简介
整体设计
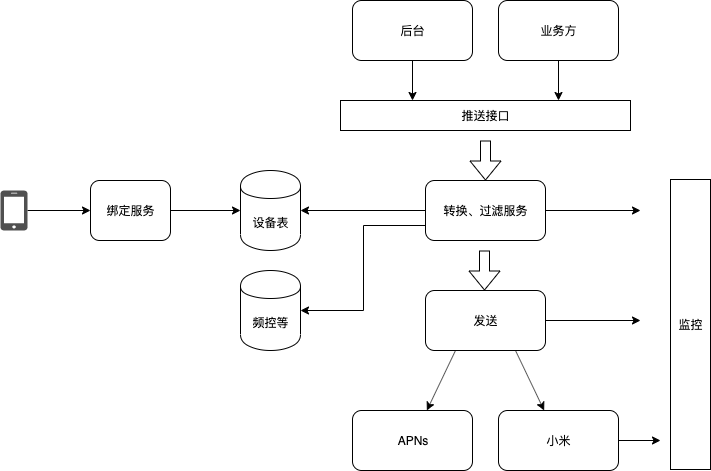
几个名词:
- uid/device id,公司内部对用户/设备的标记
- token,推送服务商(小米、个推)对设备的标记
推送的基本流程
- 公司内需求方 发送
<uid,msg>要求向特定用户推送 - 根据 uid 查询 用户设置、频控、亲密度 等服务,判定是否向用户发送推送
- 根据uid 查询对应的token ,调用推送服务商接口 发送
<token,msg>
因此,提炼出以下基本模块
- 推送调用方
- 过滤服务
- 推送服务
简单方案:模块之间采用消息队列连接
问题:出现大v的相关事件推送时,会堵,因此需要消息队列支持优先级的功能。
功能问题
-
推送需求
- 一般业务通知,与用户相关。比如“比如您订阅的xx更新了”
- 平台推广/用户唤醒,一个用户一天至少收到一次。全局推送 + 个性化推送
- 部分用户群体,特定信息通知。
-
推送系统和推送服务商关系
推送服务商只是实现了到设备的可达性,什么时候和发什么,仍有推送系统决定
-
推送系统日志采集与问题排查
- 唯一id关联推送的各个阶段
- 排查需求:某人为什么没收到消息
- 统计需求:每天的发送、接收和点击;一次全局推的发送、接收和点击
所以日志中应该包括:时间,用户,消息三个基本信息
-
通道选择
- 客户端轮询
- 长连接通道(针对即时性要求较高的业务)
- 推送服务商通道
-
推送过滤
- 根据用户设置、频控、用户打开时间
- 计算用户对推送内容的兴趣程度决定是否推送
- 两个互斥的业务
第一个是变化不大的,后两个则每天都会变化,如何动态插拔过滤规则
-
送达数和点击数的利用
- 分析用户兴趣
- 评估推送效果
-
面向使用者接口
- 关键就是消息model的定义。消息id,基本内容,客户端行为
-
客户端的准备
- 各个通道,统一消息model的处理
-
推送对其它系统的作用
- 提高用户对业务的粘性
- 各个系统之间的数据格式
-
优化设计
- 消息调度
- 负载隔离,比如直播服务及时性要求较高,全局推及时性要去低,两者不应共用同一个服务器
推送是一个数据处理系统
data processing system 和 普通的后端业务开发。
我们知道,一开始开发只有业务开发。后来因为大数据的火爆,产生了数据开发。两者有何差异呢?
- 一个显式的区别是,业务开发使用springmvc、dubbo 等构建业务逻辑。数据开发使用hadoop、spark 等处理业务。数据开发 后来分化为 批量处理和实时处理
- 后端请求处理多为集中式的,一个http 请求落在哪个服务器上,该服务器调用rpc/jdbc/redis 等从各个服务器抓取数据过来,根据业务要求 得到返回结果。计算是集中的,数据是分布的。
- 数据处理 多为分布式的,对于批量处理,因为数据量大,所以将数据分拆,计算跟着数据走。对于storm 等,则将计算分散在多个主机上,扩大数据的处理能力。不算数据是否集中,计算都是分散的
- 什么是数据处理,我们看spark 等提供的接口:过滤、转换、组合等。而业务处理通常类似于根据uid查询用户信息,用户发个评论数据库新增一条记录。
由此,我们可以看到,推送系统属于一个 data processing system ,拿普通的spring、springmvc、rpc调用那一套来实现 数据处理逻辑就会很难受。
因此,理想情况下,可以尝试使用storm/flink来替换 模块+消息队列的 处理方案。
性能问题
-
全局推和个性化推送的冲突问题
- 全局推顺序查询数据库,个性化推送随机查询数据库
- 全局推和个性化推送量都比较大,同时进行时,系统不堪重负
-
对于一个http 请求, 10ms 和 20ms 差距不大,因为用户感知不到。但是对于推送系统,请求却是累积的。比如我现在要给几百万用户发个推送,并且因为业务的原因(比如直播)要求几分钟内推完。从完成任务总量的时间来说,单个请求10ms和20ms 就是翻倍的性能差距
支持时效性短的推送——是一个隔离问题还是一个优先级问题
2019.3.15补充: 我们曾碰到一个问题,公司有直播业务,一般一次直播是一个小时,考虑到直播的时效性,业务方要求我们必须半个小时内将开播推送送达到主播的粉丝(越快越好)。我们直播组件之间是通过消息队列连接的,对该问题的理解有几个阶段
-
既然直播如此重要,就划出两台机器单独处理直播就可以了。但这个方案有几个问题
- 直播推送只有晚上忙,白天直播机器空着太浪费了
- 服务与节点绑定,导致业务上线复杂
-
我们在发送方和 接收方之间专门加了一个 dispatcher 服务,根据后台配置将不同业务推送分发到不同的节点上
- 方便了上线
- 直播节点白天清闲晚上繁忙的问题还是没有解决
- 基于rabbitmq 实现,深度依赖了rabbitmq的订阅模型,导致我们后续想更换kafka 时非常困难。解决一个问题有多种方式、层面(业务层、架构层、中间件层、存储层等),慎重
-
一般的推送其实时效性并不高,所以本质是一个根据时效性决定优先级的问题。rabbitmq 本身支持优先级队列,但消息量太大时会出问题。
反思
- 当时为什么就按照 隔离去想去做了?或者说,做成隔离的样子也问题不大,但应该对功能 特性做深度的抽象,即隔离的复杂性 由中间件负责,而不是业务负责,更犯不上为了实现隔离单独做了一个dispatcher 组件。
- 单纯的隔离无法解决 节点负载不均衡的问题,所以隔离的粒度不应该是节点,而是节点内部的隔离,比如不同的业务类型采用不同的线程池。 当你发现不同业务的时效性其实没那么高之后,很容易联想到优先级。当你进行深度抽象时,才容易发现隔离和优先级的共性特征。
- 方案设计时,没有经过充分的讨论,就自己拍脑袋
- 方案设计时,根本不知道 rabbitmq 支持优先级队列,技术能力影响视野
- 当我知道要按优先级队列做时,消息中间件团队已有组件并不支持,但他们很乐意支持。当你对本质有一个较为深刻的理解后,你可以发现需求,推动改变。
时刻保持优雅,而不是修修补补成大泥球