前言
Kafka 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,这种设计使得 Kafka 能做到超高的性能。Kafka 的性能,尤其是异步收发的性能是Rabbitmq/Kafka/Rocketmq中最好的。这种异步批量的设计带来的问题是,它的同步收发消息的响应时延比较高,因为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批再发送。在服务端,Kafka 不会把一批消息再还原成多条消息,再一条一条地处理,这样太慢了。Kafka 这块儿处理的非常聪明,每批消息都会被当做一个“批消息”来处理。也就是说,在 Broker 整个处理流程中,无论是写入磁盘、从磁盘读出来、还是复制到其他副本这些流程中,批消息都不会被解开,一直是作为一条“批消息”来进行处理的。
重新理解kafka
Apache Kafka 是消息引擎系统,也是一个分布式流处理平台(Distributed Streaming Platform)
官网上明确标识 Kafka Streams 是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统。这就是说,你不能期望着 Kafka 提供类似于集群调度、弹性部署等开箱即用的运维特性。坦率来说,这的确是一个“双刃剑”的设计,也是 Kafka 社区“剑走偏锋”不正面 PK 其他流计算框架的特意考量。大型公司的流处理平台一定是大规模部署的,因此具备集群调度功能以及灵活的部署方案是不可或缺的要素。但毕竟这世界上还存在着很多中小企业,它们的流处理数据量并不巨大,逻辑也并不复杂,部署几台或十几台机器足以应付。
kafka 较新的1.0 和 2.0 也主要集中于kafka streams的改进。
消费端优化
多线程 消费
从spring kafka 源码分析 可以看到, spring-kafka 仅使用了一个线程来 操作consumer 从broker 拉取消息,一个线程够用么? 是否可以通过加线程 提高consumer的消费能力呢?
【原创】探讨kafka的分区数与多线程消费 一个消费线程可以对应若干个分区,但一个分区只能被一个KafkaConsumer对象 消费 + KafkaConsumer 对象是线程不安全的==> 一个分区只能被具体某一个线程消费。因此,topic 的分区数必须大于一个(由server.properties 的 num.partitions 控制),否则消费端再怎么折腾,也用不了多线程。
Kafka主动检测不支持的情况并抛出异常,避免系统产生不可预期的行为。下列代码展示了KafkaConsumer 如何进行并发检测
public class KafkaConsumer<K, V> implements Consumer<K, V> {
private static final long NO_CURRENT_THREAD = -1L;
// currentThread holds the threadId of the current thread accessing KafkaConsumer
// and is used to prevent multi-threaded access
private final AtomicLong currentThread = new AtomicLong(NO_CURRENT_THREAD);
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquire();
try {
if (topics == null) {
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
} else if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
for (String topic : topics) {
if (topic == null || topic.trim().isEmpty())
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
log.debug("Subscribed to topic(s): {}", Utils.join(topics, ", "));
this.subscriptions.subscribe(new HashSet<>(topics), listener);
metadata.setTopics(subscriptions.groupSubscription());
}
} finally {
release();
}
}
private void acquire() {
ensureNotClosed();
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
}
【原创】Kafka Consumer多线程实例KafkaConsumer和KafkaProducer不同,后者是线程安全的,因此我们鼓励用户在多个线程中共享一个KafkaProducer实例,这样通常都要比每个线程维护一个KafkaProducer实例效率要高。但对于KafkaConsumer而言,它不是线程安全的,所以实现多线程时通常由两种实现方法:
-
每个线程维护一个KafkaConsumer,多个consumer 可以subscribe 同一个topic
consumer.subscribe(Arrays.asList(topic));,如果consumer的数量大于Topic中partition的数量就会有的consumer接不到数据。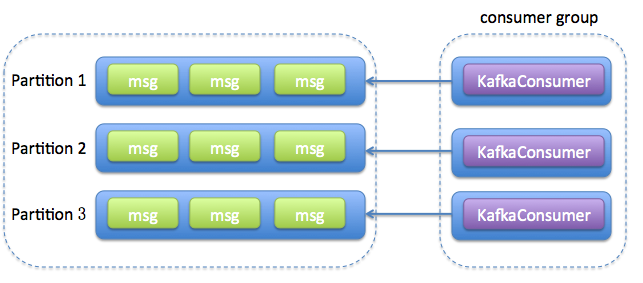
-
维护一个或多个KafkaConsumer,同时维护多个事件处理线程(worker thread)
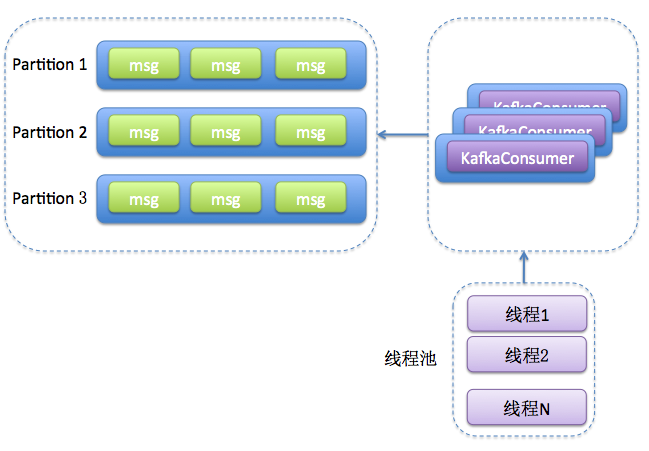
多线程消费的变迁
Why We Replaced Our Kafka Connector with a Kafka Consumer 结合kafka 源码中 ConsumerConnector 被标记为Deprecated 来看,kafka的消费端一开始用的是 ConsumerConnector,现在开始推荐使用 KafkaConsumer
Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); // 一个Topic启动几个消费者线程,会生成几个KafkaStream。
topicCountMap.put(topic, new Integer(KafkaStream的数量));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> topicList = consumerMap.get(topic);
for (KafkaStream<byte[], byte[]> kafkaStream : topicList) {
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
System.out.println("Receive->[" + new String(it.next().message()) + "]");
}
}
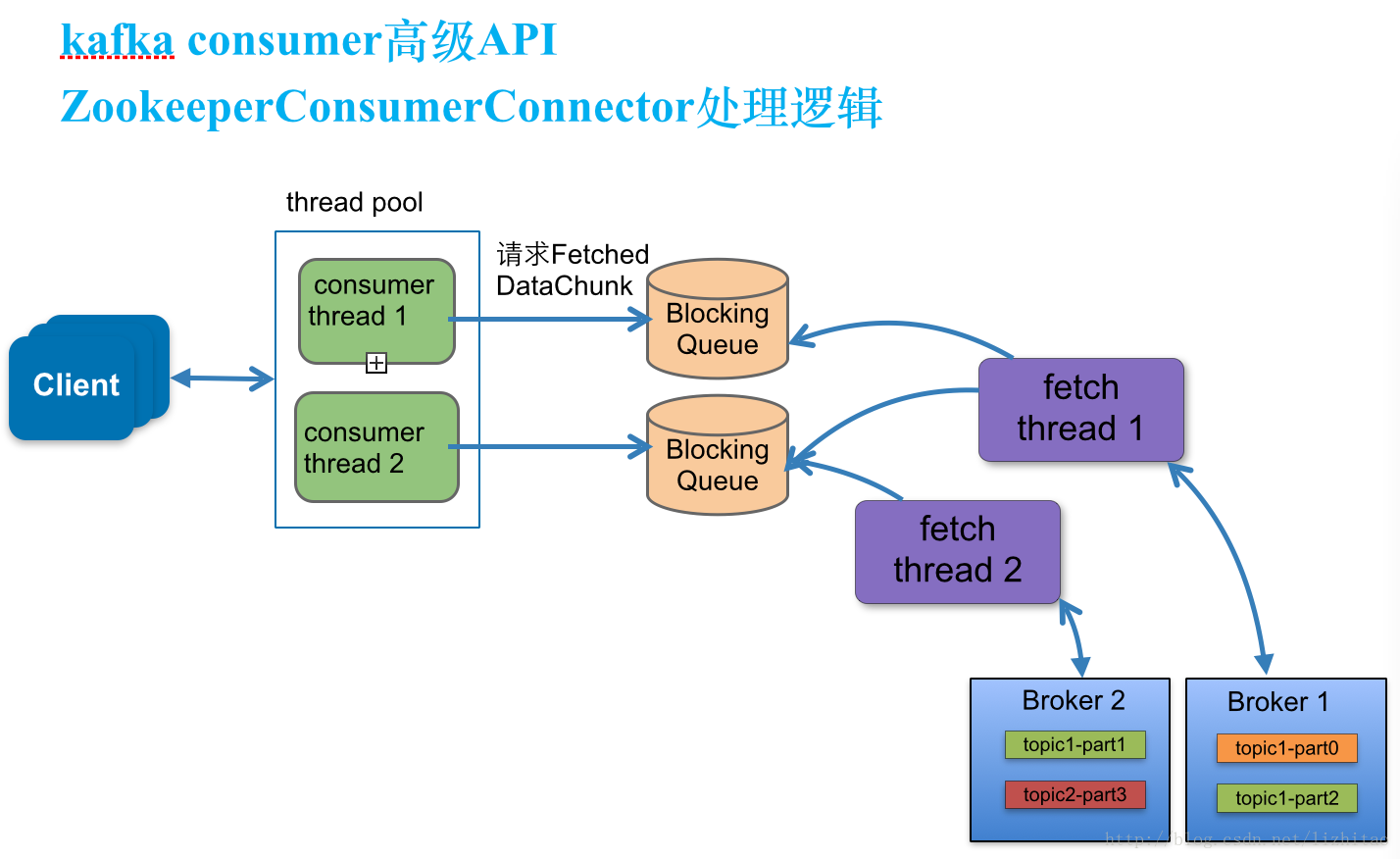
fetcher线程数和topic所在多少台broker有关。一个Topic启动几个消费者线程,会生成几个KafkaStream。一个KafkaStream对应的是一个Queue(有界的LinkedBlockingQueue)
重启项目导致rebalance
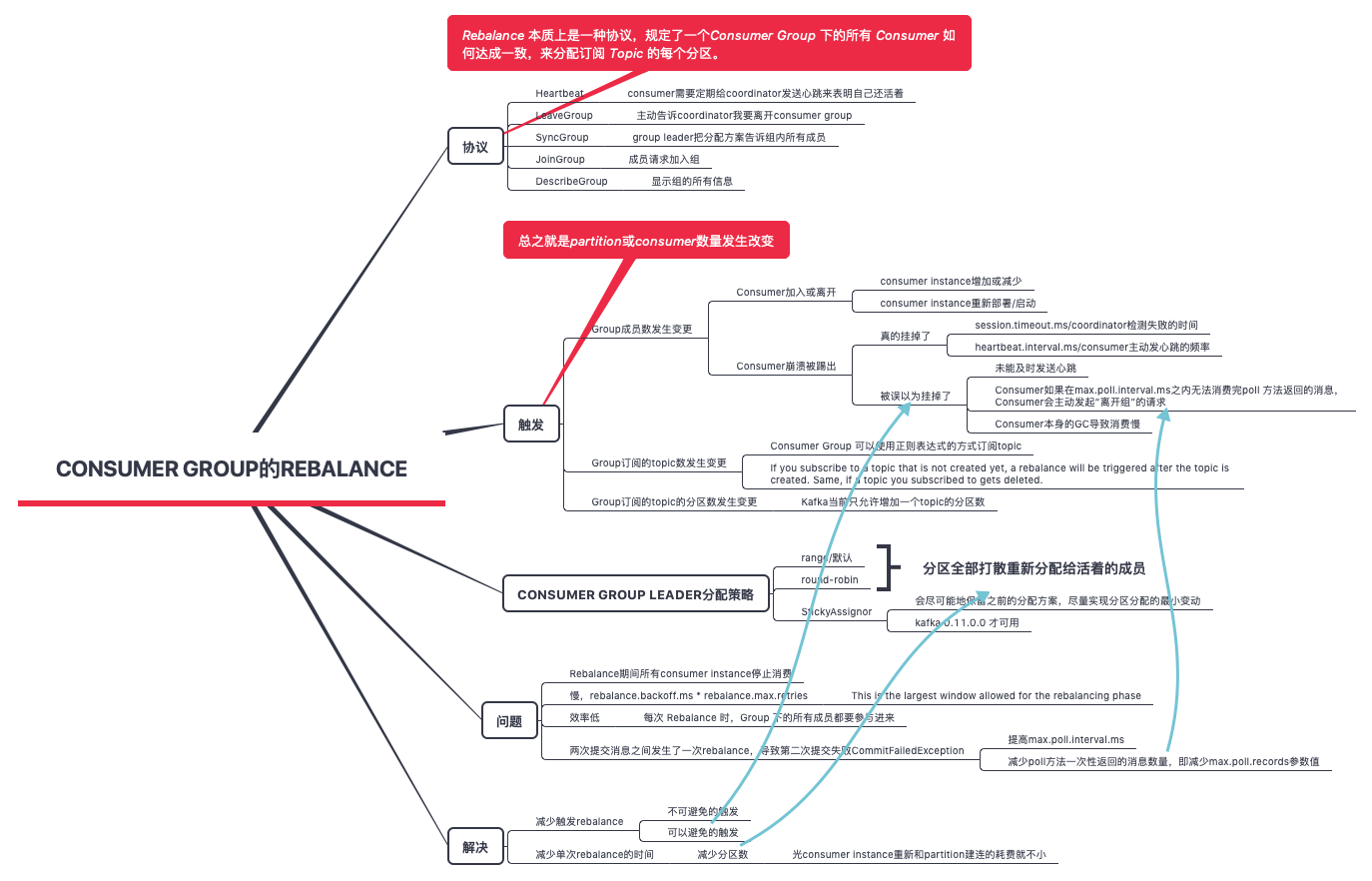
所以要处理三种情况
- consumer 多于 partition,不推荐,会有consumer 空闲
- consumer 等于 partition,这是理想的情况
- consumer 小于 partition
比如重新部署3个实例,每个实例的离开和joinGroup 会引起6次rebalance,rebalance 造成消费中断。
- 提高心跳时长,consumer instance重启完 broker都不知道重启了
- 减少一个topic partition的数量
直接重启一次很快,但是发布就有点慢? ==> 重启的时候无需拷贝war包,tomcat 可以立即启动,发布的时候,cmdb 要从跳板机(jenkins会把war包发到跳板机上)把war包拷贝到各个目标机器上 ==> 有一个时间,在这个时间内重启一遍引起的reblance较少,而超过这个时间引起的rebalance 时间较长 ==> 两个办法:找到这个时间,貌似是心跳时长,延长它;并行发布项目(6个实例一起拷贝war包并重启tomcat,cmdb有这个功能)
Kafka Streams error - Offset commit failed on partition, request timed out
Kafka Streams error - Offset commit failed on partition, request timed out
消费进度的监控
对于 Kafka 消费者来说,最重要的事情就是监控它们的消费进度了,或者说是监控它们消费的滞后程度。这个滞后程度有个专门的名称:消费者 Lag 或 Consumer Lag。
由于消费者的速度无法匹及生产者的速度,极有可能导致它消费的数据已经不在操作系统的页缓存中了,那么这些数据就会失去享有 Zero Copy 技术的资格。这样的话,消费者就不得不从磁盘上读取它们,这就进一步拉大了与生产者的差距,进而出现马太效应
监控消费进度的3个方法
- 使用kafka 自带的命令行工具kafka-consumer-groups.sh
- 使用java consumer api编程
- 使用kafka 自带的JMX 监控指标
生产端优化
分区策略
- 轮询
- 随机
- Kafka 允许为每条消息定义消息键,简称为 Key,一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面
- 其它,比如基于地理位置的分区策略
通用优化
拦截器
其基本思想就是允许应用程序在不修改逻辑的情况下,动态地实现一组可插拔的事件处理逻辑链。
Kafka 拦截器分为生产者拦截器和消费者拦截器。可以应用于包括客户端监控、端到端系统性能检测、消息审计等多种功能在内的场景。
重要的配置
要修改默认值的参数
-
log.dirs,这个参数是没有默认值的,必须由你亲自指定,值是用逗号分隔的多个路径,最好保证这些目录挂载到不同的物理磁盘上,有两个好处
- 比起单块磁盘,多块物理磁盘同时读写数据有更高的吞吐量
- 能够实现故障转移:即 Failover。这是 Kafka 1.1 版本新引入的强大功能。
- zookeeper.connect
- auto.create.topics.enable:是否允许自动创建 Topic,建议最好设置成 false,每个部门被分配的 Topic 应该由运维严格把控
log.retention.{hour|minutes|ms}:这是个“三兄弟”,都是控制一条消息数据被保存多长时间。从优先级上来说 ms 设置最高、minutes 次之、hour最低。默认保存 7 天的数据- log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小。这个值默认是 -1,表明你想在这台 Broker 上保存多少数据都可以。这个参数对多租户场景特别有用。
- message.max.bytes:控制 Broker 能够接收的最大消息大小。默认的 1000012 太少了,还不到 1MB。实际场景中突破 1MB 的消息都是屡见不鲜的。这个可以依据topic 进行个性化设置
其它
- kafka 的版本号分为两个部分:编译 Kafka 源代码的 Scala 编译器版本;kafka 自身版本。