简介
虚拟化技术的发展
- 主机虚拟化,一台物理机可以被划分为若干个小的机器,每个机器的硬件互不共享,各自安装操作系统
- 硬件虚拟化,同一个物理机上隔离多个操作系统实例
- 操作系统虚拟化,由操作系统创建虚拟的系统环境,使应用感知不到其他应用的存在
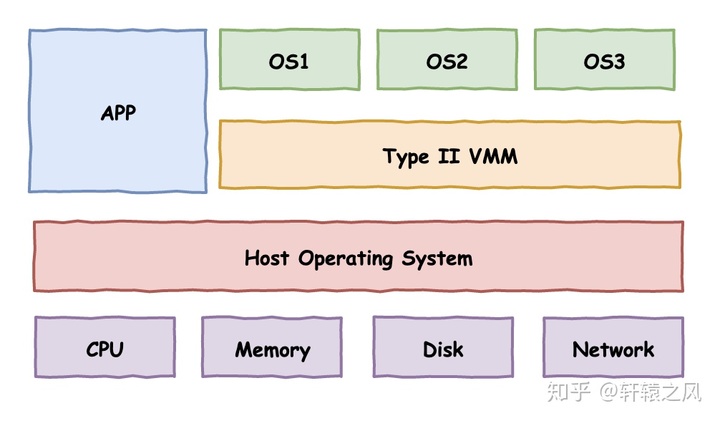
在数据中心里面用的虚拟机,我们通常叫作 Type-1 型的虚拟机,客户机的指令交给虚拟机监视器之后,可以直接由虚拟机监视器去调用硬件,指令不需要做什么翻译工作,可以直接往下传递执行就好了。因为虚拟机监视器需要直接和硬件打交道,所以它也需要包含能够直接操作硬件的驱动程序。所以 Type-1 的虚拟机监视器更大一些,同时兼容性也不能像 Type-2 型那么好。不过,因为它一般都是部署在我们的数据中心里面,硬件完全是统一可控的,这倒不是一个问题了。
在 Type-2 虚拟机里,我们上面说的虚拟机监视器好像一个运行在操作系统上的软件。你的客户机的操作系统呢,把最终到硬件的所有指令,都发送给虚拟机监视器。而虚拟机监视器,又会把这些指令再交给宿主机的操作系统去执行。
cpu 虚拟化
KVM 的「基于内核的虚拟机」是什么意思?早期比较常见的虚拟化解决方案,它的工作原理很简单:把CPU的所有寄存器都写在一组变量中(这组变量我们称为CPUFile),然后用一片内存当作被模拟CPU的内存(这片内存这里称为vMEM),然后在用一些数据结构表示IO设备的状态(这里称为vIO),三者的数据结构综合在一起,就是代表一个虚拟化的环境了(这里称之为VM),之后按顺序读出一条条的指令,根据这个指令的语义,更改VM的数据结构的状态(如果模拟了硬件,还要模拟硬件的行为,比如发现显存被写了一个值,可以在虚拟屏幕上显示一个点等),这样,实施虚拟的那个程序就相当于给被虚拟的程序模拟了一台计算机,这种技术,我称它为“解释型虚拟化技术”。指令是被一条一条解释执行的。随着技术的发展,有人就开始取巧了:很多时候,我们仅仅是在x86上模拟x86,这些指令何必要一条条解释执行?我们可以用CPU直接执行这些指令啊,执行到特权指令的时候,我们直接异常,然后在异常中把当前CPU的状态保存到CPUFile中,然后再解释执行这个特权指令,这样不是省去了很多”解释“的时间了?
KVM 介绍(二):CPU 和内存虚拟化 - Avaten的文章 - 知乎因为宿主操作系统是工作在 ring0 的,客户操作系统就不能也在ring0 了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,但是没有执行权限是会出错的。所以这时候虚拟机管理程序(VMM)需要避免这件事情发生。虚机怎么通过 VMM 实现 Guest CPU 对硬件的访问,根据其原理不同有三种实现技术:
- 基于二进制翻译的全虚拟化。客户操作系统运行在 Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
- 半虚拟化/操作系统辅助虚拟化。修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯,hypervisor 同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
- 硬件辅助的全虚拟化。2005年后,CPU厂商Intel 和 AMD 开始支持虚拟化了,这种 CPU,有 VMX root operation 和 VMX non-root operation两种模式,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下。因为 CPU 中的虚拟化功能的支持,并不存在虚拟的 CPU,KVM Guest 代码是运行在物理 CPU 之上。对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码 ==> 运行某些指令或遇到某些事件时 ==> 硬件自动挂起 Guest OS ==> 切换到 VMX root operation 模式 ,恢复VMM 的运行 (而不是cpu 直接报错) ==> VMM 将操作转到 guest os 对应的内存、设备驱动等。
总结一下:cpu 虚拟化的核心难点是特权指令,对于特权指令,guest os 要么改自己不执行特权指令,要么VMM 为cpu 报错擦屁股,要么cpu 不报错。
KVM + QEMU
KVM(Kernel-based Virtual Machine)利用修改的QEMU提供BIOS、显卡、网络、磁盘控制器等的仿真,但对于I/O设备(主要指网卡和磁盘控制器)来说,则必然带来性能低下的问题。因此,KVM也引入了半虚拟化的设备驱动,通过虚拟机操作系统中的虚拟驱动与主机Linux内核中的物理驱动相配合,提供近似原生设备的性能。从此可以看出,KVM支持的物理设备也即是Linux所支持的物理设备。
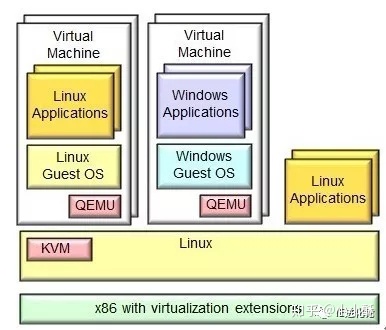
为了简化代码,KVM 在 QEMU 的基础上做了修改。VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。遇到虚机进行 I/O 操作,KVM 会从上次的系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。从 QEMU 的角度看,也可以说是 QEMU 使用了 KVM 模块的虚拟化功能,为自己的虚机提供了硬件虚拟化加速。除此以外,虚机的配置和创建、虚机运行说依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
guest os 与 物理机cpu 之间vmm 如何发挥作用的,还没找到直观感觉(未完成)。vm 是一个进程,vCpu 是其中的一个线程,由VMM 管理,这个味道咋跟docker 这么一样呢?
KVM原理简介 写的更好一些。KVM是作为一个内核模块出现的,所以它还得借助用户空间的程序QEMU 来和用户进行交互。QEMU是一套由法布里斯·贝拉(Fabrice Bellard)所编写的以GPL许可证分发源码的模拟处理器,在GNU/Linux平台上使用广泛。其本身是一个纯软件的支持CPU虚拟化、内存虚拟化及I/O虚拟化等功能的用户空间程序。借助KVM提供的虚拟化支持可以将CPU、内存等虚拟化工作交由KVM处理,自己则处理大多数I/O虚拟化的功能,可以实现极高的虚拟化效率。
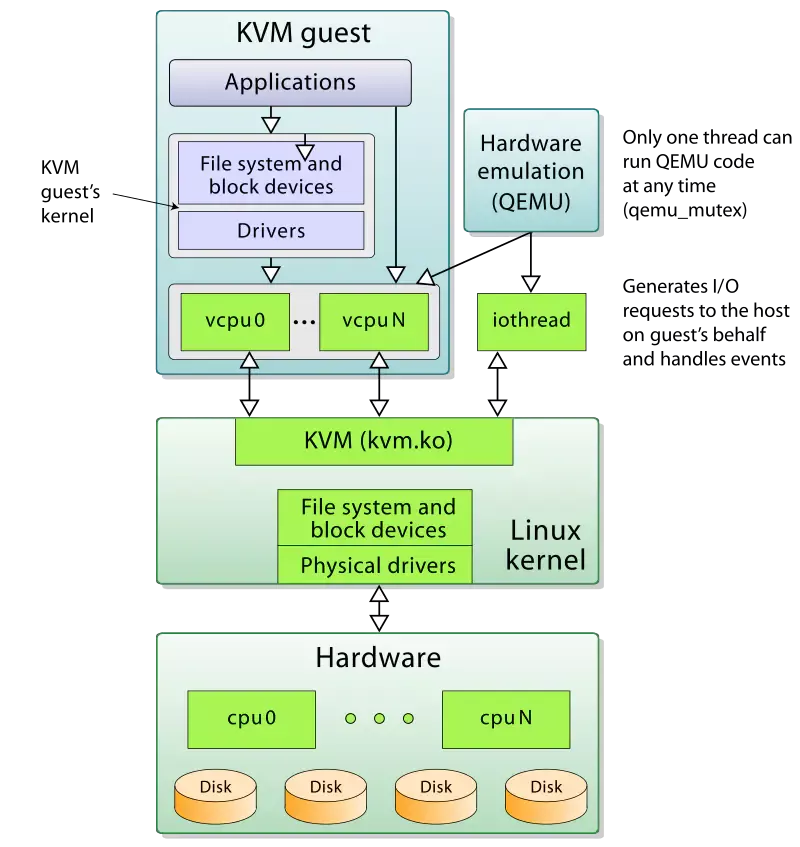
- 正常我们在执行WFI指令时会使CPU进入一个低功耗的状态,但是对于HOST OS来说,如果让CPU真正进入低功耗状态,显然会影响其他VM的运行。如果我们配置了HCR_EL2.TWI==1时,那么Guest OS在执行WFI时就会触发EL2的异常,然后陷入(PS: 感觉跟异常调用一样)Hypervisor,那么此时Hypervisor就可以将对应VCPU所处的线程调出出去,将CPU让给其他的VCPU线程使用。PS: Hypervisor 感觉就是提供了 系统调用处理这个场景
- 内存虚拟化的目的是给虚拟客户机操作系统提供一个从0开始的连续的地址空间,同时在多个客户机之间实现隔离与调度。arm主要通过Stage 2转换来提供对内存虚拟化的支持,其允许Hypervisor控制虚拟机的内存视图,而在这之前则是使用及其复杂的影子页表技术来实现。Stage 2转换可以控制虚拟机是否可以访问特定的某一块物理内存,以及该内存块出现在虚拟机内存空间的位置。这种能力对于虚拟机的隔离和沙箱功能来说至关重要。这使得虚拟机只能看到分配给它自己的物理内存。为了支持Stage 2 转换, 需要增加一个页表,我们称之为Stage 2页表。操作系统控制的页表转换称之为stage 1转换,负责将虚拟机视角的虚拟地址转换为虚拟机视角的物理地址。而stage 2页表由Hypervisor控制,负责将虚拟机视角的物理地址转换为真实的物理地址。虚拟机视角的物理地址在Armv8中有特定的词描述,叫中间物理地址(intermediate Physical Address, IPA)。
- I/O虚拟化,有四种方案:设备模拟,比如qemu 模拟具体的I/O设备的特性;前后端驱动接口;设备直接分配,将一个物理设备直接分配给Guest OS使用;设备共享分配,其主要就是让一个物理设备可以支持多个虚拟机功能接口,将不同的接口地址独立分配给不同的Guest OS使用。如SR-IOV协议。
命令行方式创建一个传统虚拟机
qemu 创建传统虚拟机流程(virtualbox是一个图形化的壳儿)
# 创建一个虚拟机镜像,大小为 8G,其中 qcow2 格式为动态分配,raw 格式为固定大小
qemu-img create -f qcow2 ubuntutest.img 8G
# 创建虚拟机(可能与下面的启动虚拟机操作重复)
qemu-system-x86_64 -enable-kvm -name ubuntutest -m 2048 -hda ubuntutest.img -cdrom ubuntu-14.04-server-amd64.iso -boot d -vnc :19
# 在 Host 机器上创建 bridge br0
brctl addbr br0
# 将 br0 设为 up
ip link set br0 up
# 创建 tap device
tunctl -b
# 将 tap0 设为 up
ip link set tap0 up
# 将 tap0 加入到 br0 上
brctl addif br0 tap0
# 启动虚拟机, 虚拟机连接 tap0、tap0 连接 br0
qemu-system-x86_64 -enable-kvm -name ubuntutest -m 2048 -hda ubuntutest.qcow2 -vnc :19 -net nic,model=virtio -nettap,ifname=tap0,script=no,downscript=no
# ifconfig br0 192.168.57.1/24
ifconfig br0 192.168.57.1/24
# VNC 连上虚拟机,给网卡设置地址,重启虚拟机,可 ping 通 br0
# 要想访问外网,在 Host 上设置 NAT,并且 enable ip forwarding,可以 ping 通外网网关。
# sysctl -p
net.ipv4.ip_forward = 1
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# 如果 DNS 没配错,可以进行 apt-get update
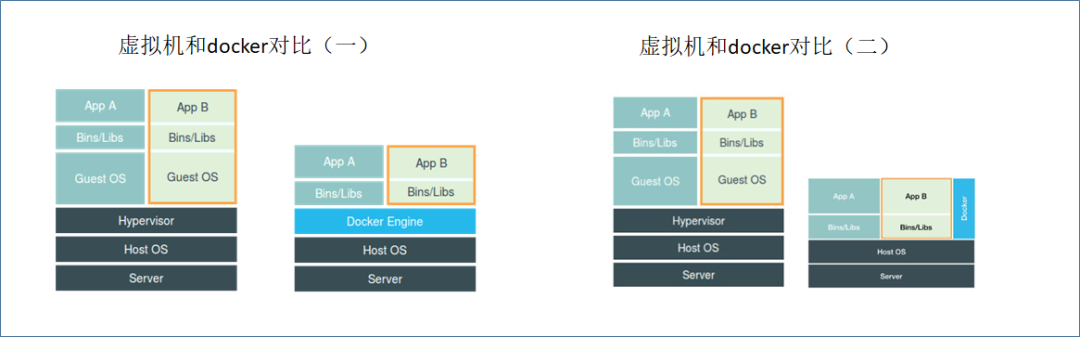
可以看到至少在网络配置这个部分,传统虚拟机跟容器区别并不大
其它
QEMU尽管非常的强大,但也正是应为它的强大导致其对初学者非常的不友好。这里推荐大家刚开始学习KVM时可以先学习kvm tool,这是一个基于C语言开发的KVM虚拟化工具,其代码非常精简易懂,同时也可以支持完整的linux虚拟化,非常适合初学者入门使用。其项目地址为https://github.com/kvmtool/kvmtool。
- 神龙架构从CPU手头接过虚拟化的重任,一路带飞存储、网络、安全等关键性能。
- 到今天为止,最适合做DPU的还是可编程可升级的FPGA。 从 VMWare 到阿里神龙,虚拟化技术 40 年演进史