简介
Runnable + Thread 实现了 logic 和 runner 的分离,runner 又进一步扩展为 executor 以便线程复用(控制并发度)。代码交给另一个线程执行,还有一个好处,就是保护调用者线程。在一个项目中,不同的线程的重要性是不同的,比如tomcat 线程池中的线程、mq 消费者线程、netty 的事件驱动线程等,它们是驱动 代码执行的源动力。假设tomcat 线程池一共10个线程,当中有一个任务处理较慢,一个线程被占用较长的时间,会严重限制tomcat的吞吐量。但总有各种耗时的任务,此时,一个重要方法是将 任务交给另一个 线程执行。调用线程 持有 future 对象,可以主动选择 等、不等或者等多长时间。这一点 可以在hystrix 看到。
Executor
Executor provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc. Executor 是一个如此成功的抽象,就像linux的File 接口一样。 任务的提交与执行相分离。 PS:有点类似于Spring IOC,Bean的创建与使用相分离。
Executor 框架为并发编程提供了一个完善的架构体系,不仅包括了线程池的管理,还提供了线程工厂、队列(类似于操作系统中的task_struct 数组)以及拒绝策略等,将线程的调度和管理设置在了用户态。
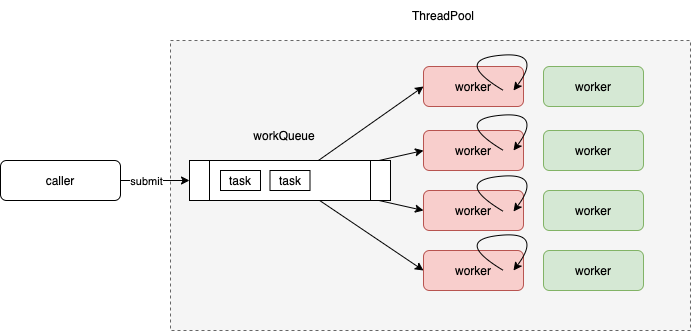
线程复用——ThreadPoolExecutor
戏(细)说 Executor 框架线程池任务执行全过程(上)
提交任务
ThreadPoolExecutor.execute 这个方法看着比较简单,但是线程池什么时候创建新的作业线程来处理任务,什么时候只接收任务不创建作业线程,另外什么时候拒绝任务。线程池的接收任务、维护工作线程的策略都要在其中体现。

作业线程
与ThreadPerTaskExecutor 中的线程不同,线程复用之后,ThreadPoolExecutor 中的线程必须改造为拥有task处理逻辑的作业线程,还必须负责作业线程的创建于销毁。
有一个形象的比喻:经理给组长提任务,并不管组长是自己做还是分派给下面的小伙伴。经理等着组长report 即可,从小伙伴的视角看,每天的“日常”就是不停的从组长那里领取task,组长视情况给任务排期,实在忙不过来便增加人手。
作业线程逻辑
worker线程在受限的条件下创建,其工作内容便是 不停的从workQueue 中取出task 并执行。
private final class Worker implements Runnable{
public void run() {
try {
Runnable task = firstTask;
// 循环从线程池的任务队列获取任务
while (task != null || (task = getTask()!= null) {
runTask(task);// 执行任务
task = null;
}
} finally {
workerDone(this);
}
}
private void runTask(Runnable task) {
task.run();
}
}
你真的了解线程池吗?每一个Worker在创建出来的时候,会调用它本身的run()方法,实现是runWorker(this),这个实现的核心是一个while循环,这个循环不结束,Worker线程就不会终止,就是这个基本逻辑。
- 在这个while条件中,有个getTask()方法是核心中的核心,它所做的事情就是从等待队列中取出任务来执行
- 如果没有达到corePoolSize,则创建的Worker在执行完它承接的任务后,核心线程会用workQueue.take()取任务、注意,这个接口是阻塞接口,如果取不到任务,Worker线程一直阻塞。
- 如果超过了corePoolSize,或者allowCoreThreadTimeOut,一个Worker在空闲了之后,非核心线程会用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)取任务。注意,这个接口只阻塞等待keepAliveTime时间,超过这个时间返回null,则Worker的while循环执行结束,则被终止了。
作业线程的管理
ThreadPoolExecutor 作业线程 由一个HashSet 成员专门持有, 管理/crud大都由调用方线程触发
- caller thread 提交任务,在特定场景下(核心线程数、最大线程数、任务队列长度),由addThread 创建新线程
- caller thread 线程调用shutdown,作业线程在 没有任务或shutdown状态下自动结束
创建新的作业线程逻辑
private Thread addThread(Runnable firstTask) {
// 为当前接收到的任务 firstTask 创建 Worker
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w);
w.thread = t;
// 将 Worker 添加到作业集合 HashSet<Worker> workers 中,并启动作业
workers.add(w);
t.start();
return t;
}
对于资源紧张的应用,如果担心线程池资源使用不当,可以利用ThreadPoolExecutor的API(有很多get方法可以获取状态)实现简单的监控,然后进行分析和优化。
对Executor 的扩展

对Executor 的扩展 主要体现在几个方面
- 规范 作业线程的管理,比如ExecutorService
- 提供 更丰富的 异步处理返回值,帮忙执行下回调,比如guava 的ListeningExecutorService
- 优化特定场景,比如netty的SingleThreadEventExecutor,只有一个作业线程
- 针对特定业务场景,更改作业线程的处理逻辑(不单纯执行Runnable.run)。比如netty的EventLoopGroup,其作业线程逻辑为 io + task ,并可以根据ioRatio 调整io 与task的cpu 占比。
在 ExecutorService 中,正如其名字暗示的一样,定义了一个服务,定义了完整的线程池的行为,可以接受提交任务、执行任务、关闭服务。抽象类 AbstractExecutorService 类实现了 ExecutorService 接口,也实现了接口定义的默认行为。
Using as a generic library 将netty的并发编程库与guava 与jdk8 做了对比,Because Netty tries to minimize its set of dependencies, some of its utility classes are similar to those in other popular libraries, such as Guava.
在上图中,netty EventExecutorGroup 的方法返回的是netty 自己实现的io.netty.util.concurrent.Future extends java.util.concurrent.Future,guava 则直接一点,ListeningExecutorService 直接返回自己定义的com.google.common.util.concurrent.ListenableFuture extends java.util.concurrent.Future
EventExecutorGroup 使用实例(不一定非得netty里才能用)
EventExecutorGroup group = new DefaultEventExecutorGroup(4); // 4 threads
Future<?> f = group.submit(new Runnable() { ... });
f.addListener(new FutureListener<?> {
public void operationComplete(Future<?> f) {
..
}
});
...
Executor的使用
百花齐放的Future
同步方法有参数和返回值,异步方法也有参数和返回值,只是异步方法的返回值 统一为Future 抽象。我们可以直接对同步方法的返回值进行处理,而java 也在不断地对Future进行扩展以对异步结果进行处理。
Chaining async calls using Java Futures

- A Future represents the result of an asynchronous computation.
- Future 模式相当于一个占位符,代表一个操作的未来的结果
- A Future (also called promise, task or deferred depending on the programming language) is a proxy to an asynchronous computation
- This approach of making Future a type means that an asynchronous computation is a first class object, which can be passed to other functions and received as a result。 如果异步方法只能通过回调来处理异步结果,则异步方法就不能作为另一个方法的参数了。
- Future also makes chains of transformations easily doable via functions like map, which allow you to transform the result into a result of another type while using a strongly typed and unit testable function. 与Future 神似的是Optional,它们都可以采用Stream 类似的方法链
谁来处理异步操作的结果
异步和回调是孪生兄弟,毕竟不管同步还是异步,都要对拿到的结果进行处理。对结果的处理,可以直接写在异步方法的回调中,也可以挂在异步方法返回的future中。异步本身分为调用线程和执行线程,对异步结果的后续处理也有几种情况
- 执行线程处理
- 额外传入一个executor线程(池)处理,此时对异步结果的处理 本身又可以一个异步操作
此外,我们可以按功能对线程池进行划分,比如rpc框架中的快慢线程池、IO框架中的IO线程池和CPU密集型线程池。
One issue with complex workflows is that you might have a mixture of CPU and I/O intensive steps. The most common way to solve this problem is to use two thread pools, one with a large number of threads for I/O and another one with one thread per physical core for CPU intensive tasks. This means that in addition to specifying the order of the steps, we also have to specify where should each function be executed. Future also helps us with this problem, because the supplyAsync method also allows fine grained control of where each function should be executed.
FutureTask
我们来看一个Futrue的简单使用
ExecutorService executor = Executors.newFixedThreadPool();
Future<Integer> future = executor.submit(new MyJob()));
跟踪submit方法所属的类,Executors.newFixedThreadPool() ==> ThreadPoolExecutor ==> AbstractExecutorService
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
返回的future是一个FutureTask,FutureTask是interface RunnableFuture<V> extends Runnable, Future<V>的实现类。
你真的了解线程池吗?get的核心实现是有个awaitDone方法,这是一个死循环,只有任务的状态是“已完成”,才会跳出死循环;否则会依赖UNSAFE包下的LockSupport.park原语进行阻塞,等待LockSupport.unpark信号量。而这个信号量只有当运行结束获得结果、或者出现异常的情况下,才会发出来。分别对应方法set和setException。这就是异步执行、阻塞获取的原理
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
// 核心代码
s = awaitDone(false, 0L);
return report(s);
}
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null; boolean queued = false;
for (;;) { // 死循环
if (Thread.interrupted()) { removeWaiter(q);throw new InterruptedException();}
int s = state;
// 只有任务的状态是’已完成‘,才会跳出死循环
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
对Future 的扩展
不管同步异步,都要拿到数据的结果,并且对拿到的结果进行后续处理。区别只是,同步代码是按照时间顺序书写的,更符合人类直觉,而异步代码则要转换下思维,Future future = timeConsumingOperation() 之后立马future.get() 就没什么意思了, 所以异步代码的“文风”(学名:异步流程控制模式)有几种
- 串行(series),后一个调用参数依赖前一个调用的结果。
- 并行(parallel),连续发起多个异步操作,然后对异步结果进行组合
- 瀑布(waterfall)等,后一个调用是否执行 + 调用参数 依赖前一个调用的结果
解决回调地狱——promise模式
CompletableFuture原理与实践-外卖商家端API的异步化在Java8之前我们一般通过Future实现异步,Future用于表示异步计算的结果,只能通过阻塞或者轮询的方式获取结果,而且不支持设置回调方法。Netty 和 Guava 的扩展都提供了 addListener 这样的接口,用于处理 Callback 调用,但future的Callback容易出现回调地狱的问题,由此衍生出了 Promise 模式来解决这个问题。
jdk1.8 也提供了相关的方案:CompletableFuture,A Future that may be explicitly completed (setting its value and status), and may be used as a CompletionStage, supporting dependent functions and actions that trigger upon its completion.
[concurrency-interest] CompletableFuture CompletableFuture 曾经被讨论过以下命名:SettableFuture, FutureValue, Promise, and probably others.
基于异步接口组织业务逻辑——编排/Futures
the biggest advantage of using Futures is composability. You might imagine that dealing with transformations which are themselves asynchronous means having to somehow extract your result from a mess that looks like Future<Future<…<Future<T>>…>>. The existence of methods like thenCompose means that any sequence of asynchronous operations will be handled like one asynchronous operation in the rest of your program and this what makes reasoning about and working with these operations much easier. 将多个异步操作组合为一个异步操作
guava ListenableFuture和AbstractFuture
ListenableFuture的简单使用
ListeningExecutorService executorService=MoreExecutors.listeningDecorator(Executors.newCachedThreadPool());
final ListenableFuture<Integer> listenableFuture = executorService.submit(new MyJob<Integer>());
// 添加监听事件
Futures.addCallback(listenableFuture, new FutureCallback() {
public void onSuccess(Integer result) {}
public void onFailure(Throwable thrown) {}
});
跟踪submit方法所属的类,ListeningExecutorService ==> AbstractListeningExecutorService ==> AbstractExecutorService
public abstract class AbstractListeningExecutorService extends AbstractExecutorService{
protected final <T> ListenableFutureTask<T> newTaskFor(Runnable runnable, T value){
return ListenableFutureTask.create(runnable, value);
}
public <T> ListenableFuture<T> submit(Callable<T> task) {
return (ListenableFuture)super.submit(task);
}
}
public abstract class AbstractExecutorService implements ExecutorService{
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
}
实际执行的submit方法和上节的submit方法一样一样的,但在submit方法中,上节执行的是AbstractExecutorService.newTaskFor返回FutureTask,此处执行的是AbstractListeningExecutorService.newTaskFor返回ListenableFutureTask,其实际也是个java.util.concurrent.FutureTask。所以一个ListenableFuture具有cancel的能力就不奇怪了。看来本质上,ListenableFutureTask取消任务的方式还是和FutureTask一样。
ListenableFuture所具备的addListener方法则是任务挂在一个地方,当run方法执行完毕后,执行这些任务。(不同的guava版本实现代码有很大不同)
CompletionFutre
我们看jdk1.8 CompletionFutre,可以看到:各种thenXX,即便对同步调用的返回值进行各种处理,也不过如此了。将异步代码写的如何更像 同步代码 一点,是异步抽象/封装一个发展方向。
void business(){
Value value1 = timeConsumingOperation1();
Object result1 = function1(value1);
Object result2 = function2(value1);
Value value2 = timeConsumingOperation2();
Object result3 = function3(value1,value2);
...
}
void business(){
CompletionFutre future1 = timeConsumingOperationAsync1();
CompletionFutre future2 = timeConsumingOperationAsync2();
future1.thenApply(function1).thenApply(function2).thenCombine(future2,function3);
...
}
CompletableFuture中包含两个字段:result和stack。result用于存储当前CF的结果,stack(Completion)表示当前CF完成后需要触发的依赖动作(Dependency Actions),去触发依赖它的CF的计算,依赖动作可以有多个(表示有多个依赖它的CF),以栈(Treiber stack)的形式存储,stack表示栈顶元素。