 Redis 如何做到每秒数万 QPS 的超高处理能力 对源码解析很到位。
Redis is single threaded. How can I exploit multiple CPU / cores?
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second。cpu 以及内存读写 的速度足够快,以至于一个线程便支持了100w QPS。很多时候, 瓶颈是内存大小及带宽。也就是说,即便支持了多线程,支持了更高的QPS, 更有可能的是你的网卡带宽先被打满了。
However, to maximize CPU usage you can start multiple instances of Redis in the same box and treat them as different servers.
However with Redis 4.0 we started to make Redis more threaded. For now this is limited to deleting objects in the background, and to blocking commands implemented via Redis modules. For the next releases, the plan is to make Redis more and more threaded.
单线程机制在进行sunion之类的比较耗时的命令时会使redis的并发下降。因为是单一线程,所以同一时刻只有一个操作在进行,所以,耗时的命令会导致并发的下降,不只是读并发,写并发也会下降。
为什么说Redis是单线程的以及Redis为什么这么快!我们不能任由操作系统负载均衡,因为我们自己更了解自己的程序,所以,我们可以手动地为其分配CPU核,而不会过多地占用CPU。类似于netty的arena类似,在极端追求性能的场合,一些中间件会亲自插手cpu调度、内存分配,而不是听从语言的runtime 或操作系统。
单线程也有单线程的好处,比如可以基于redis实现自增id服务