简介
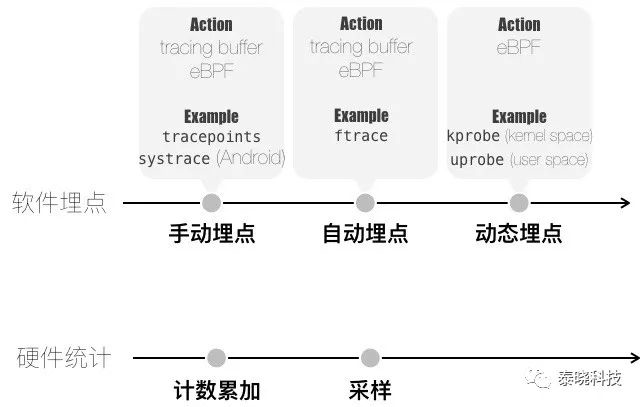
如何通过监控找到性能瓶颈?
- 宏观上,找出整个分布式系统中的瓶颈组件。全链路监控
- 微观上,快速地找出进程内的瓶颈函数,就是从代码层面直接寻找调用次数最频繁、耗时最长的函数,通常它就是性能瓶颈。火焰图
cpu
CPU 的物理核与逻辑核
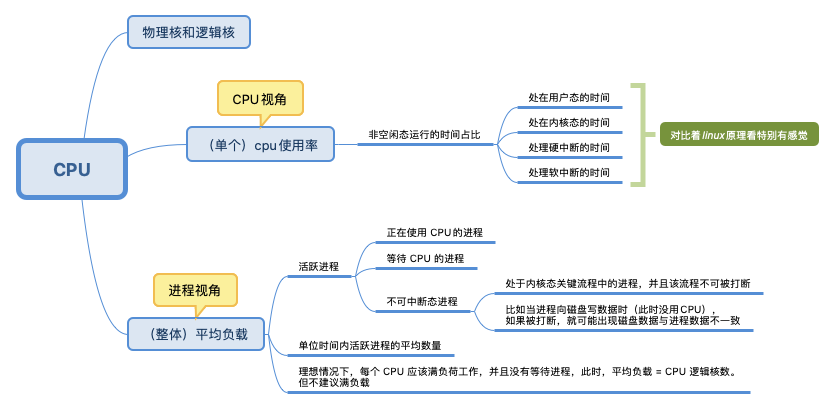
一台机器可能包含多块 CPU 芯片,多个 CPU 之间通过系统总线通信。一块 CPU 芯片可能包含多个物理核,每个物理核都是一个实打实的运算核心(包括运算器、存储器等)。超线程(Hyper-Threading)技术可以让一个物理核在单位时间内同时处理两个线程,变成两个逻辑核。但它不会拥有传统单核 2 倍的处理能力,也不可能提供完整的并行处理能力。
假设一个 CPU 芯片就是一个班级;它有 2 个物理核,也就是 2 个同学,老师让他们分别担任班长和体育委员;过了一段时间,校长要求每个班级还要有学习委员和生活委员,理论上还需要 2 位同学,但是这个班级只有 2 个人,最后老师只能让班长和体育委员兼任。这样一来,对于不了解的人来说,这个班级有班长、体育委员、学习委员和生活委员 4 个职位。
top
top 命令输出
top - 18:31:39 up 158 days, 4:45, 2 users, load average: 2.63, 3.48, 3.53
Tasks: 260 total, 2 running, 258 sleeping, 0 stopped, 0 zombie
%Cpu(s): 38.1 us, 4.2 sy, 0.0 ni, 53.5 id, 2.3 wa, 0.0 hi, 1.9 si, 0.0 st
KiB Mem : 16255048 total, 238808 free, 7608872 used, 8407368 buff/cache
KiB Swap: 33554428 total, 31798304 free, 1756124 used. 7313144 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32080 root 20 0 8300552 4.125g 11524 S 86.4 26.6 1157:05 java
995 root 20 0 641260 41312 39196 S 28.6 0.3 7420:54 rsyslogd
top 命令找到%CPU 排位最高的进程id=32080,进而找到对应的容器
CPU 使用率就是 CPU 非空闲态运行的时间占比,比如,单核 CPU 1s 内非空闲态运行时间为 0.8s,那么它的 CPU 使用率就是 80%;双核 CPU 1s 内非空闲态运行时间分别为 0.4s 和 0.6s,那么,总体 CPU 使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%
%Cpu(s): 38.1 us, 4.2 sy, 0.0 ni, 53.5 id, 2.3 wa, 0.0 hi, 1.9 si, 0.0 st
上述比例加起来是100%
- us(user):表示 CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。
- sy(sys):表示 CPU 在内核态运行的时间百分比(不包括中断),通常内核态 CPU 越低越好,否则表示系统存在某些瓶颈。
- ni(nice):表示用 nice 修正进程优先级的用户态进程执行的 CPU 时间。nice 是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计 CPU 开销。
- id(idle):表示 CPU 处于空闲态的时间占比,此时,CPU 会执行一个特定的虚拟进程,名为 System Idle Process。
- wa(iowait):表示 CPU 在等待 I/O 操作完成所花费的时间,通常该指标越低越好,否则表示 I/O 存在瓶颈,可以用 iostat 等命令做进一步分析。
- hi(hardirq):表示 CPU 处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。
- si(softirq):表示 CPU 处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。
- st(steal):表示 CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。
CPU 使用率与平均负载的关系
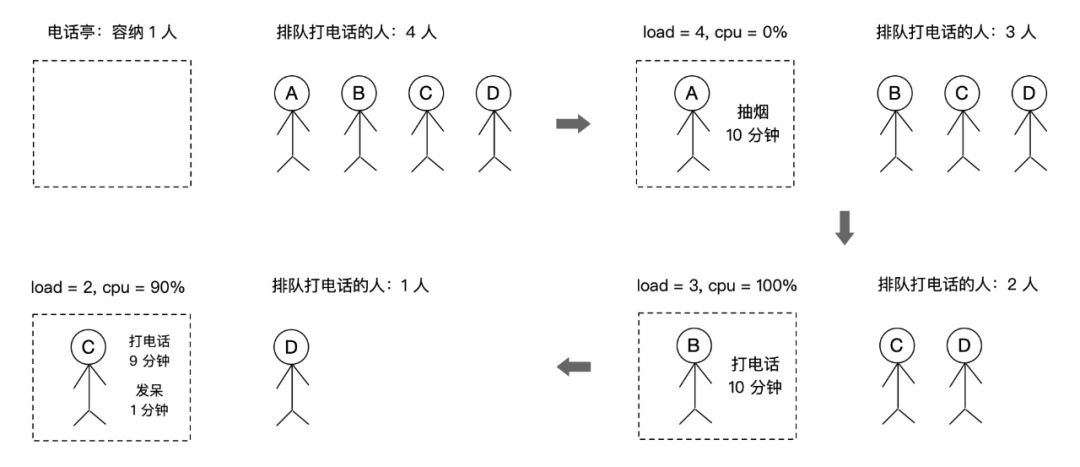
CPU 使用率是单位时间内 CPU 繁忙程度的统计。而平均负载不仅包括正在使用 CPU 的进程,还包括等待 CPU 或 I/O 的进程。因此,两者不能等同。举一个例子:假设现在有一个电话亭,有 4 个人在等待打电话,电话亭同一时刻只能容纳 1 个人打电话,只有拿起电话筒才算是真正使用。那么 CPU 使用率就是拿起电话筒的时间占比,它只取决于在电话亭里的人的行为,与平均负载没有非常直接的关系。而平均负载是指在电话亭里的人加上排队的总人数。
LinuxLoad Average= 可运行队列进程平均数 + 休眠队列中不可打断的进程平均数
一文说清linux system loadload衡量的是task(linux 内核中用于描述一个进程或者线程)对系统的需求(CPU、内存、IO等等),system load average由内核负载计算并记录在/proc/loadavg 文件中, 用户态的工具(比如uptime,top等等)读的都是这个文件。内核是怎么计算load average的? 指数加权移动平均法:a1 = a0 * factor + a * (1 - factor),其中a0是上一时刻的值,a1是当前时刻的值,factor是一个系数,取值范围是[0,1],a是当前时刻的某个指标采样值。
我们一般认为:
- 如果load接近0,意味着系统处于空闲状态;
- 如果 1min 平均值高于 5min 或 15min 平均值,则负载正在增加;
- 如果 1min 平均值低于 5min 或 15min 平均值,则负载正在减少;
- 如果它们高于系统 CPU 的数量,那么系统很可能遇到了性能问题(视情况而定)。
如何排查用户态 CPU 使用率高?
一文说清linux system load导致load 飙高的原因,说简单也简单,无非就是runnable 或者 uninterruptible 的task 增多了。但是说复杂也复杂,因为导致task进入uninterruptible状态的路径非常多(粗略统计,可能有400-500条路径)。PS:
- 周期性飙高
- IO原因
- 内存原因,比如task 在申请内存的时候,可能会触发内存回收,如果触发的是直接内存回收,那对性能的伤害很大。
- 锁,比如采用mutex_lock进行并发控制的路径上,一旦有task 拿着lock 不释放,其他的task 就会以TASK_UNINTERRUPTIBLE的状态等待,也会引起load飙高。
- user CPU,有些情况下load飙高是业务的正常表现,此时一般表现为user cpu 飙高
迟分析需要深入内核内部,在内核路径上埋点取数。所以这类工具的本质是内核probe,包括systemtap,kprobe,ebpf等等。但是probe 技术必须结合知识和经验才能打造成一个实用的工具。阿里自研的ali-diagnose可以进行各种delay分析,irq_delay, sys_delay, sched_delay, io_delay, load-monitor。
如果想定位消耗 CPU 最多的 Java 代码,可以遵循如下思路:
- 通过
top命令找到 CPU 消耗最多的进程号; - 通过
top -Hp 进程号命令找到 CPU 消耗最多的线程号(列名仍然为 PID); - 通过
printf "%x\n" 线程号命令输出该线程号对应的 16 进制数字; - 通过
jstack 进程号 | grep 16进制线程号 -A 10命令找到 CPU 消耗最多的线程方法堆栈。
如果是非 Java 应用,可以将 jstack 替换为 perf。 生产系统推荐使用 APM 产品,比如阿里云的 ARMS,可以自动记录每类线程的 CPU 耗时和方法栈(并在后台展示),开箱即用,自动保留问题现场
如何限制cpu的使用
The bandwidth allowed for a group(进程所属的组) is specified using a quota and period. Within each given “period” (microseconds), a group is allowed to consume only up to “quota” microseconds of CPU time. When the CPU bandwidth consumption of a group exceeds this limit (for that period), the tasks belonging to its hierarchy will be throttled and are not allowed to run again until the next period. 有几个点
- cpu 不像内存 一样有明确的大小单位,单个cpu 是独占的,只能以cpu 时间片来衡量。
- 进程耗费的限制方式:在period(毫秒/微秒) 内该进程只能占用 quota (毫秒/微秒)。
quota /period = %CPU。PS:内存隔离是 申请内存的时候判断 判断已申请内存有没有超过阈值。cpu 隔离则是 判断period周期内,已耗费时间有没有超过 quota。PS: 频控、限流等很多系统也是类似思想 - period 指的是一个判断周期,quota 表示一个周期内可用的多个cpu的时间和。 所以quota 可以超过period ,比如period=100 and quota=200,表示在100单位时间里,进程要使用cpu 200单位,需要两个cpu 各自执行100单位
- 每次拿cpu 说事儿得提两个值(period 和 quota)有点麻烦,可以通过进程消耗的 CPU 时间片quota来统计出进程占用 CPU 的百分比。这也是我们看到的各种工具中都使用百分比来说明 CPU 使用率的原因(下文多出有体现)。
ps
[root@deployer ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 2018 ? 00:00:29 /usr/lib/systemd/systemd --system --deserialize 21
root 2 0 0 2018 ? 00:00:00 [kthreadd]
root 3 2 0 2018 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 2018 ? 00:00:00 [kworker/0:0H]
root 9 2 0 2018 ? 00:00:40 [rcu_sched]
......
root 337 2 0 2018 ? 00:00:01 [kworker/3:1H]
root 380 1 0 2018 ? 00:00:00 /usr/lib/systemd/systemd-udevd
root 415 1 0 2018 ? 00:00:01 /sbin/auditd
root 498 1 0 2018 ? 00:00:03 /usr/lib/systemd/systemd-logind
......
root@pts/0
root 32794 32792 0 Jan10 pts/0 00:00:00 -bash
root 32901 32794 0 00:01 pts/0 00:00:00 ps -ef
三类进程
- pid=1 init进程Systemd
- pid=2 内核线程kthreadd,用户态不带中括号, 内核态带中括号。在 linux 内核中有一些执行定时任务的线程, 比如定时写回脏页的 pdflush, 定期回收内存的 kswapd0, 以及每个 cpu 上都有一个负责负载均衡的 migration 线程等.
- tty 带问号的,说明不是前台启动的,一般都是后台启动的服务
perf
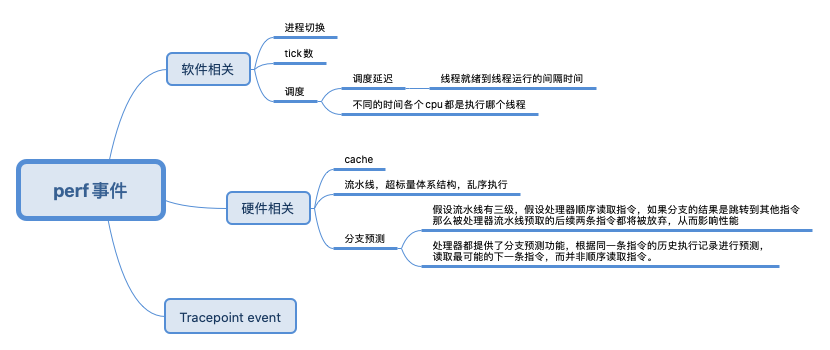
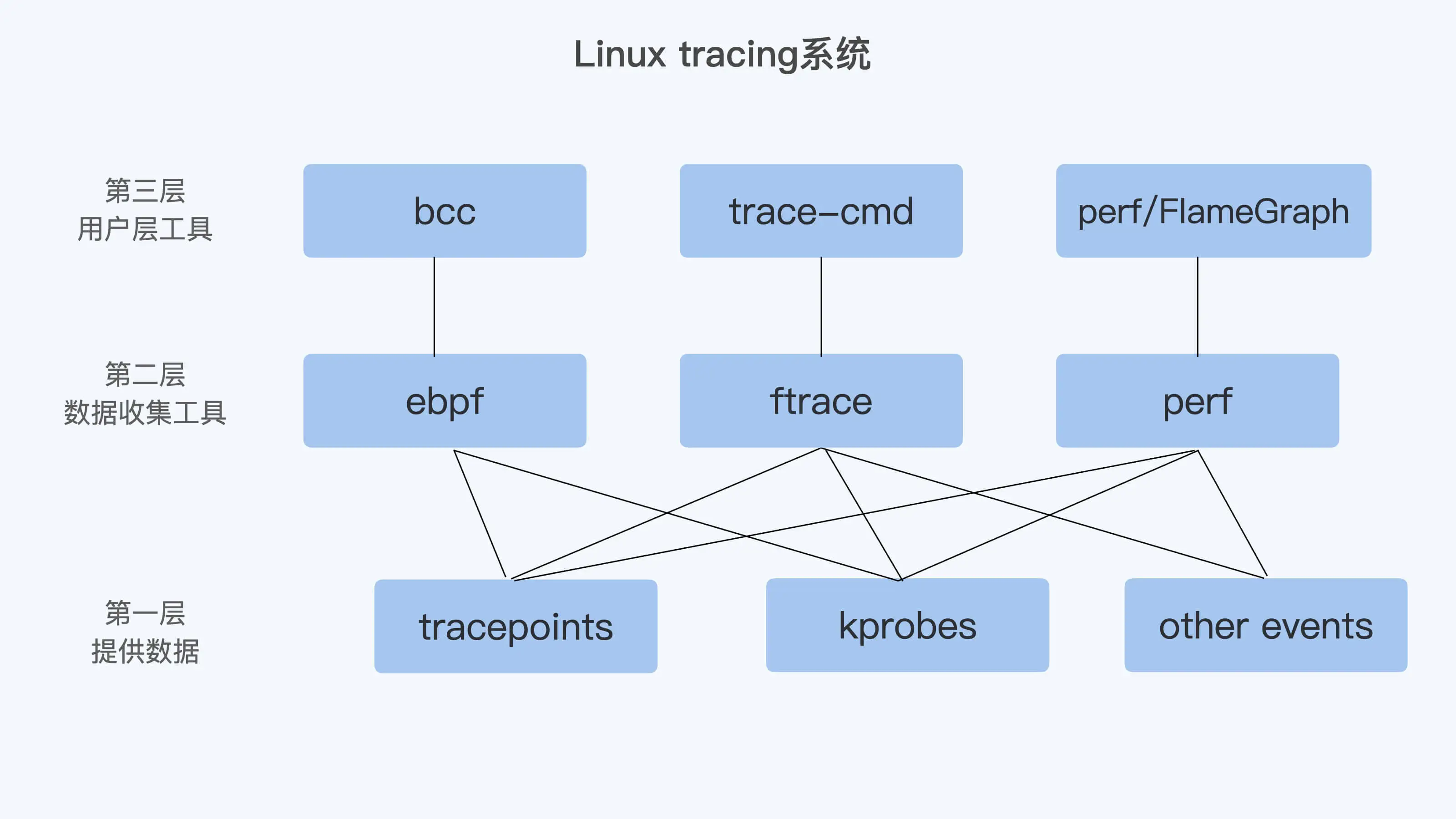
perf began as a tool for using the performance counters subsystem in Linux, and has had various enhancements to add tracing capabilities. linux 有一个performance counters,perf 是这个子系统的外化。perf是性能分析的必备工具, 它最核心的能力是能访问硬件上的Performance Monitor Unit (PMU)。
perf的原理是这样的:每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。这是一种采样的模式,我们预期,运行时间越多的函数,被时钟中断击中的机会越大,从而推测,那个函数(或者pid等)的CPU占用率就越高。perf最大的好处是它可以直接跟踪到整个系统的所有程序(而不仅仅是内核),所以perf通常是我们分析的第一步,我们先看到整个系统的outline,然后才会进去看具体的调度,时延等问题。
event 和 采样
三类event,event 是 perf 工作的基础,主要有两种:有使用硬件的 PMU 里的 event,也有在内核代码中注册的 event。
- Hardware event,Hardware event 来自处理器中的一个 PMU(Performance Monitoring Unit),这些 event 数目不多,都是底层处理器相关的行为,perf 中会命名几个通用的事件,比如 cpu-cycles,执行完成的 instructions,Cache 相关的 cache-misses。不同的处理器有自己不同的 PMU 事件
- Performance counters are CPU hardware registers that count hardware events such as instructions executed, cache-misses suffered, or branches mispredicted. They form a basis for profiling applications to trace dynamic control flow and identify hotspots. perf provides rich generalized abstractions over hardware specific capabilities. Among others, it provides per task, per CPU and per-workload counters, sampling on top of these and source code event annotation.
- Software event,Software event 是定义在 Linux 内核代码中的几个特定的事件,比较典型的有进程上下文切换(内核态到用户态的转换)事件 context-switches、发生缺页中断的事件 page-faults 等。
- Tracepoints event,实现方式和 Software event 类似,都是在内核函数中注册了 event。不仅是用在 perf 中,它已经是 Linux 内核 tracing 的标准接口了,ftrace,ebpf 等工具都会用到它。
- Tracepoints are instrumentation points placed at logical locations in code, such as for system calls, TCP/IP events, file system operations, etc. These have negligible(微不足道的) overhead when not in use, and can be enabled by the perf command to collect information including timestamps and stack traces. perf can also dynamically create tracepoints using the kprobes and uprobes frameworks, for kernel and userspace dynamic tracing. The possibilities with these are endless.
在这些 event 都准备好了之后,perf 又是怎么去使用这些 event 呢?有计数和采样两种方式
- 计数,就是统计某个 event 在一段时间里发生了多少次。一般用perf stat 查看
- 采样,Perf 对 event 的采样有两种模式:
- 按照 event 的数目(period),比如每发生 10000 次 cycles event 就记录一次 IP、进程等信息, perf record 中的 -c 参数可以指定每发生多少次,就做一次记录
- 定义一个频率(frequency), perf record 中的 -F 参数就是指定频率的,比如 perf record -e cycles -F 99 – sleep 1 ,就是指采样每秒钟做 99 次。
- 通过-e指定感兴趣的一个或多个event(perf list可以列出支持的event)
- 指定采样的范围, 比如进程级别 (-p), 线程级别 (-t), cpu级别 (-C), 系统级别 (-a)
使用 perf 的常规步骤:在 perf record 运行结束后,会在磁盘的当前目录留下 perf.data 这个文件,里面记录了所有采样得到的信息。然后我们再运行 perf report 命令,查看函数或者指令在这些采样里的分布比例,后面我们会用一个例子说明。或者
// 在 perf record 运行结束后,会在磁盘的当前目录留下 perf.data 这个文件,里面记录了所有采样得到的信息。
# perf record -a -g -- sleep 60
// 用 perf script 命令把 perf record 生成的 perf.data 转化成分析脚本
# perf script > out.perf
# git clone --depth 1 https://github.com/brendangregg/FlameGraph.git
# FlameGraph/stackcollapse-perf.pl out.perf > out.folded
// 用 FlameGraph 工具来读取这个脚本,生成火焰图。
# FlameGraph/flamegraph.pl out.folded > out.sv
perf record 在不加 -e 指定 event 的时候,它缺省的 event 就是 Hardware event cycles。
perf stat
perf stat 针对程序 t1 的输出
$perf stat ./t1
Performance counter stats for './t1':
262.738415 task-clock-msecs # 0.991 CPUs
2 context-switches # 0.000 M/sec
1 CPU-migrations # 0.000 M/sec
81 page-faults # 0.000 M/sec
9478851 cycles # 36.077 M/sec (scaled from 98.24%)
6771 instructions # 0.001 IPC (scaled from 98.99%)
111114049 branches # 422.908 M/sec (scaled from 99.37%)
8495 branch-misses # 0.008 % (scaled from 95.91%)
12152161 cache-references # 46.252 M/sec (scaled from 96.16%)
7245338 cache-misses # 27.576 M/sec (scaled from 95.49%)
0.265238069 seconds time elapsed
perf stat 给出了其他几个最常用的统计信息:
- Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
- Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
- Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
- CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
- Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
- Instructions: 机器指令数目。
- IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
- Cache-references: cache 命中的次数
- Cache-misses: cache 失效的次数。
通过指定 -e 选项,可以改变 perf stat 的缺省事件 ( 可以通过 perf list 来查看 )。假如你已经有很多的调优经验,可能会使用 -e 选项来查看您所感兴趣的特殊的事件。
perf sched
Perf – Linux下的系统性能调优工具,第 2 部分未读
perf sched 使用了转储后再分析 (dump-and-post-process) 的方式来分析内核调度器的各种事件
ftrace
ftrace对内核函数做 trace。最重要的有两个 tracers,分别是 function 和 function_graph。
- function tracer 可以用来记录内核中被调用到的函数的情况,比如或者我们关心的进程调用到的函数。还可以设置 func_stack_trace 选项,来查看被 trace 函数的完整调用栈。
- function_graph trracer 可以用来查看内核函数和它的子函数调用关系以及调用时间
ftrace 的操作都可以在 tracefs 这个虚拟文件系统中完成(对于 CentOS,这个 tracefs 的挂载点在 /sys/kernel/debug/tracing 下),用户通过 tracefs 向内核中的 function tracer 发送命令,然后 function tracer 把收集到的数据写入一个 ring buffer,再通过 tracefs 输出给用户。
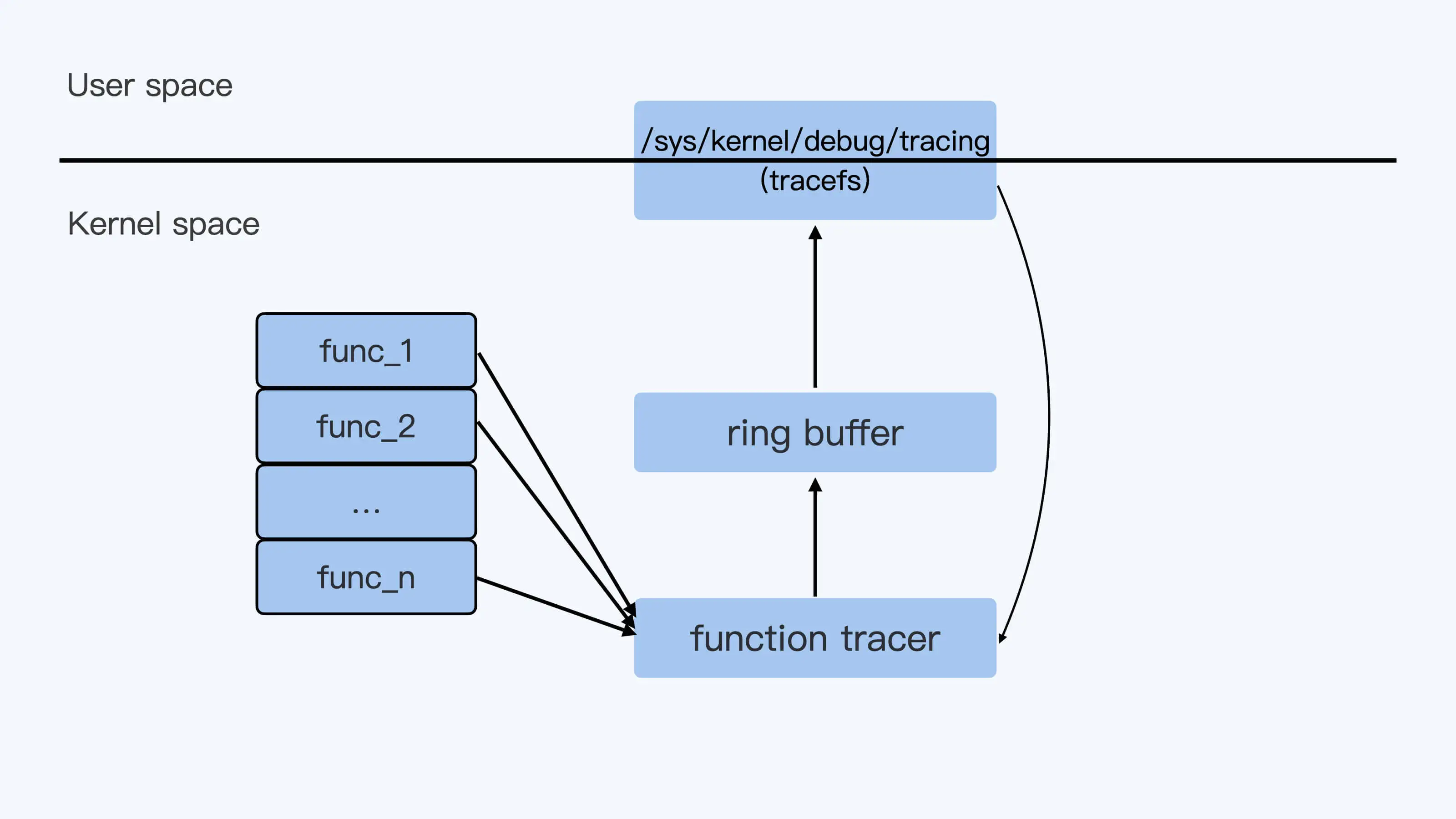
frace 可以收集到内核中任意一个函数被调用的情况,这点是怎么做到的?这是因为在内核的每个函数中都加上了 hook 点。但不是在源码上直接加入的,而是利用 gcc 编译器的特性,为每个内核函数二进制码中预留了 5 个字节。
Tracepoint 和 kprobe
tracepoint 其实就是在 Linux 内核的一些关键函数中显式埋下的 hook 点(hook点的逻辑是 寻找注册的probe 函数并执行),这样在 tracing 的时候,我们就可以在这些固定的点上挂载调试的函数,然后查看内核的信息。
并不是在所有的函数中都有 tracepoint,我们又该怎么办呢?kprobe 可以动态地在所有的内核函数(除了 inline 函数)上挂载 probe 函数。当 kprobe 函数注册的时候,其实就是把目标函数地址上内核代码的指令码,替换成了“cc”,也就是 int3 指令。这样一来,当内核代码执行到这条指令的时候,就会触发一个异常而进入到 Linux int3 异常处理函数 do_int3() 里。在 do_int3() 这个函数里,如果发现有对应的 kprobe 注册了 probe,就会依次执行注册的 pre_handler();原来的指令;最后是 post_handler()。理论上 kprobe 其实只要知道内核代码中任意一条指令的地址,就可以为这个地址注册 probe 函数。简单说 kprobe 把目标指令替换,替换的指令可以使程序跑到一个特定的 handler 里,去执行 probe 的函数。
分析实践
Perf – Linux下的系统性能调优工具,第 1 部分 值得再细读一遍,尤其是如何从linxu及硬件 视角优化性能。
当算法已经优化,代码不断精简,人们调到最后,便需要斤斤计较了。cache 啊,流水线啊一类平时不大注意的东西也必须精打细算了。
干货携程容器偶发性超时问题案例分析(一)干货携程容器偶发性超时问题案例分析(二) 这两篇文章中,使用perf sched 发现了物理上存在的调度延迟问题。
容器网络一直在颤抖,罪魁祸首竟然是 ipvs 定时器通过 perf top 命令可以查看 哪些函数占用了最多的cpu 时间
干货携程容器偶发性超时问题案例分析(一)干货携程容器偶发性超时问题案例分析(二)两篇文章除了膜拜之外,最大的体会就是:业务、docker daemon、网关、linux内核、硬件 都可能会出问题,都得有手段去支持自己做排除法
排查思路
- 通过 perf 发现了一个内核函数的调用频率比较高
- 通过 ftrace(function tracer) 工具继续深入,对上大概知道这个函数是在什么情况下被调用到的,对下看到函数里所有子函数的调用以及时间。PS:就好比,看到某个项目 超时比较多,要么是自己代码不行,要么qps 高,那么下一步就是分析 上游谁调的最多。
日志
linux内核输出的日志去哪里了在内核编码时,如果想要输出一些信息,通常并不会直接使用printk,而是会使用其衍生函数,比如 pr_err / pr_info / pr_debug 等,这些衍生函数附带了日志级别、所属模块等其他信息,比较友好,但其最终还是调用了printk。printk函数会将每次输出的日志,放到内核为其专门分配的名为ring buffer的一个槽位里。ring buffer其实就是一个用数组实现的环形队列,不过既然是环形队列,就会有一个问题,即当ring buffer满了的时候,下一条新的日志,会覆盖最开始的旧的日志。ring buffer的大小,可以通过内核参数来修改。
dmesg命令,在默认情况下,是通过读取/dev/kmsg文件,来实现查看内核日志的。当该命令运行时,dmesg会先调用open函数,打开/dev/kmsg文件,该打开操作在内核中的逻辑,会为dmesg分配一个file实例,在这个file实例里,会有一个seq变量,该变量记录着下一条要读取的内核日志在ring buffer中的位置。刚打开/dev/kmsg文件时,这个seq指向的就是ring buffer中最开始的那条日志。之后,dmesg会以打开的/dev/kmsg文件为媒介,不断的调用read函数,从内核中读取日志消息,每读取出一条,seq的值都会加一,即指向下一条日志的位置,依次往复,直到所有的内核日志读取完毕,dmesg退出。