简介
Calico是一个纯3层的数据中心网络方案(也就是局域网网络方案),能够提供可控的VM、容器、裸机之间的IP通信。calico 容器在主机内外都通过 路由规则连通(主机内不会创建网桥设备);flannel host-gw 主机外靠路由连通,主机内靠网桥连通。
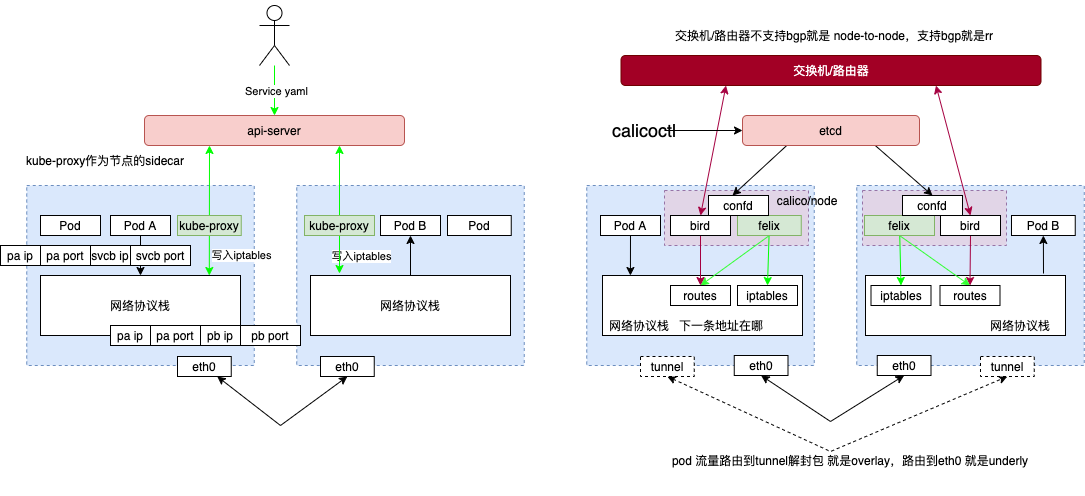
Kubernetes网络之Calico为何流行?Calico在每个计算节点都利用Linux Kernel实现了一个高效的虚拟路由器vRouter来负责数据转发。每个 vRouter 都通过BGP协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。Calico保证所有容器之间的数据流量都是通过IP路由的方式完成互联互通的。Calico节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
Kubernetes学习笔记之Calico CNI Plugin源码解析(一)未读
Kubernetes学习笔记之Calico CNI Plugin源码解析(二)
calico 文档与安装
GitHub projectcalico/calico
- 官网有对应各个平台的安装文档
- calico 版本不同,安装细节也有所不同。
- calico 从v3.0后 不再支持 mesos
- calico 一开始是python开发,逐步转为go
- calico 基础服务的启动方式演化
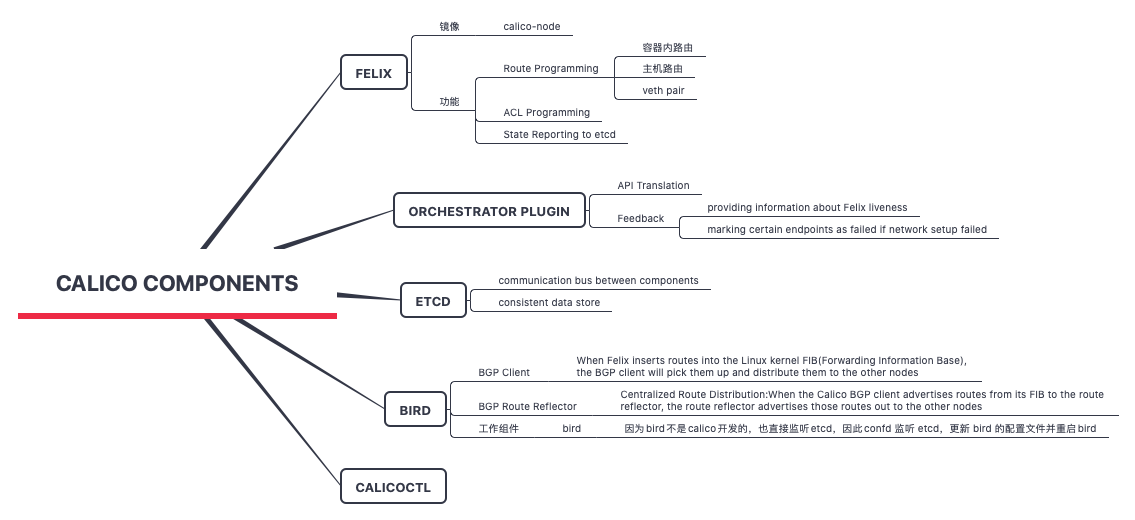
- calico 由felix(calico agent)、bgp client、bgp route reflector等组成,这些组件是下载二进制分别安装的
- 新版Calico服务是作为容器来运行的
calico下载 文件夹解压后的文件列表
release-v3.10.0
├── README
├── bin # 不同os 版本的可执行文件
│ ├── calicoctl
│ ├── calicoctl-darwin-amd64
│ └── calicoctl-windows-amd64.exe
├── images
│ ├── calico-cni.tar
│ ├── calico-kube-controllers.tar
│ ├── calico-node.tar ## 容器运行时为host网络
│ └── calico-typha.tar
└── k8s-manifests
├── alp
│ ├── istio-app-layer-policy.yaml
│ ├── istio-inject-configmap-1.1.6.yaml
│ └── istio-inject-configmap-1.1.7.yaml
├── calico-etcd.yaml
├── calico-policy-only.yaml
├── calico-typha.yaml
├── calico.yaml
├── calicoctl-etcd.yaml
├── calicoctl.yaml
├── canal-etcd.yaml
├── canal.yaml
├── crds.yaml
├── flannel-migration
│ ├── calico.yaml
│ └── migration-job.yaml
└── rbac
├── rbac-etcd-calico.yaml
├── rbac-etcd-flannel.yaml
├── rbac-kdd-calico.yaml
└── rbac-kdd-flannel.yaml
github 资源
projectcalico/calico
projectcalico/calicoctl
projectcalico/felix ## 维护路由规则,容器主机内外的连通全靠路由规则
projectcalico/cni-plugin # 创建route和虚拟网卡virtual interface,以及veth pair等网络资源,并且会把相关数据写入calico datastore数据库里
projectcalico/node ## 路由守护程序,同步分发路由信息
calico 各个组件之间 通过etcd 相互通信,包括calicoctl
网络模式
Overlay模式/IPIP 或vxlan 模式
Kubernetes网络之Calico为何流行?BGP是互联网上一个核心的去中心化自治路由协议,它通过维护IP路由表或“前缀”表来实现自治系统AS之间的可达性,属于矢量路由协议。不过,考虑到并非所有的网络都能支持BGP,以及Calico控制平面的设计要求物理网络必须是二层网络,以确保 vRouter间均直接可达,路由不能够将物理设备当作下一跳等原因,为了支持三层网络,Calico还推出了IP-in-IP叠加的模型,它也使用Overlay的方式来传输数据。IPIP的包头非常小,而且也是内置在内核中,因此理论上它的速度要比VxLAN快一点 ,但安全性更差。Calico 3.x的默认配置使用的是IPIP类型的传输方案而非BGP。
把 IP 层封装到 IP 层的一个 tunnel。作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
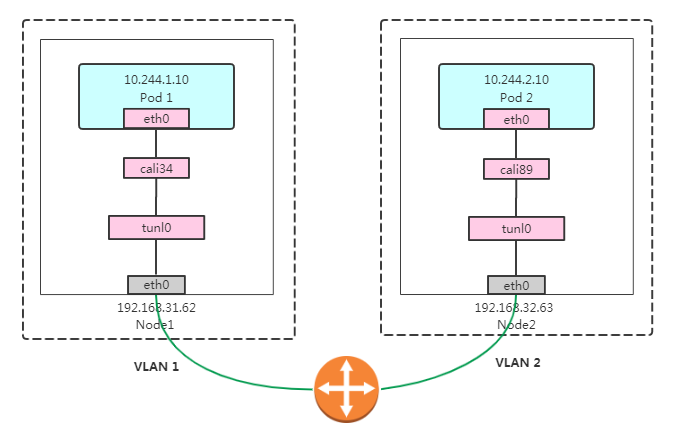
Pod 1访问Pod 2大致流程如下:
- 数据包从容器1出到达Veth Pair另一端(宿主机上,以cali前缀开头);
- 进入IP隧道设备(tunl0),由Linux内核IPIP驱动封装在宿主机网络的IP包中(新的IP包目的地之是原IP包的下一跳地址,即192.168.31.63),这样,就成了Node1到Node2的数据包;
- 数据包经过路由器三层转发到Node2;
- Node2收到数据包后,网络协议栈会使用IPIP驱动进行解包,从中拿到原始IP包;
- 然后根据路由规则,根据路由规则将数据包转发给cali设备,从而到达容器2。
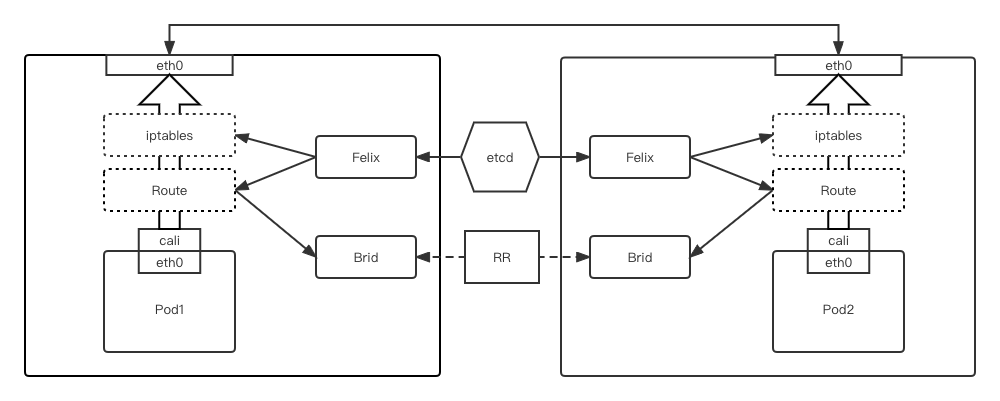
Underlay模式/BGP 模式
Calico在小规模集群中可以直接互联,在大规模集群中可以通过额外的BGP route reflector来完成。
按部署模式分
- node-to-node mesh。每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。
- BGP Speaker RR模式。RR模式 中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式。
原理
Designed to simplify, scale and secure cloud networks by
- Layer 3 based routing approach
- BGP for Routes distribution
- Policy driven network security implemented by iptable rules
underlay/BGP 模式下 的Speaker RR模式
通过将整个互联网的可扩展 IP 网络原则压缩到数据中心级别。Calico 在每一个计算节点利用 Linux kernel 实现了一个高效的 vRouter 来负责数据转发 而每个 vRouter 通过 BGP 协议负责把自己上运行的 workload 的路由信息像整个 Calico 网络内传播 - 小规模部署可以直接互联,大规模下可通过指定的 BGP route reflector 来完成。
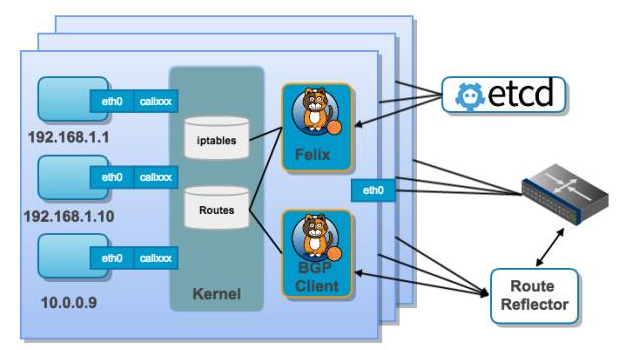
通过将整个互联网的可扩展 IP 网络原则压缩到数据中心级别。即将构建物理网络的设备、协议等 应用到数据中心网络
Calico 不使用隧道或 NAT 来实现转发,而是巧妙的把所有二三层流量转换成三层流量,并通过 host 上路由配置完成跨 Host 转发。PS:数据包的通信是利用linux 现有机制, calico的各个组件 通过操作linux 路由表、iptables等来控制数据包的流向,本身不接触数据包。换句话说,某个时刻停掉calico组件,只要路由表记录还在,便不影响容器通信。
根据AS 的不同划分方式(共用一个AS/每个机架交换机一个AS/一个node一个AS,AS 内 ibgp,AS间 ebgp,ibgp 和 ebgp 的speake 路由通告规则不同),有多种组网模型,都可以实现分发路由的效果,只是适应的网络规模、架构等有所不同IP Interconnect Fabrics in Calico
Network Policy
Network Policy。当k8s想控制 namespace 之间是否可以 互通时,便要求网络组件能够根据 k8s 的指令做出反应。k8s 介入了网路,便有了和网络组件的沟通规范,就像docker和网络组件的接口一样。 正像calico github 上介绍的一样 Calico is an open source system enabling cloud native application connectivity and policy ,calico 除了支持 connectivity,还支持policy。
calico根据 profile/policy 生成对等的iptables rule, allow 或者 drop 流量,参见Calico网络的原理、组网方式与使用
报文流程
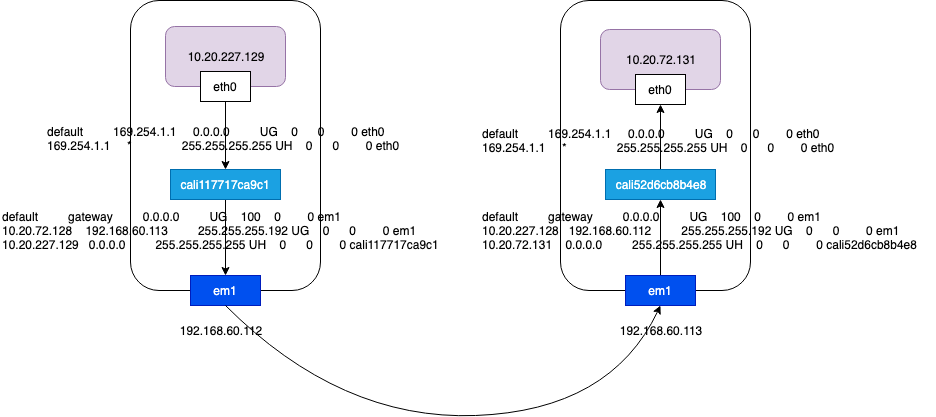
容器到主机
当一个数据包的目的地址不是本机时,就会查询路由表,从路由表中查到网关后,它首先会通过 ARP 获得网关的 MAC 地址,然后在发出的网络数据包中将目标 MAC 改为网关的 MAC,而网关的 IP 地址不会出现在任何网络包头中。
default 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 * 255.255.255.255 UH 0 0 0 eth0
从路由表可以知道 169.254.1.1 是容器的默认网关,169.254.1.1 是预留的本地 IP 网段,容器会查询168.254.1.1 的 MAC 地址,这个 ARP 请求发到哪里了呢? eth0 是 veth pair 的一端,其对端是主机上 caliXXXX 命名的 interface,caliXXXX 没有ip只有一个无用的ee:ee:ee:ee:ee:ee,容器和主机所在网络不存在 169.254.1.1,容器想获取网关169.254.1.1的mac地址却找不到169.254.1.1,怎么办? 实际上 Calico 利用了网卡的代理 ARP 功能。
root$192.168.60.112:/# ip neigh
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:ee:ee STALE
192.168.60.112 dev eth0 lladdr ee:ee:ee:ee:ee:ee STALE
代理 ARP 是 ARP 协议的一个变种,当 ARP 请求目标跨网段时,网关设备收到此 ARP 请求,会用自己的 MAC 地址返回给请求者(PS:毕竟目标ip跨了网段,把目标ip的mac返回给主机也没用,查询某个网卡是否开始arp proxycat /proc/sys/net/ipv4/conf/califxx/proxy_arp)。
-
在容器内,Calico 通过一个巧妙的方法将 workload 的所有流量引导到一个特殊的网关 169.254.1.1,从而引流到主机的 calixxx 网络设备上,最终将二三层流量全部转换成三层流量来转发。
主机侧veth收到的数据包 源mac 目的mac 源ip 目的ip 差异 macvlan 容器 二层广播获取到目的容器的mac 容器 目的容器 数据包无论mac/ip都不是发给主机的 calico 容器 calixx/ ee:ee:ee:ee:ee:ee容器 目的容器 数据包mac是发给主机的,根据ip做三层路由 flannel 容器 flannel直接设置的目的mac 容器 目的容器 -
在主机上通过开启代理 ARP 功能来实现 ARP 应答,使得 ARP 广播被抑制在主机上,抑制了广播风暴,也不会有 ARP 表膨胀的问题。
主机到目的主机
容器的后续报文 IP 地址还是目的容器,但是 MAC 地址就变成了主机上对应caliXXXX的地址,也就是说所有的报文都会发给主机,然后主机根据路由表进行转发。caliXXXX 接收到报文后,报文的目的ip地址 10.20.72.131 匹配的是第二项(路由规则匹配的是一个网段),把 192.168.60.113 作为下一跳地址,并通过 em1 发出去。
root$192.168.60.112:/# route
default gateway 0.0.0.0 UG 100 0 0 em1
10.20.72.128 192.168.60.113 255.255.255.192 UG 0 0 0 em1
10.20.227.129 0.0.0.0 255.255.255.255 UH 0 0 0 cali117717ca9c1
PS: 在物理网络中,下一跳一般是路由器(数据包在路由器直接传递),在calico 网络下,物理机作为vrouter,物理机ip 自然也作为下一跳地址。
目的主机到容器
报文到达容器所在的主机 192.168.60.113 ,报文会匹配最后一个路由规则,这个规则匹配的是一个 IP 地址,而不是网段,也就是说主机上每个容器都会有一个对应的路由表项。报文发送到 cali52d6cb8b4e8 这个 veth pair,然后从另一端发送给容器,容器接收到报文之后,发送目的地址是自己,就做出应答,应答报文的返回路径和之前类似。
root$192.168.60.113:/# route
default gateway 0.0.0.0 UG 100 0 0 em1
10.20.227.128 192.168.60.112 255.255.255.192 UG 0 0 0 em1
10.20.72.131 0.0.0.0 255.255.255.255 UH 0 0 0 cali52d6cb8b4e8
默认情况下,当网络中出现第一个容器时,calico 会为容器所在的节点分配一段子网(子网掩码为 /26,比如192.168.196.128/26),后续出现在该节点上的容器都从这个子网中分配 IP 地址。这样做的好处是能够缩减节点上的路由表的规模,按照这种方式节点上 2^6 = 64 个 IP 地址只需要一个路由表项就行,而不是为每个 IP 单独创建一个路由表项。节点上创建的子网段可以在etcd 中 /calico/ipam/v2/host/<node_name>/ipv4/block/ 看到。calico 还允许创建容器的时候指定 IP 地址,如果用户指定的 IP 地址不在节点分配的子网段中,calico 会专门为该地址添加一个 /32 的网段。
使用
calicoctl 使用
本节有calicoctl 1.6.3 为准
- The calicoctl command line interface provides a number of resource management commands to allow you to create, modify, delete, and view the different Calico resources.
-
calicoctl 的command 分为三个部分:
- Resource的增删改查,包括create、replace、apply、delete、get
- node,start and check calico/node container.
- config
- ipam, ip 地址管理,只有两个command: release、show。release 用来手动释放一个已分配的ip
问题来了, calico 中的resource 说的啥东东?Resource Definitions
- bgp peer
- host endpoint
- ip pool
- node,quay.io/calico/node 容器启动时自动创建
- policy,
- profile, Calico uses an identically(同一的) named profile to represent each Docker network.calico 的每个网络都有一个同名的 profile,profile 中定义了该网络的 policy。 profile 的两个关键配置 ingress egress,即描述了哪些流量可以进来,哪些流量可以出去。
- workload endpoint
profile 和 policy 换一种方式描述 iptables的意思(实际效果仍然是iptables 实现,并且都采用了rule 的方式),描述了规则(主要是 ingress 和 egress)以及 应用规则的 endpoint。两者的区别是:
- profile与network 同名,profile的 ingress 和 egress 自动应用到 network 中的 所有endpoint上。 policy的 ingress 和 egress 应用到 符合 selector所定义的规则的 endpoint 上。
- profile 自动创建,policy 手动创建
- profile 算是一种 特殊的 policy
The calicoctl commands for resource management (create, apply, delete, replace, get) all take resource manifests as input. 有点类似k8s,kubectl 操作的时候指定的是 json/yaml
apiVersion: v1
kind: <type of resource>
metadata:
# Identifying information
name: <name of resource>
...
spec:
# Specification of the resource
...
By default, Calico blocks all traffic unless it has been explicitly allowed through configuration of the globally defined policy which uses selectors to determine which subset of the policy is applied to each container based on their labels. (calico 默认会阻止所有流量,除非明确允许)
排查——node status 有问题
containerA跨主机ping hostB上的containerB,不通,检查步骤
- tcpdump(
tcpdump -nn -i 网卡名 -e) 判断 hostA 网卡是否收到包 - 检查 hostA 路由规则
- tcpdump 判断 hostB 网卡是否收到包
- 检查 hostA 路由规则
已知原因:
calicoctl node status 某个节点 状态 不是up
IPv4 BGP status
+---------------+-------------------+-------+----------+--------------------------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+--------------------------------+
| 192.168.60.42 | node-to-node mesh | start | 06:03:39 | Active Socket: Connection |
| | | | | refused |
| 192.168.60.83 | node-to-node mesh | wait | 06:03:40 | Established |
+---------------+-------------------+-------+----------+--------------------------------+
其它
容器网络插件 Calico 与 Contiv Netplugin深入比较
谐云Calico大规模场景落地实践 未读完,措辞要仔细研究
calico 为什么使用BGP?
一个网络凭空多了许多vRouter,需要与其它vRouter 通过bgp 同步信息
Why BGP? In the Calico design, this would equate to tens of thousands of routers, and potentially millions of routes or end points. These numbers are not consistent with using an IGP, but do fit in the envelope for BGP, especially when we use route reflection to improve the router scaling number. calico 假设 网络中有上万个 routers,这个量级下IGP 效率不行。
Each endpoint(也就是容器的cali0) can only communicate through its local vRouter(容器所在host), and the first and last hop in any Calico packet flow is an IP router hop through a vRouter(也就是cali0 只跟 host 交互). Each vRouter announces all of the endpoints it is attached to to all the other vRouters and other routers on the infrastructure fabric, using BGP, usually with BGP route reflectors to increase scale. (vRouter 或运行 route reflectors服务的 route彼此会交流 路由信息)
calicoctl node status 列出当前node 可以沟通路由规则的peer。
Dive into Calico - IP Interconnect Fabrics
数据中心 calico bgp路由同步策略 Basic Calico architecture overview
ippool 分配细节
calico网络策略默认情况下,当网络中出现第一个容器,calico会为容器分配一段子网(子网掩码/26,例如:172.0.118.0/26),后续出现该节点上的pod都从这个子网中分配ip地址,这样做的好处是能够缩减节点上的路由表的规模,按照这种方式节点上2^6=64个ip地址只需要一个路由表项就行了,而不是为每个ip单独创建一个路由表项。如下为etcd中看到的子网段的值:
注意:当64个主机位都用完之后,会从其他可用的的子网段中取值,所以并不是强制该节点只能运行64个pod ,只是增加了路由表项