简介
专门有一本书叫《高性能计算之并行编程技术—— MPI并行程序设计》
一个接口规范
在 90 年代之前,程序员可没我们这么幸运。对于不同的计算架构写并发程序是一件困难而且冗长的事情。当时,很多软件库可以帮助写并发程序,但是没有一个大家都接受的标准来做这个事情。由于当时很多软件库都用到了这个消息传递模型,但是在定义上有些微小的差异,这些库的作者以及一些其他人为了解决这个问题就在 Supercomputing 1992 大会上定义了一个消息传递接口的标准- 也就是 MPI。到 1994 年的时候,一个完整的接口标准定义好了(MPI-1)。
一切靠自己的MPI框架MPI是一个跨语言的通讯协议,支持高效方便的点对点、广播和组播。它提供了应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。从概念上讲,MPI应该属于OSI参考模型的第五层或者更高,他的实现可能通过传输层的sockets和Transmission Control Protocol (TCP)覆盖大部分的层。大部分的MPI实现由一些指定的编程接口(API)组成,可由C, C++,Fortran,或者有此类库的语言比如C#, Java或者Python直接调用。MPI优于老式信息传递库是因为他的可移植性和速度。MPI标准也不断演化。主要的MPI-1模型不包括共享内存概念,MPI-2只有有限的分布共享内存概念。但是MPI程序经常在共享内存的机器上运行。MPI有很多参考实现,例如mpich或者openmpi。
Massage Passing Interface 是消息传递函数库的标准规范,由MPI论坛开发。
- 一种新的库描述,不是一种语言。共有上百个函数调用接口,MPI 提供库函数/过程供 C/C++/FORTRAN 调用。
- MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现
- MPI是一种消息传递编程模型,最终目的是服务于进程间通信这一目标 。
// 端到端通信
int MPI_Send(const void *buf, int count, MPI_Datatype datatype, int dest,int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype,int source, int tag, MPI_Comm comm, MPI_Status *status)
// 集合通信
// Broadcasts a message from the process with rank root to all other processes of the group.
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype,int root, MPI_Comm comm)
// Gathers values from a group of processes.
int MPI_Gather(const void *sendbuf, int sendcount, MPI_Datatype sendtype,void *recvbuf, int recvcount, MPI_Datatype recvtype, int root,MPI_Comm comm)
// Sends data from one task to all tasks in a group.
int MPI_Scatter(const void *sendbuf, int sendcount, MPI_Datatype sendtype,void *recvbuf, int recvcount, MPI_Datatype recvtype, int root,MPI_Comm comm)
...
高级特性
- 聚合通信(MPI_Reduce/MPI_Allreduce等)的编程模式:每个程序独立完成一定的计算工作,到达交汇点,同时调用聚合通信原语(primitive)完成数据交换,然后根据结果进行后续计算。
- 某些场景下,多个进程需要协调同步进入某个过程。MPI提供了同步原语例如MPI_Barrier。所有进程调用MPI_Barrier,阻塞程序直到所有进程都开始执行这个接口,然后返回。由此可见它的作用就是让所有进程确保MPI_Barrier之前的工作都已完成,同步进入下一个阶段。
MPI程序如何运行?
程序可以分为计算块和通信块。每个程序可以独立完成计算块,计算完成后进行交互,即通信或者同步。交互完成后进入下一个阶段的计算。直到所有任务完成,程序退出。
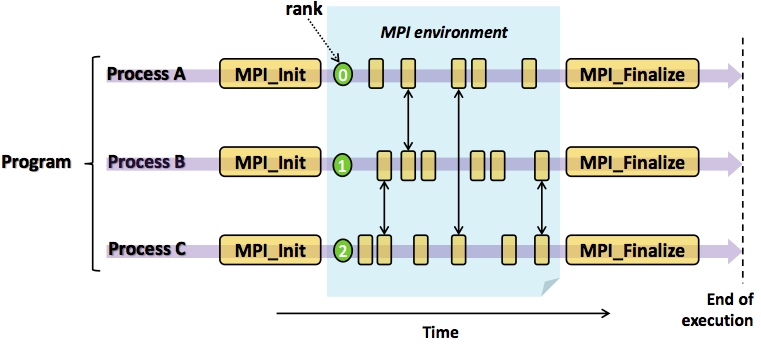
MPI框架只是提供了通信机制,即任务之间同步和通信的手段。计算任务怎么分解,数据怎么划分,计算怎么实现,任务怎么合并等等问题都由程序开发者自己决定。MPI框架在程序启动的时候,为每个程序副本分配了唯一的序号(rank)。通常程序可以通过获取rank确定自己是谁,根据rank决定谁该做什么工作,进程间显性地通过指定rank来进行通信。
周边
- 虽然MPI标准主要关注通信和进程间交互,但是资源管理和进程调度问题是任何一个分布式计算的框架必须解决的问题。进程管理接口PMI (Process Management Interface)定义了MPI程序与运行时环境的交互接口,尝试解决资源管理问题。PMI有很多具体实现,典型的例子是Hydra进程管理器,它是PMI-1标准的具体实现。
- 所有的分布式系统都需要容错。那么MPI程序如何容错呢?不同的框架实现提供了不同程度的容错支持。主要的方式是快照(checkpoint)和程序重启机制。例如Hydra框架基于Berkerly的BLCR快照和重启库(checkpoing and restart)实现MPI程序的快照功能。例如用户通过下述方式启动程序,指定快照机制和快照数据目录:
mpiexec -ckpointlib blcr -ckpoint-prefix /home/buntinas/ckpts/app.ckpoint -f hosts -n 4 ./app - 某些场景下, MPI程序需要访问和共享分布式文件系统完成计算。MPI标准的MPI-IO部分定义了文件共享和访问接口,实现聚集IO(Collective IO),某些应用模式中提供了相比POSIX接口更好的性能。
示例
#include <stdio.h>
#include <mpi.h>
#define BUFMAX 81
int main(int argc, char *argv[]){
char outbuf[BUFMAX], inbuf[BUFMAX];
int rank, size;
MPI_Status status;
// 初始化MPI
MPI_Init(&argc, &argv);
// 获取当前进程的进程号 并存入rank变量中
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 获取进程的数量,并存入size变量中
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 在该程序中,进程号不为0的进程,只负责发数据给进程0。
// 进程号不为0的处理逻辑。
if (rank != 0) {
// 创建要发送的数据
sprintf(greeting, "Greetings from process %d of %d!",rank, size);
//发送数据给进程0
MPI_Send(greeting, strlen(greeting)+1, MPI_CHAR, 0, 0,MPI_COMM_WORLD);
} else { // 进程号为0的处理逻辑
// 打印进程0的数据
printf("Hello! Greetings from process %d of %d!\n", rank, size);
// 循环接收其它进程发送的数据,并打印。
for (int q = 1; q < comm_sz; q++) {
// 接收其它进程的数据
MPI_Recv(greeting, MAX_STRING, MPI_CHAR, q,0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// 打印
printf("%s\n", greeting);
}
}
// 关闭MPI
MPI_Finalize();
return 0;
}
容器时代的MPI
在 Kubernetes 上常见的是 kubeflow 社区的 tf-operator 支持 Tensorflow PS 模式,或者 mpi-operator 支持 horovod 的 mpi allreduce 模式。kubeflow/mpi-operator The MPI Operator makes it easy to run allreduce-style distributed training on Kubernetes.
深度学习分布式训练框架 horovod (19) — kubeflow MPI-operator
主要分两种角色。
- Worker 本质上是 StatefulSet,在分布式训练的过程中,训练任务通常是有状态的,StatefulSet 正是管理这些的 Workload 的对象。
- Launcher 相当于一个启动器的角色,它会等Worker都就位之后,去启动MPI的任务。通常会是一个比较轻量化的 Job,他主要完成几条命令的发送就可以了,通常是把命令通过 ssh/rsh 来发送接受命令,在 mpi-operator 里使用的是 kubectl 来给 Worker 发送命令。
为什么 MPI-Operator 于 TF-Operator 相比没有 service 概念?kubectl-delivery 的已经将 kubectl 放入到 Launcher 容器内,之后可以通过 kubectl 来给 Worker 发送 mpirun 的命令。
主要过程
- MPIJob Controller 会根据每一份 MPIJob 的配置,生成一个 launcher pod 和对应个数的 worker pod;
- MPIJob Controller 会针对每一份 MPIJob 生成一份 ConfigMap,其中包含两份脚本,一为反映该任务所有 worker pod 的 hostfile,一为 kubexec.sh 脚本;
- Launcher pod 上的 mpirun 会利用由 ConfigMap 中的 kubexel 在 worker pod 中拉起进程;需要注意的是,kubectl的执行有赖于 MPIJob Controller 预先创建的 RBAC 资源(如果对应的 Role 中没有给 launcher pod 配置在 worker pod 上的执行权限,launcher pod 在执行
kubectl exec时会被拒绝);
运行MPI 除了 mpi-operator/trainning-operator 之外,还可以考虑使用 volcano的 job controllerMPI on Volcano。