简介
案例
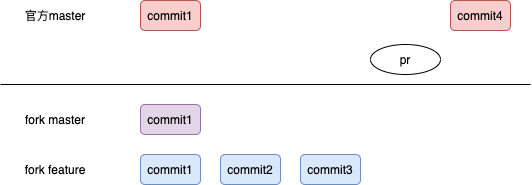 比如在给github 上一些项目提交pr 的时候发现以下问题
比如在给github 上一些项目提交pr 的时候发现以下问题
- 在提交的pr (包含commit2 和commit3) 合并到 master 之前,master 新增了commit4
- commit4 和pr 中的代码有冲突
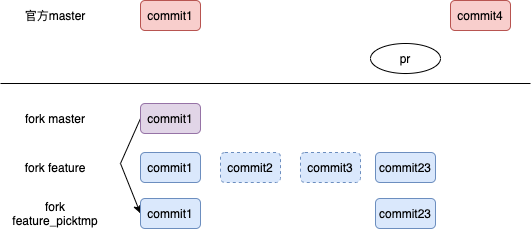
- 对于feature分支,首先合并commit2和commit3,成为commit23(这一步可以忽略)
- 从master fork 分支到feature_picktmp,然后通过git cherry-pick 将 commit23 转移到feature_picktmp 分支上
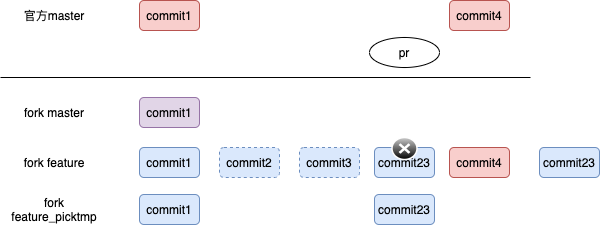
- 对于feature分支,废弃掉commit23,然后merge commit4,之后将 commit23 转移到feature 分支上
合并分支
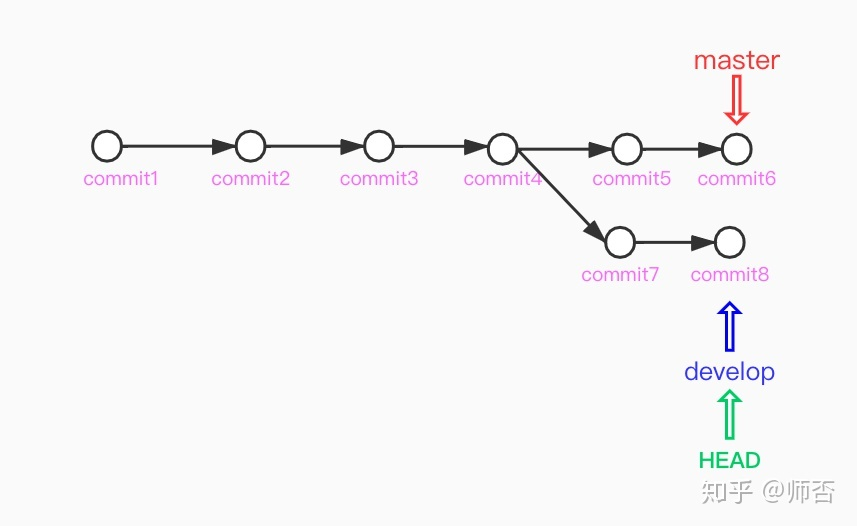
merge
在 develop 分支下merge master
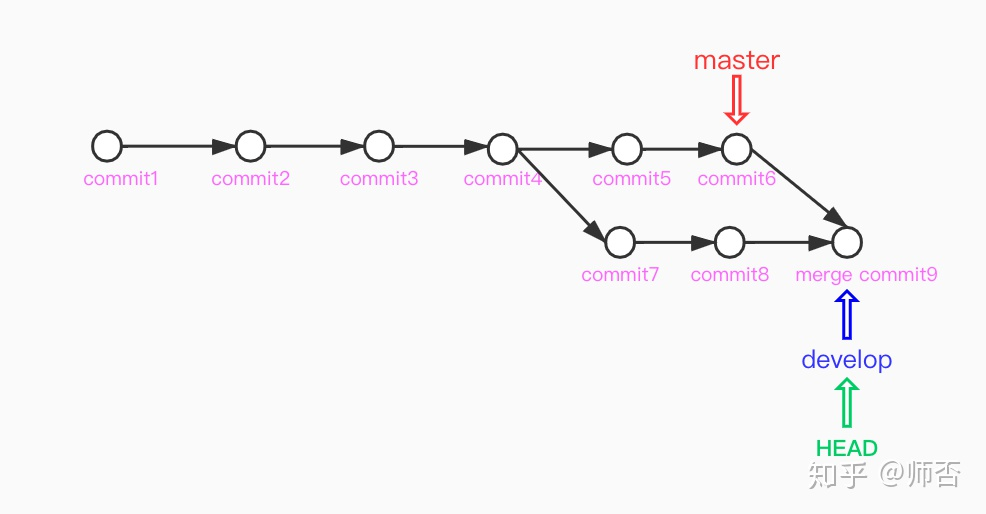
rebase
为什么你应该停止使用 Git rebase 命令 - KenChoi的文章 - 知乎
在 develop 分支下rebase master
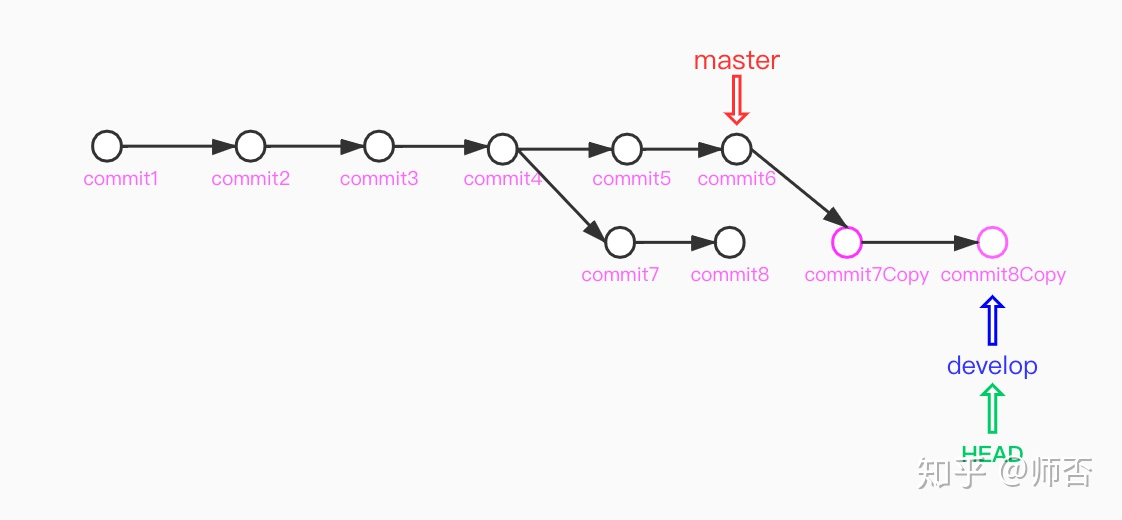
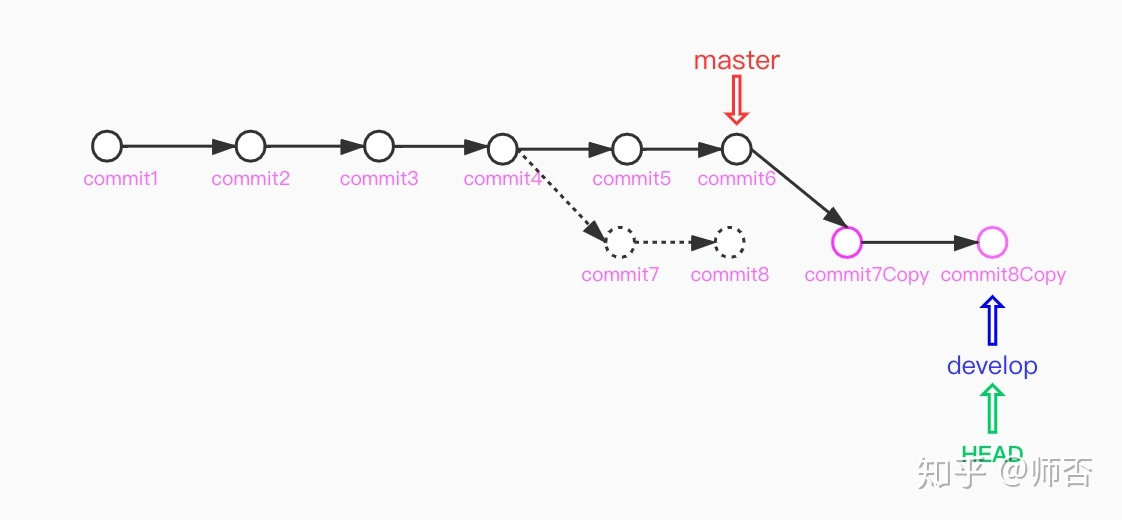
如果rebase过程中有冲突(就像merge 也会有冲突一样),就先解决冲突(选择/合并/丢弃commit),然后执行git rebase --continue 继续rebase
commit 操作
合并commit
# 在develop 分支
git rebase -i commit7 或者 git rebase -i HEAD~2
出来一个vim 操作界面,可以选择对commit8 commit7 保留删除合并等
一个 commit bind 一个多或多个文件变更,rebase 本质支持对commit 的移动(也就是对文件变更的处理),即对哪些文件变更进行何种操作:合并、丢弃、移动等。
转移commit到另一分支
对于多分支的代码库,将代码从一个分支转移到另一个分支是常见需求。这时分两种情况。
- 你需要另一个分支的所有代码变动,那么就采用合并(git merge)。
- 你只需要部分代码变动(某几个提交),这时可以采用 Cherry pick。Cherry pick 功能是把已经存在的commit进行挑选,然后重新提交。比较合适的一个场景是把A分支的某次或者多次的提交也提交到B分支上
# 先切换到 A 分支
$ git checkout A
# 找到这次提交
$ git log
commit f038d7ffb1685af7d4f870ad0b798670b6f760e8 (HEAD -> feature/0113_update)
Author: qxj <qxj@qq.com>
Date: Thu Jan 14 15:24:54 2021 +0800
feat: xxx
# 再切换到B分支
$ git checkout B
# 把 A 分支下的这次commit 重新提交到 B 分支下
$ git cherry-pick 'f038d7ffb1685af7d4f870ad0b798670b6f760e8'
转移多个commit 可以查询更多文章。git-cherry-pick教程
回退
reset
git reset --hard commit_id(可用 git log –oneline 查看) ### 本地代码回退,HEAD 就会指向 commit_id
git push origin HEAD --force ### 远程库代码回退
// 或者
git reset --hard HEAD~1
git push --force
还未commit 放弃当前目录所有变更 git checkout . && git clean -xdf
revert
git revert是用一次新的commit来回滚之前的commit,git reset是直接删除指定的commit。
git revert commitValue
commitValue可以使用git log查看
git协同工作流
来自陈皓《左耳听风》课程
- 中心式协同工作流
- 功能分支协同工作流,用分支来完成代码改动的隔离
-
gitflow协同工作流,开发、线上、预发和测试环境 都有对应的分支,要额外的精力管理好代码与环境的一致性。
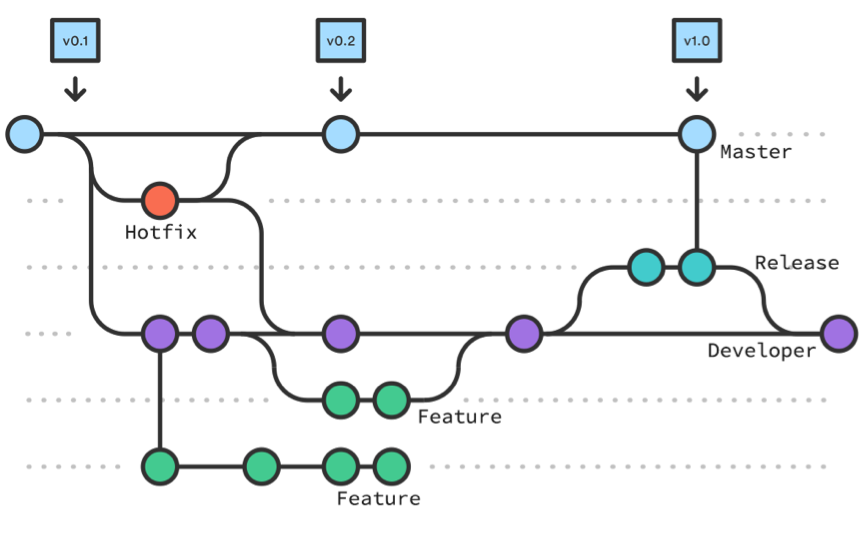
环境 分支 来源 持续性 备注 线上 master hotfix/release 合并 长期 每一次提交都是可以发布的 线上 hotfix 预发 release developer 副本 功能开发完成 到 发布前 测试 developer feature 合并/release 合并 长期 开发 feature1, feature2 - github flow/forking flow,官方库 ==> fork 本地库 ==> 开发、push本地库 ==> 发起 pull request ==> 合并到官方库
- gitlab flow 将github flow 与环境联系起来
协同工作流的本质:基于分支来解决并发、版本和环境等问题。
- 不同的团队能够尽大可能的并行开发
- 不同软件版本和代码的一致性
- 不同环境和代码的一致性
- 代码总是会在稳定和不稳定间交替。我们希望生产线上的代码总是能对应到稳定的代码上来。
gitflow 是略显复杂的,在微服务及soa架构方式下,每个服务都很小,对应代码仓库都很小。以devops为主的开发流程、ci/cd 使得feture 代码在很短时间 便可以合并到master上,无需维护大量分支。因此协同工作流的本质,并不是怎么玩好代码仓库的分支策略,而是玩好我们的软件架构和软件开发流程。
- TrunkBased 的“易于持续集成”和 GitFlow 的“易于管理需求”特点
基本原理
从git底层命令开始说起
参见https://git-scm.com/book/zh/v1
git命令分为底层(plumbing)命令和高层(porcelain)命令,底层命令得以让你窥探 Git 内部的工作机制,也有助于说明 Git 是如何完成工作的,以及它为何如此运作。 多数底层命令并不面向最终用户:它们更适合作为新命令和自定义脚本的组成部分。
Git是一套内容寻址文件系统。 这种说法的意思是,Git 从核心上来看不过是简单地存储键值对(key-value)。它允许插入任意类型的内容,并会返回一个key,通过该key可以在任何时候再取出该内容。可以通过底层命令 hash-object 来示范这点,传一些数据给该命令,它会将数据保存在.git目录并返回表示这些数据的key,通过 cat-file 命令可以将数据内容取回。
$ mkdir test
$ cd test
$ git init
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
// 也可以直接添加文件
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
存储的并不是文件名而仅仅是文件内容。这种对象类型称为 blob 。
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
Git 以一种类似 UNIX 文件系统但更简单的方式来存储内容。所有内容以 tree 或 blob 对象存储,其中 tree 对象对应于 UNIX 中的目录,blob 对象则大致对应于 inodes 或文件内容。通常 Git 根据你的暂存区域或 index 来创建并写入一个 tree 。因此要创建一个 tree 对象的话首先要通过将一些文件暂存从而创建一个 index 。
$ echo 'new file' > new.txt
$ git update-index --add new.txt
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
commit对象
$ echo 'first commit' | git commit-tree d8329f(一个 tree 的 SHA-1)
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3(一个前继提交)
cac0cab538b970a37ea1e769cbbde608743bc96d
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
commit指明了该时间点项目快照的顶层tree对象、作者/提交者信息(从 Git 设置的 user.name 和 user.email中获得)以及当前时间戳、一个空行,以及提交注释信息。
到这里,我们或许能理解git是一个内容寻址文件系统的含义。