简介
Kubernetes架构为什么是这样的?在 Google 的一篇关于内部 Omega 调度系统的论文中,将调度系统分成三类:单体、二层调度和共享状态三种,按照它的分类方法,通常Google的 Borg被分到单体这一类,Mesos被当做二层调度,而Google自己的Omega被当做第三类“共享状态”。我认为 Kubernetes 的调度模型也完全是二层调度的,和 Mesos 一样,任务调度和资源的调度是完全分离的,Controller Manager承担任务调度的职责,而Scheduler则承担资源调度的职责。
| 资源调度 | 任务调度 | 任务调度对资源调度模块的请求方式 | |
|---|---|---|---|
| Mesos | Mesos Master Framework |
Framework | push |
| YARN | Resource Manager | Application Master Application Manager |
pull |
| K8S | Scheduler | Controller Manager | pull |
Kubernetes和Mesos调度的最大区别在于资源调度请求的方式
- 主动 Push 方式。是 Mesos 采用的方式,就是 Mesos 的资源调度组件(Mesos Master)主动推送资源 Offer 给 Framework,Framework 不能主动请求资源,只能根据 Offer 的信息来决定接受或者拒绝。
- 被动 Pull 方式。是 Kubernetes/YARN 的方式,资源调度组件 Scheduler 被动的响应 Controller Manager的资源请求。
为什么不支持横向扩展?
几乎所有的集群调度系统都无法横向扩展(Scale Out),集群调度系统的架构看起来都是这个样子的
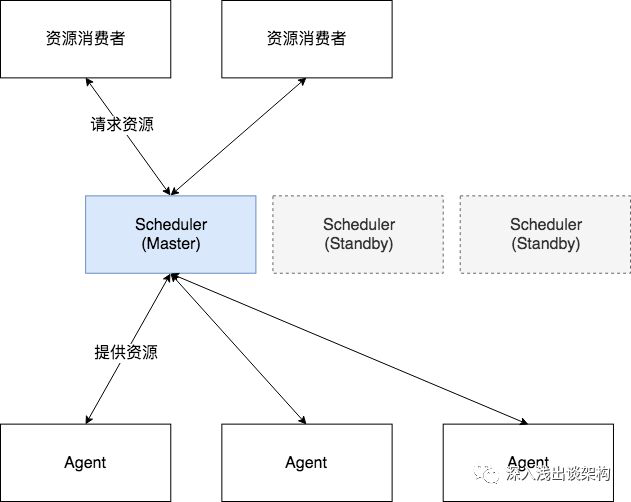
中间的 Scheduler(资源调度器)是最核心的组件,虽然通常是由多个(通常是3个)实例组成,但是都是单活的,也就是说只有一个节点工作,其他节点都处于 Standby 的状态。
每一台服务器节点都是一个资源,每当资源消费者请求资源的时候,调度系统的职责就是要在全局内找到最优的资源匹配:拿到全局某个时刻的全局资源数据,找到最优节点——这是一个独占操作。
一篇文章搞定大规模容器平台生产落地十大实践对于大的资源池的调度是一个很大的问题,因为同样一个资源只能被一个任务使用,如果串行调度,可能会调度比较慢。如果并行调度,则存在两个并行的调度器同时认为某个资源空闲,于是同时将两个任务调度到同一台机器,结果出现竞争的情况。Kubernetes有这样一个参数percentageOfNodesToScore,也即每次选择节点的时候,只从一部分节点中选择,这样可以改进调度效率。
调度分类
资源全局最优 vs 业务稳定性最优
在线调度最常见的调度能力
- 应用基本诉求:如规格、OS等
- 容灾与打散
- 高级策略:应用对物理资源、网络、容器的一些定制要求。
- 应用编排:比如应用对宿主机的独占要求,以确保绝对的防干扰;多个应用部署在同一台宿主机上的互斥要求
- cpu 精细编排:最大化使用宿主机物理核资源;应用之间最小cpu干扰隐患
- 重调度:应用重调度;cpu重调度
中心调度器做到了一次性最优调度;但与最终想要的集群维度全局调度最优,是两个完全不一样的概念。重调度也包括全局中心重调度和单机重调度。为什么一定需要中心重调度作为一次性调度的补偿呢?我们举几个例子:
- 集群内存在众多长生命周期的 POD 实例;随着时间的积累,集群维度必将产生众多资源碎片、CPU 利用率不均等问题。
- 大核 POD 的分配需要动态的腾挪式调度能力(实时驱逐某些小核 POD 并空闲出资源)、或基于提前规划的全局重调度,在众多节点上预空闲一些大核。
- 资源供给总是紧张的。对某个 POD 做一次性调度时,可能存在一定“将就”,这意味着某种瑕疵和不完美;但集群资源又是动态变化的,我们可以在其后的某个时刻,对该 POD 发起动态迁移,即重调度,这将带来业务更佳的运行时体验。